
DEEP LEARNING
由浅入深探索基于深度学习的词向量构建
WORLD VECTOR
概述
众所周知,编程语言是一种机械的、缺乏活力的语言,换句话说,它是一种“硬语言”,而汉语、英语等自然语言是含义、用法多变的“软语言”,此外,自然语言的“软”还体现在新的词语或新的含义会随着时代的发展不断出现。
我们的语言是由一个个文字构成的,而语言的含义是由单词构成的。换句话说,单词是含义的最小单位(在英语、日语等语言中亦是如此),因此,为了让计算机理解自然语言,让它理解单词的含义是最重要的事情了。
本篇文章将由浅及深,逐步讲述将单词向量化的原因和方法,你将了解到:

词向量是什么?
词向量的构建为什么重要?
怎样构建词向量?
我们将探讨一些巧妙地蕴含了单词含义的表示方法,具体来说我们将探讨以下3种方法:
基于同义词词典的方法。
基于计数的方法。
基于推理的方法(word2vec)。
最后我们将对利用self-attention优化词向量的BERT方法进行展望。
基于同义词词典的方法

要表示单词的含义,首先可以考虑使用人工方式来定义单词含义。人们已经尝试过很多人工定义单词含义的活动,但是目前被广泛使用的是一种被称为同义词词典的词典,在同义词词典中,具有相同含义的单词(同义词)或含义类似的单词(近义词)被归类到同一个组中。比如,使用同义词词典,我们可以知道car的同义词有automobile、motorcar等。
另外,在自然语言处理中用到的同义词词典有时会定义单词之间更细粒度的关系,比如“父类——子类”关系、“整体——部分”关系。
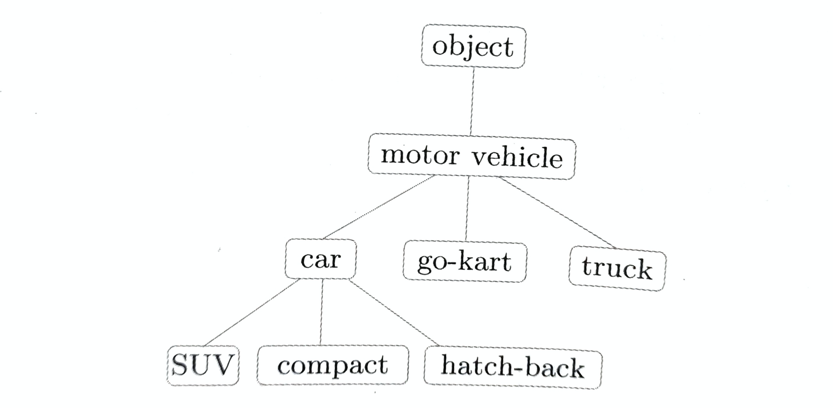
像这样,通过对所有单词创建近义词集合,并用图表示各个单词之间的关系,可以定义单词之间的联系,利用这个“单词网络”,可以教会计算机单词之间的相关性,并利用这种关系,让计算机做一些对我们有用的事情,比如应用于信息检索场景中。
但这样的构建与表示方法工作量较大且难以维护,同时在互联网时代,新词层出不穷,无疑为网络的更新增加了更多难度。
基于计数的方法
1、单词的分布式表示
世界上存在各种各样的颜色,颜色可以用文字命名:极光绿、天空蓝。也可以通过RGB三原色来表示。使用RGB这样的向量表示可以更准确地指定颜色。例如(255,24,150)和(255,26,151)两个颜色几乎无法用肉眼区别,但是向量却可以表示出它们之间的细微差别;再比如我们虽然难以准确想象(232,23,30)这个颜色长什么样,但我们通过向量可以肯定它是红色系的颜色。既然向量有这样的好处,那能不能将这样的向量表示方法运用到单词上呢?

分布式假设
分布式假设所表达的理念非常简单:“某个单词的含义由它周围的单词形成”,即单词本身没有含义,单词含义由它所在的上下文(语境)形成。如“我 吃 鸡腿”和“我 啃 鸡腿”,“吃”和“啃”所在的语境相似,我们可以进而推出“吃”和“啃”相关性较强。
即我们会根据一个单词的上下文来决定这个单词的含义,一般情况下将左右两边相同数量的单词作为上下文。
共现矩阵
如何基于分布式假设使用向量表示单词?最直截了当的实现方法就是对目标词周围单词数量进行计数。具体讲就是在关注某个单词的情况下对它周围出现了多少次什么单词进行计数,然后再汇总,称这种做法为“基于计数的方法”。
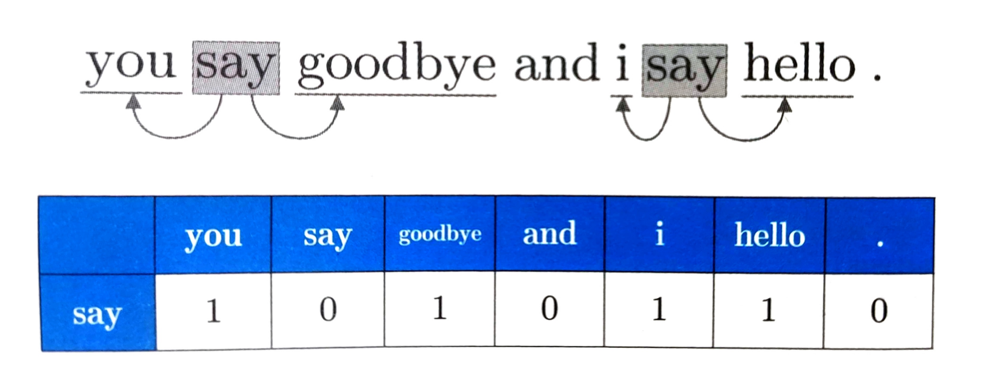
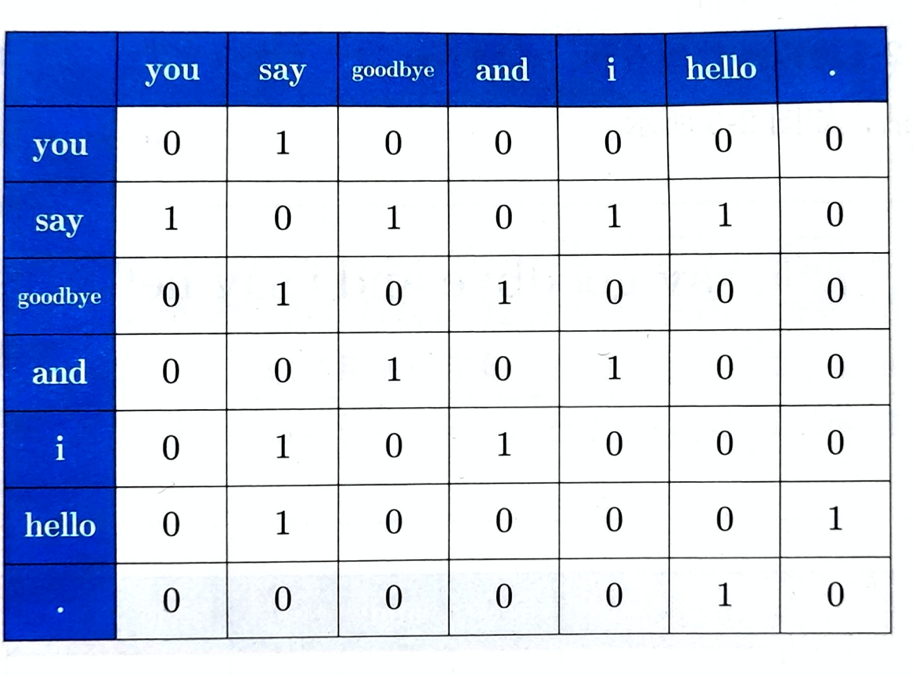
这个表格的各行对应相应单词的向量,因为表格呈矩阵状,所以称为共现矩阵,使用共现矩阵,可以获得各个单词的向量。
有了词向量之后,我们可以根据词向量做很多事情,除了文本分类任务,还可以通过计算词向量之间的欧式距离、余弦距离来寻找近义词。
2、基于计数方法的特点总结
基于计数的方法有着显著的优点,如算法简单易懂、语料易获得且无需标注。但这种方法也存在着一定的弊端,基于计数的方法在面对小型语料库时可能会因为语料库规模较小而导致词向量表示不完全,但在处理大型语料库时也会出现问题:
据统计,现实生活中汉语词汇量约为40万个,英文的词汇量更是超过100万个。因此如果语料库的单词数量非常大,那么基于计数的方法就需要生成一个100w*100w的庞大矩阵。即一个单词的向量维度可能高达100w维,用这么高维的词向量作为下游神经网络的输入层不可避免将在后续进行更加复杂的计算,显然是不现实的。即使是进行降维运算,运算量也是极大的,需要大量的计算资源和时间。
基于推理的方法
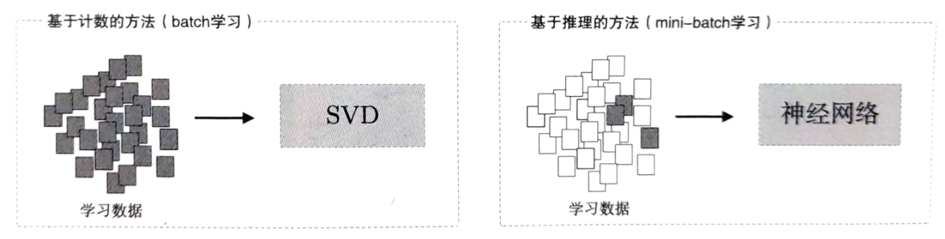
基于计数的方法需要一次性处理全部的学习数据,开销较大,对硬件性能要求高。而基于推理的方法通常在mini-batch数据上进行学习,这意味着网络一次只需要学习一部分数据。
顾名思义,基于推理的方法主要操作是“推理”。如:当给出周围的单词(上下文)时,预测“?”处会出现什么单词,这就是推理。
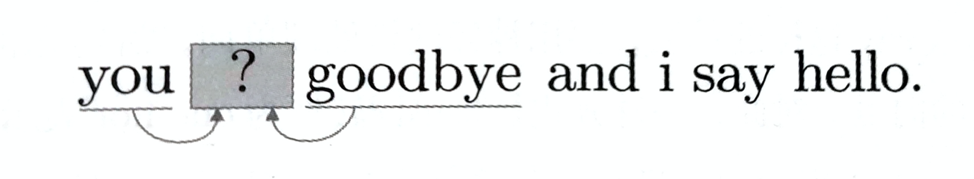
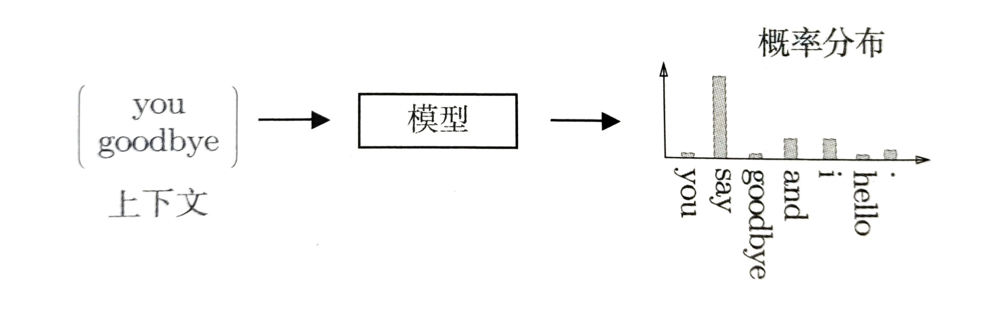
这个模型接收上下文信息作为输入,并输出预测的各个单词的出现概率,在这样的框架中使用语料库来学习模型,使之能做出正确的预测,作为模型学习的产物,我们得到了单词的分布式表示。
1、神经网络中单词的处理方法
在开始任务之前,我们并没有得到词汇的向量表示,而神经网络无法直接处理单词,因此需要先将单词转化为固定长度的one-hot向量。在one-hot表示中,只有一个元素是1,其他元素都是0.
和上一节一样,我们用“You say goodbye and I say hello.”这个一句话的语料库来说明。这个语料库一共有7个单词,此时各个单词可以转化为如下的one-hot表示。
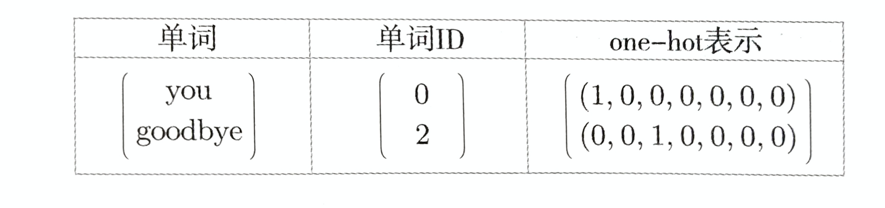
one-hot向量的维数和语料库中词汇的种数相等,并将单词ID对应的元素设为1,其他元素为0
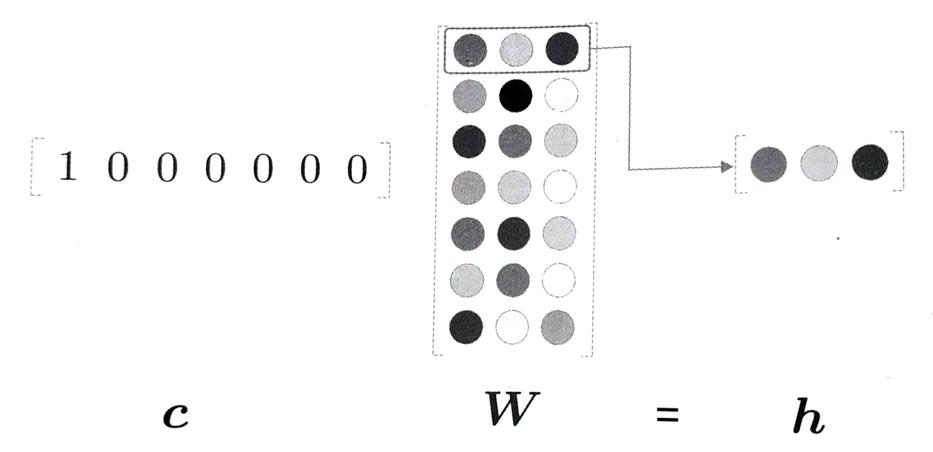
只要将单词表示为向量,这些向量就可以由构成神经网络的各种层来处理。比如对于one-hot表示的某个单词,使用全连接层对其进行变换的情况如下图:
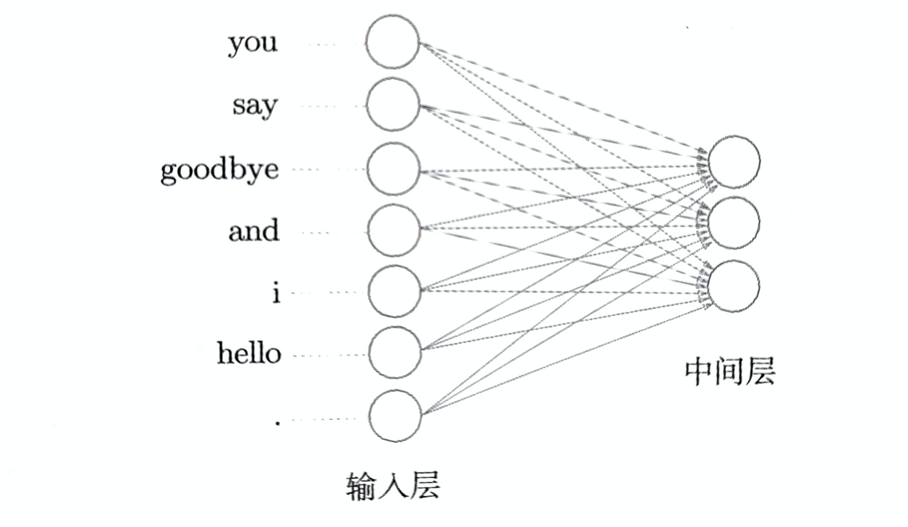
全连接层通过箭头连接所有节点,这些箭头拥有权重参数,它们和输入层神经元的加权和成为中间层的神经元
在输入层是one-hot向量的情况下,上述全连接对应的中间层相当于是提取的权重矩阵的对应行向量。
2、简单的word2vec
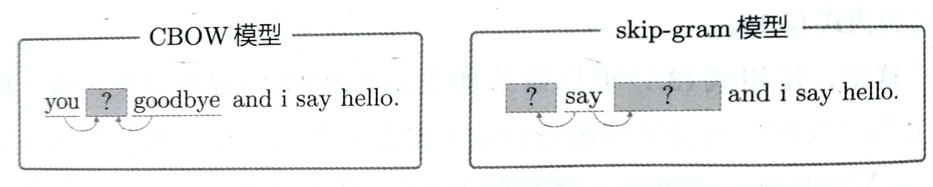
至此准备工作已经完成,可以进行word2vec的实现了。准确地说,接下来将介绍word2vec中使用的两个神经网络模型——CBOW模型和skip-gram模型,前者将详细介绍,后者将类比介绍。
CBOW模型
CBOW模型是根据上下文预测目标词的神经网络,“目标词”是指中间的单词,它周围的单词是“上下文”。这个上下文用[\’you\’,\’goodbye\’]这样的单词列表表示,将其转换为one-hot表示,以便CBOW模型可以进行处理。通过训练这个CBOW模型,使其能够尽可能地正确预测,在训练过程结束后,我们可以获得单词的向量表示。
下图是一个简单的CBOW模型的网络,它有两个输入层,经过中间层到达输出层。这里由输入层到中间层的变换由两个相同的全连接层(权重矩阵为Win)完成,从中间层到输出层神经元的变换由另一个全连接层(权重矩阵为Wout)完成。
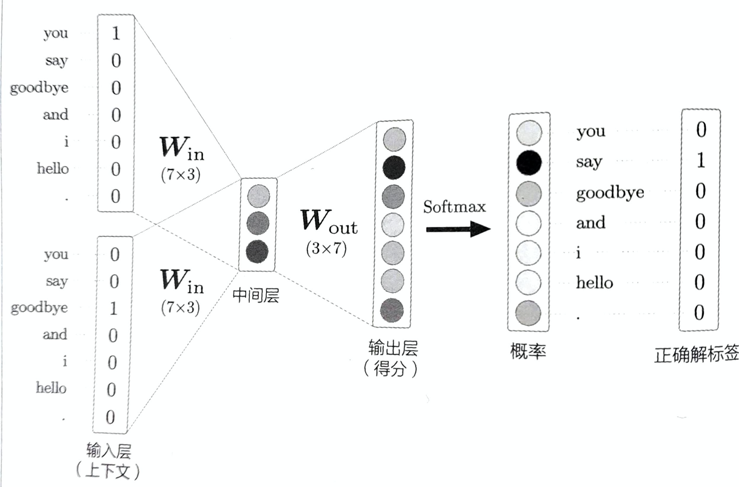
中间层的神经元是各个输入层经全连接层变化后得到的值的“平均”。就上例而言,经全连接层变换后,第1个输入层转化为h1,第2个输入层转化为h2,那么中间层的神经元是(h1+h2)/2
这个输出层一共有7个神经元,这些神经元对应于各个单词,输出层的神经元是各个单词的得分,它的值越大,就说明对应单词的出现概率就越高,对这些得分应用softmax函数,就可以得到概率。将这个概率与正确解标签进行对比,计算损失,然后反向传播、更新Win和Wout矩阵参数。如此反复,训练若干次后得到的Win矩阵就是我们要的词向量矩阵,其中每一行为一个单词的词向量。
CBOW模型的学习就是调整权重,以使预测准确,其结果是权重Win学习到蕴含单词出现模式的向量。权重Win的各行保存着各个单词的分布式表示,通过反复学习,不断更新各个单词的向量表示,以正确地从上下文预测出应当出现的单词,如此获得的向量很好地对单词含义进行了编码,这就是word2vec的全貌。
skip-gram模型
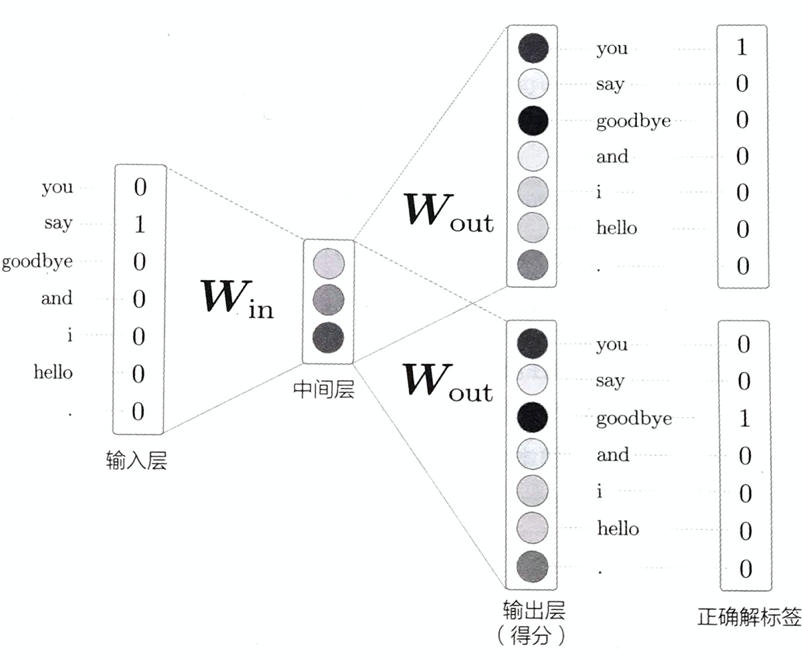
skip-gram模型是反转了CBOW模型处理的上下文和目标词的模型,请类比理解,这里不再详述。
3、基于推理的方法特点总结
使用word2vec方法训练词向量,由于引入了神经网络,可以更加深入地提取词语信息。它的优势在于每次训练所需数据量小,相比于基于计数的方法开销小,对硬件要求更低,且词向量是基于神经网络反复训练得到的,更能表示词语的特性。同时训练数据易获得,我们只需要选用具有正常语言逻辑的文本内容经过格式转换就可以作为训练数据,且由于无需标注,可以节省大量人力时间成本。
但经过上述方法训练得到的词向量,无法表示不同语境下相同词语含义的细微区别。例如“今天午餐又吃了顿方便面,感觉很没营养。”和“你看的这些三流小说太没营养了吧?”两个句子中的“营养”实际表达了不同的含义。但经过word2vec训练得到的词向量却无法表达出二者的区别,这就需要我们考虑相同词语在不同语境下融合上下文后的信息表达,通过BERT自然语言处理通用模型可以很好地进行解决,这里点到为止,尽请期待下次分享!
文章作者:潘嘉伟
手绘插画:岳 媛
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/33114.html