
为什么要了解git的存储原理

git是一个分布式版本控制软件,最初由林纳斯·托瓦兹创建。由于git采用了分布式版本库的作法,不需要服务器端软件,就可以运作版本控制。[1]因此,git很快就成为了最受欢迎的版本管理工具之一。
工欲善其事必先利其器,熟练的使用git是每一个开发人员无法绕过的门槛,为了更好的了解、使用git,我们不仅需要知其然,更要知其所以然。下面就让我带领大家一起去探寻git在存储方面的原理。
[1] 引用自wiki百科https://zh.wikipedia.org/wiki/Git

git存储原理

在介绍原理之前,我们需要了解一些git的重要概念:
-
对象,特指.git/objects目录下的文件(文件名一般为十六进制hash格式)
-
blob、commit、tree,指的是git对象的类型
git的三个分区:
-
工作区,就是你在电脑里能看到的目录。
-
暂存区,一般指./git/index 文件(其中主要存储各个文件的git对象id,具体格式较为复杂,这里不做过多介绍)。
-
版本库,一般指.git/refs目录和.git/objects目录。
本文将着重探索版本库相关目录下的文件变化,接下来我们就通过一次实操,来探寻git对象和分区的是如何工作起来的!

1)从git的目录说起

首先,我们初始化一个空的git仓库,观察它的目录结构。
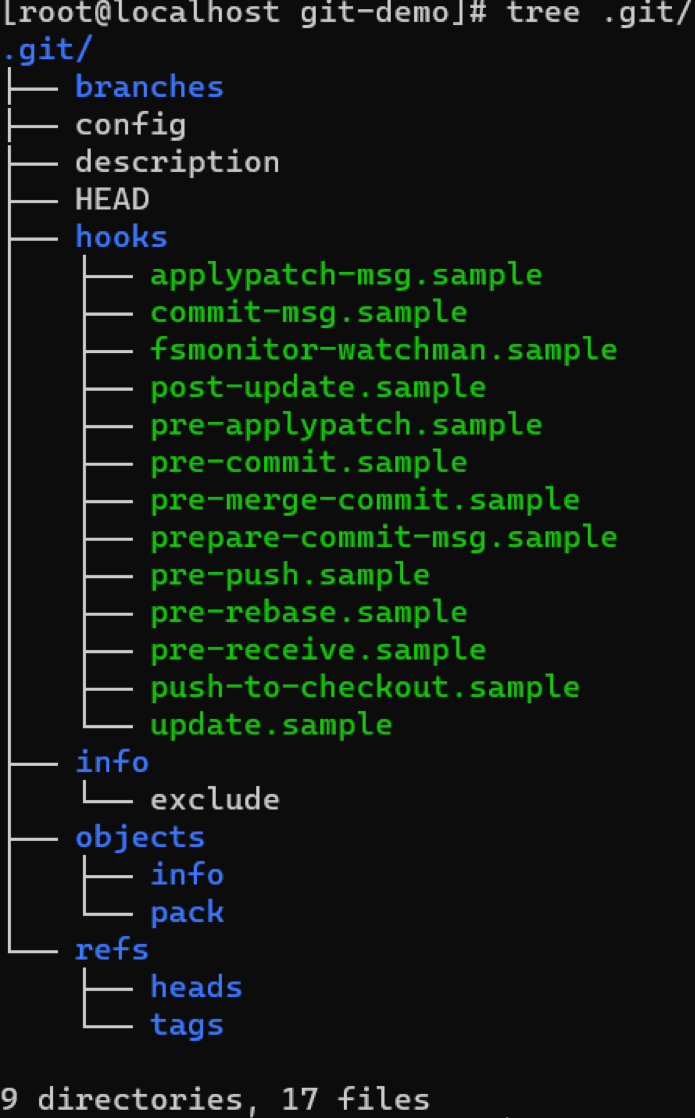
A.refs目录
refs目录通常也被称为‘引用’目录,git中的引用分为两种,其中heads和remotes(图中暂未标出)分别存储了本地和远程的分支信息,其内容是可变的;tags目录主要存储git的所有tag,其内容是不可变的,经常在发布版本时候使用。
B.objects目录
存放所有的 git 对象,其文件名为哈希值一共40位,前 2 位作为文件夹名称,后 38 位作为对象文件名。
C.hooks目录
一些git钩子脚本所在的目录,执行git命令的过程中会自动调用该目录下配置的钩子脚本
D.额外的文件
HEAD、FETCH_HEAD、ORIG_HEAD,这三个文件是中分别存储了本地的git引用、git fetch的引用、origin引用
2)创建文件试试?
我们新建两个普通的文件,并执行git add . ,观察objects目录会发生什么变化?
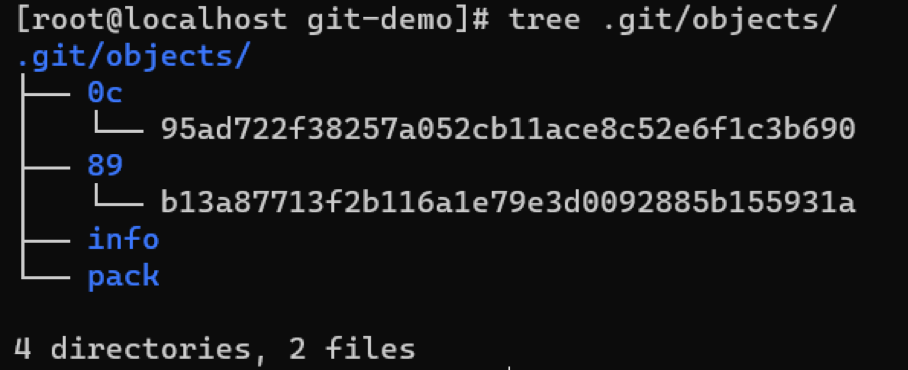
从上图我们可以看到,objects目录多了两个文件,那么这两个文件的作用是什么的呢?
在继续探索之前,我们需要知道git cat-file 命令,git cat-file -t object可以输出git对象的类型,git cat-file -p object 可以输出git对象解密后的内容。下面我们就看一下这两个git对象的类型和内容。
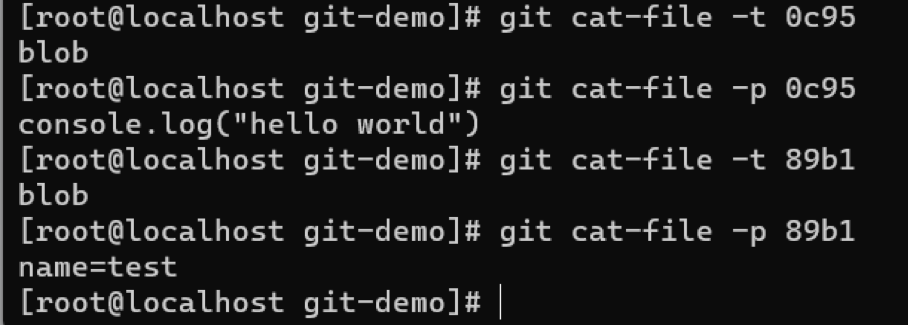
很明显,这两个文件正是我们的代码index.js 和 env.dev,因此可以看出这两个git对象完整的存储了代码库的代码(由于git对象会完整的存储每一个代码文件,代码库会随着提交次数的变多,而变得越来越大)。同时,我们注意到这两个git对象的类型都是blob,这正是git用来保存文件的对象类型。但是,仅仅有这两个文件好像无法保存代码库的目录结构。接下来,我们执行git commit 命令。
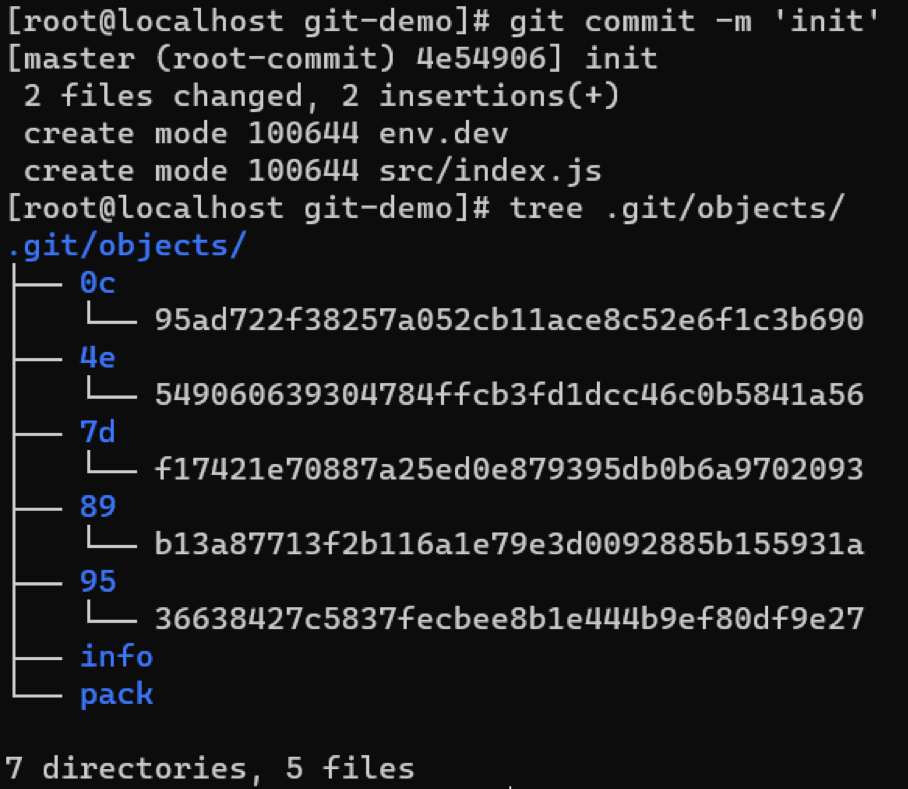
此时objects目录下面多了三个git对象,我们依次查看每个git对象的类型和内容
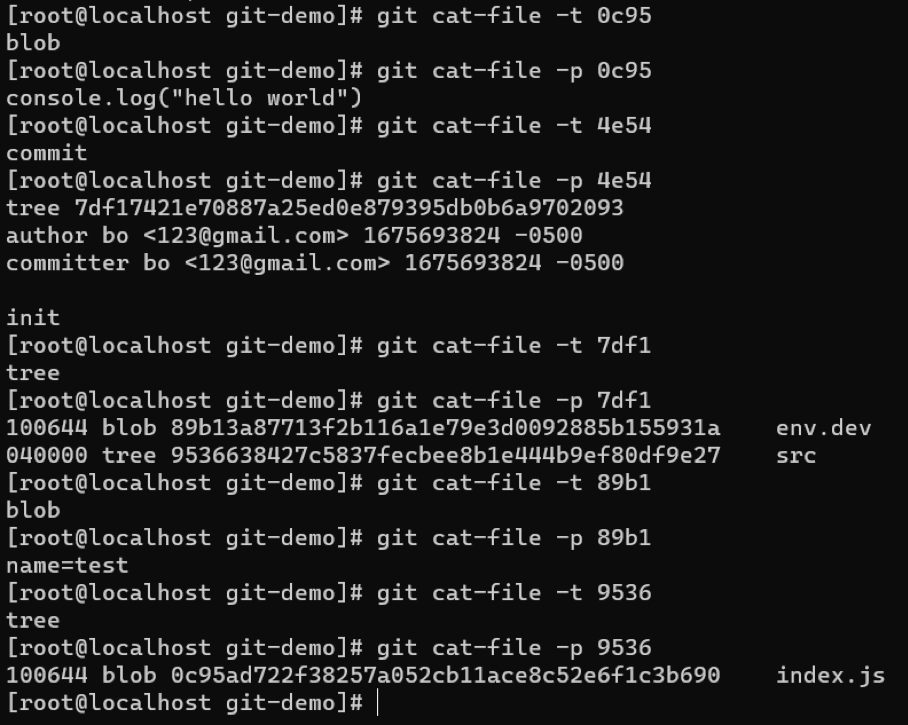
首先观察4e54这个对象,它的类型是commit,内容(其中的100644和040000记录了文件类型、权限信息)的第一行表示该对象指向一个类型为tree 名字为7df1的对象;第二行和第三记录的是提交人的信息;最后一行记录的是提交信息。然后再看7df1对象的类型和内容,它的类型是tree,内容第一行表示该对象指向一个类型为blob名字为89b1的对象;第二行表示该对象还指向一个类型为tree名字为9536的对象。剩下的就不再一一解释,我们将上述结构用图形表示出来。
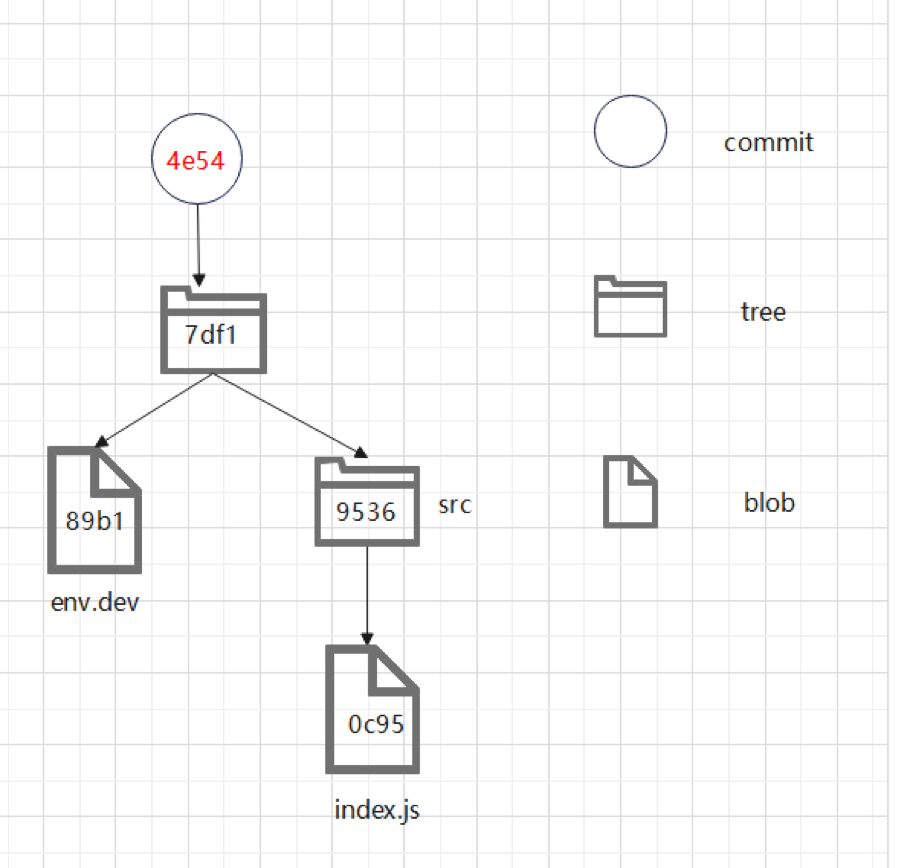
此时,我们发现,git使用了三种节点类型,完整保存了代码库的一个历史版本。其中的commit类型对象表示一次提交也就是一个版本;tree类型表是一个目录;blob类型表示一个文件。至此,我们已经大致了解了git是如何存储一个版本的,那么多个版本呢?
3)修改文件,再次提交?
首先我们在env.dev增加一些内容,并执行git add命令。
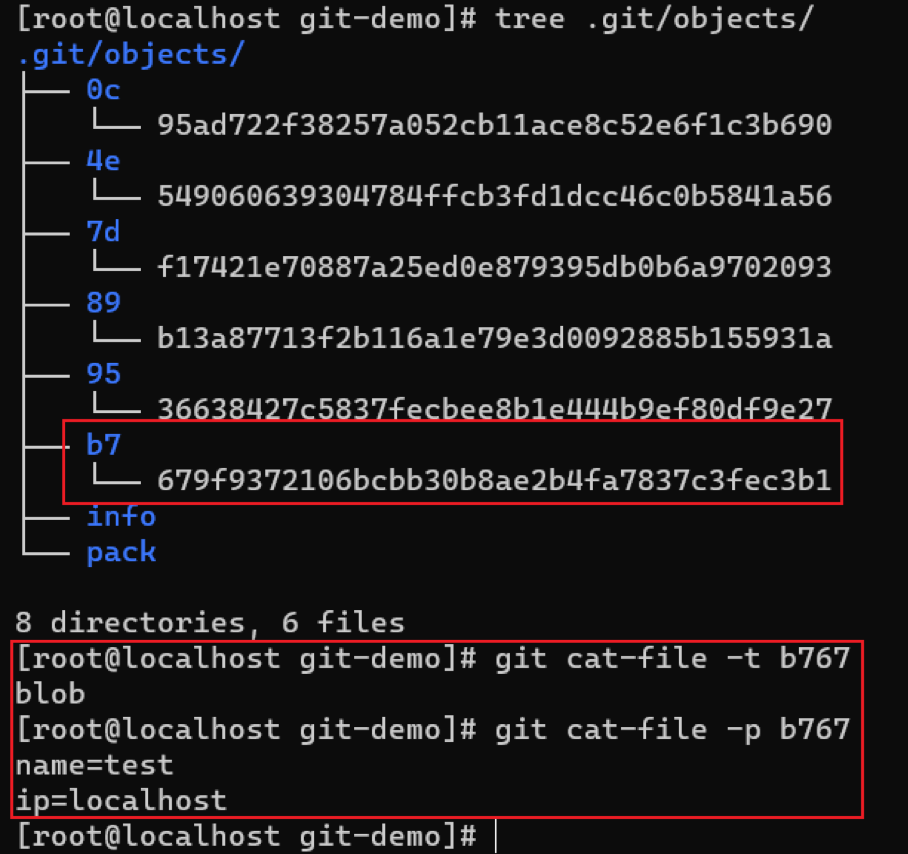
此时可以发现,objects目录下多了一个blob类型的git对象,里面完整保存了修改后的文件env.dev。此时的git 对象状态如下图所示:
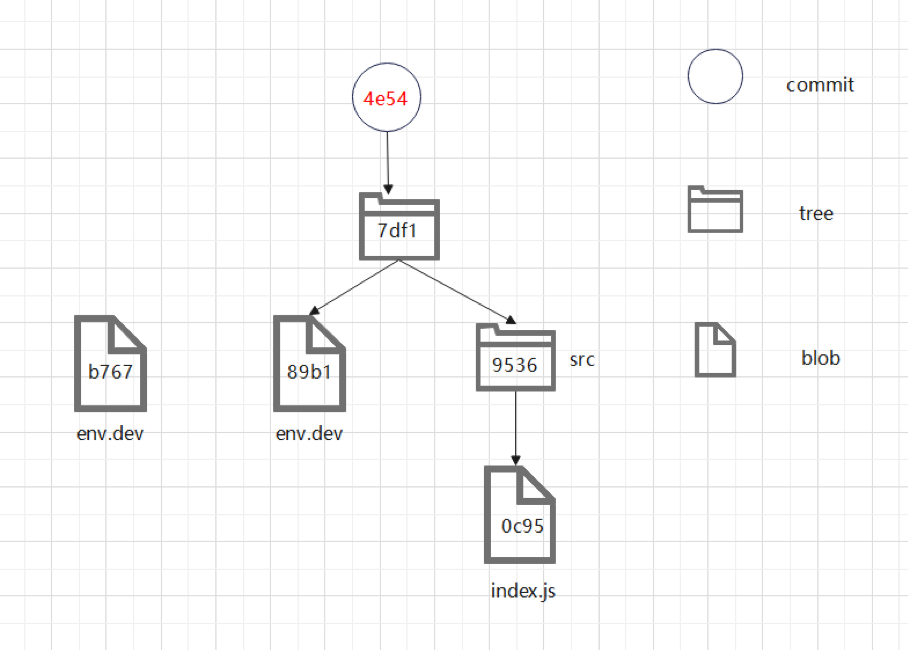
接下来我们执行git commit命令,看看会发生什么:
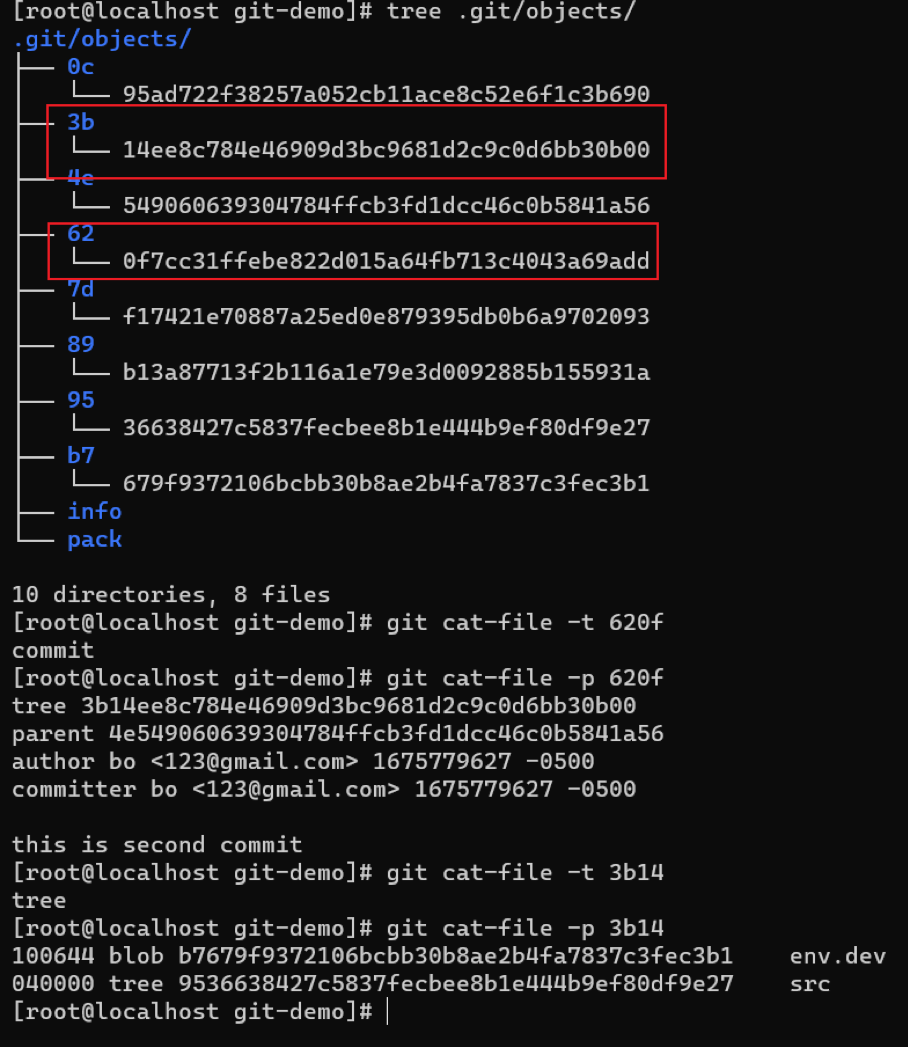
此时我们发现,objects目录下又多了两个git对象,分别是620f,其类型为commit,其内容第一行指向3b14(类型为tree)的节点,第二行指向父节点4e54(类型为commit),后面几行为作者信息和提交信息;3b14节点则指向b767(blob)节点和9536(tree)节点。此时所有git对象的关系如下图所示:
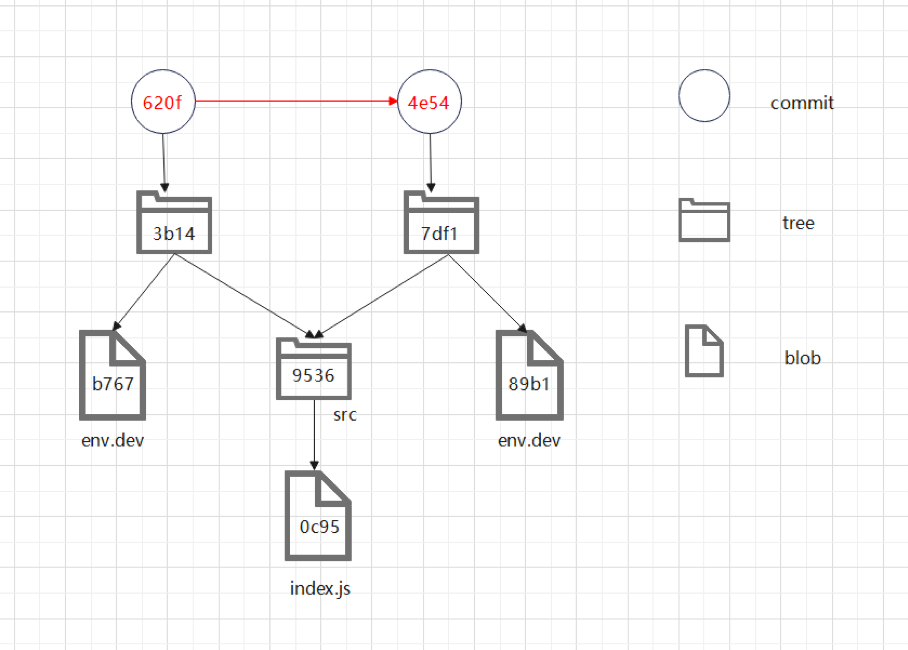
观察上图我们发现:
-
若文件发生变化,git则会生成一个blob对象来全量的保存最新的文件的内容(这也是导致.git目录越来越大的主要原因)。
-
若tree类型的对象指向的内容发生变化,git也会重新生成一个tree类型型对象,来指向变化后的内容。
-
只看commit类型的对象,它们就像是一个单链表结构(实际上为树形结构)。
-
依靠commit对象,我们可以查看任意历史版本的代码库。

总结

git使用了三种对象commit、tree、blob来记录文件、管理文件的版本信息。其中commit对象,主要存储版本信息以及版本间的依赖关系,tree和blob对象主要存储代码文件和目录结构。三者相互配合就能够完成git任意版本切换的功能。
以上只是对git存储的原理做了简单的介绍,git更复杂的暂存区、工作区、分支的合并、衍合等,可以参考《pro git》一书,详细了解。

E
N
D
文章作者:张 博
手绘插画:岳 媛
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/32986.html
