
分布式系统,顾名思义,就是让多台服务器、多计算单元,协同来完成整体的计算任务。它拥有多种组织方式。在分布式系统中,使用分层模型,路由和代理计算任务、存储任务,将不同的工作,划分到不同业务集群机器中,是常用的方法。一般来说,最基础的分布式系统,可以分为典型的三层结构:
-
接入层:用来对接客户连接的第一层,负责用户业务处理的分发,和用户连接的负载均衡。
-
逻辑层:处理系统不同业务的计算层,不同的业务可以划分到不同的计算集群当中,等待接入层分配任务,处理不同的业务单元。
-
数据层:通过离散化的存储方式,提高整体数据的写入、读取、检索的速度。
相关工作示例,如图1所示:
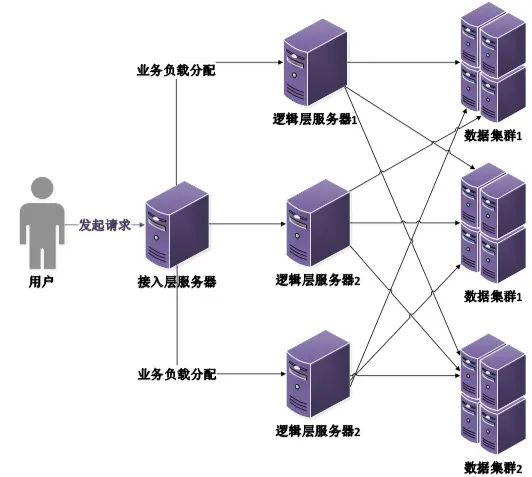

图1 分布式系统基本三层结构
这是最基本的分布式系统,在实际业务中,根据需求的不同,系统的分散和划分方法也会又很大的不同,不同的的业务层中,特别在复杂的分布式系统中,还会定义专门的代理网关Proxy和路由进程Router处理消息的分发和负载均衡。
在基本的分布式系统中,为了支持更为庞大的系统能力,解决特定的分布式问题,分布式系统又总结了一些典型的分布式模型和技术方案。
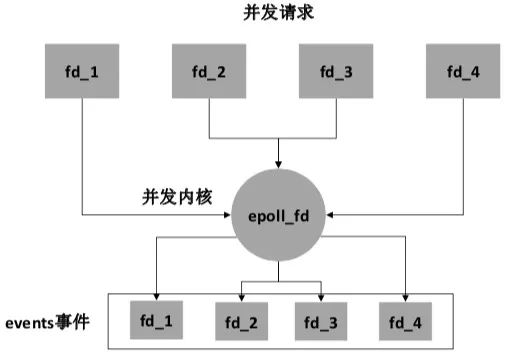
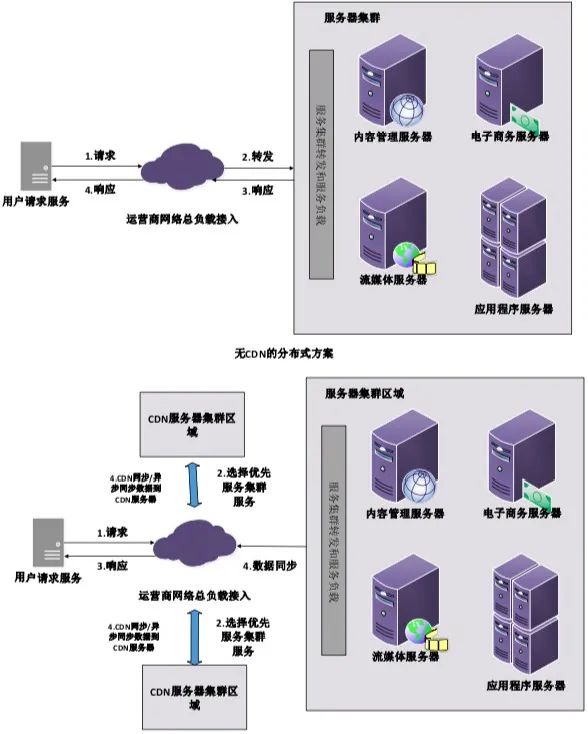
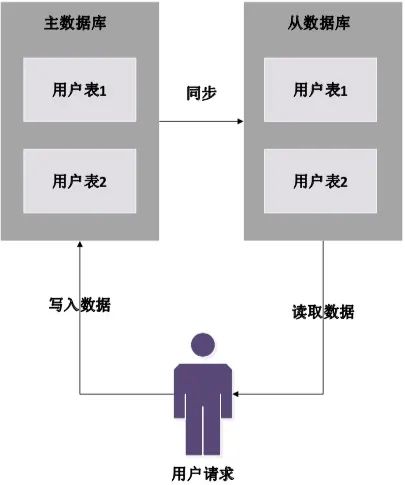
并发模型 一个服务器在处理用户请求的时候,可能会同时接受到非常多的用户请求,并且还需要为其他用户返回数据输出。在处理过程中,服务器系统经常会有“等待”或者“阻塞”的问题存在。系统如果去等待一个请求到下一个请求,会极大的降低系统效率,降低吞吐量。这就是分布式系统中,经常遇到的“并发问题”。 在分布式的并发模型中,常用的是两种方案:多线程方案和异步方案。 在早期时间,多线程多进程方案是最常用的技术。但是多线程技术在处理以下问题拥有一些弊端: 多线程中,多个线程程序的执行顺序不可控制。 同步数据和对象,不同线程之间同步处理,会造成不可估计的错误,或者死锁问题。 多线程之间,不同CPU处理之间的数据来回拷贝,会造成CPU计算资源的浪费。 针对多线程方案的弊端,异步模型方案,逐步开始流行起来。异步模型方案,解决了多线程的死锁问题,也避免了数据拷贝之间的消耗。异步回调模型,就是最早的分布式计算中,并行计算的雏形。 异步回调模型的实现,是基于非阻塞的I/O(网络和文件)模型,在函数读写的时候,不用等待当前函数调用的结果,立刻返回“空“或者”有“的结果。 最常用的异步回调模型,是Linux的epoll模型,它使用底层内核,快速查找到数据,读写连接或者文件,当计算完成以后,再通过连接异步处理、并且返还结果。它的每个操作都是非阻塞的,一个进程就可以使用这种方式,处理大量的并发消息。另一方面,由于异步模型是单个进程的,它的数据和处理逻辑都是固定的,不会出现多线程的不可预知错误,也不需要加锁。它大大简化了并行模型的开发过程,是现阶段高吞吐、高并发系统的首选。它的运作模型,如图2所示: 图2 epoll并发模型 除了并发模型,在后面我们还会再继续详细介绍分布式中的并行计算方案。 分布式中的数据缓冲 在互联系统和智能设备的分布式系统中,为了具有良好的用户体验,需要在秒的级别之内,返还结果。分布式系统,它的运算遍布在各个分布式集群当中,为了提高系统效率,数据缓冲就成为了它的常用技术方案。 分布式缓冲技术,应用最广泛的是CDN(Content Delivery Network)内容分发网络,它大量运用在视频、图片、直播等应用领域。它的原理,是使用大量的缓存服务器,将缓存服务器分布到用户集中访问的地区网络中,用于提高当地的数据延迟。在用户进行使用的时候,使用全局的接入层和负载技术,将用户指向它最近、最适合的缓存服务器中,通过这个服务器响应用户的消息请求。它的部署原理,如图3所示: 图3 非CDN缓存的分布式和CDN缓存的分布式方案 除了CDN缓存技术,还有很多其他的分布式换从技术,比如反向代理缓存、本地应用缓存、数据库缓存、分布式共享缓存、内存对象缓存等,大家可以自行学习这些技术。 分布式存储技术 在分布式系统的时代,数据如何存放更大的数据、承载更多的连接、支持更多的并发检索,成为了新时代技术的跳转。在传统的MySQL数据库,逐渐无法承载大互联网时代的系统需求,数据存储的方式变得更加多样化,比如使用文件、数据条切片等方式。在这种情况下,分布式数据库NoSQL应运而生,用于支持高并发的分布式业务,其中的佼佼者有MangoDB、Redis、RadonDB等。 分布式数据库,可以承载更大的、更快的数据能力,不同的数据,可以存放在不同的服务器上,通过特定的检索和应用方式,将机器集群联合起来。这也是分布式系统的一种,数据系统的分布式系统。在分布式数据系统中,根据数据的拆分和管理方式,主要可以分为以下几类: 单数据库架构:不同的数据库服务器中,各自独立数据,相互不干预。 主从数据库架构:由一台服务器处理数据写入,一台服务器处理读取查询,相互之间进行数据同步,如图4所示: 图4 主从数据库架构 垂直数据库切分架构:将每个单独垂直的数据库模块,和服务器逻辑层的模块联合起来,形成一个相对垂直的业务-数据模型,各个数据之间的耦合,只在逻辑层进行联合处理。 水平数据切分架构:将大量的高段位的数据,进行水平的存储,并且进行拆分,拆分到不同表中,比如有个数据由10000条,我们可以切分为10条数据库,每个数据段存储1000条,再通过统一检索的方式,检索指向到不同的服务器数据库位置,其中大数据Hadoop中的HDFS是这种架构的佼佼者。
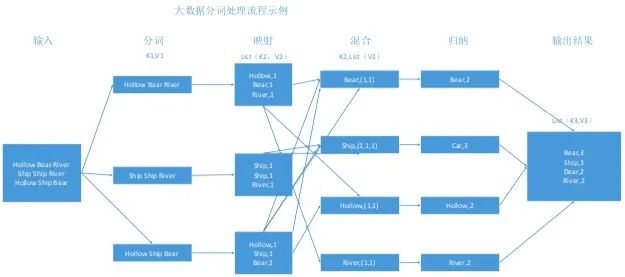
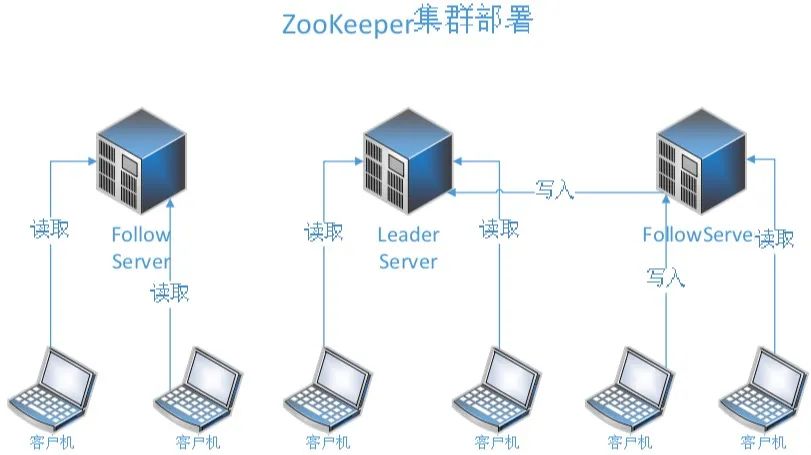
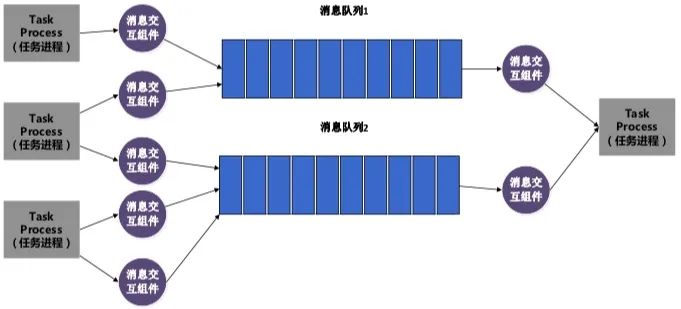
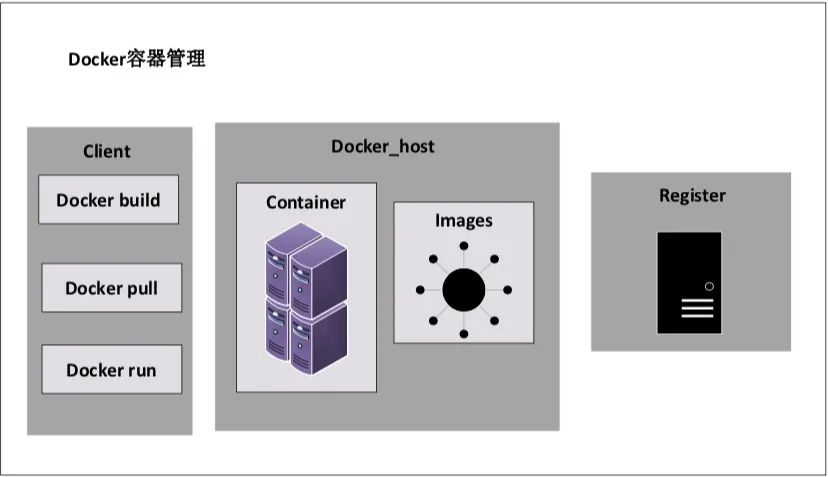
分布式系统管理 分布式系统,并不是简单的堆砌机器集群,如果没有良好的调度和管理方式,分布式系统可能还不如集中式系统,它的复杂性和容错性,可能还会降低效率。 在分布式系统的管理上,我们可以关注以下几个主要指标: 硬件故障率:分布式集群,拥有很多太服务器,每个服务器都有一定的硬件故障几率,我们设定为x。分布式系统拥有n台服务机器,作为一个整体集群,它出现硬件的故障几率,可以使用如下计算方式:SER(System Error Rate)=1 –(1-x)^n,可以看出,随着机器规模的增加,故障率会逐步上升。有效的硬件监控和故障预测,是分布式系统管理的重要组成。 资源利用率:分布式系统在运作的时候,可能会出现这样一种情况:在某些时段,某些机器非常繁忙,而某些机器却出现闲置,甚至某些服务长期才会使用一次。这样造成了计算资源极大的浪费,也会让分布式系统产生了很多不必要的开销。一个高效的分布式系统管理,需要有高效和灵活的管理机制,既不会让某些机器高负载运转,也能在灵活调度计算资源的分配,让整个系统都能得到较好的使用效率,并且持续保持健康。另外,分布式系统集群的扩容、缩容,实时在线操作,都是需要非常复杂的技术处理,这也是分布式系统管理的重要研究对象。 分布式系统的更新和扩展:在一个大型的分布式系统中,多个系统相互协作,相互影响,在更新某个系统或者模块的时候,不免会影响到其他系统的工作。如果停止整个系统的运营,会对用户造成极大的伤害。所以在分布式系统的设计当中,系统的更新和扩展,也是极其重要的考核指标。在这个方面,诞生了不少优秀的分布式框架,比如微服务框架EJB、WebService等。 数据决策统计:在大型的分布式系统中,很多都伴随着大数据系统的运行,如何去使用分布式方案,进行数据的统计和决策,也是重要的技术方案。其中Google的MapReduce模型,如图5所示: 图5 MapReduce分词处理模型 针对分布式系统的各项需求,在长期的发展中,在工业界和学术界,诞生了许多针对性的系统或者组件,具体可以归类如下所示: 目录服务和中控系统 分布式系统是由许多系统和进程共同组成,如何去响应每个服务所需要的功能模块,监听服务模块的负载情况,调配系统集群资源,应急突发的错误情况、扩展和恢复系统组件,是分布式系统的痛点需求。其中Hadoop的Zookeeper是比较优秀的开源项目,它能帮助系统处理数据发布/订阅、负载均衡、服务名称管理、配置信息维护、命名处理、分布式协调、Master选举、数据同步、消息队列、分布式业务锁等。它的运作方式,如图6所示: 图6 ZooKeeper集群结构 在Zopper集群种,采用Paxos算法,主要包含三种节点角色: Leader节点:表示被选区的机器节点,提供读写的服务,需要被选举。 Follow节点:集群的其他节点,提供对外逻辑服务和同步功能,参与Leader节点的选举策略。 Observer节点:集群的其他节点,提供对外逻辑服务和同步功能,不参与Leader节点的选举策略。 消息队列 在分布式系统中,不同服务之间,需要进行协调沟通,消息的一致性也是非常重要的。对此产生了一些非常优秀的消息队列组件,比如Kafka、ActiveMQ、ZeroMQ、Jgroups等。消息队列模型,将抽象进程间的交互为消息处理,形成一个“消息队列的管道”,进行存储。其他的进程可以对队列进行访问,读取消息或者处理消息,消息的路由存放的队列管道进行决策,这样就静态化了复杂的消息路由问题,形成了易用的消息模型。具体模型示例,如图7所示: 图7 消息通道组件工作 消息队列组件,类似一个邮箱,消息队列服务是一个独立的进程,相关的其他服务,可以通过消息队列组件,向队列进程投放消息,队列再进行消息的一致性分发,将它分发到预定的目标服务,让消息的分发更加简便、运维更加清晰。 事务协调系统 事务协调是分布式系统中最为复杂的技术问题,一个完全的业务流程,它可能关联着不同的服务进程,不同的进程之间协调工作,是一个复杂的流程。业务过程中还会有故障产生,相关的备用解决方案,也是重要的问题。 自动化部署 分布式系统是一个分散化的、高度复杂性的大型系统,对于它的部署和运维,是一项艰难的任务,如果通过人力进行工作,将会耗费极大精力和时间。自动化的部署,就成为了分布式系统的重要辅助系统,其中容器化Docker、“池管理”、RPM打包,都是优秀的部署系统。下面是Docker的运作模式,如图8所示: 图8 Docker的容器组件模块 分布式系统是一个复杂的、高度能力分散自治的系统能力,如何去面向未来群体智能的新时代技术体系,分布式系统是打开大门最关键的一把钥匙。

原创文章,作者:速盾高防cdn,如若转载,请注明出处:https://www.sudun.com/ask/30549.html