
最近在工作中遇到一个问题,如何对kubernetes集群内容器文件传输进行流量限制。我们都知道在kubernetes集群中可以使用kubectl cp来进行pod与本地之间的文件传输,那么可不可以使用kubectl cp对集群内容器的文件传输进行限流呢?kubectl cp在传输大文件(目录)时会不会影响pod本身业务的网络访问呢?如果会,该如何对kubectl cp的传输进行限制以保证pod本身业务的正常运行呢?带着以上问题,我们来了解一下kubectl cp是怎样实现的,看看能否对以上问题提出解决方案。
省流结论:
通过研究kubectl cp的实现原理,不建议使用kubectl cp来实现集群容器内大文件传输的流量限制,具体原因如下:
– kubectl cp依赖tar命令实现,如果容器内没有tar命令,kubectl cp无法完成文件传输。
– 通过kubernetes集群中的max-connection-bytes-per-sec参数来限制每次连接的带宽,可以实现对kubectl cp传输文件的速率进行限制,配合kubernetes其他对并发请求数量的控制策略可以实现流量控制。但该设置对整个集群生效,所造成的影响不只是对kubectl cp进行限制。
综合以上两点考虑,不建议使用kubectl cp在生产环境中对容器内的文件传输进行限流。
为了弄清楚kubectl cp背后的工作流程,我们从一个具体例子入手:
kubectl cp -v=9 test-kubectl/nginx-69687f68cb-p79t5:temp.txt ./temp.txtkubectl -v设定日志输出级别,-v=9可以看到背后的http请求日志,通过这种方式我们可以详细地看到在命令行键入kubectl cp后,发起了哪些http请求。
POST https://xxxxxx/kubernetes/region/api/v1/namespaces/test-kubectl/pods/nginx-69687f68cb-p79t5/exec?command=tar&command=cf&command=-&command=temp.txt&container=nginx&stderr=true&stdout=true 101通过kubectl cp打印出来的日志我们不难发现,kubectl命令行向kubernetes集群的apiserver发起了一个exec请求,我们来看一下kubectl如何发起的exec请求。
Kubectl cp处理流程
kubectl cp命令的处理逻辑,是由kubectl/cmd/cp.go实现的。
kubectl cp首先会检查参数数量是否有误:
func (o *CopyOptions) Validate() error {if len(o.args) != 2 {return fmt.Errorf(\"source and destination are required\")}return nil}
之后抽离源地址与目的地址并验证有效性:
srcSpec, err := extractFileSpec(o.args[0])destSpec,err := extractFileSpec(o.args[1])
之后根据pod地址是在源地址处或目的地址处进行不同处理:
if len(srcSpec.PodName) != 0 {return o.copyFromPod(srcSpec, destSpec)}if len(destSpec.PodName) != 0 {return o.copyToPod(srcSpec, destSpec, &exec.ExecOptions{})}
我们先以pod为源地址的情况进行介绍,两者原理上是相同的。对于pod方为源地址的情况,执行copyFromPod流程,实现过程为先将pod文件(目录)打包,
options := &exec.ExecOptions{...Command: []string{\"tar\", \"cf\", \"-\", t.src.File.String()},}o.execute(options)
可以看到在执行cp的过程中创建了一个options对象,其中包括要对容器执行的不同的command,在execute阶段,kubectl通过向kube-apiserver发起exec请求来执行这些命令。
kubectl向kube-apiserver发起请求
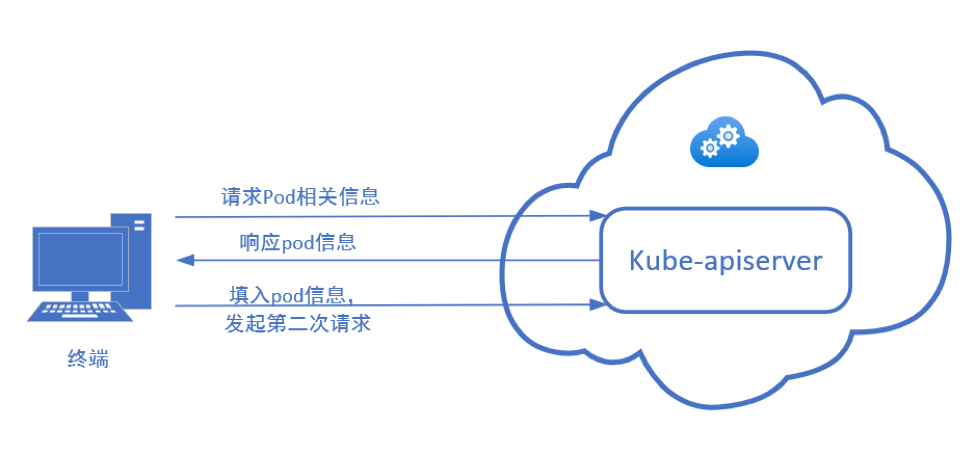
kubectl实际上向kube-apiserver发起了两次请求,第一次请求是为了构建第二次请求获取pod相关信息,第二次请求则是向kube-apiserver发起的exec请求。
第一次根据pod名称与namespace名称获取pod对象。
p.Pod,err=p.PodClient.Pods(p.Namespace).Get(context.TODO(),p.PodName,metav1.GetOptions{})if err != nil {return err}GET https://xxxxxx/kubernetes/region/api/v1/namespaces/test-kubectl/pods/nginx-69687f68cb-p79t5
kubectl拿到pod信息之后会检验pod状态,如果状态为complete,kubectl将返回错误并不再执行后续流程,之后kubectl会检查命令是否输入了container名称,如果没有则从获取的pod信息中查找默认的container名称。
之后会将得到的container名称以及command作为参数附加在url中向kube-apiserver发起第二次请求,以连接pod的exec操作地址。
req := restClient.Post().Resource(\"pods\").Name(pod.Name).Namespace(pod.Namespace).SubResource(\"exec\")req.VersionedParams(&corev1.PodExecOptions{Container: containerName,Command: p.Command,Stdin: p.Stdin,Stdout: p.Out != nil,Stderr: p.ErrOut != nil,TTY: t.Raw,}, scheme.ParameterCodec)return p.Executor.Execute(\"POST\", req.URL(), p.Config, p.In, p.Out, p.ErrOut, t.Raw, sizeQueue)
Execute会调用NewSPDYExecutor连接到请求的服务器并将连接升级为多路复用双向流,关于SPDY协议在本文最后有简要介绍
func (*DefaultRemoteExecutor) Execute(method string, url *url.URL, config *restclient.Config, stdin io.Reader, stdout, stderr io.Writer, tty bool, terminalSizeQueue remotecommand.TerminalSizeQueue) error {exec, err := remotecommand.NewSPDYExecutor(config, method, url)return exec.StreamWithContext(context.Background(), remotecommand.StreamOptions{Stdin: stdin,Stdout: stdout,Stderr: stderr,Tty: tty,TerminalSizeQueue: terminalSizeQueue,})}
至此kubectl将cp命令转化为对pod的exec来实现。exec的实现是通过对kube-apiserver发起http请求,之后NewSPDYExecutor 将http连接升级为多路复用双向流。为了了解后续流程,我们需要来到kube-apiserver中看看apiserver接收到kubectl的请求后发生了什么。
kube-apiserver如何处理请求
上文中我们已经得知kubectl会将命令行输入转换为向kube-apiserver发起的exec请求,接下来本节中将介绍在kube-apiserver中接收到请求后,都进行了哪些处理。
kube-apiserver接收到kubectl发送的请求后,它的restServer会根据url将请求交由podStorage中对应的处理器处理。仍然以上文的exec为例,restServer会将其交给podStorage的ExecRest处理器。
restStorageMap := map[string]rest.Storage{\"pods\": podStorage.Pod,\"pods/attach\": podStorage.Attach,\"pods/status\": podStorage.Status,\"pods/log\": podStorage.Log,\"pods/exec\": podStorage.Exec,\"pods/portforward\": podStorage.PortForward,\"pods/proxy\": podStorage.Proxy,\"pods/binding\": podStorage.Binding,\"bindings\": podStorage.LegacyBinding,
podStorage的Exec是一个ExecREST对象,ExecREST中提供了kubelet的连接地址获取方式,在kubernetes集群初始化时,各kubelet会将自己所在的主机名注册到kub-apiserver,因此可以根据nodeName获取kubelet连接方式。
ExecRest的Connect方法中,首先根据kubeletConn与pod信息获取对pod执行exec操作的url,然后创建对应的handler向该url发起连接请求。
// Connect returns a handler for the pod exec proxyfunc (r *ExecREST) Connect(ctx context.Context, name string, opts runtime.Object, responder rest.Responder) (http.Handler, error) {...location, transport, err := pod.ExecLocation(r.Store, r.KubeletConn, ctx, name, execOpts)if err != nil {return nil, err}return newThrottledUpgradeAwareProxyHandler(location, transport, false, true, true, responder), nil}
本节中我们分析了kube-apiserver在接收到kubectl发送的http请求后所做的处理,可以看出kube-apiserver根据接收到的请求查询到pod所在机器的kubelet连接方式,并将该请求转发到了pod所在机器上的kubelet进行处理。
kubelet如何处理请求
上文已经介绍了在kube-apiserver处,apiserver将对pod执行命令操作的请求转发给了pod所在机器的kubelet处理。我们都知道,kubelet是kubernetes在每个Node上的“节点代理”,其作用就是负责管理kubernetes在该节点上所创建的Pod。接下来我们一起来分析在kubelet处对接收到的请求做了哪些操作:
kubelet接收到请求后,首先由其kubeletService根据url将请求路由到kubeletServer的getExec处理:
func (s *Server) InstallDebuggingHandlers(criHandler http.Handler) {// ...ws = new(restful.WebService)ws.Path(\"/exec\")ws.Route(ws.GET(\"/{podNamespace}/{podID}/{containerName}\").To(s.getExec).Operation(\"getExec\"))...s.restfulCont.Add(ws)
经过多次调用,kubelet的getExec发起一个 gRPC 调用让运行时端(即docker)来准备一个用于执行命令的流端点并返回其地址
func (c *runtimeServiceClient) Exec(ctx context.Context, in *ExecRequest, opts ...grpc.CallOption) (*ExecResponse, error) {out := new(ExecResponse)err := c.cc.Invoke(ctx, \"/runtime.v1alpha2.RuntimeService/Exec\", in, out, opts...)return out, nil}
之后kubelet会将请求重定向到该url。
url, err := s.host.GetExec(podFullName, params.podUID, params.containerName, params.cmd, *streamOpts)if s.redirectContainerStreaming {http.Redirect(response.ResponseWriter, request.Request, url.String(), http.StatusFound)return}
到这里我们总结一下,kubelet在接收到kube-apiserver转发的请求后到目前为止做了哪些事情:kubelet接收请求后,执行GetExec,经过多次调用过程,最终发起一个gRPC请求从容器运行时端获得了一个容器的操作地址。然后再将接收到的请求重定向到GetExec所得到的url。
那么gRPC请求是由谁处理的呢?以及kubelet将请求重定向到该url后又发生了什么呢?我们继续分析。
kubelet创建dockershim调用cri
为了解答以上问题,我们就需要了解kubelet在初始化时都做了哪些工作。kubelet在初始化时除了创建了自己的kubeletService之外,还创建了dockershim组件以调用cri(container runtime interface)。上文中提到runtimeClient的Exec发起了一个gRPC请求以获取容器运行时的操作地址。该请求就是由dockershim.dockerService实现的。
// Exec 准备一个流端点以在容器中执行命令,并返回地址。func (ds *dockerService) Exec(_ context.Context, req *runtimeapi.ExecRequest) (*runtimeapi.ExecResponse, error) {...return ds.streamingServer.GetExec(req)}
这就解答了第一个问题,gRPC是由dockershim的dockerService处理的,返回的是一个url,之前的提到kubeletServer会将pod的exec请求重定向到这个url。
接下来研究第二个问题,kubeletServer将请求重定向到该url后又发生了什么?dockerService除了提供了GetExec的能力之外,同时创建了streamingServer可以处理exec的请求,它会将getExec所得到的url交给serveExec函数处理。
func NewServer(config Config, runtime Runtime) (Server, error) {...ws := &restful.WebService{}endpoints := []struct {path stringhandler restful.RouteFunction}{{\"/exec/{token}\", s.serveExec},{\"/attach/{token}\", s.serveAttach},{\"/portforward/{token}\", s.servePortForward},}
serveExec函数会调用ExecInContainer函数,Docker在容器中执行命令的核心实现就是 NativeExecHandler.ExecInContainer() 方法:
func (*NativeExecHandler) ExecInContainer(client libdocker.Interface, container *dockertypes.ContainerJSON, cmd []string, stdin io.Reader, stdout, stderr io.WriteCloser, tty bool, resize <-chan remotecommand.TerminalSize, timeout time.Duration) error {...startOpts := dockertypes.ExecStartCheck{Detach: false, Tty: tty}streamOpts := libdocker.StreamOptions{InputStream: stdin,OutputStream: stdout,ErrorStream: stderr,RawTerminal: tty,ExecStarted: execStarted,}err = client.StartExec(execObj.ID, startOpts, streamOpts)if err != nil {return err}
简而言之,kubelet主要工作步骤为:首先调用容器运行时的getExec获取pod的操作地址url,再将接收到的请求重定向到pod exec的url,将命令传入pod执行并获得执行结果,并将输入、输出以及标准错误输出流转发给kube-apiserver。kubelet处理请求的流程图如下所示:
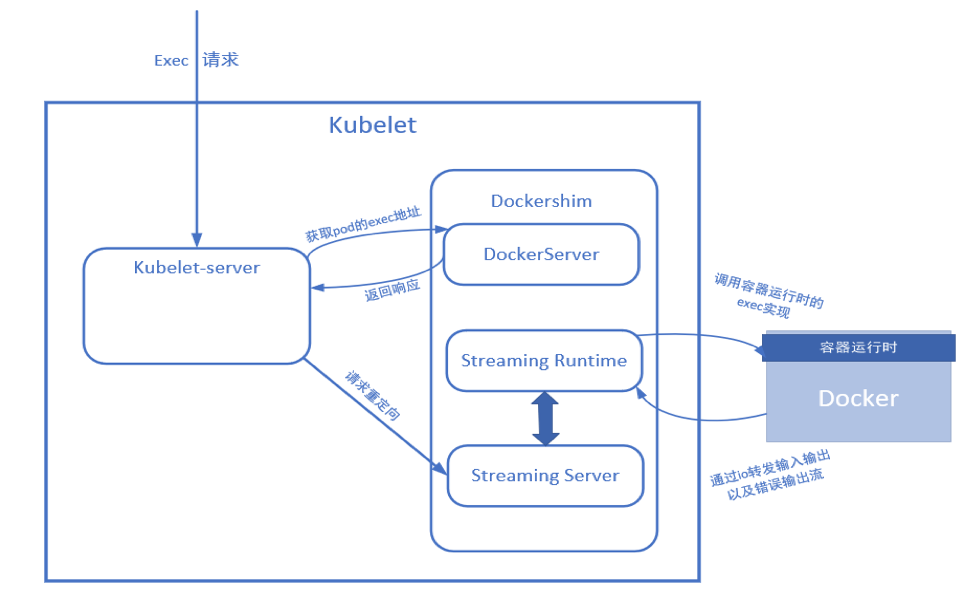
kubectl接收到响应
经过多次转发,对pod的操作终于成功进入容器执行,并将结果发送给kube-apiserver。再经由kube-apiserver转发给kubectl。
我们最初是从kubectl开始,由于kubectl cp向kube-apiserver发起了exec请求进行了以上分析。kubectcl在得到执行结果后,通过io.copy将打包pod文件所产生的输出流拷贝到本地的目的地址。
至此,kubectl cp整个流程结束,将执行结果输出。

现在我们来解答一下本文初的问题,是否能对kubectl cp的传输过程进行限流。
经过本文分析,可以看出kubectl cp是通过kubectl将该命令转换为向kube-apiserver发起的exec请求,由kube-apiserver将请求转发给kubelet,kubelet调用本机的docker去目标pod中执行相关命令,再将执行结果由kubelet响应给kube-apiserver,再由kube-apiserver返回给kubectl输出。整个流程如下所示:
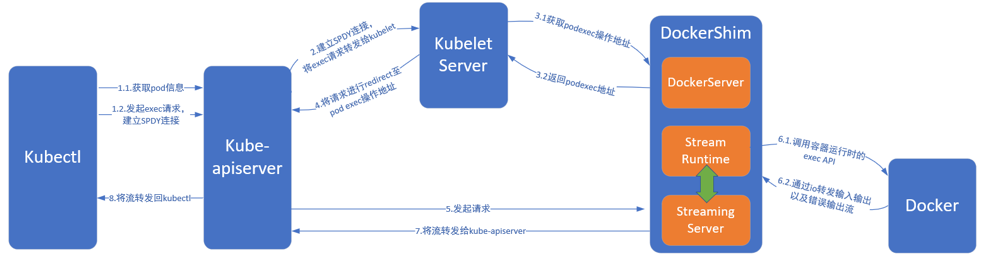
请求被转发到pod中是由docker执行命令,经过抓包发现,输入输出流都是通过本地io的形式实现的,并不经过pod网卡,因此不会给pod的网卡带来负载。而在kubectl到kube-apiserver,再由kube-apiserver转发kubelet的过程中是有可能给网络带来压力的。因此如果我们想要对此进行限制以保证pod的正常业务访问,应该从这些环节入手解决。
传输速率限制
之前有提到过,在kubectl侧,是调用了NewSPDYExcutor来将连接升级为多路复用双向流,SPDY协议是由Google开发的一种网络传输协议,最终演变为http2,http2的关键功能主要来自于SPDY。不同于http1的流控制依赖于TCP流控制,在SPDY协议中提供了自己的流控制功能。kube-apiserver与kubelet之间就使用了SPDY协议进行通信,在上文介绍kube-apiserver处工作流程时也有提到,可以通过限制PerConnectionBandwidthLimitBytesPerSec对每个传输流的每秒最大传输字节数进行限制。
该参数可以通过添加kube-apiserver.yaml中的启动参数可以对其进行配置:
--max-connection-bytes-per-sec=nn为每秒传输的最大字节数,对于此参数的作用,kubernetes文档中有介绍到:如果不为0,则限制每个连接每秒传输的最大字节数为n,目前只对long-running请求起作用。
对于long-running请求,kubernetes对其做了限定,以下请求属于long-running请求,可以看到exec就在其中:
filters.BasicLongRunningRequestCheck(sets.NewString(\"watch\", \"proxy\"),sets.NewString(\"attach\", \"exec\", \"proxy\", \"log\", \"portforward\"),)
经过实测确实能够对kubectl cp的传输速率进行限制,但我们能看到,long-running请求不止exec一种,这就意味着其他请求也会因为该设置的改动收到影响。
并发请求限制
除此之外,kubernetes还提供了对连接数的限制,可以设置kube-apiserver的最大并发量,区分为只读操作与修改(mutating)操作(get,list和watch等查询操作属于非mutating操作,其他都属于mutating操作),分别通过以下参数进行设置:
--max-requests-inflight--max-mutating-requests-inflight
同时,从1.18版本,kubernetes还提供了基于API 优先级和公平性的并发控制方案,即APF,以上两个参数也需要在APF设定各请求平等竞争时生效。在1.20版本后,kubernetes默认启用APF对集群并发请求进行管理,APF会为每个请求分配一个优先级,每个优先级都有各自的请求数量限制。
分析到这里,现在我们可以解答文章开头所提出的那个问题了:我们确实可以通过修改kube-apiserver的启动参数,对kubectl cp的传输速率以及并发请求数量进行限制。但这些设置并不是只对kubectl cp生效,对集群中的其他请求同样进行了限制,因此不建议使用这种方式对kubectl cp进行限流。
本文从具体问题出发,研究介绍了kubectl cp的工作原理与执行流程,同时对kubernetes集群的流量控制与并发控制进行了简单介绍,对kubernetes集群内容器文件传输方案进行了探讨,欢迎大家的讨论和纠正!

文章作者:董皓哲
手绘插画:岳 媛
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/33700.html