
团队介绍
我们是光大科技有限公司智能化平台团队混沌工程项目组,致力于打造金融领域全业务领域的混沌工程平台,平台通过一系列的故障注入实验来验证各类系统在未知、突发故障场景下的真实反应,从而识别系统潜在风险,持续增强系统对故障风险的免疫能力,最大限度减少系统潜在故障对生产业务的影响。
我们团队拥有经验丰富的混沌工程领域技术专家和研发工程师,将不定期分享相关领域的技术文章和解决方案,期待与大家共同探索技术的落地实践和发展趋势。
一、引言
作为工程师,最不愿碰到的便是半夜被电话叫醒,开始紧张的查验问题、处理故障以及恢复服务。或许就是因为一个很小的变更,因某种未预料到的场景,引起蝴蝶效应,导致大面积的系统混乱、故障和服务中断,对客户的业务造成影响。系统虽有完善的监控告警和故障处理机制,但这些事后的响应和被动的应对却无法提前发现复杂系统中隐藏的缺陷。
面对这样的问题,有没有什么有效的解决办法呢?
二、技术概念与现状
混沌工程(Chaos Engineering)便是为了解决该问题而发展出来的一门学科。混沌工程旨在提升分布式系统的容错性,通过在分布式系统上进行由经验指导的受控实验,观察系统行为反应并根据实验结果发现系统缺陷,从而建立系统在规模增大时应对因意外条件引发混乱的能力和信心。
最初在2008年,Netflix为了快速了解其服务是否足够健壮而创建了混沌猴子(Chaos Monkey)实验工具,通过随机终止生产环境中的容器实例,观察系统稳定性。之后在此基础上逐步扩展出了猴子军团工具集(Simian Army)、故障注入测试(FIT)、混沌金刚(Chaos Kong)、Gremlin等工具。
经过多年的发展,混沌工程已发展成为一门包含完整指导思想、多平台测试工具及多种实验框架的学科。如今:微软、谷歌、亚马逊等诸多公司均通过引入混沌工程来提升现代架构的可靠性和容错性。
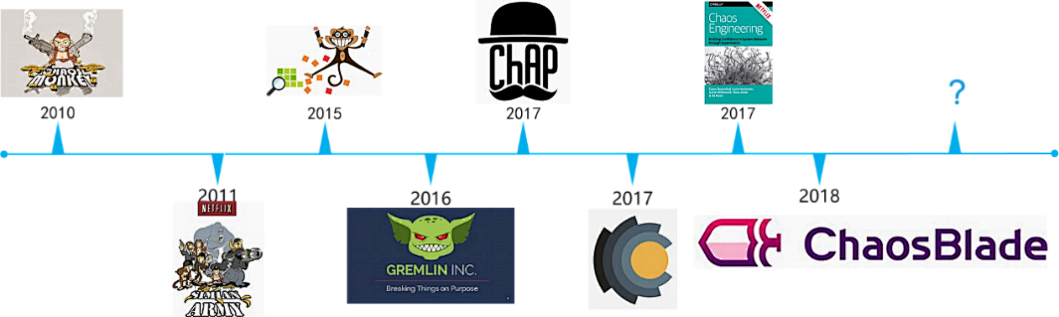

从上述场景来看,混沌工程似乎与传统测试在关注点上有很大的重叠,但其实相比于传统测试,混沌工程有着本质上的区别。
在传统测试中,测试一般来说只会产生二元的结果,即验证一个结果是真还是假,从而判定测试是否通过,但并不能让我们发掘出对于系统未知的、尚不明确的认知。
而混沌工程实验的可能性是无限的,根据不同的分布式系统架构和不同的核心业务价值,实验可以千变万化。例如,模拟整个云服务区域或整个数据中心故障,或者强制系统节点间的时间不同步,开发人员可针对这些实验结果对系统做进一步的优化,从而提高对系统真实弹性水平的信心。
在目前常见的工具中,不同的实验工具支持特定的单一场景,以ChaosBlade和ChaosMesh对比为例:ChaosBlade的长处在于对应用层的支持(如支持Dubbo、Servlet等)以及提供了对中间件和数据库的实现机制。
ChaosMesh的优势在于对PaaS平台的支持,但从实际生产的角度来讲,混沌工程应该覆盖各层级、多语言、前端及服务端的多种技术架构,目前已知的混沌工程工具尚未做到这一点。
三、光大科技
在混沌工程领域的实践
随着互联网金融服务的快速发展,光大科技紧随云原生领域发展趋势,不断完善云平台的生态建设。针对越来越复杂的分布式架构,智能云计算部近期推出了基于混沌工程的全业务链故障演练平台,利用混沌实验最小化爆炸半径,提前探知系统风险,通过架构优化和改进来解决实际问题。
整体来说,全业务链故障演练平台综合目前各种工具作为故障注入套件,项目范围涵盖了IaaS、PaaS及SaaS层,实现了从前端业务入口至底层服务器的全业务链条的故障演练场景,还可以针对客户的具体需求进行扩展。比如,扩充对特定中间件及数据库的支持,对多语言、多架构服务端应用的支持。
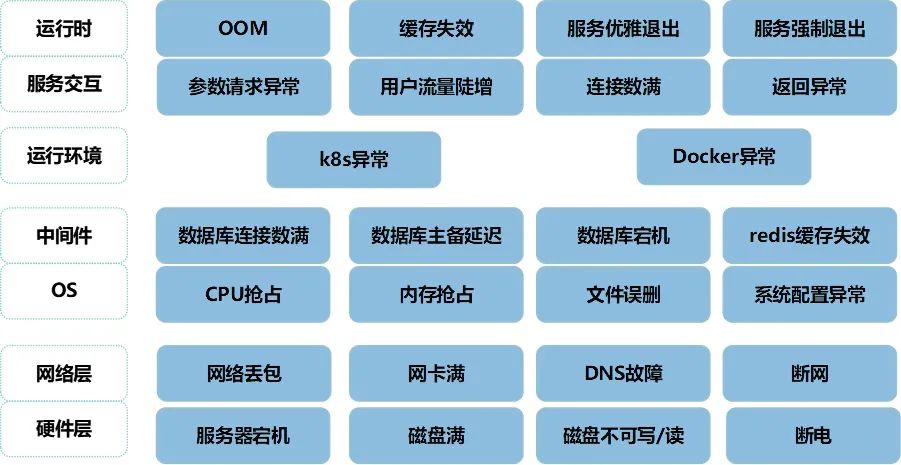
平台支持的部分故障演练场景如下:
以下是平台模块之间的交互流程:
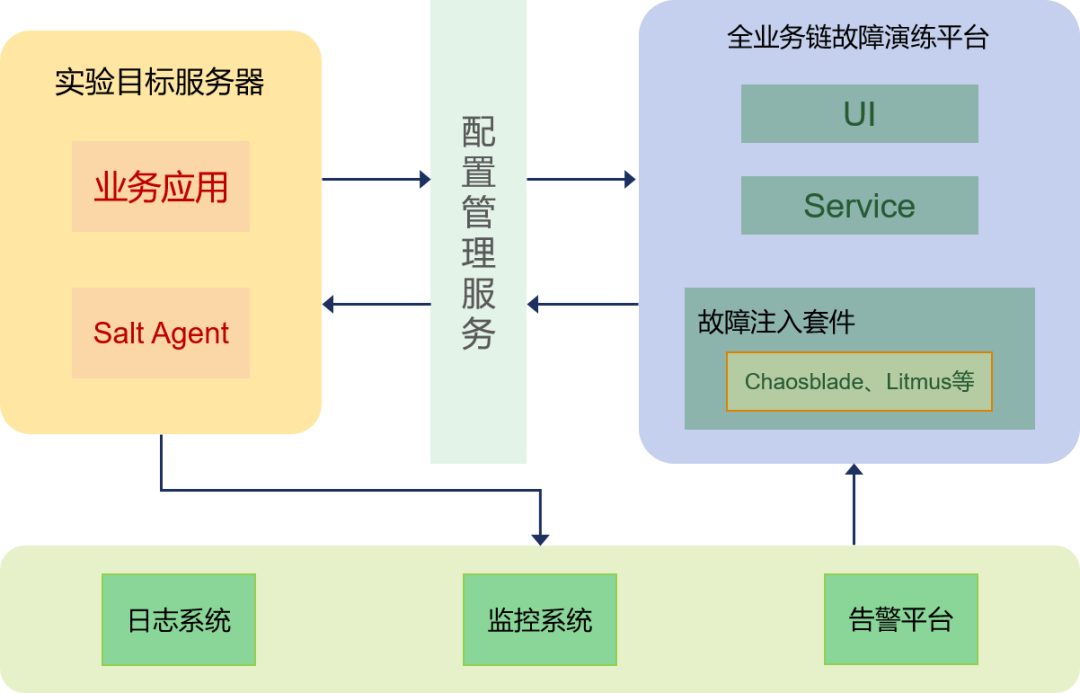
借助配置管理服务实现故障注入和恢复的指令下发,以应用系统和设备(虚拟机/物理机)为维度实现权限管控,并将最小攻击目标限定在单个IP或进程上。平台通过和公司现有云鹰平台的告警系统、监控系统、日志系统相关联,可以实时查看演练时的异常指标和应用日志详情,进而从演练准备(评估爆炸半径)、故障注入、故障恢复、报警验证到生成演练报告,形成一套基本的故障演练实施流程。平台的建成将在发现分布式系统未知故障、打造韧性系统、验证监控有效性、梳理微服务之前强弱依赖关系等方面发挥重要作用,并为系统智能运维的模型训练提供真实的生产数据。
全业务链故障演练平台受众广泛,针对科技公司各种复杂的分布式架构系统,架构师可以借助平台验证系统架构的容错能力;开发运维人员可根据实验结果提高故障的应急效率;测试人员通过实验可以提前暴露线上问题,降低故障率;产品和设计人员则可通过多次实验不断提升客户的使用体验。
四、后续规划
当前在处理大规模系统时,100%的健康运行几乎是不可能实现的,处在部分故障中的系统要求仍能正常运行对外提供服务,这就需要架构本身具备 Resilient 能力,这里的Resilient即为韧性(具备恢复能力)。
在过去,企业常通过灾备技术应对可能出现的系统风险,如今借助全业务链故障演练平台,企业将通过运维模式的改进真正实现韧性架构,降低经济损失,提高故障免疫力。
应用系统的稳定性、容错性和可恢复性需要多方面的保证,对应用系统实施混沌工程是建立对系统抵御生产环境中失控条件的能力以及信心的一个重要手段。
为了达到预期的效果,后续将不断完善全业务链故障演练平台,为提升业务系统的稳定性做更好的服务。
作者:张宏源
浅谈云计算之ELB(弹性负载均衡)
RabbitMQ高可用镜像队列集群
探索零信任下的应用安全建设
一种时间序列数据的异常检测方法
搜索微信公众号 EBCloud
关注我们吧!
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/33484.html