
团队介绍
我们是光大科技有限公司智能云计算部运维服务团队智慧教学、教务项目组,在集团“聚焦数字化能力,构建平台化光大,引领智能化未来”战略指引下,积极构建数字化、智能化、生态化的教学、培训、管理平台,用科技赋能集团数字化转型。
导言
ONE
缓存是现在系统中必不可少的模块,并且已经成为了高并发高性能架构的一个关键组件,这篇文章结合redis的特点,详细讲解其在缓存中起到的作用。

redis
TWO
REmote DIctionary Server(redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。下面我们看看redis有哪些特点。
|
|
根据这几个特点,我们可以发现redis的优势与不足。 |
|
|
|
|
|
|
缓存
THREE
下面聊聊缓存(只聊后端架构中的缓存,不包括网络缓存、前端缓存等)。
后端缓存是后端架构中不可或缺的一部分,一般都存放在内存中,我们可以把缓存想象为覆盖在数据库上面的保护层,帮助数据库拦截一部分请求,减少磁盘操作。
缓存的分类
本地缓存:调用快、不支持分布式。代表产品:Ehcache(现在最流行的纯Java开源缓存框架)。
分布式缓存:多了远程调用带来的网络开销,调用数据没有本地缓存快,但是支持分布式,缓存使用的内存和应用程序分别位于不同的机器,便于架构拓展。代表产品:redis。
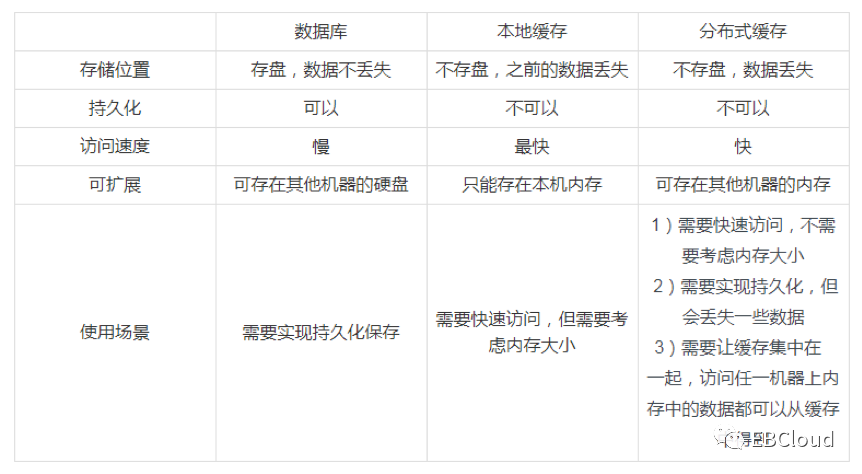
根据分类,可以总结出哪些数据适合放在什么类型的缓存中。
静态数据(不改变的数据)、不需要多实例共享的数据,适合放到本地缓存。
频繁改变、需要多实例共享的数据,例如session,适合放到分布式缓存。
缓存与DB的同步方式
不论是缓存还是数据库中的数据发生了更新时,另一方都需要同步更新,从而保证数据的一致性,同步方式主要有以下三种:
1. cache aside (旁路缓存)
这种方式是多数情况下采用的方式,实现也非常简单,也是开发人员最容易想到、最好理解的实现方式,问题就是这种方式对业务代码侵入性强,需要把所有write的操作都考虑进来。
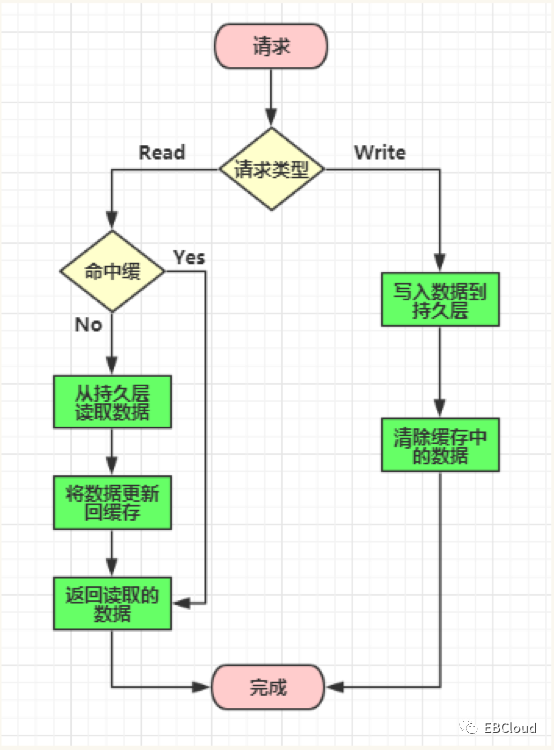
图片来源于CSDN
2. read/write through (读写穿透)
封装好缓存和数据库同步的逻辑(数据库的维护工作由缓存代理),对业务透明,开发人员不需要额外写代码去处理一致性问题,问题就是实现相对复杂。
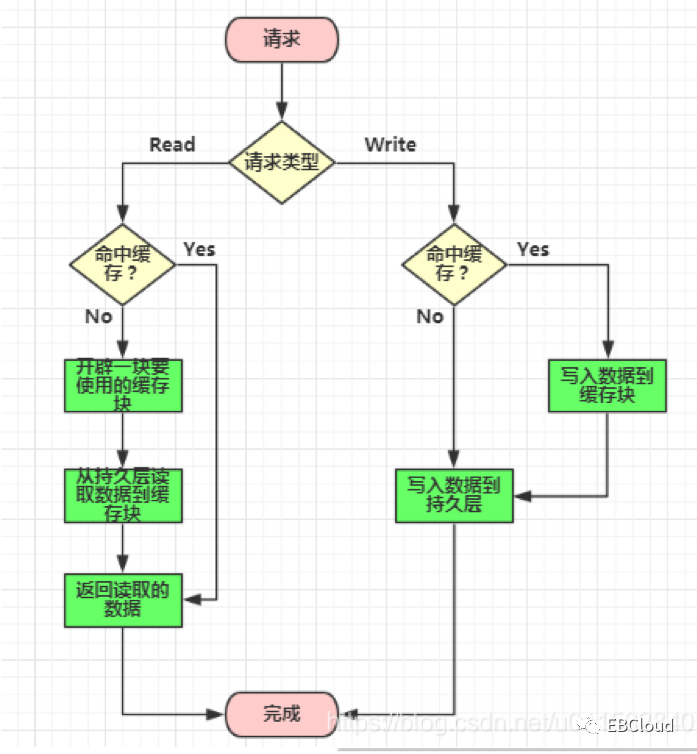
图片来源于CSDN
3. write back (异步缓存写入)
更新的时候只更新缓存,异步写入数据库。好处是直接操作内存速度快;缺点是一致性差,如果发生宕机,或者异步写入数据库的过程中发生了问题,数据有丢失风险。这种方式适合对一致性要求不高的场景。
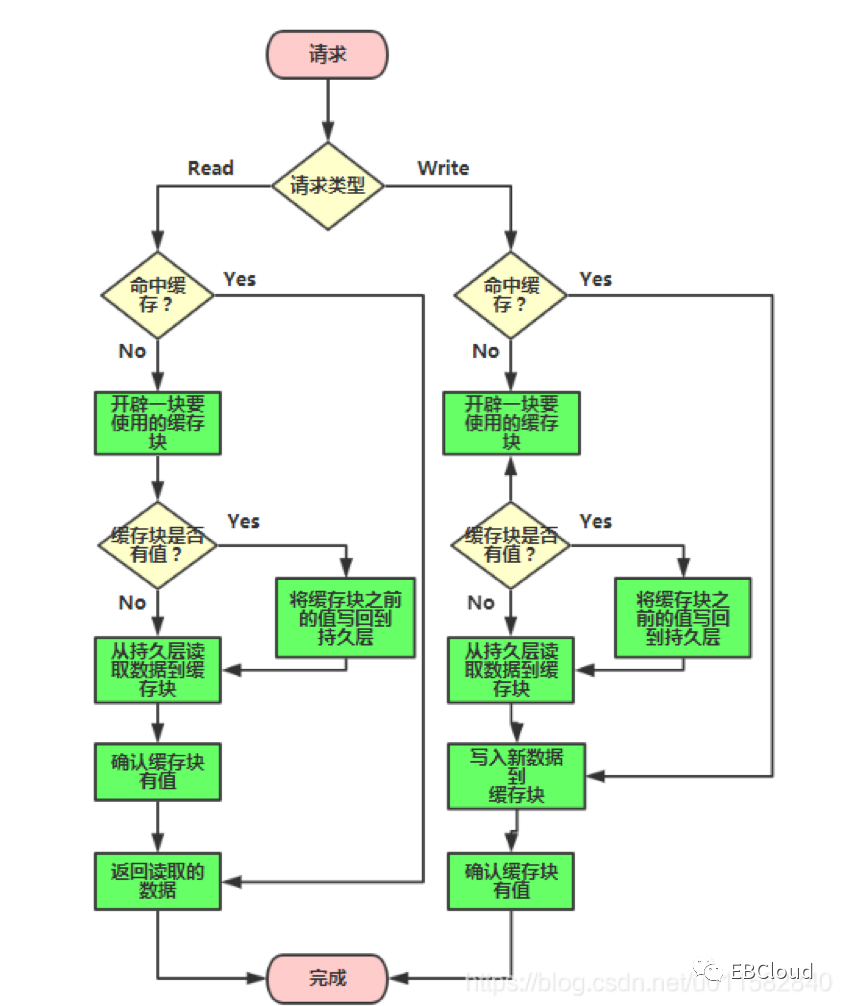
图片来源于CSDN
对这三种方式进行比较我们发现不管哪种方式,都有各自的优缺点,还请读者根据各自项目的实际应用作取舍。如果你的应用比较轻量,使用缓存的场景也不是很多,而且也不想投入过多人力进行缓存服务的研发,那么cashe aside就可以满足你的需求,笔者所在的项目也是用的这种方式。
命中率
命中率衡量缓存系统效率的重要指标,其计算方式为:
从缓存中读取数据的次数/(从缓存中读取数据的次数+访问硬盘的次数)
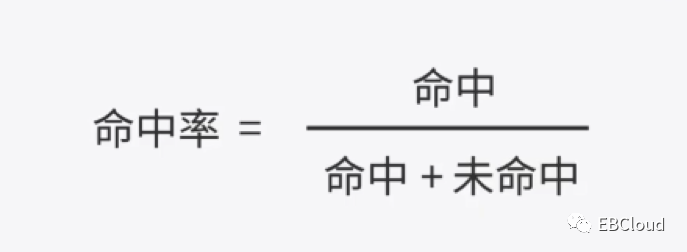
命中率高,说明到达缓存系统拦截到的请求越多,到数据库的请求少,不难发现命中率越高说明缓存系统设计的效果越好,那么如何提高缓存命中率呢?
首先需要开发人员了解业务数据的特点,什么时间访问频率高,什么情况变更频率高,需要结合具体场景进行设计。总的来说,频繁变更的数据不适宜放到缓存,因为频繁变更导致数据总是失效,也就降低了命中率。另外,缓存的过期策略要配置得合理,过短导致降低命中率,过长浪费内存资源。
redis对过期数据的处理
FOUR
前面说到缓存的过期策略要配置的合理,redis提供了设置过期时间的命令:
EXPIRE key seconds //将key的生存时间设置为ttl秒PEXPIRE key milliseconds //将key的生成时间设置为ttl毫秒EXPIREAT key timestamp //将key的过期时间设置为timestamp所代表的的秒数的时间戳PEXPIREAT key milliseconds-timestamp //将key的过期时间设置为timestamp所代表的的毫秒数的时间戳
但是,长期将redis作为缓存使用,难免会遇到内存空间存储瓶颈。当redis内存超出物理内存限制时,内存数据就会与磁盘产生频繁交换,使redis性能急剧下降。此时如何淘汰无用数据释放空间,存储新数据就变得尤为重要了。配置参数maxmemory 可以用来限制内存大小,当实际占用内存达到maxmemory上限时,便会触发redis淘汰机制,可以通过redis.conf文件的maxmemory-policy参数来进行配置。
redis淘汰策略一共有六种:

图片来源于CSDN
其中,LRU算法(Least Recently Used,最近最久未使用法)是按照一个非常著名的计算机操作系统基础理论得来的:最近使用的数据会在未来一段时期内仍然被使用,已经很久没有使用的数据很有可能在未来较长的一段时间内仍然不会被使用。基于这个思想, 每次从内存中找到最久未使用的数据然后置换出来,从而存入新的数据,LRU的具体原理笔者就不再赘述了,请读者自行百度吧。
总结
FIVE
通过前面的介绍,我们大致认识到了redis在缓存系统中举足轻重的地位,缓存也的确是redis最擅长做的事情,除了做缓存,redis在处理热点数据、秒杀、排行榜等等方面也有着诸多应用。让我们带着小学生的心态开启redis的大门,不断向前迈进吧!
参考资料
1.本地缓存与分布式缓存的优缺点
https://blog.csdn.net/u010013573/article/details/102530682
2.如何保证缓存与数据库的双写一致性?
https://blog.csdn.net/chang384915878/article/details/86756463
3.配置redis作为缓存淘汰策略
https://blog.csdn.net/qq_41204714/article/details/84578481
4. 为什么分布式一定要有redis?
https://blog.csdn.net/hcmony/article/details/80694560
#往期推荐#
作者 :刘思远
长按识别二维码关注我们
原创文章,作者:EBCloud,如若转载,请注明出处:https://www.sudun.com/ask/33803.html
