
楔子
上一篇文章(可以点击传送门进行阅读)我们介绍了 ES 的基本概念以及安装方式,那么本次就来看看如何操作 ES。ES 支持客户端通过标准的 HTTP 请求来访问数据,并且 API 遵循 Restful 风格。

操作索引
我们说过,ES 的索引就类似于 MySQL 的数据库,因此我们首先要创建索引。
创建索引
方式:通过 PUT /{index} 即可创建指定名称的索引,举个例子。
PUT http://82.157.146.194:9200/people此时我们便创建了一个索引叫 people,同时服务器会返回如下内容。
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "people"
}返回的 JSON 包含三个字段,含义如下。
- acknowledged:响应结果,true 表示添加成功;
- shards_acknowledged:分片结果,true 表示分片成功;
- index:创建的索引名称;
注意:索引的分片数量默认为 1,在 7.x 之前默认为 5。
如果添加的索引已存在,那么会返回错误信息,比如我们将索引 people 再创建一次。
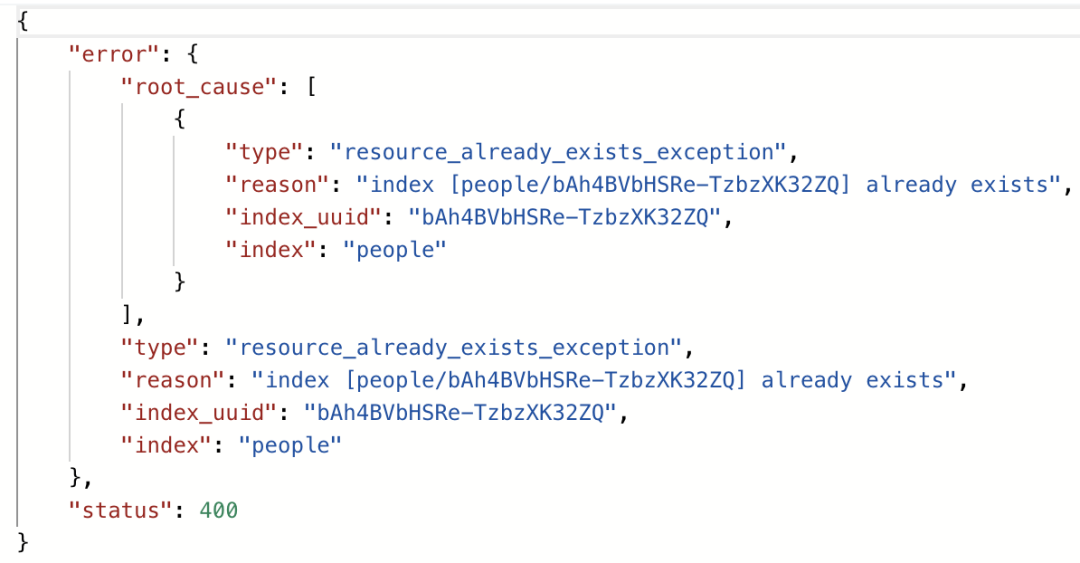
服务器依旧会返回一个 JSON,里面包含了详细的错误信息,这些信息都见名知意。并且不管什么错误,返回的错误信息的格式是固定的。
当然,如果你不确定添加的索引是否存在,那么在添加之前可以查看一下。
查看索引
方式:通过 GET /{index} 即可查看指定的索引信息。
GET http://82.157.146.194:9200/people服务器返回内容如下。

里面有几个关键字段需要解释一下。
- number_of_shards:分片数量,我们说 ES 会将 Index 切分成多份,每一份叫做一个 shard,从 7.x 开始默认只有一个 shard;
- number_of_replicas:副本数量,每个 shard 可以配置多个副本,保证高可用,默认副本数为 1;
- creation_date:索引的创建时间;
- uuid:索引的唯一标识;
shard 也被称为主分片,primary shard
replica 也被称为副本分片,replica shard
不过我个人还是习惯称它们为分片和副本
以上就是查看索引,但如果索引不存在,会返回什么呢?比如我们查看 people2,这个索引是不存在的。
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [people2]",
"resource.type": "index_or_alias",
"resource.id": "people2",
"index_uuid": "_na_",
"index": "people2"
}
],
"type": "index_not_found_exception",
"reason": "no such index [people2]",
"resource.type": "index_or_alias",
"resource.id": "people2",
"index_uuid": "_na_",
"index": "people2"
},
"status": 404
}返回的依旧是包含错误信息的 JSON,里面的字段解释了错误的原因。
查看全部索引
然后除了查询单个索引之外,也可以查询全部的索引。
GET http://82.157.146.194:9200/_cat/indices里面的 _cat 表示查看,indices 表示索引,整体含义就是查看当前 ES 服务器的所有索引。
服务器会以一个二维表的形式返回,第一行是字段,剩余行是索引记录。其中字段的含义如下:
- health:当前服务器健康状态,green 表示集群完整,yellow 表示单点正常、集群不完整,red 表示单点不正常;
- status:索引的状态,是打开还是关闭;
- index:索引的名称;
- uuid:索引的唯一编号;
- pri:分片(shard)的数量;
- rep:副本(replica)的数量;
- docs.count:可用文档(Document)的数量;
- docs.deleted:文档删除状态(逻辑删除);
- store.size:分片和副本整体占用的空间大小;
- pri.store.size:分片占用的空间大小;
- dataset.size:主分片占用的空间大小;
删除索引
说完了添加索引和查询索引,再来看看如何删除索引。相信删除的过程不用我说你也知道,发一个 DELETE 请求即可。
DELETE http://82.157.146.194:9200/people服务器返回内容如下:
{
"acknowledged": true
}返回的 JSON 里面只包含一个 acknowledged 字段,为 true 表示删除成功。如果删除一个不存在的索引,那么会报错,比如这里再次删除索引 people。
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [people]",
"resource.type": "index_or_alias",
"resource.id": "people",
"index_uuid": "_na_",
"index": "people"
}
],
"type": "index_not_found_exception",
"reason": "no such index [people]",
"resource.type": "index_or_alias",
"resource.id": "people",
"index_uuid": "_na_",
"index": "people"
},
"status": 404
}因此基于返回值我们很容易判断出,操作是否出现错误,以及错误原因是什么。
关于索引操作,再总结一下。
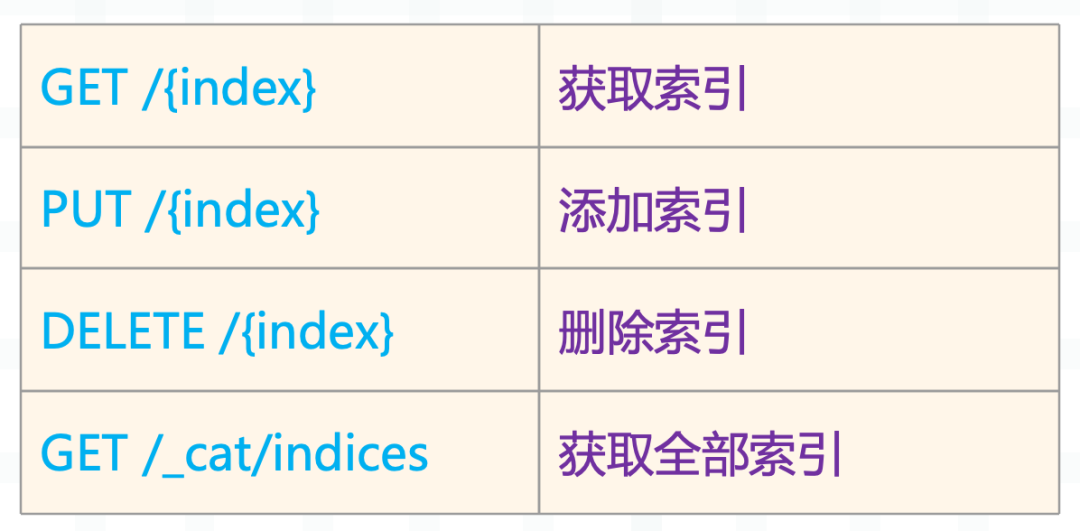
以上就是索引相关的操作,还是比较简单的。
文档操作
索引已经创建好了(刚才删除的 people 索引又重新创建了),接下来我们来创建文档,并添加数据。这里的文档可以类比关系型数据库中的表数据,添加的数据格式为 JSON。
另外我们知道在关系型数据库中,必须先定义好表、指定好字段才可以使用,但在 ES 中则不需要。因为 ES 对字段的处理是非常灵活的,我们可以忽略某个字段,或者新增一个字段。
新增文档
首先是添加一个新文档。
// 通过 PUT /{index}/_doc/{document_id} 添加文档
// 文档数据是一个 JSON
PUT http://123.57.183.166:9200/people/_doc/satori{
“name”: “古明地觉”,
“age”: 17,
“gender”: “female”,
“address”: “地灵殿”
}
一个 document 就是一条 JSON 数据,每个 document 都有一个唯一的 id,其中 id 可以通过路径参数指定。返回响应如下:
{
"_index": "people",
"_id": "satori",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}解释一下里面的字段:
_index:标识文档位于哪个索引中;_id:每个文档都有一个唯一 id;_version:版本号,当对文档执行增删改操作时,该文档的版本号会自增 1;result:这里的 created 表示创建成功;_shards.total:分片的总数;_shards.successful:创建成功的分片数;_shards.failed:创建失败的分片数;
到这里应该有人发现了,如果文档 id 每次都需要手动指定,未免有点麻烦。因此 ES 也可以帮我们生成文档 id,做法如下:
POST http://123.57.183.166:9200/girls/_doc{
“name”: “芙兰朵露”,
“age”: 400,
“gender”: “female”,
“address”: “红魔馆”
}
这里我们没有指定文档 id,那么 ES 会自动生成,返回响应如下。
{
"_index": "people",
"_id": "HSW404wBlTaHOP7A6wd2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}注意这里的请求,如果通过路径参数手动指定了文档 id,那么 POST 和 PUT 请求均可。但如果没有指定文档 id,那么只能使用 POST 请求。
获取文档
目前我们已经在 people 这个 index 下面创建了两个 document,它们的 id 分别是 satori 和 HSW404wBlTaHOP7A6wd2,那么便可通过如下方式进行查询。
GET /people/_doc/satoriGET /people/_doc/HSW404wBlTaHOP7A6wd2
响应内容如下:
{
"_index": "people",
"_id": "satori",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "古明地觉",
"age": 17,
"gender": "female",
"address": "地灵殿"
}
}{
“_index”: “people”,
“_id”: “HSW404wBlTaHOP7A6wd2”,
“_version”: 1,
“_seq_no”: 1,
“_primary_term”: 1,
“found”: true,
“_source”: {
“name”: “芙兰朵露”,
“age”: 400,
“gender”: “female”,
“address”: “红魔馆”
}
}
里面的 _source 字段的值,就是我们添加的文档数据。
修改文档
说完了添加和查询,再来看看修改,比如我想将文档 id 为 ‘satori’ 的文档中的 name 字段的值,改为 ‘古明地恋’,要怎么做呢?
// 手动指定了文档 id,那么 POST 和 PUT 均可
// 如果没有指定,那么只能使用 POST
// 因此这里 POST 和 PUT 均可
POST /people/_doc/satori{
“name”: “古明地恋”,
“age”: 17,
“gender”: “female”,
“address”: “地灵殿”
}
非常简单,直接改即可。就像新建文档一样,输入相同的 URL,会将旧的文档数据替换掉,并且版本号会自增 1。ES 服务器返回数据如下:
{
"_index": "people",
"_id": "satori",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}我们看到 _version 从初始的 1 变成了 2,并且此时的 result 不再是 created,而是 updated,表示更新。并且在更新的过程中,字段数量可以和之前不一样,也就是说我们可以新增字段、删除字段,非常灵活。
并且由于指定了文档 id,所以 POST 请求和 PUT 均可。这里我们将另一个文档也给改了,并调整一下字段。
PUT /people/_doc/HSW404wBlTaHOP7A6wd2{
“name”: “芙兰朵露·斯卡雷特”,
“年龄”: 400,
“gender”: “female”,
“address”: “东方红魔馆”
}
ES 服务器返回数据如下:
{
"_index": "people",
"_id": "HSW404wBlTaHOP7A6wd2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}注意:修改数据必须要指定文档 id,如果不指定的话,那么会生成一个不重复的新的文档 id,此时就是新增文档。如果想修改文档,那么必须手动指定它的 id,从而实现替换。
然后再看一下里面的 _seq_no 字段,你可以认为 ES 内部有一个全局的计数器,只要有文档发生增删改,这个计数器就会自增 1,而 _seq_no 保存了当前时刻的全局计数器的值。
我们查看一下这两个文档数据。
{
"_index": "people",
"_id": "satori",
"_version": 2,
"_seq_no": 2,
"_primary_term": 1,
"found": true,
"_source": {
"name": "古明地恋",
"age": 17,
"gender": "female",
"address": "地灵殿"
}
}{
“_index”: “people”,
“_id”: “HSW404wBlTaHOP7A6wd2“,
“_version”: 2,
“_seq_no”: 3,
“_primary_term”: 1,
“found”: true,
“_source”: {
“name”: “芙兰朵露·斯卡雷特”,
“年龄”: 400,
“gender”: “female”,
“address”: “东方红魔馆”
}
}
数据发生了变化,并且此时字段可以自由调整。如果是关系型数据库,那么数据必须和表的已有字段相匹配,我们不能给一个不存在的字段添加数据。如果真想这么做,那么必须先通过 DDL 修改表字段。
所以在 ES 中,Type 的概念已经不存在了,因为它和全局索引的设计理念是冲突的,不过 Index、Document、Field 还是可以和关系型数据库的 Database、Row、Column 对应的。
删除文档
说完了,查询、添加、修改,最后来看看删除,删除很简单,直接通过 DELETE 请求即可。
DELETE /people/_doc/satori服务器返回数据如下。
{
"_index": "people",
"_id": "satori",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}因为涉及到增删改,所以当前文档的 _version 自增 1,并且 result 为 deleted,表示删除。如果要删除的文档不存在,那么 result 字段的值就是 not_found。
注意:文档被删除后,不会立即从磁盘上移除,只是被标记成已删除(逻辑删除)。如果我们查询一个已被删除(或者不存在)的文档,会返回如下信息:
{
"_index": "people",
"_id": "satori",
"found": false
}所以在获取文档时,可以先通过 found 字段判断是否存在,如果存在,再通过 _source 字段拿到具体的文档记录。
我们总结一下,文档操作的 API。
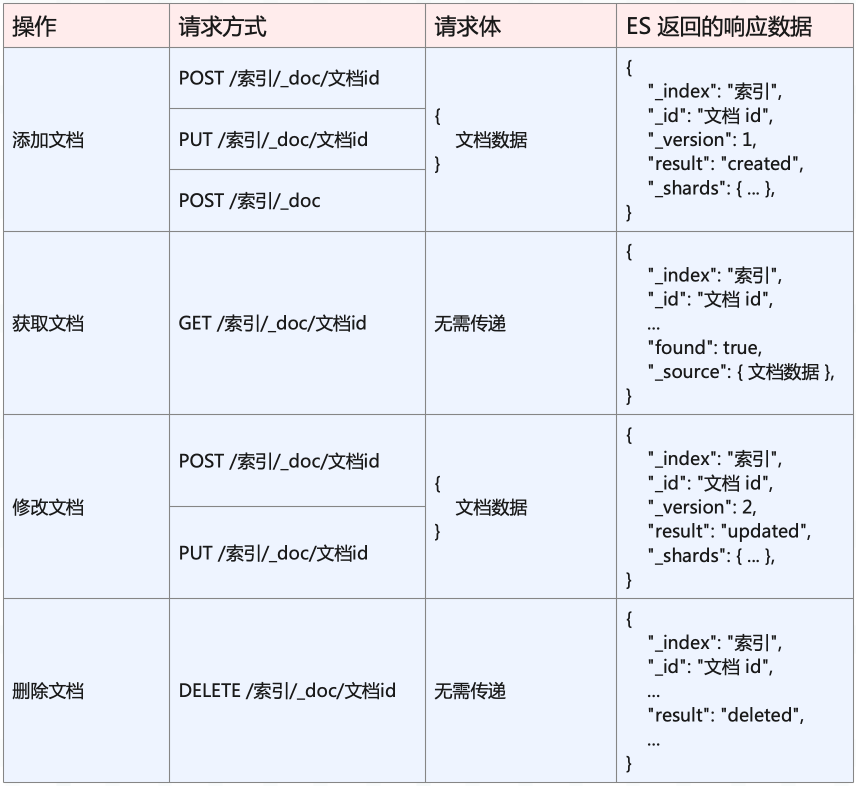
添加文档时,如果在路径参数中没有指定文档 id,即 /index/_doc,那么必须用 POST 请求,此时 ES 会自动为新增的文档生成一个不重复的 id。
如果添加文档时,在路径参数中指定了文档 id,即 /index/_doc/document_id,那么可以用 PUT 也可以用 POST,并且当指定的文档 id 已存在时,还能实现修改的效果。所以文档的新增和修改实际上用的是同一套接口,至于到底是新增还是修改,就看返回的响应中 result 字段的值是 “created” 还是 “updated”。
查询文档时,API 为 GET /index/_doc/document_id,然后通过返回响应中的 found 字段,可以判断文档是否存在。如果是 true,那么代表该文档存在,否则不存在。
最后是删除,API 为 DELETE /index/_doc/document_id,如果要删除的文档存在,那么返回响应中的 result 字段为 “deleted”,否则为 “not_found”。事实上在大部分情况下,我们并不关心删除的文档是否存在,直接删就完事了,反正文档不存在时啥事也没有。正如添加文档时,很多时候我们也不关心文档是否存在,如果存在,那么替换掉就完事了。
小结
本篇文章便简单介绍了索引以及文档的操作,当然目前都很简单,因为始终都是基于文档 id 操作单条文档。而 ES 基于 JSON 自定义了一套规则,按照这些规则,我们可以对文档进行批量操作,实现复杂的查询。
原创文章,作者:速盾高防cdn,如若转载,请注明出处:https://www.sudun.com/ask/32334.html