
我们是光大科技有限公司智能云计算部云计算团队集团云项目组,致力于光大集团IaaS平台建设与维护工作,面向集团本部及子公司提供弹性、可扩展的IaaS平台服务。我团队在云计算、虚拟化、存储领域拥有多名经验丰富的技术专家,将不定期与大家分享原创技术文章和相关实践经验,期待与大家共同探讨和进步。
前 言
随着数据不断增长以及互联网业务的兴起,业务数据呈现几何倍数的快速增长,使得企业数据中心存储系统开始面临新的挑战:新建存储系统周期长与新兴业务快速上线间的矛盾;系统庞大,管理复杂,运维人员压力巨大;存储性能无法满足越来越多的数据并行处理应用需求;客户需求分析、业务数据分析与决策推荐等需求,导致对大数据、云计算等新技术应用的需求。
什么是分布式存储
分布式存储是一种数据存储技术,简单来说,就是将数据分散存储到多个存储服务器上,并将这些分散的存储资源构成一个虚拟的存储设备,实际上数据分散地存储在服务器的各个角落。
分布式存储的出现得益于云原生应用的发展以及存储硬件的持续演进和优化。随着云计算和互联网+的发展带来了海量数据的爆发,企业亟需建设更为高效的存储系统;与此同时,以闪存为代表的新一代存储介质出现,使文件、块、对象三种形式的存储进一步融合,在此背景下,更为贴合企业用户需求的分布式存储应运而生。
分布式与集中式存储区别
集中式存储是金融业常见的存储设备,不管是SAN存储还是NAS存储,在金融行业都已使用了几十年。很多银行构建了庞大的SAN存储网络或NAS网络,并且运行稳定。近些年随着云计算技术的发展,互联网企业开始大规模使用分布式存储,分布式存储给银行传统的集中存储带来了冲击。很多金融企业面临分布式和集中式存储的选择难题。不管是集中存储还是分布式存储都有其各自的特点和使用范畴。
集中式存储:功能完善,稳定性好,运维简单,监控、运维体系健全,技术成熟,可选择的范围也很广,从中低端到高端产品齐全。不足是:单体容量有限,可扩展性较差,一次性投入大。
分布式存储:通常使用多台物理服务器,构造一个软件定义的存储,其特点是:IO吞吐量大;扩容方便;可以组成大规模的存储池;采购成本可分批次、分阶段投入,设备可以分批次折旧。但分布式存储的网络延时及稳定的性能表现不足,运维相对复杂。
当前我司构建的云计算环境中,采用集中式存储和分布式存储共存的规划设计。针对系统延时、性能稳定性要求高、有存储共享需求的业务(如数据库应用),我们建议使用集中式存储。如果系统对IO吞吐量的要求高,后续扩容需求巨大,而对性能没有极致要求,推荐使用分布式存储。对于海量非结构化数据的存储,分布式对象存储是不二的选择。
下面将结合我司目前部署的FusionStorage分布式存储,对其技术特点进行具体说明。
分布式存储逻辑架构
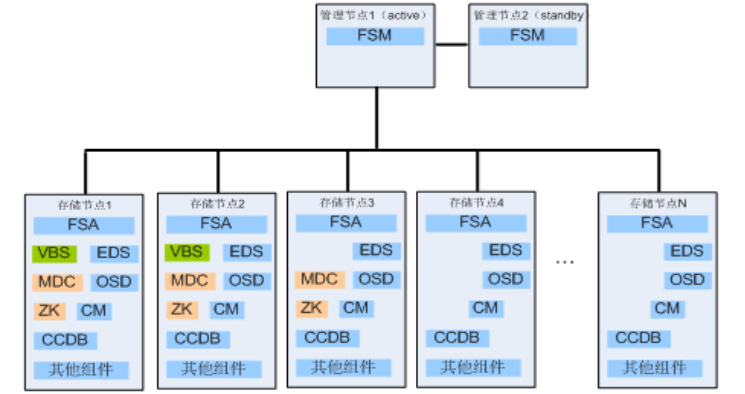
图片来源于华为官网
FusionStorage分布式存储组件介绍:
FSM:提供告警、监控、日志、配置等操作维护功能。一般部署两个,工作在主备模式下。
FSA:部署在各节点上,实现各节点与FSM通信,收集各节点的监控与告警信息或在升级本节点软件组件时接收升级包与执行升级。
MDC:元数据控制软件,实现对分布式集群的状态控制,以及控制数据分布规则、数据重建规则等。一个系统至少部署3个MDC,形成MDC集群,系统启动时由Zookeeper集群在多个MDC中选举主MDC,主MDC对其它MDC进行监控,主MDC故障时产生新的主MDC。每个资源池有一个归属MDC,当某池的归属MDC故障时,主MDC指定另外的MDC托管这个资源池,一个MDC最多管理两个资源池。MDC作为一个进程可以在每个存储节点启动,增加资源池会自动启动MDC,一个系统最多启动96个MDC。
ZK:Zookeeper缩写。一个系统需部署3、5、7等奇数个Zookeeper组成。Zookeeper集群,为MDC集群提供选主仲裁,Zookeeper至少3个,必须保证大于总数一半的Zookeeper处在活跃可访问状态。
VBS:虚拟块存储管理组件,执行卷元数据管理,VBS通过SCSI或iSCSI接口提供分布式存储接入点服务,使计算资源能够通过VBS访问分布式存储资源。
EDS:EDS组件接收到来自VBS的I/O业务之后,执行具体的I/O操作。在EDS服务里面,会执行有关快照、克隆等与块相关的特性,同时还对存储空间做管理,将块的数据与存储空间建立索引关系,确保每块数据通过索引都能找到对应的存储位置;同时在数据存储到物理空间之前,可以进行重删压缩处理。
OSD:其功能是进行数据冗余保护并持久化到存储介质中。在每个节点上部署1个OSD进程,每个OSD进程有很多实例,一块磁盘默认对应部署OSD进程里面的某个实例。
CM:集群管理软件,用于管理整个存储集群的状态信息,包括各组件的状态信息,实时监控各组件的状态,当组件出现故障时,根据组件状态触发相关措施来恢复错误。
CCDB:集群配置数据库,用于保存用户配置信息的数据库,当前在EDS组件中会采用CCDB存放配置信息。
分布式存储部署方式
分布式存储节点通过接入交换机(TOR)接入数据中心网络,并根据计算与存储的部署关系,分为分离部署与融合部署两种形态。计算与存储的分离部署方式,即虚拟机与分布式存储部署在不同的服务器上。融合部署方式,即虚拟机与分布式存储部署在同一台服务器上。两种部署方式主要特点如下:
|
指标 |
融合部署方式 |
分离部署方式 |
|
可靠性 |
中等,存储与计算绑定,风险相对较集中,随着集群规模不断扩展大,系统复杂性不断提高,可靠性下降。 |
较高,存储与计算独立,两者的故障互不影响。 |
|
性能 |
中等,计算业务与存储业务共享资源,并且同时占用网络带宽,适用于性能要求不高的场景。 |
较高,所有资源都提供给存储资源使用,不存在资源争抢情况。 |
|
易管理性 |
安装简单,存储与计算同时管理和部署,简化了管理人员的操作,可维护性高。 |
只提供存储管理,需要额外的计算资源的管理,增加了管理工作量。故障排查较为清晰。 |
|
扩展性 |
计算和存储节点同步扩展,无需分别进行计算和存储的资源规划。 |
存储资源单独扩展,可以实现计算与存储的灵活配比。 |
|
弹性 |
计算与存储的配比固定,受限于虚拟化软件或者存储软件其中之一的规格。 |
计算与存储的配比可以根据业务场景的需求自行调配,灵活程度高。 |
|
成本 |
采购成本相对较低,机柜空间占用较少。 |
计算和存储需分开采购,成本相对较高,并需要占用更多的机柜空间。 |
|
适合场景 |
面向业务负载较低的场景,并且业务种类和配比比较固定,系统规模小。 |
面向高弹性和高负载业务,可以支撑多种类型差异较大的业务,系统规模较大的存储池。 |
① 计算和存储分离部署
分离部署方式,即将虚拟机与FusionStorage存储部署在不同的服务器上。分离部署采用存储前后端网络共用组网,组网架构如下图所示:
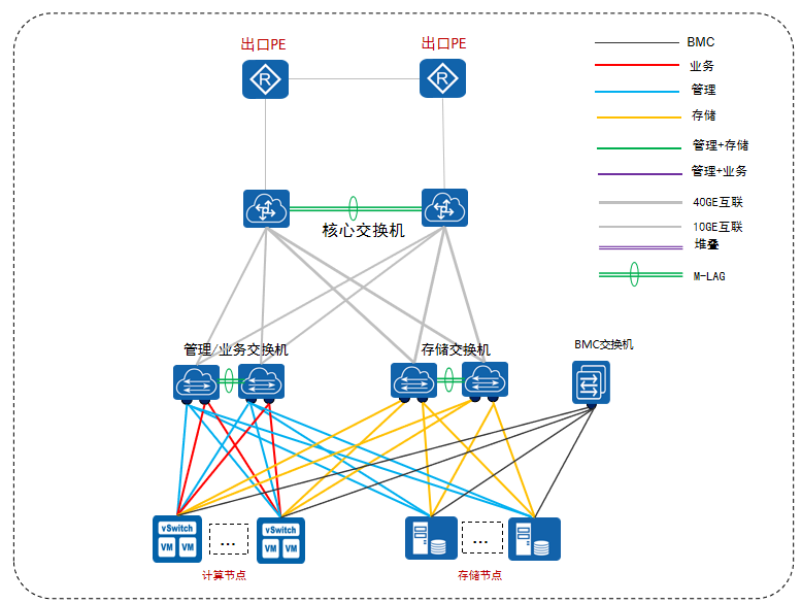

10GE组网架构说明:
1.存储前后端共用组网:存储服务器配置2块双端口10GE网卡。存储前端网卡与管理网络共用其中一块网卡用作存储,另一块网卡用作管理。
2.计算节点采用独立网卡,存储平面单独使用一块网卡,业务与管理平面共用网卡。
3.服务器的BMC网卡连接到GE交换机,用作设备带外管理。
4.10GE接入交换机为堆叠方式,上行到核心交换机。
5.服务器的10GE网口配置为双网卡绑定。

② 计算和存储融合部署
融合部署方式,即将虚拟机与FusionStorage存储部署在同一台服务器上,至少需要部署3台存储服务器。融合部署采用存储前后端网络共用组网,组网架构如下图所示:
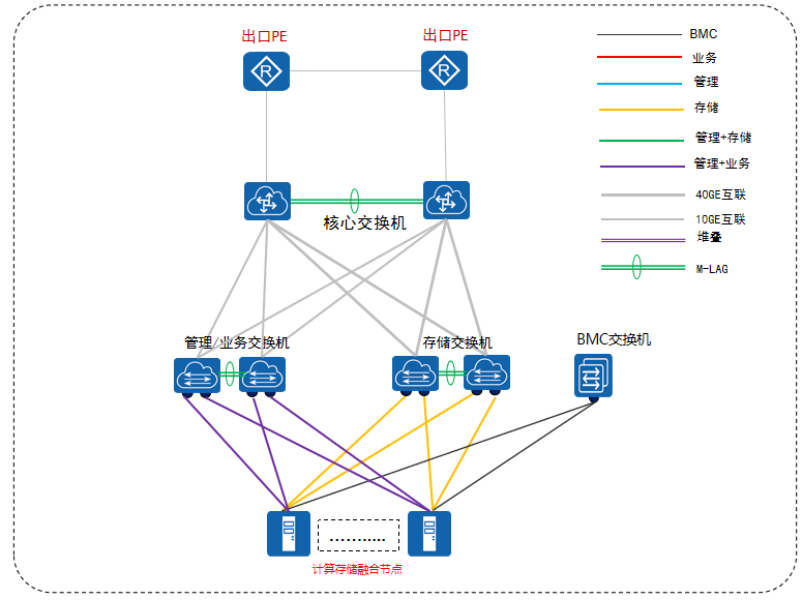
10GE组网架构说明:
1.存储前后端共用组网:服务器默认配置2块双端口10GE网卡,1块网卡用作存储,另一块网卡用作业务和管理。
2.存储必须使用独立的物理网口,不能与其它平面共享物理网口。
3.服务器的BMC网卡连接到GE交换机,用作设备带外管理。
4.10GE接入交换机配置为堆叠方式,上行到核心交换机。
5.服务器的10GE网口配置为双网卡绑定。
分布式存储关键技术原理
① 什么是多副本
分布式存储可采用数据多副本备份机制来保证数据的可靠性,即同一份数据可以复制保存为2~3个副本。针对系统中的每1个卷,默认按照4MB进行分片,分片后的数据按照DHT算法保存集群节点上。
如下图所示,对于节点Server1的磁盘Disk1上的数据块P1,它的数据备份为节点Server2的磁盘Disk2上P1’,P1和P1’构成了同一个数据块的两个副本。例如,当P1所在的硬盘故障时,P1’可以继续提供存储服务。
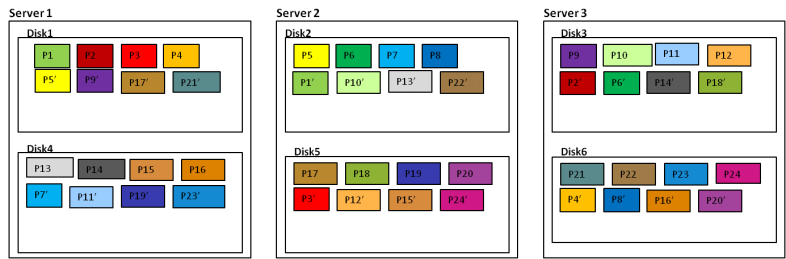
图片来源于华为官网
② 什么是纠删码
分布式存储也可以采用纠删码(Erasure Coding,简称EC)方式来保证数据的可靠性。相对三副本,EC数据冗余保护机制在提供高可靠性的同时也能够提供更高的磁盘利用率。
基于EC的分布式存储的数据保护技术,是建立在分布式、节点间冗余的基础上的。数据进入系统之后,首先被切分为N个数据条带,然后计算出M个冗余数据条带,并最终保存在N+M个不同的节点中。
如下图所示:
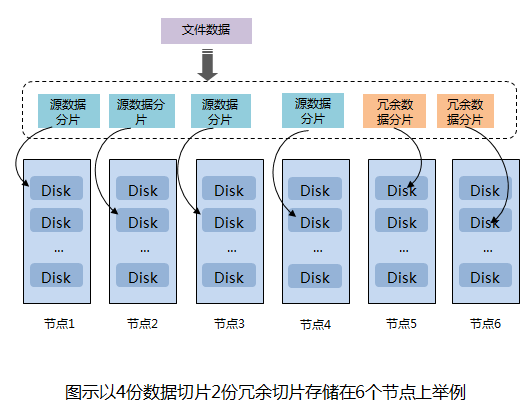
图片来源于华为官网
弹性EC是一种增强型数据冗余保护机制,广泛应用于分布式存储领域。EC在分布式存储系统中使用N个数据块和M个校验块保证数据的可靠性,这N+M个数据块中有任意M个块数据损坏,都可以通过其他N个块上的数据恢复M个块的数据。
相比于副本存储方式,EC数据冗余保护机制在提供高可靠性的同时也能够提供更高的硬盘利用率,从而降低成本。比如一个4M的IO,在三副本存储方式下,共占有12M的硬盘空间,而在4+2配比的EC存储方式下,4个数据节点每个占用1M空间,2个校验节点各占用1M空间,共6M空间,在提供相同可靠性的前提下,EC比三副本节省了6M硬盘空间。
按照华为官方测试数据来看,EC的性能通常比副本的性能高15%左右,在高比例EC配比中,最大能支持到22+2、20+3和20+4三种最大配比。
③ 怎么实现数据路由
分布式存储为支持大规模横向扩展和弹性伸缩,分为两级映射机制:
1)由VBS模块通过LUNID和LBA计算哈希值,将卷空间按1 MB大小映射到具体的节点上,完成数据的处理;
2)由OSD模块的PLOG通过PlogID和Offset计算哈希值,确定数据存放在硬盘的具体位置。
具体流程如下图所示:
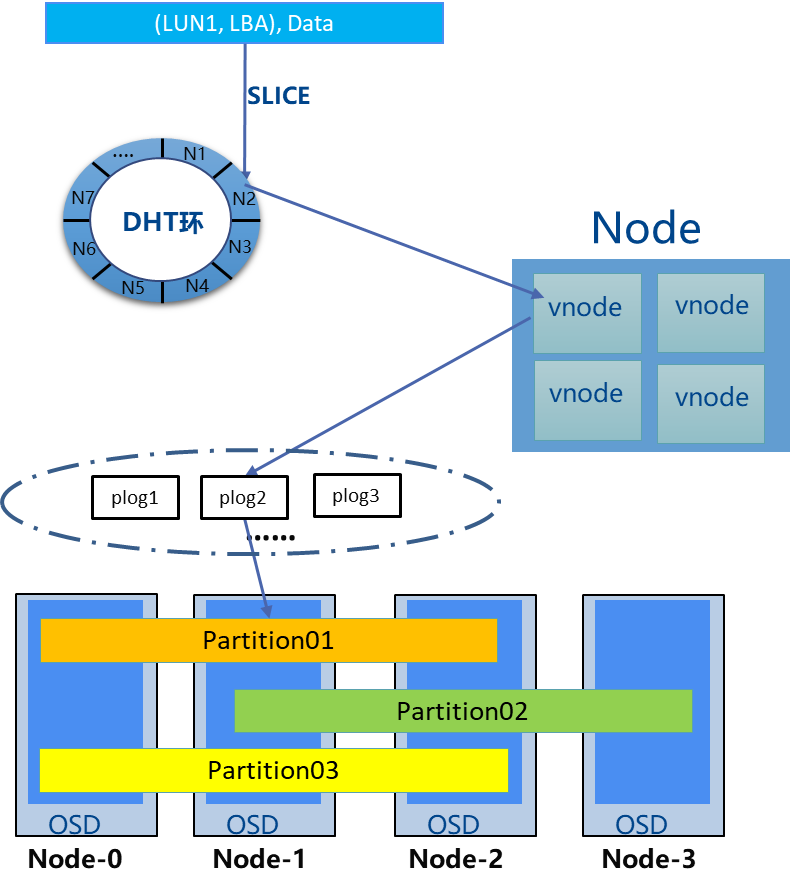
第一层DHT hash环的目的是通过hash算法将数据分发到计算出来的存储服务器节点处理该数据,通过该hash算法,确保每个数据都有对应的服务器节点来处理,保证了业务处理的均衡。系统根据LUNID和LBA定位到服务器节点,然后再定位到该服务器上的vnode上,由该vnode逻辑处理单元来处理该数据。通过vnode机制,可以确保故障节点的业务可以分散到不同的服务器节点上去接管,就可以防止只用一个物理服务器接管带来的业务处理瓶颈问题。
第二层DHT hash环的目的是通过hash算法将数据转到对应存储空间去保存,完成数据的持久化。通过该hash算法,确保数据存储空间的均衡性。系统根据PlogID和Offset定位到硬盘应该存放的具体位置,避免在海量数据中进行查找和计算,该DHT路由技术,不仅能保证数据在各个硬盘的均衡性,而且在硬件增减(故障或扩容)时,自动快速调整,并保证数据迁移的有效性,确保自动快速自愈,自动资源均衡。
④ 读IO流程是怎样的
分布式存储系统中的读IO流程(EC)示意图如下:
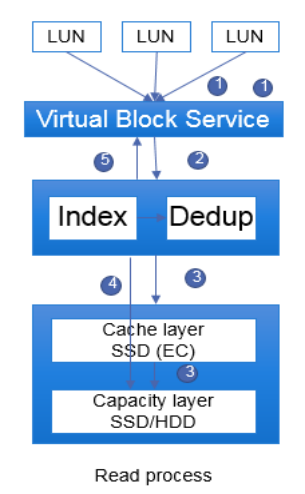
图片来源于华为官网
1、上层应用下发读IO请求到存储服务,存储服务的VBS模块收到该IO请求,根据第一层的DHT hash算法将数据转到指定服务器。
2、服务器上的EDS(Index+Dedup)模块处理该数据。EDS接收到读IO请求后,优先在内存的写缓存中查找,如果找到就返回给VBS。
3、 如果内存写缓存中没有命中,则再在内存读缓存中去查找,如果仍然没有找到,则到存储介质中去读,先在SSD Cache中去读,如果还不命中,则到存储介质中去读(详细见Read Cache章节说明)。
⑤ 写IO流程是怎样的
分布式存储系统中的写IO(EC)流程示意图如下:
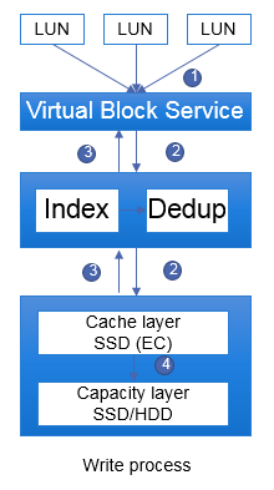
图片来源于华为官网
上层应用下发写IO请求到存储服务,存储服务的VBS模块收到该IO请求(图中①),根据第一层的DHT hash算法将数据转到指定服务器;由这个服务器上的EDS(Index+Dedup)模块处理该数据(图中②上);
EDS接收到写IO请求后,以小比例EC形式写入Cache Layer层的SSD缓存盘上(图中②下),同时该EDS所在服务器的内存中仍然保持一份该数据,EDS返回写IO成功给VBS(图中③),再由VBS返回给上层应用。待内存中的数据聚合到更大的块,走刷盘流程异步刷入(图中④)到Capacity Layer的存储介质中。
⑥ SSD Cache如何加速
传统的HDD受机械原理的影响,虽然在容量上有比较大的增长,但在性能方面,几十年来基本上没有任何变化,随机I/O时延从几毫秒到十几毫秒,严重影响用户体验和性能的发挥。而SSD虽然相对于HDD有很大的提升,但是价格比较贵。目前业界使用SSD作为系统Cache或Tier层,实现了性能和成本之间的平衡。
分布式存储中SSD Cache在功能上分为两个部分:
第一个部分通常为主机业务服务,即主机的Write I/O通过此部分用来确保数据临时持久化,不会因掉电导致数据丢失,对于这部分的Cache,通常称为WAL Cache;
第二个部分通常是作为主存机械盘的缓存区域,确保数据在进入HDD机械盘之前,先通过这个部分的Cache将数据缓存住,这样IO不需要到达机械盘,从而降低了时延,对于这部分的Cache,通常称之为Disk Cache。
逻辑架构图如下:
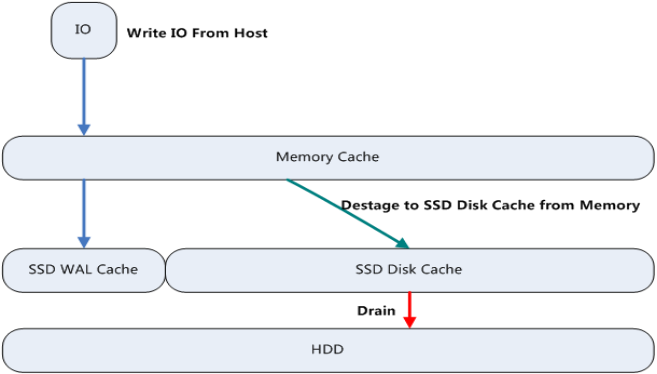
图片来源于华为官网
通常SSD WAL Cache和SSD Disk Cache这两部分的Cache通常是由一个SSD盘/卡逻辑上划分出的两个区域。
Write Cache
VBS发送的写IO操作(图中Write IO From Host)时,会将Write IO在Memory Write Cache内存中保存一份,同时同步以日志的方式(采用固定的2+2小分片EC)记录到SSD WAL Cache中并返回成功完成本次写操作,这个流程通常称为Host Write IO流程。
通常SSD Disk Cache分为两个部分:SSD Write Cache和SSD Read Cache。Memory Write Cache中的数据会进行IO排序重整并等待满分条以副本或EC的方式直接写入到SSD Write Cache中并返回;对于大块IO则直接由Memory Write Cache直通写到HDD中,而不驻留在SSD Write Cache里;
当SSD Write Cache中的保存数据水位达到一定阈值时,则由SSD Write Cache往HDD中迁移。
随着Memory Write Cache中的数据逐步刷盘到SSD Write Cache时,SSD WAL Cache中的数据将逐步淘汰掉,通常会进行异步的垃圾回收。
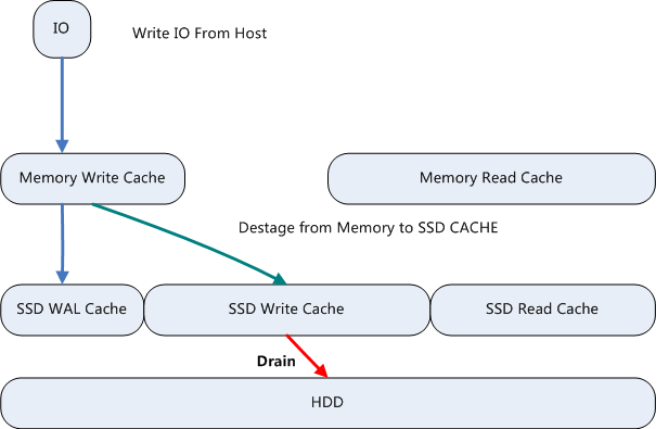
图片来源于华为官网
Read Cache
分布式存储的读缓存采用分层机制。第一层为内存Cache,内存Cache采用LRU机制缓存数据; 第二层为SSD Cache,SSD Cache采用热点读机制,系统会统计每个读取的数据,并统计热点访问因子,当达到阈值时,系统会自动缓存数据到SSD中,同时会将长时间未被访问的数据移出SSD。
EDS在收到VBS发送的读I/O操作时,会进行如下步骤处理:
Step 1:从内存“Memory Write Cache”中查找是否存在所需I/O数据,如果存在,则直接返回,同时调整该IO数据到“读Cache”LRU队首,否则执行Step 2;
Step 2:从内存“Memory Read Cache”中查找是否存在所需IO数据,如果存在,则直接返回,同时增加该IO数据的热点访问因子,否则执行Step 3;
Step 3:读请求发到OSD,OSD先从SSD的“SSD Write Cache”中查找是否存在所需IO数据,如果存在,则直接返回,如果不存在,执行Step 4;
Step 4:从SSD的“SSD Read Cache”中查找是否存在所需IO数据,如果存在,则直接返回,同时增加该IO数据的热点访问因子;如果热点访问因子达到阈值,则会被缓存在SSD的“SSD Read Cache”中,如果不存在,执行Step 5;
Step 5:从硬盘中查找到所需IO数据并返回,同时增加该IO数据的热点访问因子,如果热点访问因子达到阈值,则会被缓存在SSD的“SSD Read Cache”中。
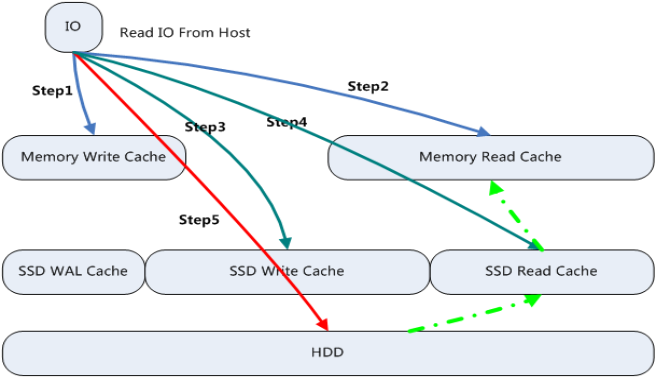
图片来源于华为官网
分布式存储功能特点
① 多种存储服务
FusionStorage通过系统软件将通用硬件的本地存储资源组织起来构建全分布式存储池,实现了向上层应用提供分布式块存储、分布式对象存储、大数据存储或分布式文件存储等多种存储服务。
② 精简配置
支持精简配置功能,为应用提供比实际物理存储更多的虚拟存储资源。相比直接分配物理存储资源,可以显著提高存储空间利用率。
③ 重删压缩
采用自适应重删技术,在用户数据处理负载较高的情况下,前重删会自动关闭,优先确保性能,由后处理完成数据缩减。在负载较低的情况下自动开启前重删,避免了后处理的读写放大。
④ 数据加密
支持数据加密特性,通过配置加密盘和内置密管,和存储系统配合完成静态数据加密,从而保证数据的安全性。
⑤ QoS
QoS支持基于卷或池设置性能目标,支持按带宽和IOPS进行配置最大性能目标,可分别限定读写总性能、读性能和写性能;定时策略可以基于业务繁忙情况设置并发生作用,避免各种IO风暴影响生产业务。
⑥ 快照
提供秒级快照机制,将用户的卷数据在某个时间点的状态保存下来,后续可以作为导出数据、恢复数据之用。快照数据在存储时采用ROW(Redirect-On-Write)机制,快照不会引起原卷性能下降。
⑦ 克隆
提供链接克隆机制,支持基于一个卷快照创建出多个克隆卷,各个克隆卷刚创建出来时的数据内容与卷快照中的数据内容一致,后续对于克隆卷的修改不会影响到原始的快照和其他克隆卷。
⑧ 异步复制
异步远程复制架构是基于两套存储集群构建异步复制关系,基于差异数据,周期性的同步主、从卷的数据,上一次同步周期数据同步完成后,到当前同步周期开始,主卷上产生的所有数据会在本次同步时写到从卷上。
⑨ Active-Active双活
基于AB两个数据中心的两套分布式存储集群构建双活容灾关系,两套存储的卷虚拟出一个双活卷,两数据中心业务的主机能同时对卷进行读写。任意数据中心故障,数据零丢失,业务能自动切换到另外一个站点运行,做到RP0=0,RTO≈0,保证业务连续性。
分布式存储展望
随着数字化转型的进程不断推进,企业逐步深刻认识数据资源对数字化转型的重要意义,促使相关的数据工具技术也不断的迭代和更新。分布式存储在未来将以更高的性能、更好的灵活性和开放性、更强的扩展性,实现更便捷的管理、更简单的运维以及更少的投入,帮助企业在数据治理过程中更好的进行企业数据的管理和保护。当然在很长一段时间内,传统集中式存储在低延时、高性能、高稳定性等核心应用场景方面的优势,仍会得到延续和应用。
作者:周琼杰
往期回顾
HTTP2如何颠覆HTTP1.1苦心经营的一切
基于机器学习的文本情感极性分析问题
初识日志管理系统
IT设备部署及上架
公众号:EBCloud
赶快扫码关注吧!
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/32418.html