
深入介绍
OpenStack Nova
本篇文章将延续之前《浅辙OpenStack Nova组件》的内容,深入介绍 OpenStack Nova 组件在虚拟机实例管理方面的功能特性。作为 OpenStack 平台中的核心组件之一,OpenStack Nova 提供了计算实例(即虚拟机实例)的服务,支持用户对虚拟机实例进行创建、管理和控制等生命周期相关操作。本文将带您一起了解,在 OpenStack Nova中,用户可以通过哪些方式来管理和操作虚拟机实例,以及创建虚拟机实例过程中有哪些流程。
虚拟机实例
16种操作

-
创建(create):创建一个新的虚拟机实例,需要指定一个flavor(规格),一个image(镜像)或一个volume(卷)作为启动源,一个network(网络),一个key pair(密钥对)和一个security group(安全组)。
-
删除(delete):删除一个已有的虚拟机实例,释放其占用的资源。删除后的虚拟机实例无法恢复。
-
启动(start):启动一个已经停止的虚拟机实例,恢复其运行状态。
-
停止(stop):停止一个正在运行的虚拟机实例,保存其磁盘状态。停止后的虚拟机实例可以再次启动。
-
暂停(pause):暂停一个正在运行的虚拟机实例,保存其内存状态到磁盘。暂停后的虚拟机实例可以恢复。
-
恢复(resume):恢复一个已经暂停的虚拟机实例,从磁盘加载其内存状态。恢复后的虚拟机实例继续运行。
-
挂起(suspend):挂起一个正在运行的虚拟机实例,保存其内存状态到主机内存。挂起后的虚拟机实例不占用CPU资源,但占用内存资源。挂起后的虚拟机实例可以恢复。
-
恢复(resume):恢复一个已经挂起的虚拟机实例,从主机内存加载其内存状态。恢复后的虚拟机实例继续运行。
-
重启(reboot):重启一个正在运行或已经停止的虚拟机实例,重新加载其磁盘状态。重启后的虚拟机实例重新运行。
-
重建(rebuild):重建一个已有的虚拟机实例,使用一个新的image或volume作为启动源,保留其flavor,network,key pair和security group。重建后的虚拟机实例重新运行。
-
调整大小(resize):调整一个已有的虚拟机实例的flavor,增加或减少其内存或CPU数量。调整大小后的虚拟机实例需要确认或撤销操作。
-
确认调整大小(confirm resize):确认调整大小操作,释放原来的资源。确认后的虚拟机实例使用新的flavor运行。
-
撤销调整大小(revert resize):撤销调整大小操作,回到原来的资源。撤销后的虚拟机实例使用原来的flavor运行。
-
迁移(migrate):迁移一个已有的虚拟机实例到另一个计算节点上,根据调度器选择合适的目标节点。迁移前需要停止虚拟机实例,迁移过程中会复制磁盘文件和元数据。迁移后需要确认或撤销操作。
-
确认迁移(confirm migrate):确认迁移操作,释放原来的资源。确认后的虚拟机实例在新节点上运行。
-
撤销迁移(revert migrate):撤销迁移操作,回到原来的节点上。撤销后的虚拟机实例在原节点上运行。

实例
流程
创建虚拟机实例是 OpenStack 平台中最基本、最常见的操作之一。为方便初学者了解 Nova 的工作原理和组件之间的交互关系,我们通常以创建虚拟机实例为例来介绍 Nova 组件的调用流程。这种方式可以为初学者打下使用 OpenStack 平台的基础。同时,由于 OpenStack 平台的复杂性和灵活性,不同的 OpenStack 发行版和不同的部署方式下,Nova 组件的工作原理和调用方式会有所不同,这也是为何我们经常以创建虚拟机实例为例来进行说明,因为它是最通用和了解度最高的方式。
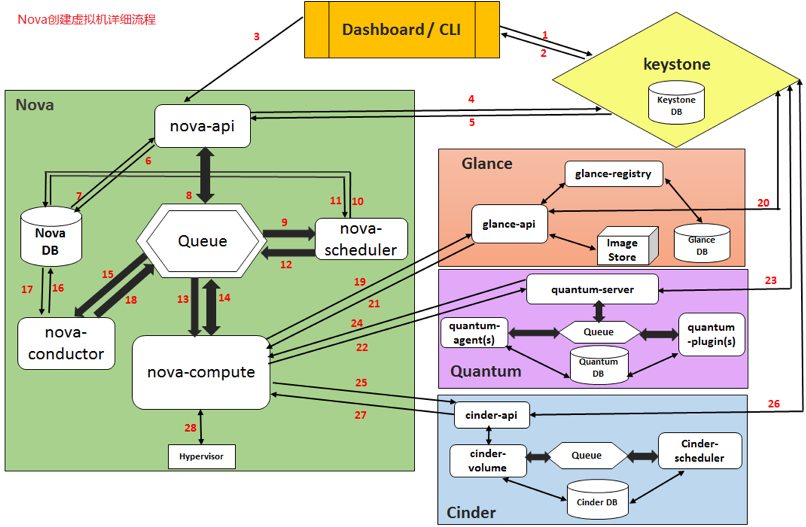
创建虚拟机实例的总体流程图
本节重点是探究Nova在创建虚拟机实例的过程中内部组件的一个调用流程,上图是为各位同学提供一个总体流程的概览,涉及到的其他组件调用流程本次不作赘述,以下是本节重点探究内容的调用逻辑描述:
1) 用户通过OpenStack Dashboard、命令行或API方式发起创建实例请求,请求包含虚拟机实例的配置信息,如虚拟机实例名称、镜像、网络等。
2) Nova API Server接收到请求,进行身份验证和授权,确保用户有权限进行操作。Nova API Server还将请求进行解析,并构建一个称为请求对象的数据结构,该对象包含所有与请求相关的信息。
3) Nova API Server将请求对象发送到nova-scheduler服务。nova-scheduler会查询nova数据库中的计算节点信息,并使用一系列策略和插件(如Filter Scheduler、Weight Scheduler、Host Aggregate Scheduler等)来选择一个合适的计算节点来创建实例。策略和插件可以根据虚拟机实例规格、可用性区域等条件进行过滤,权重计算可以根据计算节点的负载、性能等因素进行计算。
4) Nova Scheduler选择完计算节点后,会将计算节点信息和请求对象发送给nova-compute服务。
5) Nova Compute接收到请求对象和计算节点信息后,首先会从Glance镜像服务中下载虚拟机实例镜像文件,并将其存储到本地磁盘中。然后,它会使用libvirt(一种虚拟化管理工具)与计算节点的虚拟化层(如KVM、Xen、VMware等)进行交互,以创建虚拟机实例实例。Nova Compute还将实例的元数据(下一章节详解)发送到nova-metadata服务,以提供给虚拟机实例实例访问。
6) Nova Compute创建完实例后,会将实例的状态信息发送到nova-conductor服务进行数据库操作,包括实例的创建、状态变更等操作。nova-conductor还会将实例的信息存储到nova数据库中。
7) Nova Compute将实例的网络信息发送到nova-network服务,nova-network服务根据实例的网络配置信息创建网络连接,使虚拟机实例实例能够与外部通信。如果需要分配浮动IP地址,nova-network服务将分配一个可用的浮动IP地址并分配给虚拟机实例实例。
8) Nova Compute将实例的元数据信息发送到nova-metadata服务,该服务将元数据信息存储在nova数据库中,并提供元数据服务以供虚拟机实例实例访问。
9) Nova API Server将创建实例的结果返回给用户,包括虚拟机实例的ID和IP地址等信息。用户可以使用这些信息连接到虚拟机实例实例。
总之,Nova组件之间相互协作,通过流程管理虚拟机实例的创建和运行。用户可以通过Nova API Server与Nova组件交互,完成虚拟机实例的创建、删除等操作。通过详细的流程,可以更好地了解Nova组件如何协同工作来创建虚拟机实例。
虚拟机实例
元数据

在 OpenStack 中,元数据服务用于存储虚拟机实例的有关配置和信息,这些信息主要分为虚拟机实例元数据和用户元数据两大类。而 cloud-init 是一个主要用于虚拟机实例自动化配置和管理的工具,它通常与元数据服务一起使用来获取虚拟机实例的各种配置信息。具体来说,cloud-init 工具用于在虚拟机实例启动时获取元数据信息,以帮助自动完成虚拟机实例的配置和管理任务。它可以获取具体元数据信息如下所示:
01
虚拟机实例元数据
-
hostname:虚拟机实例名称。
-
UUID:虚拟机实例的唯一标识符。
-
image_name:虚拟机实例使用的镜像名称。
-
launch_index:虚拟机实例在同一批创建的虚拟机实例列表中启动的顺序。
-
meta:存储用户定义的元数据。
-
network:虚拟机实例网络信息。
-
public_keys:SSH 公钥信息。
-
ramdisk_id:虚拟机实例使用的 RAMDisk 镜像的 ID。
-
reservation_id:虚拟机实例预留的 ID。
-
security_groups:虚拟机实例所属的安全组。
-
user_data:用户针对这个实例定义的元数据内容。
02
用户定义的元数据
自定义键值对:用户可以定义任意的键值对信息,用于自己的特定需求。例如:自定义的配置、应用程序元数据、密钥材料等。
需要注意的是,cloud-init 工具通常仅用于读取和处理虚拟机实例元数据,并不会访问用户元数据,因为用户元数据可能包含敏感性和机密性信息。在某些情况下,用户可以编写自己的 cloud-init 配置文件,并在 OpenStack 中创建虚拟机实例进行测试和验证。
元数据
流程

这里简单介绍下流程中涉及nova以外的组件:
|
模块 |
功能 |
部署位置 |
|
neutron-metadata-agent |
允许用户实例通过网络访问 Cloud-init 元数据和用户数据 |
计算节点 |
|
neutron-ns-metadata-proxy |
接收用户实例的HTTP请求,并通过进程间通信(unix domain socket)将请求发送给neutron-metadata-agent
|
计算节点 |
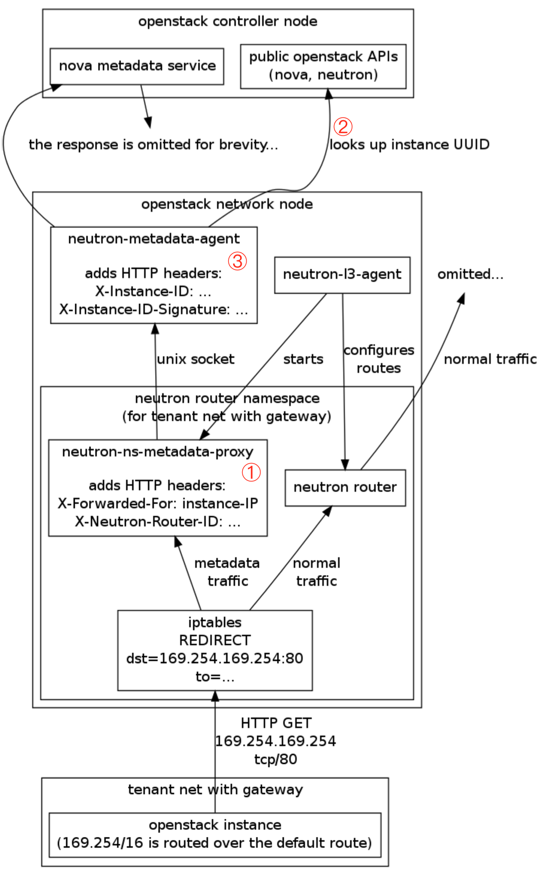
OpenStack Liberty版本之前cloud-init获取虚拟机实例元数据流程图
结合上图,我们知道cloud-init获取虚拟机实例元数据原流程是:
1) 当虚拟机启动时,会获取一个IP地址,通常通过DHCP获得。虚拟机也会拥有一个默认网关和DNS服务器地址,当需要访问元数据服务时,nova-api-metadata 服务将按需从元数据存储库中检索出所需的元数据,它会向 http://169.254.169.254 发送HTTP请求。该请求会通过默认网关路由到计算节点内的 neutron-ns-metadata-proxy上;
2) neutron-ns-metadata-proxy 收到请求后,会将虚拟机IP、路由ID信息添加到http请求的包头当中,再将打包好的请求转发给 neutron-metadata-agent ;
3) neutron-metadata-agent接收到请求后,会查询虚拟机的UUID,具体做法是:
a. 通过 路由ID找到路由连接的所有子网,然后筛选出虚拟机IP所在的子网;
b. 在子网中找到虚拟机IP对应的端口;
c. 通过端口找到对应的虚拟机及其UUID。
neutron-metadata-agent 将虚拟机UUID添加到http请求的包头中,然后转发给 nova-api-metadata;
4) nova-api-metadata检索需要的元数据,然后将其格式化并原路返回给cloud-init进行处理,自动将其应用于虚拟机的网络设置、主机名、用户等方面。
从OpenStack Liberty版本开始,可以通过Neutron的命名空间的元数据服务代理(neutron-ns-metadata-proxy)来直接获取元数据,而不再需要使用Neutron元数据代理(neutron-metadata-agent)处理请求。这使得元数据服务的部署更加简单和灵活,并且对于大型部署来说,可以提高元数据服务的性能和可扩展性。
169.254.169.254

而OpenStack为了兼容,保留了这个地址169.254.169.254。虚拟机启动时就会向 169.254.169.254请求元数据服务,所以OpenStack之后也沿用了这个设计。但是这个地址在实际OpenStack是不存在的,需要配置iptables映射到真实的API地址,将目标为元数据服务器的流量重定向到本地9796端口上。
这个地址来源于AWS,当年AWS在设计公有云的时候,为了让虚拟机能够访问元数据,就将 169.254.169.254这个特殊的IP作为元数据服务器的地址, 后来很多厂商给亚马逊定制了一些操作系统的镜像,比如Ubuntu,Fedora,Centos 等,而且将里面获取元数据的API地址固定写死。
文章作者:苏栋强
手绘插画:岳 媛
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/32648.html