

常见的数据冗余保护机制
我们知道在集中式存储中可以将一台服务器的磁盘组成RAID阵列,通过镜像冗余(RAID1)或者校验冗余(RAID5、RAID6)的方式对磁盘上的数据进行冗余保护。其中,RAID1至少需要两块磁盘,同一份数据将被同时复制到组成RAID的每块磁盘中,该级别的RAID只要有一块磁盘可用,即可正常工作。RAID1可以提供磁盘级保护。RAID5和RAID6都是数据块级校验条带存储,多块磁盘组合成RAID5或RAID6后,数据将以块(block)为单位同步式分别存储到不同的磁盘上,并对数据块进行海明码运算得到校验块,校验块也会被同时写入不同的磁盘。RAID5和RAID6也可以为数据提供磁盘级保护。
类似地,在FusionStorage中有多副本冗余和EC纠删码冗余两种数据保护机制。不同的是,分布式存储中的数据冗余机制是可以跨节点甚至跨机柜的,以提供服务器级安全或者机柜级安全。集中式存储架构中组成RAID阵列的磁盘来源于单个节点,虽然可以允许一定数量的磁盘损坏,但是当整个节点发生故障时,无法有效恢复数据。而FusionStorage多副本EC纠删码机制所提供的跨节点或跨机柜冗余均可以有效应对节点故障。
FusionStorage中的多副本技术
顾名思义,多副本就是通过数据保护软件为一份数据保存多份相同的副本以应对可能发生的数据丢失或损坏的风险。FusionStorage中的多副本是通过将相同的数据在不同的节点上存储多份来实现数据保护的一种技术,支持三副本和两副本,推荐三副本。以三副本为例,如果将三个副本存储于不同的节点的不同磁盘中,同时故障两个节点或磁盘,系统仍可正常读写数据,业务不中断,数据不丢失,实现服务器级冗余;如果将三个副本存储于不同机柜的不同节点中,同时故障两个机柜、节点或磁盘,系统仍可正常读写数据,业务不中断,数据不丢失,实现机柜级冗余。
1.多副本机制下的数据读写原理
”
写原理:
在FusionStorage中,数据Data会被拷贝成3份相同的副本,分别存储于不同的节点的不同磁盘中,如图1所示。
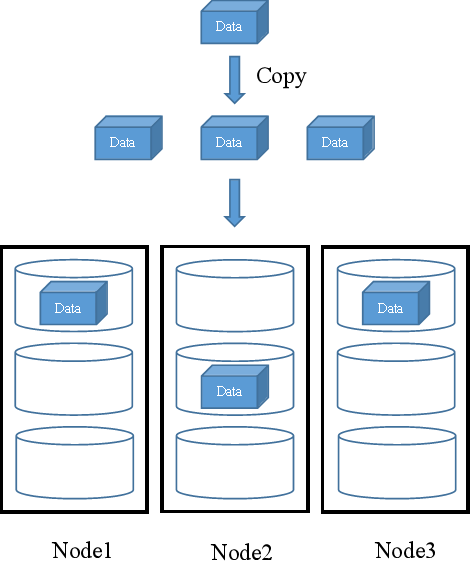
图1 多副本机制下的数据写
读原理:
在FusionStorage中,需要读取数据Data时,可以从存放Data副本的三个节点中的任意一个节点读取,也可以同时从三个节点中进行读取,如图2所示。
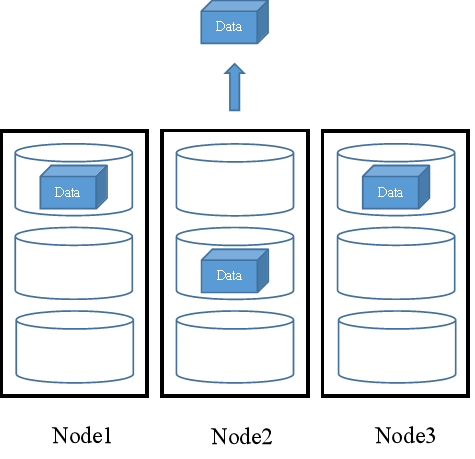
图2 多副本机制下的数据读
故障场景时写原理:
多副本机制下如果发生节点故障,例如,Node3发生节点故障,FusionStorage将在剩余的两个节点中存储副本。如图3所示。
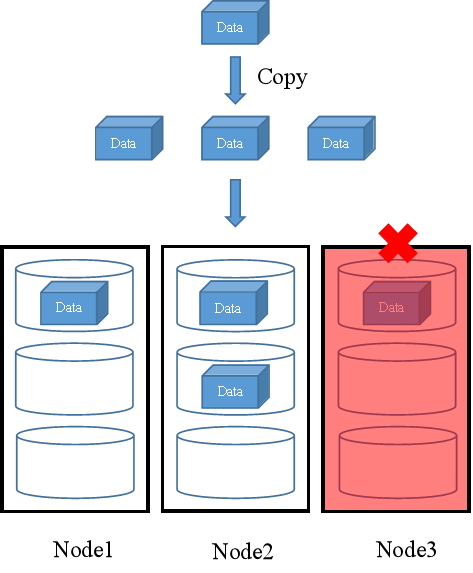
图3 故障场景时数据写
故障场景时读原理:
当Node3发生节点故障,FusionStorage将在剩余的两个节点中读取一个副本返回给用户。如图4所示。
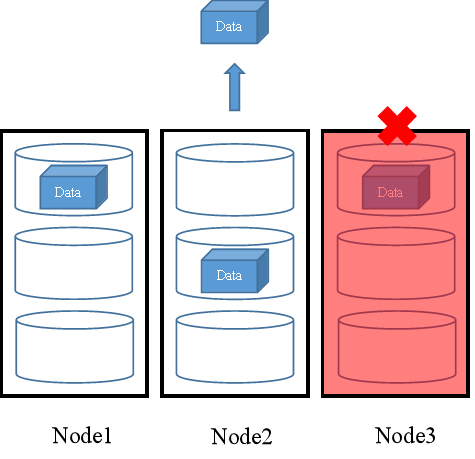
图4 故障场景数据读
2.故障场景时多副本数据重构
”
多副本机制下,当发生节点或硬盘故障后,FusionStorage将读取其他正常磁盘的数据,通过拷贝的方式直接将数据重建至新的磁盘中。如图5所示,节点3发生故障,该节点上的所有数据副本丢失,FusionStorage会读取其他正常磁盘中的数据副本,并拷贝一份将数据重建至新的磁盘。
重构策略上,会根据硬盘故障或节点故障的具体场景有所不同:
-
当硬盘发生故障时,存储池等待15分钟后启动数据重构。
-
当节点发生故障时,存储池还存在冗余保护时,延迟7天启动数据重构;当存储池不存在冗余保护时,延迟24小时启动数据重构。
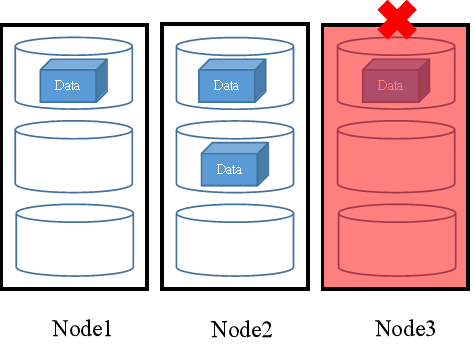
图5 故障场景时多副本数据重构
FusionStorage中的EC纠删码技术
Erasure Coding(简称EC,即纠删码)是一种冗余保护机制,通过计算校验片的方式实现数据冗余保护。在FusionStorage中,数据会被切分为固定大小的数据块,每N个连续的数据块通过EC编码算法计算得到M个校验块,其中N为偶数,M取值2、3或4,N≥M。
EC冗余方式的空间利用率约为N/(N+M),N越大,空间利用率越高,数据的可靠性由M值的大小决定,M越大可靠性越高。
如果将N个数据块和M个校验块存储于不同节点的不同磁盘中,则最多可同时故障M个节点或M块硬盘,系统仍可正常读写数据,业务不中断,数据不丢失,实现服务器级安全;如果将N个数据块和M个校验块存储于不同机柜的不同节点中,则最多可同时故障M个机柜、不同机柜的M个节点或M块硬盘,系统仍可正常读写数据,业务不中断,数据不丢失,实现机柜级安全。机柜级安全和服务器级安全的原理类似,本文将以服务器级安全为例介绍EC纠删码在FusionStorage中的应用原理。
1.EC纠删码机制下的数据读写原理
”
在FusionStorage中,采用不同的冗余配比方式,EC纠删码机制下的数据读写原理也有所不同。EC冗余配比有两种方式,分别是N+M冗余配比和N+M:1冗余配比。在服务器级安全下,N+M冗余配比指的是将N个数据块和M个校验块随机存储于不同节点的不同磁盘中(因为存储节点的个数大于N+M,基于可靠性的考虑,数据块将被存储于不重复的节点),此时存储池允许故障M个节点或M块磁盘。同样,在服务器级安全下,N+M:1(折叠)冗余配比指的是将N个数据块和M个校验块随机打散存放于所有节点,每个节点都可能存在存放M个分片的情况,此时存储池允许故障1个节点或M块硬盘。而具体采用的EC冗余配比方式由存储节点和N+M值的数量关系决定。当存储节点的数量≥N+M时采用N+M冗余配比,当(N+M)/M≤存储节点的数量<N+M时采用N+M:1冗余配比。
当采用N+M冗余配比时的数据读写原理
写原理:
N+M冗余配比要求存储节点的数量大于等于N+M值,当进行数据写入时,FusionStorage会将N个数据块和M个校验块随机存储于不同节点的不同磁盘中。此处我们以存储节点数量=7、N=4、M=2为例。当用户写入数据Data时,假设数据Data被切分为4个数据块(D1~D4),同时通过EC编码算法计算得到2个校验块(C1~C2),FusionStorage会将这6个分片随机存入6个节点的不同磁盘中。如图6所示。
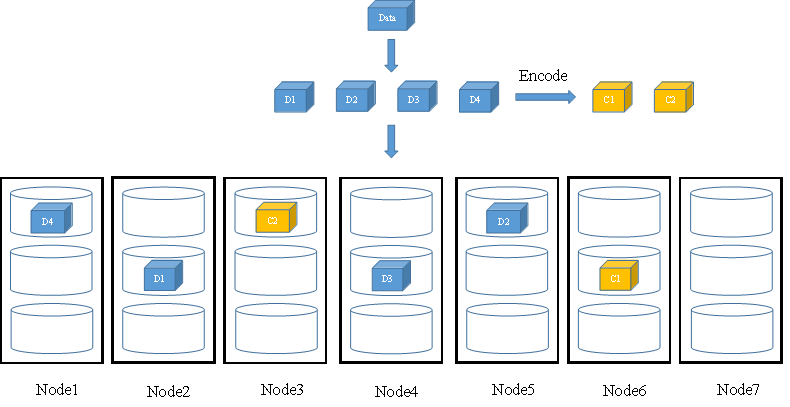
图6 N+M冗余配比数据写
读原理:
当用户进行数据读取时,FusionStorage会从节点中读取数据块,并通过Copy的方式将所有数据块拼装成需要读取的数据。如图7所示,FusionStorage会从所有存放了Data数据块的4个节点的不同硬盘中读取数据块(D1~D4),并通过Copy的方式将这4个数据块拼装成Data返回给用户。
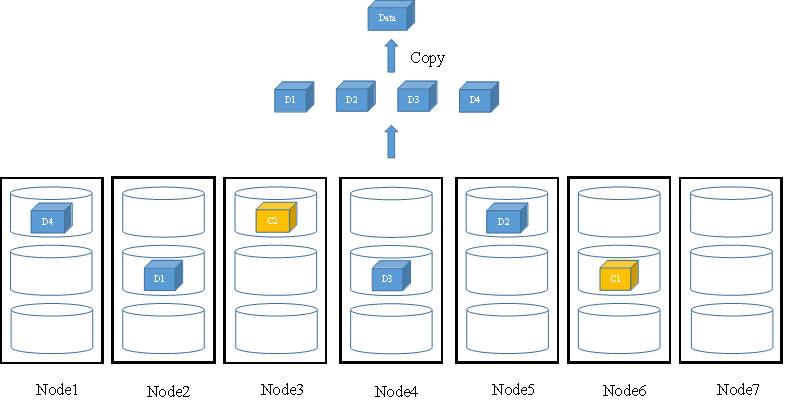
图7 N+M冗余配比数据读
故障场景时写原理:
当发生节点故障时,如果故障后剩余存储节点的数量依然大于等于N+M的值,FusionStorage会重新分配一个新节点组成N+M冗余,以保证数据可靠级别不降低。如图8所示,当节点6故障后,剩余的6个节点依然满足大于等于4+2的要求,FusionStorage将会分配节点7存放Data1的校验块C1。
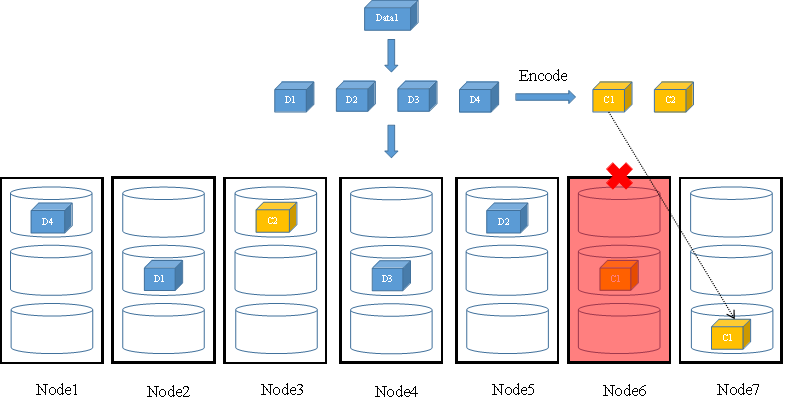
图8 N+M冗余配比故障场景时数据写(1)
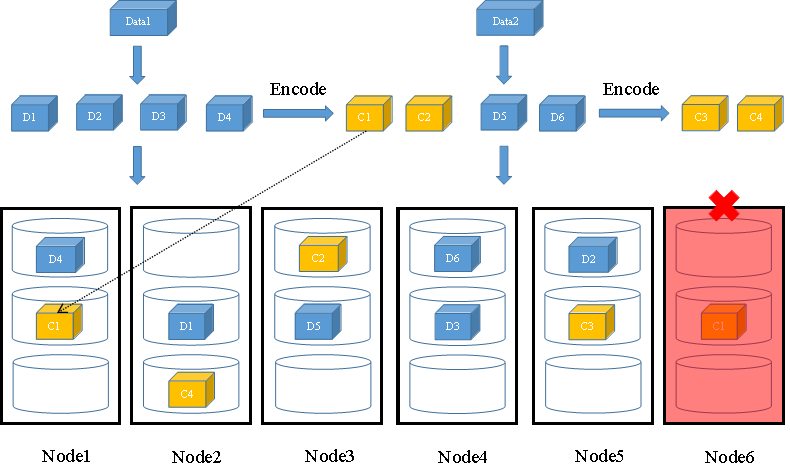
图9 N+M冗余配比故障场景时数据写(2)
如果故障后剩余存储节点的数量小于N+M的值,在故障恢复前FusionStorage会将新写入的数据缩列为N/2+M,以保证IO不中断的同时可靠级别不降低(可允许同时故障的磁盘数量不变,依然为M的值),故障恢复后,FusionStorage冗余配比恢复为N+M。此例中,假设节点数量改为6,故障一个节点后节点的数量不满足大于等于4+2的要求,此时FusionStorage会将新写入的数据Data2缩列为2+2冗余配比,保证了数据可靠级别不变。如图9所示,数据块D5和D6以及校验块C3和C4会被存储在不同节点的不同磁盘上。
故障场景时读原理:
当在保护级别内发生存储节点故障或磁盘故障时,FusionStorage会读取任意N个数据(数据块或校验块),并通过EC算法解码计算恢复出数据。如图10所示,假设此时有6个存储节点,其中节点5和节点6发生节点故障,无法读取数据块D2和校验块C1,FusionStorage会从其他4个正常节点中读取D1、D3、D4和C2,并通过解码计算出数据Data返回给用户。
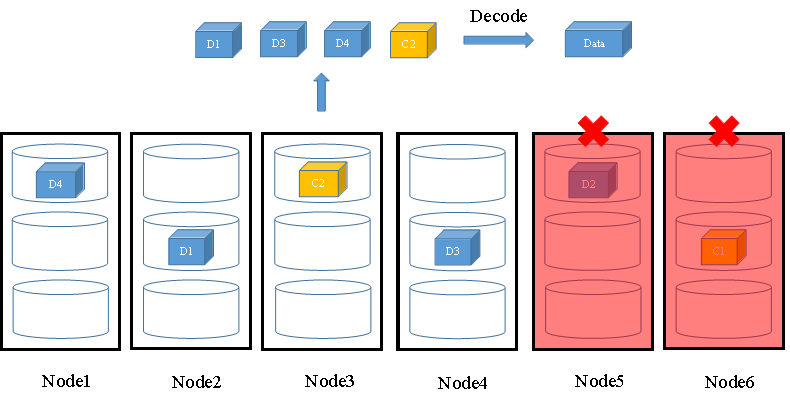
图10 N+M冗余配比故障场景时数据读
当采用N+M:1冗余配比时的数据读写原理
写原理:
N+M:1冗余配比要求存储节点的数量大于等于(N+M)/M的值,同时小于N+M的值,当进行数据写入时,FusionStorage会将N个数据块和M个校验块随机打散存放于所有节点,每个节点都存在存放M个分片的情况。此处我们以存储节点数量=5、N=4、M=2为例。当用户写入数据Data时,假设数据Data同样被切分为4个数据块(D1~D4),同时通过EC编码算法计算得到2个校验块(C1~C2),FusionStorage会将这6个分片随机打散存入所有5个节点的不同磁盘中。如图11所示。
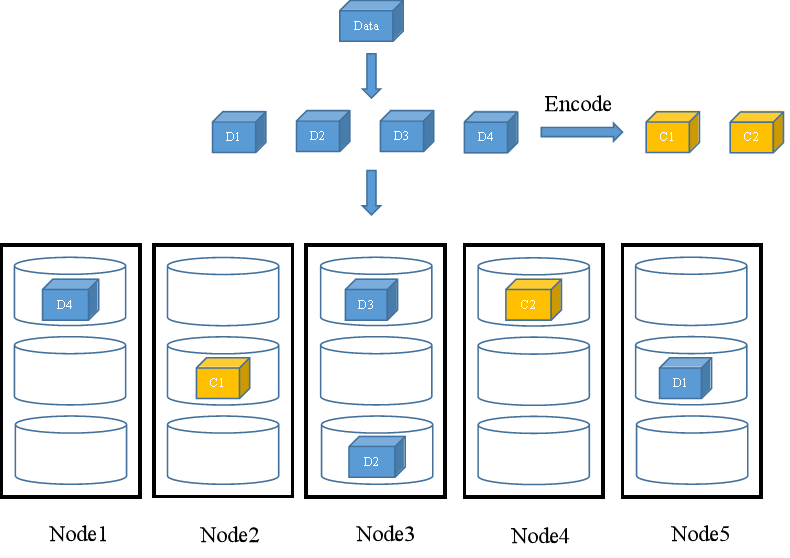
图11 N+M:1冗余配比数据写
前面我们提到,对于N+M:1冗余配比的方式可以允许同时故障M块磁盘或故障一个节点。这是因为在N+M:1冗余配比的方式中,每个节点都可能存在存放M个分片的情况。上图中节点3中就存放了2个数据块,如果节点3和其他任意一个节点同时发生了节点故障,故障分片的数量将会达到3个,超过了允许故障分片的个数,无法通过EC算法计算出需要读取的数据。实际生产中每个存储节点都可能存在存放M个分片的情况,因此只允许故障一个节点。
读原理:
当用户进行数据读取时,FusionStorage会从节点中读取数据块,并通过Copy的方式将所有数据块拼装成需要读取的数据。如图12所示,FusionStorage会从所有存放了Data数据块的3个节点中读取数据块(D1~D4),然后拼装成数据Data返回给用户。
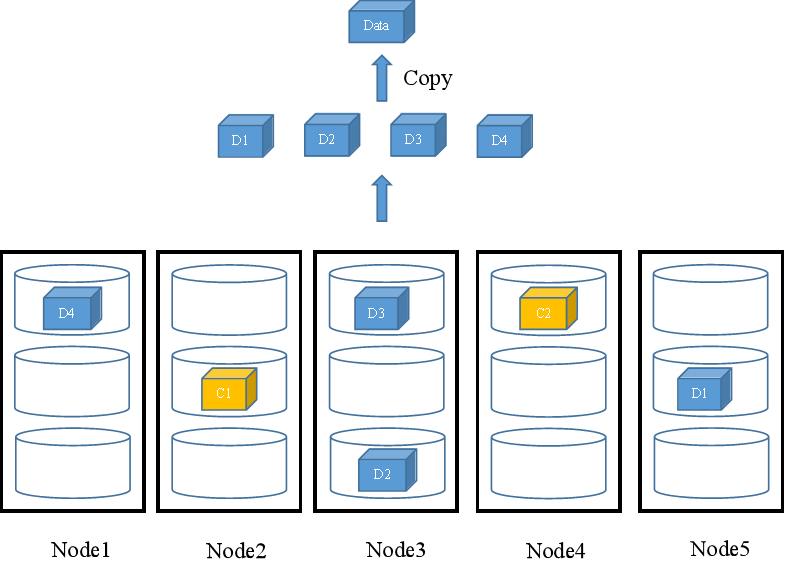
图12 N+M:1冗余配比数据读
故障场景时写原理:
对于采用了N+M:1冗余配比方式的存储池,当故障一个节点或不多于M块磁盘后,FusionStorage仍然会将N个数据块和M个校验块写入所有正常节点中。
故障场景时读原理:
当发生一个存储节点故障或不多于M块磁盘故障时,FusionStorage会读取任意N个数据(数据块或校验块),并通过EC算法解码计算恢复出数据。如图13所示,节点3发生故障,无法读取该节点的数据块D2、D3,FusionStorage会从其他正常节点读取4个数据D4、D1、C1和C2,并通过解码计算得到数据Data返回给用户。
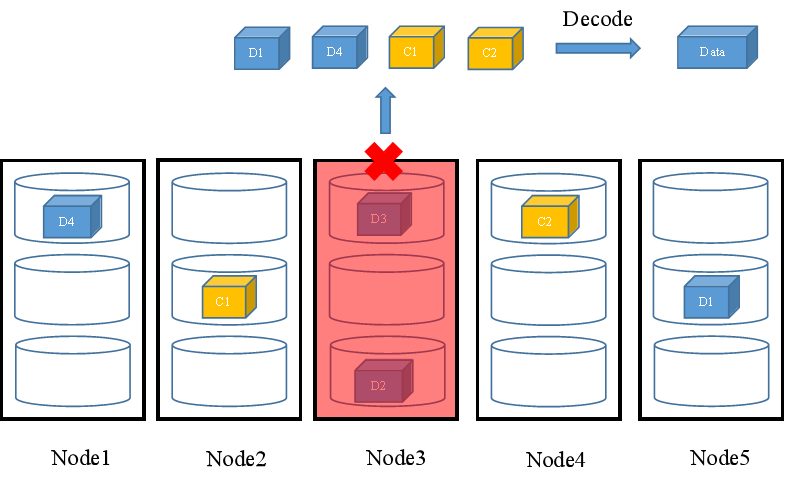
图13 N+M:1冗余配比故障场景数据读
2.故障场景时EC数据重构
”
FusionStorage存储池发生节点故障或磁盘故障后,分布式存储系统将从其他正常磁盘读取N个数据,通过EC算法解码计算得到故障磁盘的数据并将其存放到其他正常磁盘中。如图14所示,节点6发生故障,数据块D2丢失,FusionStorage从其他正常磁盘中读取D1、D3、D4和C1进行解码计算得到数据块D2的数据,整个故障磁盘和整个节点的数据都可以通过EC解码进行恢复。
重构策略上,会根据硬盘故障或节点故障的具体场景有所不同:
-
当硬盘发生故障时,存储池等待15分钟后启动数据重构。
-
当节点发生故障时,存储池还存在冗余保护时,延迟7天启动数据重构;当存储池不存在冗余保护时,延迟24小时启动数据重构。
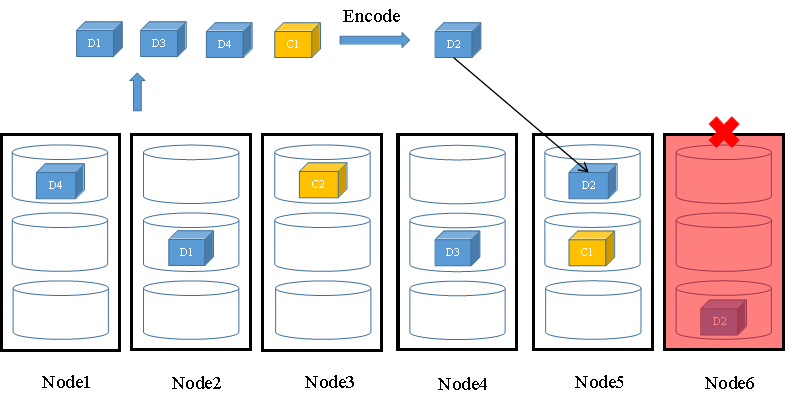
图14 故障场景时EC数据重构
3.EC纠删码中的数学计算
”
前面我们提到数据写入时的编码、故障场景下读取数据后的解码以及数据重构都需要进行EC纠删码算法计算,EC纠删码是最早应用于通信领域的一种前向纠错码,用于解决数据传输过程中的损耗问题,后广泛应用于分布式存储领域。EC纠删码有多种分类,如阵列码、里德-所罗门码( Reed-Solomon Code,简称RS码)和低密度奇偶校验码( Low Density Parity Check Code ,简称LDPC码)。其中,在分布式存储领域最常用的EC纠删码一般都是基于RS码的实现和优化。
为了方便描述,我们将需要写入的数据表示为矩阵的形式,如图15所示,矩阵D即需要写入的数据,矩阵B为编码矩阵,编码矩阵需要满足任意n阶子阵可逆。为了方便数据存储,编码矩阵上部都是n阶单位阵,下部为m*n阶矩阵(m对应FusionStorage中校验块的数量M),一般选用范德蒙德矩阵或柯西矩阵。最右侧的矩阵D+C为实际落盘存储的数据。
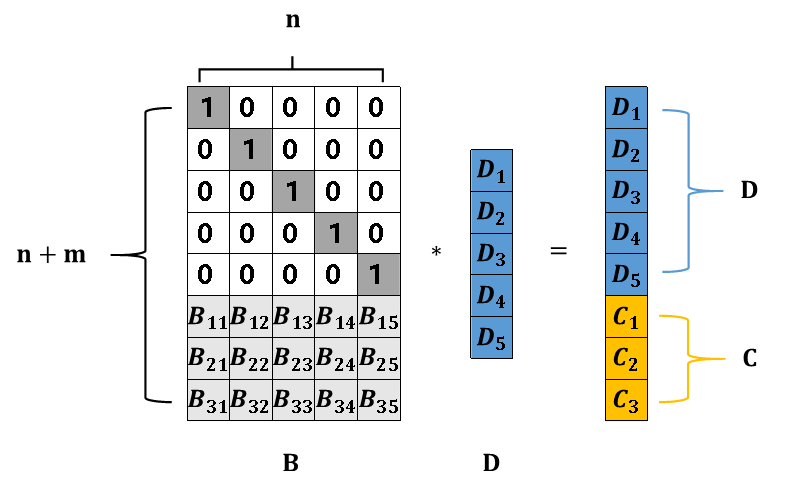
图15 RS编码计算的数学表示
当发生节点故障或磁盘故障时需要通过EC解码计算的方式进行数据恢复。我们此处以上图为例,对数据解码进行阐述。
第一步:
将D+C矩阵的若干行(此处应小于等于3)删除,用以模拟节点故障或磁盘故障导致的数据丢失,并删除编码矩阵中对应行得到矩阵B’,此时矩阵B’和矩阵Survivors为已知,我们需要通过解码运算得到矩阵D,即需要读取的数据,如图16所示。
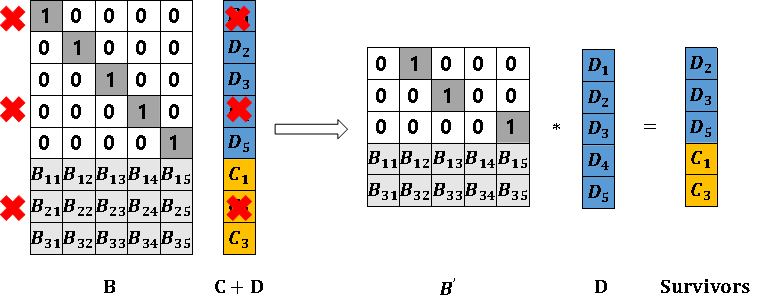
图16 数据丢失的矩阵模拟
第二步:
对矩阵B’求逆。
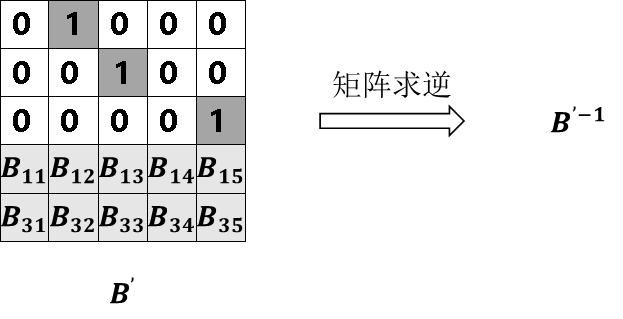
图17 矩阵B’求逆
第三步:
等式两边分别左乘矩阵 B’的逆B’-1,等式左侧将得到一个n阶单位阵和矩阵D的乘积,这样需要读取的数据D就变为矩阵B’-1与矩阵Survivors的乘积,如图19所示。
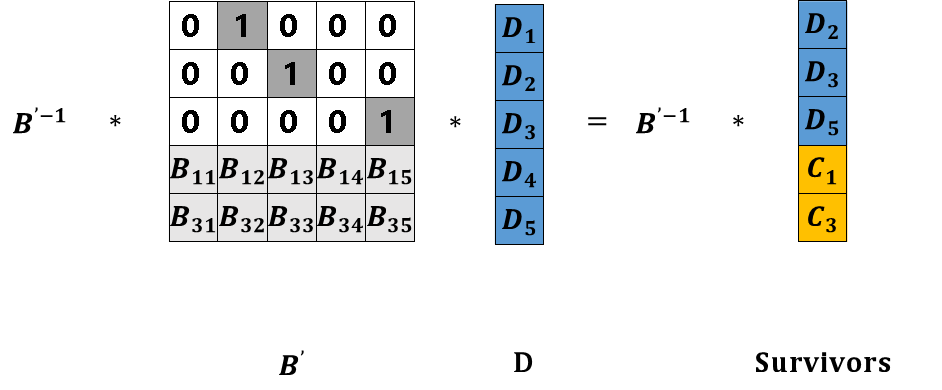
图18 等式两边左乘B’-1
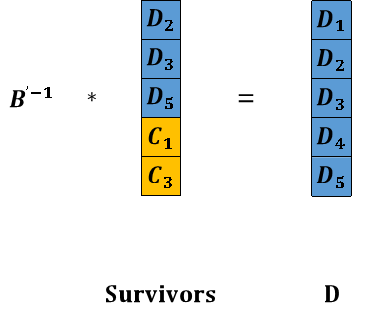
图19 EC解码得到矩阵D
通过上面的矩阵解码运算最终得到矩阵D,即所需读取的数据。
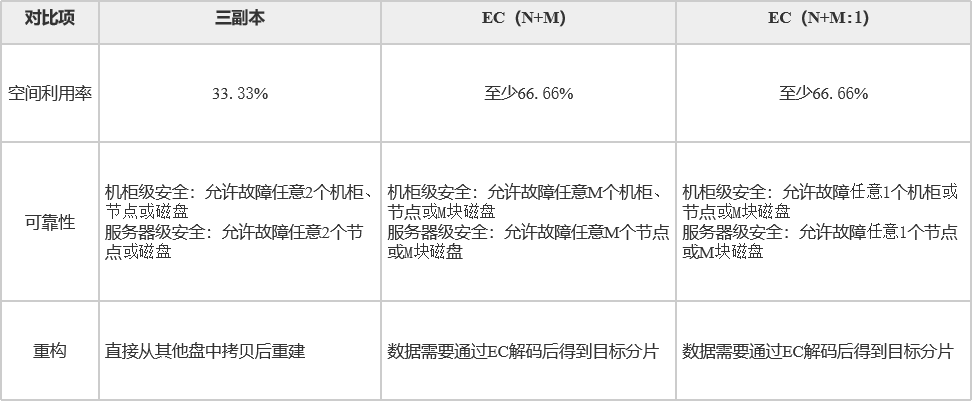
FusionStorage中多副本和EC纠删码对比
FusionStorage中EC纠删码相较于多副本可在满足高可靠性的同时显著增加空间利用率。但是多副本机制在数据重构时因为不需要进行EC解码计算,所以具有速度优势,且对存储节点的压力相对较小。下表通过空间利用率、可靠性和重构三个维度对二者进行详细比较。
总结
任何在设计阶段考虑到的异常情况,一定会在系统实际运行中发生。而且在系统实际运行过程中还会遇到很多在设计时并未考虑到的异常故障。存储系统是一切业务系统的根基,对于存储系统的设计需要考虑更加充分的冗余保护,尽量在规划设计阶段就避免可能存在的单点缺陷。分布式存储FusionStorage支持的节点级甚至机柜级冗余保护可以帮助企业减少单点故障可能导致的严重损失。
集中式存储在稳定性方面具有一定优势,但是无论是存储容量还是数据处理能力都更容易出现瓶颈,而采用分布式存储FusionStorage搭建的存储资源池可以由若干台x86标准服务器组成且方便后期进行Scale-Out扩展,因此存储和数据计算可以平均分布在所有组成存储池的节点上,有效改善单机架构时存在的空间和IO处理瓶颈问题。分布式存储还有诸多问题需要解决,但这不会阻挡存储技术的演进趋势,如果选择的话,你会选择在什么时间站在分布式存储的身边。


文章作者:李许飞
排版设计:王蔚棋
手绘插画:岳 媛

求分享
求点赞
求在看
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/32441.html