
团队简介
我们是光大科技有限公司智能云计算部运维服务团队分布式数据库项目组,致力于促进集团数据库技术转型,提供高可用、强一致等特性的分布式数据库服务,降低数据库运维难度,保障数据安全,助力集团数字化转型。我们将不定期与大家分享数据库与分布式领域相关的技术文章和实践经验,期待与大家共同探讨和进步。
引言
说到索引,很多人肯定会立马想到MySQL中使用的B+树这种索引结构,毕竟是面试常考题型。我在准备面试的过程中,也只是浅显的了解到MySQL在创建主键时会自动创建一个主键索引,除此之外,还有联合索引、唯一索引等索引结构。创建主键索引的时候会通过B+树来存储数据。所以,MySQL为什么要使用B+树作为索引?还有没有其他索引结构?索引到底是干什么的?带着这些疑问,我查阅了相关的资料,同时以项目背景为出发点,希望对索引做一次重新认识。
要实现一个最最简单的数据库,利用Bash函数就可以做到:
#!/bin/bashdb_set () {echo \"$1,$2\" >> database}db_get () {grep \"^$1,\" database | sed -e \"s/^$1,//\" | tail -n 1}
这两个函数就是一个最简单的键值数据库。存数据时,不断在database文件末尾添加一行键值对即可;查数据时,通过grep会找到数据及之前所有的修改记录。这个数据库文件就像一个日志,不断的在末尾追加数据。由于传统磁盘对顺序写表现出的优异性能,数据库的写入性能会很高。但是有一个问题,如果一直往该文件中添加数据,久而久之,这个文件会变得异常大,文件中会出现很多重复的数据。同时,查找数据也是个问题,每次都要从头到尾找一次,别人都下班了,你还在等着查询结果。
既然文件很大,把它拆分成一个个小文件不就行了,同时定期对这些小文件进行压缩,剔除掉重复的和不要的数据,节省存储空间。但是查数据的问题怎么解决。现在的方式,每次找数据都要对整个表扫描一次,黄花菜都凉了,解决办法就是使用索引。
索引是什么

索引的本质就像一部字典前面的检索页,查字典时,通过拼音开头的字母可以快速查找到某个字的位置,索引也一样。通过给数据库中的数据添加类似路标的记号,这样从索引中就可以直接检索到该数据的位置。
让我们用最简单的哈希索引试试,哈希索引就是在内存中将每个键都映射到数据文件中的字节偏移量,这个偏移量就是键对应值的位置。查找时,只要通过哈希映射找到偏移量,然后寻找该位置读取即可。
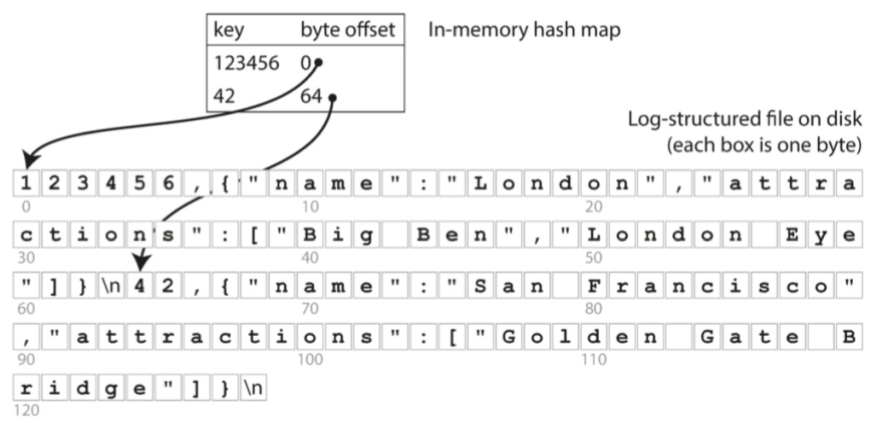
图片来源于网络
听起来是个不错的办法,但是大部分数据库都不会使用哈希索引,因为实际的数据库系统需要考虑的东西很多,比如发生崩溃后怎么处理,数据如何保证不丢失。除此之外,哈希索引需要整个放进内存中,如果我的键很多,散列冲突的可能性也会变大,同时,对于数据的范围查询支持也不够。
有没有更好的办法?
LSM-Tree索引
聪明的大脑已经帮我们想出了解决办法。Google传奇工程师Jeff Dean等人开发了一个可持久化的键值数据库LevelDB。LevelDB使用了一种称之为SSTable(Sorted String Table)的表结构,顾名思义,SSTable 中数据会按照键的顺序排列,同时LevelDB在内存中维护着一个称之为LSM-Tree(Log Structured Merge Tree)的索引结构,LSM-Tree通过某种平衡树(比如基数树)结构保证键的有序,在超出树的容量后,就将其作为SSTable写入磁盘中,同时新的数据会被写入一个新的 LSM-Tree中。
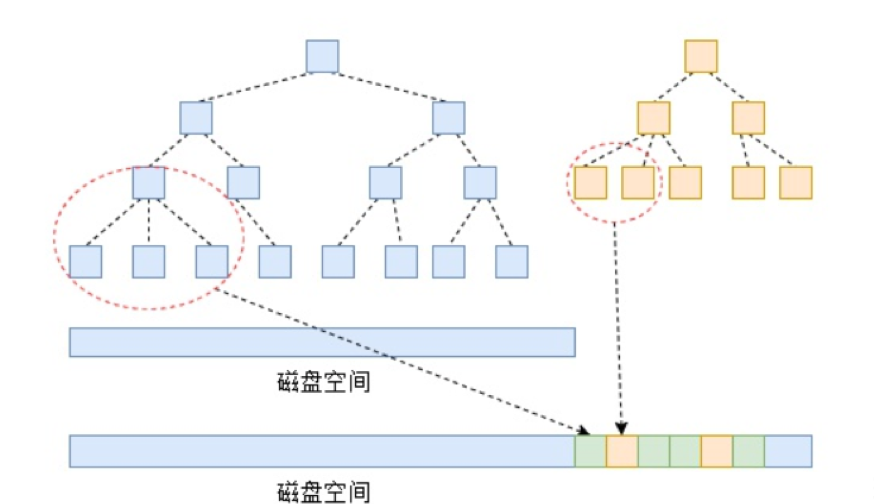
图片来源于网络
正如文章之前说的,LevelDB会定期的在后台执行合并操作,将多个SSTable压缩为一个,以去除重复的或删除不用的数据。那么如何查找数据呢?既然键是有序的,查找就好办多了,比如使用二分查找,时间复杂度可以降到O(log2n)。LevelDB会先在内存中查找关键字,然后在最近的SSTable中查找,然后在之前的表中查找。当然,在实际的实现中,LevelDB对细节做了很多的优化,比如使用多层压缩来提升性能,这些都是后话了。
除了LevelDB,Facebook基于LevelDB开发了性能更好的RocksDB,国内大名鼎鼎的分布式数据库TiDB底层存储就使用的RocksDB。
B+Tree索引
能不能使用B+树来做索引?
当然可以,开源数据库BoltDB就使用B+树来实现索引,而etcd的底层就使用的BoltDB。除此之外,常见的关系型数据库(比如MySQL、PostgresSQL等)也常常使用B+树来实现索引。相较于键值数据库,MySQL等关系型数据库在数据存储上更为复杂,比如Compact、Dynamic行格式等,此处不做深究。所以,B+树索引有什么优点,为什么要用它来做索引。
基于LSM-Tree索引的数据库由于顺序写入的特点,有着很高的写入吞吐量,因为所有的前台写入都发生在内存中,并且所有后台写入都保持着顺序访问的模式。但是对于查询来说,往往需要在多个SSTable中依次查找,导致读取的吞吐量下降。而B+树就不同了,在B+树中只有叶子节点存储着数据,并且叶子节点之间通过链表顺序连接。在查找时,通过根节点确定数据的范围,然后顺着叶子节点的链表查找即可。在找到数据行对应的页之后,数据库会把整个页读入到内存中,并在内存中查找具体的数据行。
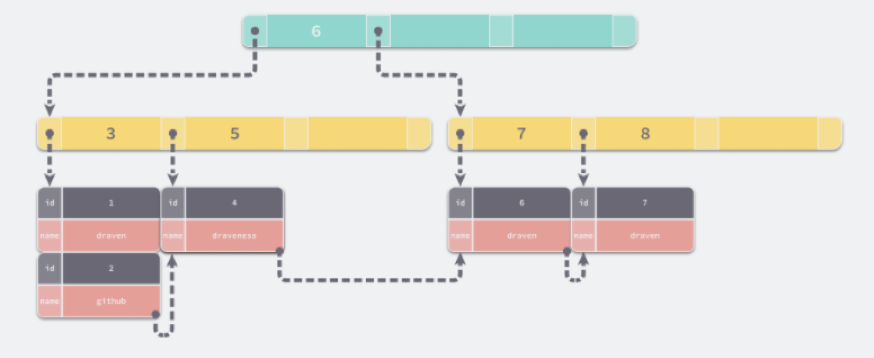
图片来源于网络
这就是为什么MySQL等数据库不使用B树来实现索引的原因,B树中每个节点都会存储数据,在查找时,总是需要从根节点向下遍历子树查找满足条件的数据行,这个特点带来了大量的随机I/O。
从B+树的特点中,我们也能看到,其对于读取数据有着很好的性能,同时对于条件范围查询也能很好的支持。但是由于存储数据时会发生重复的随机磁盘写入,写入性能较差。为此,我也通过实验比较了几种使用不同索引结构的数据库,实验设备为公司电脑,环境为Centos7虚拟机(4core+4GB+40GB磁盘)。
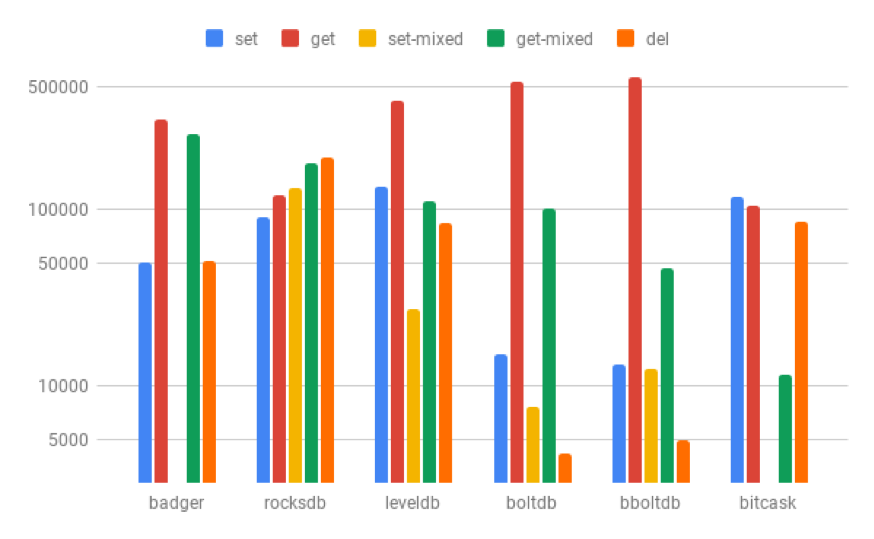
可以看到,基于B+树索引的boltdb和bboltdb的读取吞吐量很高,但是写入吞吐量却很低,而rocksdb和leveldb等基于LSM的数据库在写入吞吐量上表现优异,读取稍逊。
总结
数据库使用索引可以加快查询的速度,LSM树索引的写入性能优异,而B+树索引的读取性能更高,每条路上都有自己独特的风景,我们需要场景来选择合适的索引结构。除此之外,还存在着为搜索引擎设计的全文索引、模糊索引等。而引入索引的过程也造成了写的缓慢,这也是需要权衡的事。
参考文献
-
https://draveness.me/whys-the-design-mysql-b-plus-tree/
-
《design data intensive application》——Martin Kleppmann
-
https://github.com/boltdb/bolt
-
https://github.com/google/leveldb
-
https://shiniao.fun/posts/%E5%9F%BA%E4%BA%8Elsm%E7%9A%84%E6%95%B0%E6%8D%AE%E5%BA%93%E9%94%AE%E5%80%BC%E5%AD%98%E5%82%A8/
往期回顾
从Mark Word中看Java锁的升级
统一日志中心关键设计揭秘 -索引生命周期管理

漫谈Redis与缓存

企业级监控管理平台建设内幕


扫二维码
关注EBCloud
作者:朱哲哲
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/33209.html