
引言\’\’
消息中间件,以其高效且可靠的消息传递机制,使得平台间的数据交流变得无障碍。这种机制不仅为分布式系统的集成提供了坚实基础,还通过消息传递和消息排队模型,极大地扩展了分布式环境下进程间的通信能力。在这个过程中,发送者将消息发送给消息服务器,而消息服务器则将这些消息有序地存放在队列中,等待在合适的时机将它们转发给接收者。
随着国内信息化建设的持续深化,众多企业已迈入深度应用的新阶段,中间件技术也迎来蓬勃发展的春天。本文旨在通过对Kafka和RabbitMQ这两种消息中间件的对比分析,为开发人员提供有力的决策支持,以便他们能够根据实际需求选择最适合的消息中间件。
Kafka与RabbitMQ对比分析\’\’
Kafka最初由LinkedIn公司采用Scala语言开发,是一个分布式、多分区、多副本的消息系统,并依赖于Zookeeper进行协调。作为一种高吞吐量的分布式发布订阅系统,Kafka能够处理消费者在网站上产生的所有动作流数据。
图1 Kafka工作原理图
RabbitMQ是一款开源的消息队列服务软件,基于Advanced Message Queuing Protocol (AMQP)协议实现。RabbitMQ在分布式系统中用于存储转发消息,以其易用性、出色的扩展性以及高可用性等特点受到广泛认可。
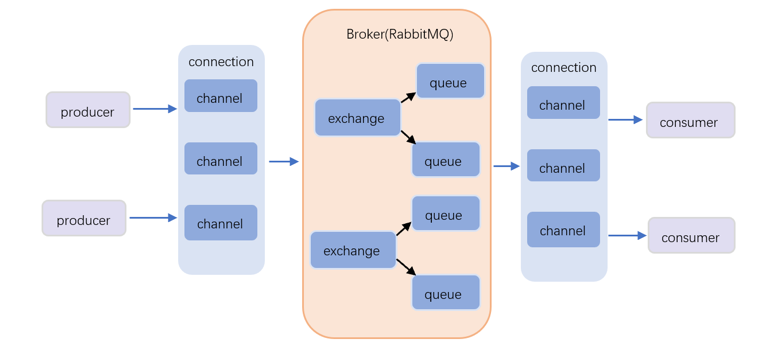
图2 RabbitMQ工作原理图
1、消息顺序
Kafka在同一主题、单一分区、单一消费者的情况下,能够确保消息按照发送的顺序到达消费者端。然而,在这种配置下,Kafka的高吞吐量优势可能无法充分发挥,因为单个分区和单一消费者限制了并行处理的能力。而在多分区、多消费者、消费者组的情况下,Kafka无法保证全局的消息顺序性。虽然每个分区内部是有序的,但不同分区的消息可能由不同的消费者以不同的速度处理,因此无法保证跨分区的消息顺序。
RabbitMQ在正常情况下能够确保消息顺序到达消费者。但在异常情况下,如消息处理失败并返回队列时,RabbitMQ则无法保证这些重新入队的消息能够按照原始顺序再次被消费,这可能导致消息顺序性被破坏。
2、消息匹配
RabbitMQ允许在消息中添加routing_key或者自定义消息头,然后通过一些特殊的Exchange,可以很方便的实现消息匹配分发。
Kafka如果要实现消息匹配,则需要的开发成本高。通过简单的配置去自动匹配和分发到合适的消费者端这件事是不可能的。消费者端必须先把所有消息都取出来,然后再根据业务需求,自己去实现各种精准和模糊匹配。在过于复杂的情况下,还要引入规则引擎。
3、消息路由
Kafka并未提供任何路由过滤功能,因此当消费者订阅某一主题时,将会接收到该主题上的全部消息。
RabbitMQ则不同,它提供了多种交换器类型,每种类型都有独特的队列分发策略。通过灵活结合交换器和routing key值,RabbitMQ可以在中间件层实现精确的消息路由功能。
4、消息延迟
RabbitMQ3.5.8版本以后通过使用rabbitmq delayed message exchange插件支持延迟/预定消息。当在消息交换上启用此插件时,生产者可以向RabbitMQ发送消息,并且生产者可以延迟RabbitMQ将此消息路由到消费者队列的时间。
此功能允许开发人员安排未来的命令,这些命令在此之前不应该被处理。例如当生产者遇到限制规则时,我们可能希望将特定命令的执行延迟到稍后的时间。
图片来源网络
Kafka不支持该功能。当消息到达时,它将消息写入分区,消费者可以立即使用它们。且Kafka没有为消息提供TTL机制。此外,Kafka分区是一个仅追加的事务日志,因此它无法操纵消息时间(或分区内的位置)。
5、消息保持
RabbitMQ在消费者成功消费消息后,会立即从存储中删除该消息,这是大多数消息代理平台的通用设计,通常无法更改。
Kafka则采用了不同的设计思路,它按照每个主题配置的超时时间保留所有消息。Kafka并不关注消费者的消费状态,它更像是一个消息日志系统。消费者可以按需消费每条消息,并通过调整分区偏移量来自由地在消息流中前进或后退。Kafka会定期检查主题中消息的年龄,并自动清除那些超过保留期限的旧消息。
6、消息的错误处理
在Kafka中,如果单个分区中的某条消息消费失败,系统将停止继续消费该分区后续的消息,无论是因为Kafka自身消息格式损坏还是消费者处理异常。这种机制意味着,一旦遇到消息消费问题,Kafka不允许跳过失败的消息继续处理后续内容。因此,在选择Kafka用于数据统计不要求十分精确的场景时,必须警惕消息消费问题可能导致项目不可用的风险。
RabbitMQ在处理消息出错或消费错误时,能够利用重试机制和死信交换(DLX)等工具,确保即使遇到问题也能继续消费后续消息,从而提供了更为灵活和便利的处理方式。
7、消费者复杂性
RabbitMQ采用了智能代理(smart-broker)和简单消费者(dumb-consumer)的运作模式。在这种模式下,消费者通过注册到特定的消费队列来接收消息。一旦有消息进入队列,RabbitMQ会自动将这些消息推送给消费者进行处理,并同时从队列中移除这些已处理的消息。当系统负载上升时,RabbitMQ能够灵活地将消息分发到消费者组中的多个消费者,从而实现消费者的水平扩展,而无需对系统进行任何额外的配置或修改。
Kafka采用愚蠢代理人(dumb-broker)和聪明消费者(smart-consumer)的设计思路。在消费者组中,消费者需要相互协调,确保每个消费者监听不同的主题分区,避免重复处理。此外,消费者还需自行管理和存储各自分区的偏移索引。在负载较轻时,单个消费者需要同时处理和跟踪多个分区,这对消费者端的资源要求较高。随着系统负载的增加,我们可以通过增加消费者数量来应对,但消费者数量最多只能扩展到与主题分区数量相当的水平。虽然可以通过增加分区数来进一步增加消费者数量,但一旦系统负载减少,已添加的分区无法删除,这可能导致消费者资源的浪费。
总结\’\’
根据以上我们对Kafka及RabbitMQ的对比分析,我们可以得出以下结论:
Kafka在以下场景下更为合适:
(1)提供严格的消息排序机制,确保消息的有序性。
(2)当需要长时间保留消息,并具备重放历史消息的能力时,Kafka是理想之选。
而RabbitMQ则具备以下优势:
(1)拥有先进且灵活的路由规则,为消息传递提供了更多可能性。
(2)RabbitMQ支持消息计时控制,可以有效控制消息的过期时间和延迟发送。
(3)面对消费者无法处理消息的情况,RabbitMQ提供了高级故障处理功能,无论是暂时还是永久问题都能得到妥善处理。
(4)在消费者实现方面,RabbitMQ也更为简单便捷。
参考文献\’\’
[1]RabbitMQ vs Kafka:正面交锋
[2]消息中间件选型分析
■ 文章作者 王梦娇 ■
■ 封面设计 Lina ■
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/32855.html