
当下很多人对大模型的态度是“期待太高,耐心太少。想的太多,用的太少”。
人工智能或许会在大模型的帮助下,迎来产业应用的拐点,不断下沉成为信息社会的基础设施,成为像大数据、云计算一样的信息基础设施,并且再进一步发展成为像水、电、气一样的社会基础设施。但这需要时间与耐心,可能一年、五年,也可能是又一次寒冬来临的前夜。
面对产业界的高预期,媒体的过度解读,我们要保持耐心,通过研究分析大模型的技术特点与技术价值,观察其行业发展趋势,不断地探索大模型的应用场景,确保在长周期的技术赛道中占有一席之地。
01 引言 Introduction
ChatGPT掀起的AI风暴还未平息,多模态GPT-4、百度文心一言、阿里通义千问又带来了新的浪潮。英伟达公司的首席执行官黄仁勋认为“我们正处在AI的iPhone时刻”,也有人将ChatGPT Plugins比作苹果应用商店,大模型被认为将像移动互联网一样开启一个新的时代。 我想通过这篇文章,揭开大模型的神秘面纱,一起研究大模型是什么?能做什么?跟我们有什么关系?
1、大模型的定义 大模型,也叫大语言模型(Large Language Model,LLM)。 大模型的“大”,是指模型参数至少达到1亿以上。GPT-3的参数规模是1750亿。大模型之外,还有“超大模型”,通常拥有数万亿到数千万亿参数。大模型和超大模型的主要区别,就在于模型参数数量的多寡、计算资源的需求和性能表现。 模型,通常是一个函数或者一组函数,以线性函数、非线性函数、决策树、神经网络等各种形式呈现。模型的实质,就是对这组函数映射的描述和抽象。 训练和优化各种模型,就能够得到更加准确和有效的函数映射。模型的目的,是为了从数据中找出一些规律和模式,更好地预测未来。
2、大模型是人工智能历史的突变和涌现 如果从1956年达特茅斯学院的人工智能会议算起,人工智能的历史已经接近70年。 图 1 人工智能发展路径 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》) 达特茅斯学院的人工智能会议发展出人工智能的三个基本派别: (1)符号学派(Symbolism),又称逻辑主义、心理学派或计算机学派。 (2)联结学派(Connectionism),又称仿生学派或生理学派。 (3)行为学派(Actionism),该学派的思想来源是进化论和控制论。 在相当长的时间里,符号学派主张的基于推理和逻辑的AI路线处于主流地位。但是,因为计算机只能处理符号,不可能具有人类最为复杂的感知,符号学派在20世纪80年代末开始走向式微。联结学派和行为学派迎来春天,在之后的AI发展史中,有三个重要的里程碑: 第一个里程碑:机器学习(ML); 第二个里程碑:深度学习(DL); 第三个里程碑:人工智能内容生成大模型。 大模型的训练需要大量的计算资源和数据,OpenAI使用了数万台CPU和GPU,并利用了多种技术对模型进行了优化和调整。2018—2023年,OpenAI实现大模型的五次迭代。同时,OpenAI也提供了API接口,使得开发者可以利用大模型进行NLP的应用开发。 大模型是在数学、统计学、计算机科学、物理学、工程学、神经学、语言学、人工智能学融合基础上的一次突变,并导致了一种“涌现”。大模型也因此称得上是一场革命。在模型尚未达到某个临界点之前,根本无法解决问题,性能也不会比随机好;但当大模型突破某个临界点之后,性能发生越来越明显的改善,形成爆发性的涌现能力。 谷歌、斯坦福和DeepMind联合发表的《大语言模型的涌现能力》(Emergent Abilities of LargeLanguage Models)用实验证明了涌现的特点:“许多新的能力在中小模型上线性放大,规模都得不到线性的增长,模型规模必须呈指数级增长并超过某个临界点,新技能才会突飞猛进。” 图 2 模型参数规模扩大为大模型带来的能力“涌现” (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》)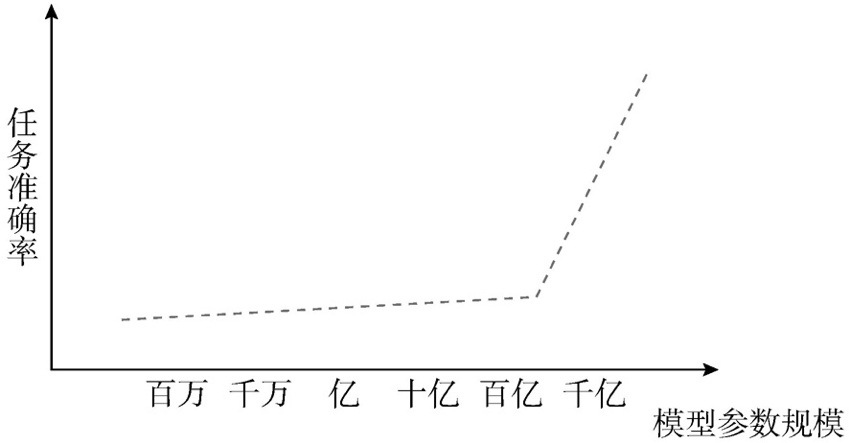

02 大模型的大脑和心脏 Brain and Heart
如果说神经网络是大模型的“大脑”,那么Transformer就是大模型的“心脏”。 大模型以人工神经网络(ANN)为基础。以OpenAI为代表的团队,为了让具有多层表示的神经网络学会复杂事物,创造了一个初始化网络的方法,即预训练(pre-trained)。在GPT中,P代表经过预训练(pre-trained),T代表Transformer,G代表生成性的(generative)。实际上,是生成模型为神经网络提供了更好的预训练方法。现在的大模型都是以人工神经网络为基础的算法数学模型。 图 3 神经网络 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》) 2017年6月,谷歌的阿希什等人发表论文:Attention Is All You Need,系统提出了Transformer的原理、构建和大模型算法。此文的开创性的思想,颠覆了以往序列建模和RNN画等号的思路,开启了预训练大模型的时代。 Transformer是一种基于注意力机制的深度神经网络,可以高效并行处理序列数据,与人的大脑非常近似。Transformer包括以下基本特征: (1)由编码组件和解码组件两个部分组成; (2)采用神经网络处理序列数据; (3)拥有的训练数据和参数越多,它就越有能力在较长文本序列中保持连贯性和一致性; (4)输入文本必须经过处理并转换为统一格式,然后才能输入到Transformer; (5)并行处理整个序列,从而可以将顺序深度学习模型的速度和容量扩展到前所未有的速度; (6)引入“注意机制”,可以在正向和反向的非常长的文本序列中跟踪单词之间的关系; 训练和反馈,在训练期间,Transformer提供了非常大的配对示例语料库(例如,英语句子及其相应的法语翻译),编码器模块接收并处理完整的输入字符串,尝试建立编码的注意向量和预期结果之间的映射。
03 大模型的构建模式 Pattern of Construction
大模型构建可以划分为4层:硬件基础设施层、软件基础设施层、模型MaaS层和应用层。 图 4 大模型的结构层级 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》) 模型即服务MaaS层是一套大模型的核心。我们使用的大模型应用(例如文心一言)必须通过这一层的模型(文心大模型4.0)提供的能力来实现对话、写作、分析、写代码等各种用户级功能。通过企业服务模块的应用程序编程接口(API)形式,大模型向企业客户或应用开发者提供多种能力调用,包括模型推理、微调训练、强化学习训练、插件库、私域模型托管等。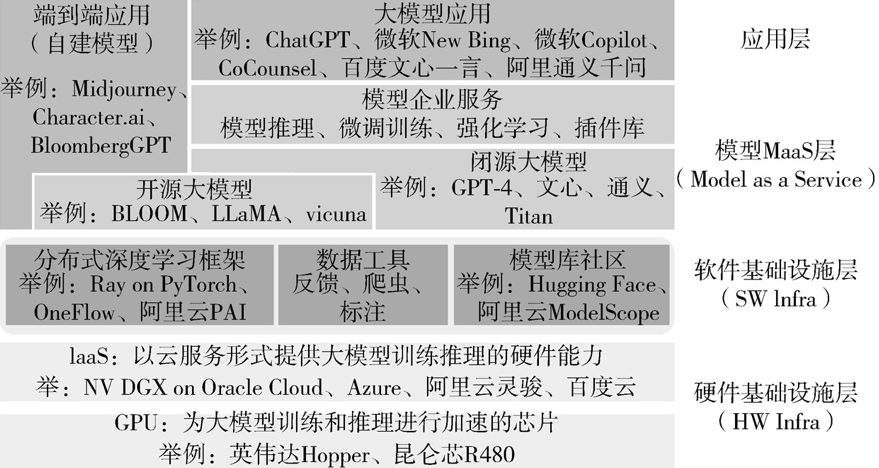
04 大模型的应用模式 Pattern of Application
图 5 构建在基础大模型上 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》) 大模型的分工越来越明确。日益增多的大模型,特别是开源大模型可以实现不同的组合,将大模型乐高化,构成大模型集群。未来具有资金、技术、数据绝对优势的企业构建基础模型,提供类似于公有云这类基础设施服务。绝大多数企业,基础行业特征和对业务的理解,构建轻量级业务领域模型,直接服务于业务。 小切口、大纵深。一个特别好的思路是:把自己的工作、产品拆分成20个、50个细化的场景,然后才能看出AI可以在哪些场景帮上忙。
05 大模型的企业应用路径 Path of Enterprise Application
图 6 大模型的企业应用路径 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》) 企业根据业务需求考虑第三方闭源大模型能否满足需求,若可以满足,则使用第三方闭源大模型与其开放的API对接。第三方闭源大模型包括百度的文心一言、阿里的通义千问、科大讯飞的讯飞星火、腾讯的腾讯混元等。 若第三方闭源大模型不能满足业务需求,那么可以考虑采取开源大模型,如果可以满足要求,那么可以在开源大模型上做微调训练、强化学习等,大模型完善工作。如果开源大模型要重做预训练,则需要进一下修改开源大模型的算法和数据集,在企业自有的算力上做预训练。开源大模型包括Facebook的Transformers、BART、LLaMA,Google的ELECTRA。百度的ERNIE、ALBERT。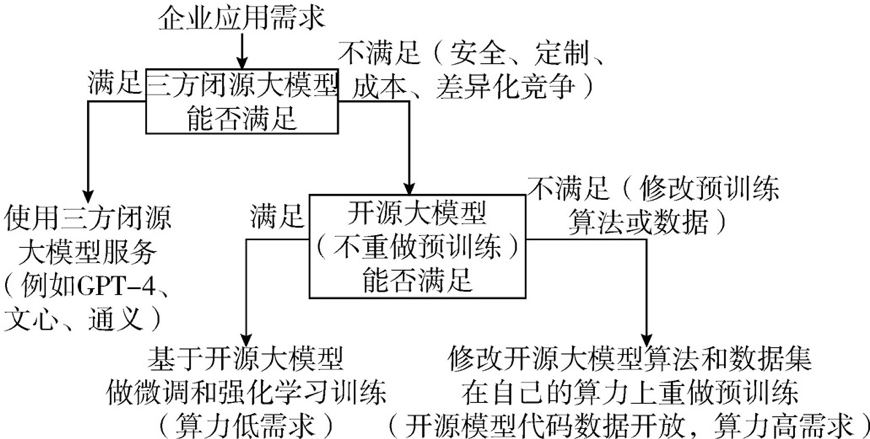
06 大模型的产业化周期性 Industrialization Periodicity
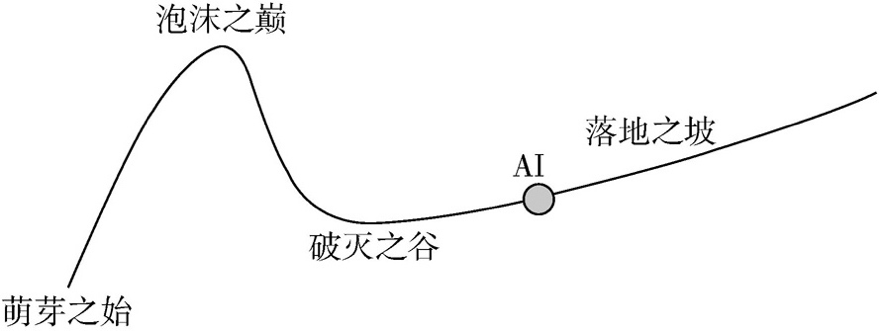
计算机、互联网、人工智能,一代又一代的技术发展,出现过许多泡沫周期。现在,大模型来了,我们在周期里的什么位置呢? 如果以大模型为主语,那就处在这个小周期的第一个上升波段,会出现过度乐观情绪,未来还会回调,然后再上升。 图 7 大模型所处的周期阶段 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》) 如果以人工智能为主语,那现在便处于第二个上升波段,已经过了曾经的泡沫巅峰,也过了破灭的谷底,开始落地爬坡。后面会有波折,但不影响大的趋势。 图 8 人工智能视角的大模型周期阶段 (图片来源于《大模型时代:ChatGPT开启通用人工智能浪潮》)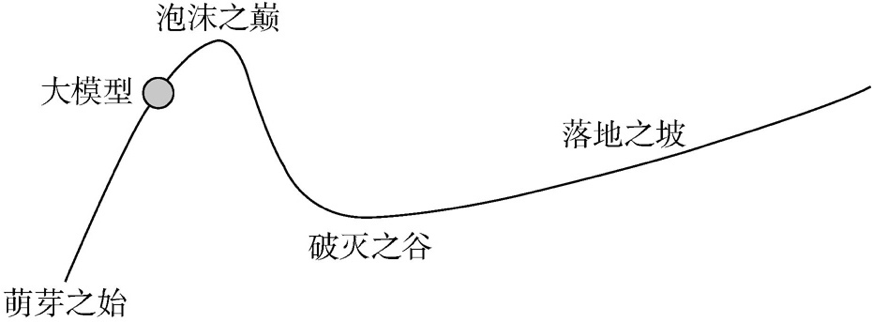
07 介绍一些大模型工具 Some Tools

参考文献 1.《大模型时代:ChatGPT开启通用人工智能浪潮》龙志勇、黄雯,中译出版社。 2.《BERT基础教程:Transformer大模型实战》作者:苏达哈尔桑·拉维昌迪兰,翻译:周参,人民邮电出版社。
文章作者:孙亚东 封面设计:Lina
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/33048.html