
e信智能化建设工作开展一年有余,这一年时间中我们从零开始探索智能化技术在e信生态的落地场景,构建了基于深度学习自然语言处理的内容安全管理能力,目前涵盖舆情能力和关联关系能力建设,并持续探索e信生态智能化的更多应用前景。在推进集团内网舆情能力建设的过程中,我们不断摸索和优化,根据项目特点沉淀了一套符合集团业务与金控集团特色的语料库数据质量治理方案。本文将结合具体业务和技术特点,侧重分析与过程,介绍e信智能化在集团内网建言献策舆情能力建设中的语料库构建与优化经验,达到促进技术交流和共同进步的目的。
第一阶段

基于互联网开放内容构建百万级商品评价语料库
在进行集团内网建言献策舆情能力建设的初始阶段,我们决定使用基于传统机器学习的自然语言处理技术来构建文本情感分析模型。该方法首先利用词袋模型对文本数据进行向量化处理,之后对向量化的文本—标签对进行基于统计学或动态规划原理的数学建模。而词袋模型高维文本向量的构建需要拥有海量数据的数据集作为支撑,数据量越大,文本的词袋向量越稠密,构建出的自然语言处理模型更加的准确和稳定。而数据来源越广泛,模型也就更加健壮,能够应用于更多的领域。因此,模型训练需要一个至少百万级的情感分析语料库。
由于缺少语料积累,且业界开源的情感分析语料规模一般为千量级,不足以支持业务需求,因此第一阶段我们着力于自行构建一个百万级数据量的情感分析语料库。
但是百万级语料无论从数据收集还是语料标注上,需要消耗的人力和时间成本均难以估计,考虑到时间成本和人力成本,我们从各大购物、旅游、酒店、影评网站收集经过标注的语料,最终得到涉及15个行业的100余万条语料作为训练集。
|
训练集 |
涉及行业 (个) |
正向语料 (条) |
负向语料 (条) |
总数 (条) |
|
商品评价 语料库 |
15 |
701669 |
461774 |
1163443 |
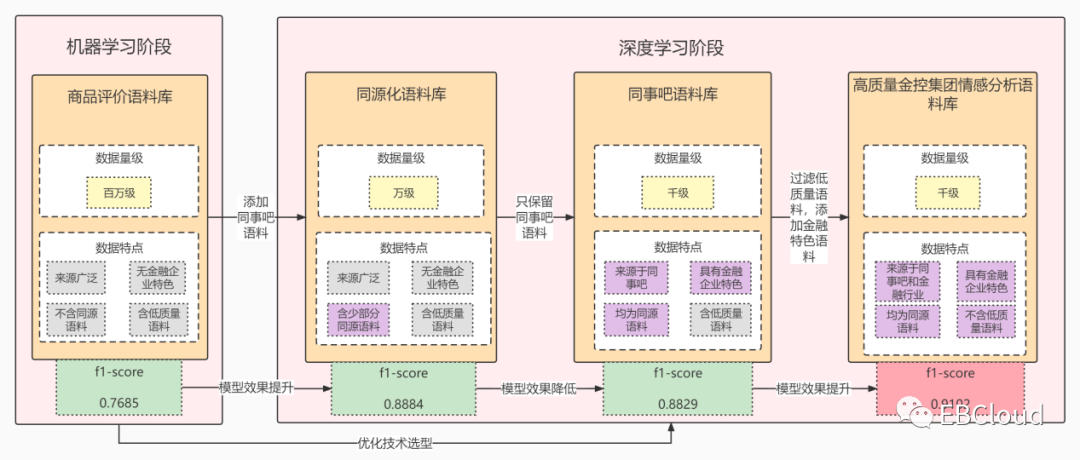
使用该语料库作为训练集,训练得到的基于机器学习的支持向量机模型在目标场景下获得了0.7685的f1-score,此结果距离在业务场景中实现良好应用还有较大差距,但可以作为一个基准,后续的数据集优化将以此阶段得到的语料库为基础进行。
|
|
数据量 |
情感类别 |
内容 |
f1-score |
|
商品 评价语料库 |
1163443 |
正向、负向 |
均为 商品评价 |
0.7685 |
第二阶段
基于商品评价语料库探索同源化语料库的构建
2.1 问题分析
第一阶段使用来自互联网数据的商品评价语料库训练模型,在应用于具有金控集团内部社区属性的集团内网场景时并没有取得很好的效果,主要原因如下:
① 商品评价语料往往情感倾向明显,含有较多具有普适性情感倾向的特征词。而金控集团内部社区语料由于实名制和应用生态的不同,情感表达往往比较委婉含蓄。此外相较于金控集团内部社区语料,商品评价语料中含有的金控领域专业术语极少,预训练模型在训练阶段很难对金控领域术语与情感倾向特征词进行情感极性的建模,因此在预测阶段就很难对金控集团内部社区语料进行准确的情感极性判断。
② 商品评价语料和金控集团内部社区语料文本长度分布不同。
|
文本长度(字符) |
商品评价语料库(条) |
金控集团内部社区数据样本(条) |
|
0~30 |
27271 |
59 |
|
31~70 |
14599 |
152 |
|
71~100 |
3129 |
98 |
|
101~120 |
1095 |
57 |
|
121~150 |
874 |
56 |
|
151~180 |
513 |
56 |
|
181~200 |
221 |
23 |
|
201~250 |
330 |
47 |
|
251~300 |
171 |
39 |
|
301~400 |
190 |
33 |
|
401~400 |
87 |
52 |
|
500+ |
158 |
15 |
|
合计 |
48638 |
687 |
观察可知,在商品评价语料库中,文本长度在180字以内的文本占比高达97.62%,而在金控集团内部社区数据样本中,文本长度在180字以内的文本占比仅有69.58%,这给训练阶段模型处理最大序列长度的设置造成了困难:如果最大序列长度设置过小,模型预测阶段难以完整处理绝大部分金控集团内部社区文本;而如果最大序列长度设置过大,训练阶段难以学到稳定的模型。
③ 第一阶段所用的传统机器学习训练方法只是单纯地对目标任务进行数学建模,模型没有很好地理解文本信息,因此难以取得好的效果。
因此在第二阶段,我们一方面计划构建具有金控集团特色的情感分析语料库,另一方面计划采用深度学习的自然语言处理框架进行情感分析模型的训练。
在项目实践中我们采用的是自然语言处理预训练模型,基于海量无监督数据训练得到的预训练模型已经在一定程度上理解了语言规律,因此通过小样本高质量语料库在预训练模型上进行fine-tune即可在大多数自然语言处理任务中得到效果优秀的模型。事实也的确如此,在从商品评价语料中选取的48638条语料组成的训练集上,ernie预训练模型的f1-score达到了0.8727,相较于传统的机器学习方法,其效果提升了0.1042,并且依然有提升空间。在大大压缩训练集数据量的基础上通过变换模型为预训练模型就取得了如此显著的模型效果提升,充分证明了使用预训练模型进行情感分析模型训练的强大优势。此外可以看出预训练模型对于训练集数据量要求不高,因此本阶段的语料库构建重点放在了训练集质量的提升上,即构建和目标应用场景——具有金控集团内部社区属性的集团内网场景同源性更强的语料库。
2.2 同源化语料库构建过程
针对在深度学习自然语言处理场景下商品评价语料和金控集团内部社区目标场景不匹配的情况,我们提出了同源化语料库改进的方案:由于光大e信同事吧这样的金控集团企业论坛兼具金融属性和通俗的社交属性,我们通过对同事吧中的公开发帖和评论进行情感极性的标注,得到了11703条文本—数据对,其中可用于进行情感分析的情感正向和负向语料共5091条。使用这一批语料随机替换掉商品评价语料中的等量内容,并使用预训练模型训练,效果对比如下:
|
|
数据量 |
情感类别 |
内容 |
f1-score |
|
商品评价 语料库 |
48638 |
正向、负向 |
均为 商品评价 |
0.8727 |
|
同源化 语料库 |
48638 |
正向、负向 |
43547条商品评价+5091条同事吧语料 |
0.8884 (提升0.0157) |
从数据可以看出,在使用同源化语料库训练时,其在预训练模型上的f1-score相较于使用商品评价语料库训练有所提升,这是因为相较于商品评价语料,光大e信同事吧语料在句式、情感特征词分布以及金控领域术语含量上与金控集团内部社区语境下的内容都更加贴近,因此训练出的模型在具有金控集团内部社区属性的集团内网场景下取得了更好的效果。
第三阶段
基于同源化语料库构建高质量金控集团特色语料库
在上一节的实验中,我们看到了使用同源化语料进行训练的优势,但当我们单纯地使用这5091条同事吧语料作为训练集进行模型训练后,得到如下结果:
|
|
数据量 |
情感类别 |
内容 |
f1-score |
|
同事吧 语料库 |
5091 |
正向、负向 |
均为同事吧语料 |
0.8829 |
可见,在单纯的同事吧语料库上,ernie预训练模型的效果有所下降,经过分析认为,出现这种情况可能是两方面原因导致:
① 数据量过小,导致模型学习到的情感分析信息较少。
② 数据质量过低,导致模型未能学习到高价值的情感分析信息。
为了进一步探究其中的原因,我们对同事吧语料库进行了进一步的优化,通过人工粗略筛选过滤掉了其中的566条低质量文本,然后以剩余的4525条语料作为训练集进行情感分析模型的训练。得到如下结果:
|
|
数据量 |
情感类别 |
内容 |
f1-score |
|
高质量同事吧 语料库 |
4525 |
正向、负向 |
均为同事吧语料 |
0.8949 |
预训练模型在经过数据量为4525条的高质量同事吧语料库训练后,取得了0.8949的f1-score,高出数据量为5091条的同事吧语料库训练结果0.0120,也高出了同源化语料库训练结果0.0065.可见,上一轮实验中并非因为5091条数据的训练集规模太小而导致训练效果降低,而是因为训练集中有较多语意不明或语法混乱的低质量文本,导致训练过程没有很好地进行。
由此我们得出了一个重要结论:
相较于传统的随机初始化网络参数进行的模型训练任务,预训练模型因为使用了海量的各行各业文本数据进行了词语维度和句子维度的训练,已经能够很好地理解语言的含义与用法。因此使用千量级的高质量训练集进行训练,即可得到高度契合任务目标场景的自然语言处理模型。
基于这样的理论,我们对高质量同事吧语料库进行了更进一步的优化,此次优化不仅进一步严格过滤了高质量同事吧语料库中的低质量语料,而且加入了在金控集团相关新闻中收集的具有情感倾向的文本数据,最终得到了数据量为4177条语料的高质量金控集团情感分析语料库。在经过模型训练后,得到如下结果:
|
|
数据量 |
情感类别 |
内容 |
f1-score |
|
高质量金控集团情感分析语料库 |
4177 |
正向、负向 |
同事吧语料+金控集团新闻语料 |
0.9102 |
预训练模型在经过高质量金控集团情感分析语料库训练后,得到了f1-score高达0.9102的金控集团文本情感分析模型,高出高质量同事吧语料库训练结果0.0153,这个结果在准确率和稳定性上都具有很高的水平,能够适用于金控集团语境下的文本情感分析任务。
至此内网内容安全语料库治理基本完成。我们在业务驱动下,以模型最终效果为导向进行技术选型与语料库治理——跟随项目阶段进行技术选型,根据技术选型确定语料库特征,根据训练反馈发现语料库问题,从而明确语料库治理的方向。
在实际的语料构建中,我们结合阶段需求统筹项目资源,对e信生态中的应用数据进行合理利用与改造,转化为适合新业务的宝贵资源,并持续进行优化,最终构建出高质量的符合金控集团特色的情感分析语料库,并在实际的模型训练中取得优异的结果。

– 总结 –
预训练模型是基于深度学习的自然语言处理的一大进步,将广泛理解文本语义的大模型训练作为上游任务进行,而开发者只负责基于预训练模型进行语料库的优化和网络超参数的调整,极大改变了随机初始化模型参数需要依赖大量级语料库的局面。因此在使用预训练模型进行自然语言处理任务的推进时,开发者应当十分重视语料库的构建与优化,相较于语料库的规模,应当尤其注重语料库的质量,并以模型效果作为反馈对语料库数据进行调整,语料库数据与目标应用场景同源度越吻合,同等超参数设置下训练得到的模型质量就会越高。
此外,以内网内容安全语料库数据治理方案为例,同样的思路可以应用到更多的智能化业务中去。在传统业务智能化转型的过程中,不仅要重视技术与框架的选型,而且应当十分重视业务语料库的构建。在语料库构建任务中,结合具体业务和项目自身数据积累对存量数据资源进行充分利用,是构建行业特色型语料库的捷径,也是对庞大数据资源的二次利用。

文章作者:潘嘉伟
任志云
排版设计:王蔚棋
手绘插画:岳 媛
在看不好意思,那就点个赞吧
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/32465.html