
作者简介:马宜萱,西安邮电大学研一在读,操作系统爱好者,主要方向为内存方向。目前在学习操作系统底层原理和内核编程。
内存检测
一般的内存访问错误如下
-
越界访问(out-of-bounds)。 -
访问已经被释放的内存(use after free)。 -
重复释放(double free)。 -
内存泄漏(memory leak)。 -
栈溢出(stack overflow)。
跟踪内存活动的各种事件源
| 事件类型 | 事件源 |
|---|---|
| 用户态内存分配 | 使用uprobes跟踪内存分配器函数,使用USDT probes跟踪libc |
| 内核态内存分配 | 使用kprobes跟踪内存分配器函数,以及kmem跟踪点 |
| 堆内存扩展 | brk系统调用跟踪点 |
| 共享内存函数 | 系统调用跟踪点 |
| 缺页错误 | kprobes、软件事件、exception跟踪点 |
| 页面迁移 | migration跟踪点 |
| 页面压缩 | compaction跟踪点 |
| VM扫描器 | Vmscan跟踪点 |
| 内存访问周期 | PMC |
对使用libc内存分配器的进程来说,libc提供了⼀系列内存分配的函数,包括malloc()和 free()等。在libc库中已经内置了一些USDT追踪点,可以在应用程序中使用这些追踪点来监视libc的行为。
以下是libc中可用的USDT探针:
# sudo bpftrace -l usdt:/lib/x86_64-linux-gnu/libc-2.31.so
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:setjmp
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:longjmp
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:longjmp_target
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:lll_lock_wait_private
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_arena_max
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_arena_test
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tunable_tcache_max_bytes
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tunable_tcache_count
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tunable_tcache_unsorted_limit
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_trim_threshold
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_top_pad
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_mmap_threshold
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_mmap_max
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_perturb
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_mxfast
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_new
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_reuse_free_list
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_reuse
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_reuse_wait
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_new
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_arena_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_sbrk_less
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_free
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_less
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_tcache_double_free
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_heap_more
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_sbrk_more
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_malloc_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_memalign_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt_free_dyn_thresholds
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_realloc_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_calloc_retry
usdt:/lib/x86_64-linux-gnu/libc-2.31.so:libc:memory_mallopt
oomkill
使用kprobes来跟踪oom_kill_process()函数,来跟踪OOM Killer事件的信息,以及可以从/proc/loadavg获取负载平均值,打印出平均负载等详细信息。平均负载信息可以在OOM发生时提供整个系统状态的一些上下文信息,展示出系统整体是正在变忙还是处于稳定状态。
static void oom_kill_process(struct oom_control *oc, const char *message)
# cat /proc/loadavg
0.05 0.10 0.13 1/875 23359
memleak
memleak可以用来跟踪内存分配和释放事件对应的调用栈信息。随着时间的推移,这个工具可以显示长期不被释放的内存。
在跟踪用户态进程时,memleak跟踪的是用户态内存分配函数:malloc()、calloc() 和 free() 等。对内核态内存来说,使用的是k跟踪点:
kmem:kfree [Tracepoint event]
kmem:kmalloc [Tracepoint event]
kmem:kmalloc_node [Tracepoint event]
kmem:kmem_cache_alloc [Tracepoint event]
kmem:kmem_cache_alloc_node [Tracepoint event]
kmem:kmem_cache_free [Tracepoint event]
kmem:mm_page_alloc [Tracepoint event]
kmem:mm_page_free [Tracepoint event]
percpu:percpu_alloc_percpu [Tracepoint event]
percpu:percpu_free_percpu [Tracepoint event]
使用工具模拟内存泄漏:
-
写一个c程序:
#include <stdio.h> #include <stdlib.h> #include <pthread.h> #include <unistd.h>long long *fibonacci(long long *n0, long long *n1) {
// 分配1024个长整数空间方便观测内存的变化情况
long long *v = (long long *) calloc(1024, sizeof(long long));
*v = *n0 + *n1;
return v;
}void *child(void *arg) {
long long n0 = 0;
long long n1 = 1;
long long *v = NULL;
int n = 2;
for (n = 2; n > 0; n++) {
v = fibonacci(&n0, &n1);
n0 = n1;
n1 = *v;
printf(“%dth => %lldn”, n, *v);
sleep(1);
}
}int main(void) {
pthread_t tid;
pthread_create(&tid, NULL, child, NULL);
pthread_join(tid, NULL);
printf(“main thread exitn”);
return 0;
} -
运行该文件
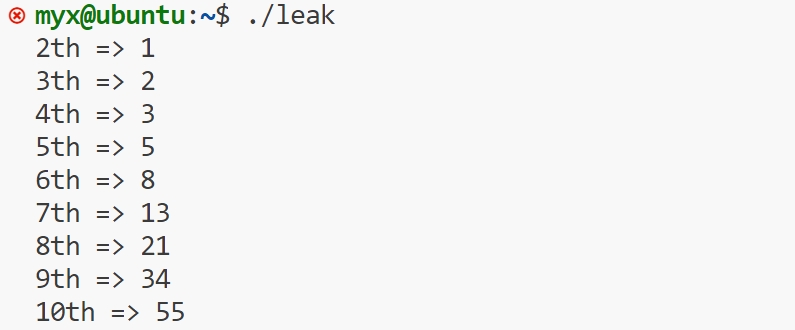
-
再开一个终端,使用命令vmstat 3
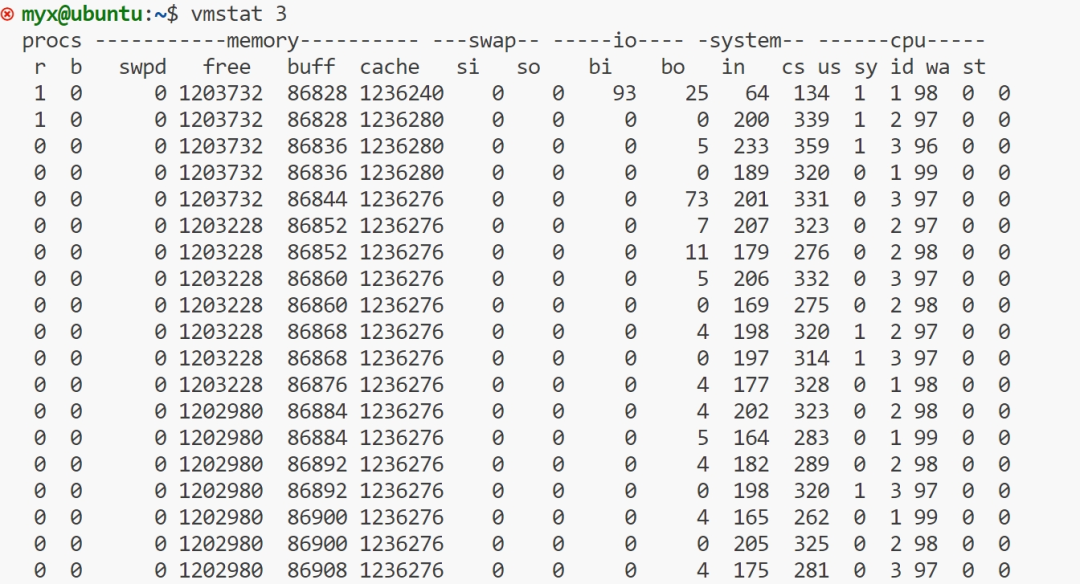
上面的 “free”, “buff”, “cache” 栏目分别以 KB 为单位显示了空闲内存、存储 I/O 缓冲区占用的内存,以及文件系统缓存占用的内存数量。”si” 和 “so” 栏目分别展示了页换入和页换出操作的数量,如果系统中存在这些操作的话。
第一行输出的是”自系统启动以来”的统计信息,这一行的大部分栏目是自从系统启动以来的平均值。然而,”memory”栏显示的仍然是系统内存的当前状态。而第二行和之后的行显示的都是一秒之内的统计信息。
可以看出free(可用内存)上下浮动慢慢减少,而buff(磁盘缓存),cache(文件缓存)上下浮动基本保持不变。
-
再次使用命令运行上面C程序
-
在打开第二个终端中使用命令:ps aux | grep app查看进程id

-
使用命令: sudo /usr/sbin/memleak-bpfcc -p 6867 运行

从图中可以看出来泄露位置:
fibonacci+0x23 [leak]
child+0x5a [leak]
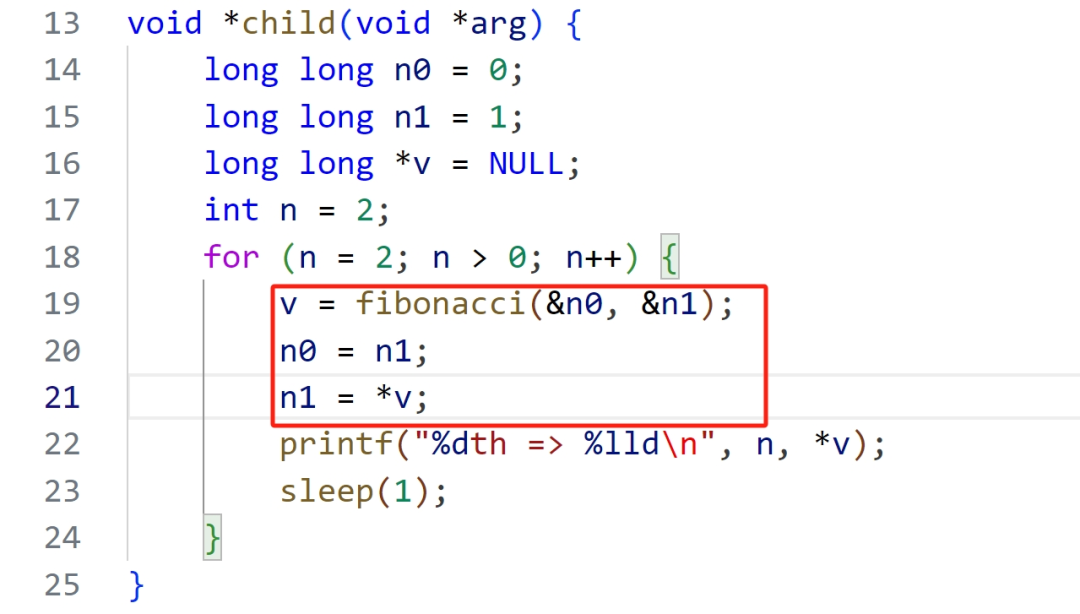
可以看出代码中的*v,没有释放,造成内存泄漏。
改后代码:
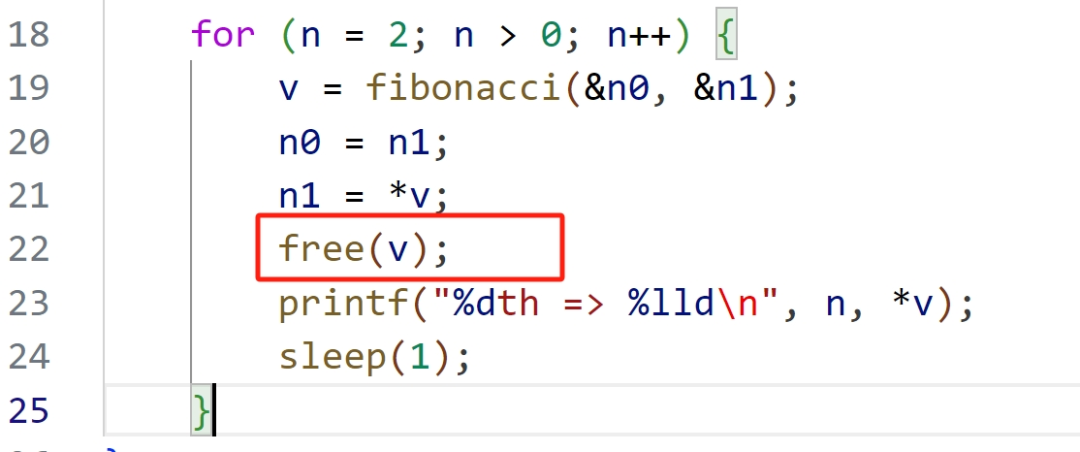
-
改进后,重复上面的操作,结果如下

单靠memleak无法判断这些内存分配操作是真正的内存泄漏(即,分配的内存没有任何引用,永远不会被释放),还是只是内存用量的正常增长,或者仅仅是真正的长期内存。为了区分这几种类型,需要阅读和理解这些代码路径的真正意图。
如果没有 -p PID 命令行参数,那么memleak跟踪的是内核中的内存分配信息:
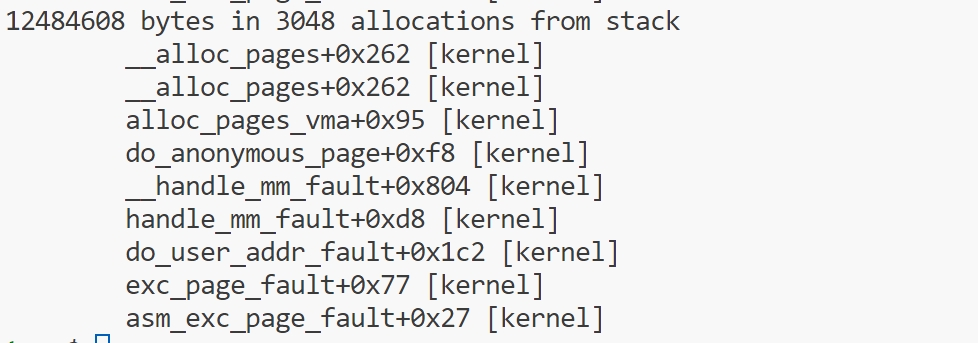
mmapsnoop
使用syscall:sys_enter_mmap 跟踪点跟踪全系统mmap系统调用并打印映射请求详细信息。
sys_enter_mmap是一个用于跟踪mmap系统调用的跟踪点的名称。
syscalls:sys_enter_mmap [Tracepoint event]
一个应用程序,特别是在其启动和初始化期间,可以显式地使用mmap() 系统调用来加载数据文件或创建各种段,在这个上下文中,我们聚焦于那些比较缓慢的应用增长,这种情况可能是由于分配器函数调用了mmap()而不是brk()造成的。而libc通常用mmap()分配较大的内存,可以使用munmap()将分配的内存返还给系统。
brkstack
一般来说,应用程序的数据存放于堆内存中,堆内存通过 brk 系统调用进行扩展。跟踪 brk 调用,并且展示导致增长的用户态调用栈信息相对来说是很有用的分析信息。同时还有一个 sbrk 变体调用。在 Linux 中,sbrk 是以库函数形式实现的,内部仍然使用 brk 系统调用。
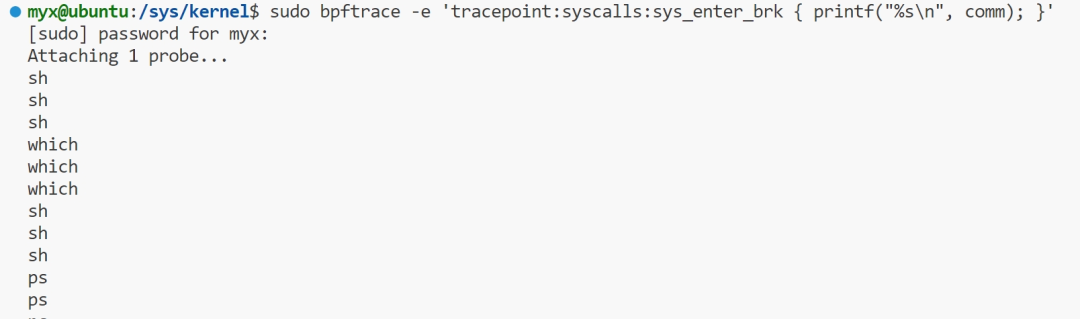
brk 可以用 syscall:sys_enter_brk 跟踪点来跟踪,同时该跟踪点对应的调用栈信息,可以用 bpftrace 版本的单行程序等方式来获取。
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_brk { printf("%sn", comm); }'
上面命令可以跟踪brk系统调用。
shmsnoop
shmsnoop跟踪 System V 的共享内存系统调用:shmget、shmat、shmdt以及shmctl。可以用来调试共享内存的使用情况和信息。
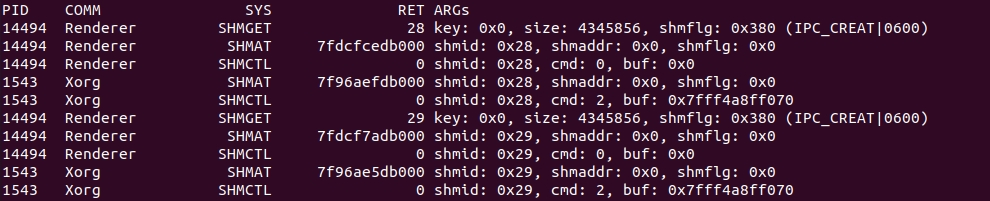
这个输出显示了一个Renderer进程通过 shmget 分配了共享内存,然后显示了该 Renderer 进程执行了几种不同的共享内存操作,以及对应的参数信息。shmget 调用的返回结果是 0x28,这个标识符接下来被 Renderer 和 Xorg 进程同时使用;换句话说,它们在共享内存中。
共享内存
共享内存就是允许两个不相关的进程访问同一个逻辑内存。共享内存是在两个正在运行的进程之间共享和传递数据的一种非常有效的方式。
不同进程之间共享的内存通常安排为同一段物理内存。进程可以将同一段共享内存连接到它们自己的地址空间中,所有进程都可以访问共享内存中的地址,就好像它们是由用C语言函数malloc()分配的内存一样。而如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。
共享内存并未提供同步机制,也就是说,在第一个进程结束对共享内存的写操作之前,并无自动机制可以阻止第二个进程开始对它进行读取。所以通常需要用其他的机制来同步对共享内存的访问,例如信号量。
-
shmget()函数
得到一个共享内存标识符或创建一个共享内存对象。
asmlinkage long sys_shmget(key_t key, size_t size, int flag);SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg) { return ksys_shmget(key, size, shmflg); }long ksys_shmget(key_t key, size_t size, int shmflg) { struct ipc_namespace *ns; static const struct ipc_ops shm_ops = { .getnew = newseg, .associate = security_shm_associate, .more_checks = shm_more_checks, }; struct ipc_params shm_params;ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}成功:共享内存段标识符
出错:-1-
函数参数:
Key:共享内存的键值,多个进程可以通过它,来访问同一个共享内存;其中特殊的值IPC_PRIVATE,用于创建当前进程的私有共享内存, 多用于父子进程间。
size:共享内存区大小 。
Shmflg:同 open 函数的权限位,也可以用八进制表示法
-
返回值:
-
-
shmat( )函数
连接共享内存标识符为shmid的共享内存,连接成功后把共享内存区对象映射到调用进程的地址空间,随后可像本地空间一样访问。
asmlinkage long sys_shmat(int shmid, char __user *shmaddr, int shmflg);SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg) { unsigned long ret; long err;err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA);
if (err)
return err;
force_successful_syscall_return();
return (long)ret;
}成功:被映射的段地址
出错:-1-
函数原型
shmid:要映射的共享内存区标识符
shmaddr:将共享内存映射到指定位置
Shmflg:SHM_RDONLY:共享内存只读,默认0:共享内存可读写
-
返回值:
-
-
shmdt()函数
与shmat函数相反,是用来断开与共享内存附加点的地址,禁止本进程访问此片共享内存。
本函数调用并不删除所指定的共享内存区,而只是将先前用shmat函数连接(attach)好的共享内存脱离(detach)目前的进程。
asmlinkage long sys_shmdt(char __user *shmaddr);SYSCALL_DEFINE1(shmdt, char __user *, shmaddr) { return ksys_shmdt(shmaddr); }long ksys_shmdt(char __user *shmaddr) { // 获取当前进程的内存管理结构 struct mm_struct *mm = current->mm; // 定义虚拟内存区域结构体指针 struct vm_area_struct *vma; // 将共享内存地址转换为无符号长整型 unsigned long addr = (unsigned long)shmaddr; // 初始化返回值,默认为无效参数错误 int retval = -EINVAL;#ifdef CONFIG_MMU
// 定义大小变量和文件指针
loff_t size = 0;
struct file *file;
struct vm_area_struct *next;
#endif// 检查共享内存地址是否有效
if (addr & ~PAGE_MASK)
return retval;// 尝试获取内存映射写锁,可被信号中断
if (mmap_write_lock_killable(mm))
return -EINTR;// 查找给定地址的虚拟内存区域
vma = find_vma(mm, addr);#ifdef CONFIG_MMU
while (vma) {
next = vma->vm_next;// 检查地址是否匹配,并且 vma 与 shm 相关
if ((vma->vm_ops == &shm_vm_ops) &&
(vma->vm_start – addr)/PAGE_SIZE == vma->vm_pgoff) {// 记录 shm 段的文件和大小
file = vma->vm_file;
size = i_size_read(file_inode(vma->vm_file));
// 取消映射 shm 段
do_munmap(mm, vma->vm_start, vma->vm_end – vma->vm_start, NULL);
// 设置返回值为成功
retval = 0;
vma = next;
break;
}
vma = next;
}// 遍历所有可能的 vma
size = PAGE_ALIGN(size);
while (vma && (loff_t)(vma->vm_end – addr) <= size) {
next = vma->vm_next;// 检查地址是否匹配,并且 vma 与 shm 相关
if ((vma->vm_ops == &shm_vm_ops) &&
((vma->vm_start – addr)/PAGE_SIZE == vma->vm_pgoff) &&
(vma->vm_file == file))
// 取消映射 shm 段
do_munmap(mm, vma->vm_start, vma->vm_end – vma->vm_start, NULL);
vma = next;
}#else /* CONFIG_MMU */
// 在 NOMMU 条件下,必须给出要销毁的确切地址
if (vma && vma->vm_start == addr && vma->vm_ops == &shm_vm_ops) {
// 取消映射 shm 段
do_munmap(mm, vma->vm_start, vma->vm_end – vma->vm_start, NULL);
// 设置返回值为成功
retval = 0;
}#endif
// 解锁内存映射
mmap_write_unlock(mm);
return retval;
}-
函数原型
shmaddr:连接的共享内存的起始地址
-
-
shmctl函数
完成对共享内存的控制
asmlinkage long sys_shmctl(int shmid, int cmd, struct shmid_ds __user *buf);SYSCALL_DEFINE3(shmctl, int, shmid, int, cmd, struct shmid_ds __user *, buf) { return ksys_shmctl(shmid, cmd, buf, IPC_64); }static long ksys_shmctl(int shmid, int cmd, struct shmid_ds __user *buf, int version) { int err; struct ipc_namespace *ns; struct shmid64_ds sem64;if (cmd < 0 || shmid < 0)
return -EINVAL;ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO: {
struct shminfo64 shminfo;
err = shmctl_ipc_info(ns, &shminfo);
if (err < 0)
return err;
if (copy_shminfo_to_user(buf, &shminfo, version))
err = -EFAULT;
return err;
}
case SHM_INFO: {
struct shm_info shm_info;
err = shmctl_shm_info(ns, &shm_info);
if (err < 0)
return err;
if (copy_to_user(buf, &shm_info, sizeof(shm_info)))
err = -EFAULT;
return err;
}
case SHM_STAT:
case SHM_STAT_ANY:
case IPC_STAT: {
err = shmctl_stat(ns, shmid, cmd, &sem64);
if (err < 0)
return err;
if (copy_shmid_to_user(buf, &sem64, version))
err = -EFAULT;
return err;
}
case IPC_SET:
if (copy_shmid_from_user(&sem64, buf, version))
return -EFAULT;
fallthrough;
case IPC_RMID:
return shmctl_down(ns, shmid, cmd, &sem64);
case SHM_LOCK:
case SHM_UNLOCK:
return shmctl_do_lock(ns, shmid, cmd);
default:
return -EINVAL;
}
}-
函数原型
shmid:共享内存标识符
cmd:IPC_STAT:得到共享内存的状态,把共享内存的shmid_ds结构复制到buf中;IPC_SET:改变共享内存的状态,把buf所指的shmid_ds结构中的uid、gid、mode复制到共享内存的shmid_ds结构内;IPC_RMID:删除这片共享内存
buf:共享内存管理结构体。
-
faults
跟踪缺页错误和对应的调用栈信息,可以为内存使用量分析提供一个新的视角。缺页错误会直接导致 RSS 的增长,所以这里截取的调用栈信息可以用来解释进程内存使用量的增长。正如 brk() 一样,可以通过单行程序来直接跟踪这个事件并进行分析。
跟踪page_fault_user和page_fault_kernel来对用户态和内核态的缺页错误对应的频率统计信息进行分析。
exceptions:page_fault_user [Tracepoint event]
exceptions:page_fault_kernel [Tracepoint event]
vmscan
使用vmscan跟踪点观察页面换出守护进程(kswapd)的操作。这个进程在系统内存压力上升时负责释放内存以便重用。值得注意的是,尽管内核函数的名称仍然使用scanner,但为了提高效率,内核已经采用链表方式来管理活跃内存和不活跃内存。
vmscan:mm_shrink_slab_end [Tracepoint event]
vmscan:mm_shrink_slab_start [Tracepoint event]
vmscan:mm_vmscan_direct_reclaim_begin [Tracepoint event]
vmscan:mm_vmscan_direct_reclaim_end [Tracepoint event]
vmscan:mm_vmscan_memcg_reclaim_begin [Tracepoint event]
vmscan:mm_vmscan_memcg_reclaim_end [Tracepoint event]
vmscan:mm_vmscan_wakeup_kswapd [Tracepoint event]
vmscan:mm_vmscan_writepage [Tracepoint event]
-
vmscan:mm_shrink_slab_end,vmscan:mm_shrink_slab_start
使用这两个跟踪点计算收缩slab所花的全部时间,以毫秒为单位。这是从各种内核缓存中回收内存。
-
vmscan:mm_vmscan_direct_reclaim_begin,vmscan:mm_vmscan_direct_reclaim_end
使用这两个跟踪点计算直接接回收所花的时间,以毫秒为单位。这是前台回收过程,在此期间内存被换入磁盘中,并且内存分配处于阻塞状态。
-
vmscan:mm_vmscan_memcg_reclaim_begin,vmscan:mm_vmscan_memcg_reclaim_end
内存cgroup回收所花的时间,以毫秒为单位。如果使用了内存cgroups,此列显示当cgroup超出内存限制,导致该cgroup进行内存回收的时间。
-
vmscan:mm_vmscan_wakeup_kswapd
kswapd 唤醒的次数。
-
vmscan:mm_vmscan_writepage
kswapd写入页的数量。
drsnoop
drsnoop使用mm_vmscan_direct_reclaim_begin 和 mm_vmscan_direct_reclaim_end 跟踪点,来跟踪内存释放过程中的直接回收部分。它能够显示受到影响的进程以及对应的延迟,即直接回收所需的时间。可以用来定量分析内存受限的系统中对应用程序的性能影响。
-
直接内存回收
在直接内存回收过程中,有可能会造成当前需要分配内存的进程被加入一个等待队列,当整个node的空闲页数量满足要求时,由kswapd唤醒它重新获取内存。这个等待队列头就是node结点描述符pgdat中的pfmemalloc_wait。如果当前进程加入到了pgdat->pfmemalloc_wait这个等待队列中,那么进程就不会进行直接内存回收,而是由kswapd唤醒后直接进行内存分配。
直接内存回收执行路径是:
__alloc_pages_slowpath()->__alloc_pages_direct_reclaim()->__perform_reclaim()->try_to_free_pages()->do_try_to_free_pages()->shrink_zones()->shrink_zone()在
__alloc_pages_slowpath()中可能唤醒了所有node的kswapd内核线程,也可能没有唤醒,每个node的kswapd是否在__alloc_pages_slowpath()中被唤醒有两个条件:而在kswapd中会对node中每一个不平衡的zone进行内存回收,直到所有zone都满足 zone分配页框后剩余的页框数量 > 此zone的high阀值 + 此zone保留的页框数量。kswapd就会停止内存回收,然后唤醒在等待队列的进程。
之后进程由于内存不足,对zonelist进行直接回收时,会调用到try_to_free_pages(),在这个函数内,决定了进程是否加入到node结点的pgdat->pfmemalloc_wait这个等待队列中,如下:
unsigned long try_to_free_pages(struct zonelist *zonelist, int order, gfp_t gfp_mask, nodemask_t *nodemask) { unsigned long nr_reclaimed; struct scan_control sc = { /* 打算回收32个页框 */ .nr_to_reclaim = SWAP_CLUSTER_MAX, .gfp_mask = current_gfp_context(gfp_mask), .reclaim_idx = gfp_zone(gfp_mask), /* 本次内存分配的order值 */ .order = order, /* 允许进行回收的node掩码 */ .nodemask = nodemask, /* 优先级为默认的12 */ .priority = DEF_PRIORITY, /* 与/proc/sys/vm/laptop_mode文件有关 * laptop_mode为0,则允许进行回写操作,即使允许回写,直接内存回收也不能对脏文件页进行回写 * 不过允许回写时,可以对非文件页进行回写 */ .may_writepage = !laptop_mode, /* 允许进行unmap操作 */ .may_unmap = 1, /* 允许进行非文件页的操作 */ .may_swap = 1, };BUILD_BUG_ON(MAX_ORDER > S8_MAX);
BUILD_BUG_ON(DEF_PRIORITY > S8_MAX);
BUILD_BUG_ON(MAX_NR_ZONES > S8_MAX);/* 当zonelist中获取到的第一个node平衡,则返回,如果获取到的第一个node不平衡,则将当前进程加入到pgdat->pfmemalloc_wait这个等待队列中
* 这个等待队列会在kswapd进行内存回收时,如果让node平衡了,则会唤醒这个等待队列中的进程
* 判断node平衡的标准:
* 此node的ZONE_DMA和ZONE_NORMAL的总共空闲页框数量 是否大于 此node的ZONE_DMA和ZONE_NORMAL的平均min阀值数量,大于则说明node平衡
* 加入pgdat->pfmemalloc_wait的情况
* 1.如果分配标志禁止了文件系统操作,则将要进行内存回收的进程设置为TASK_INTERRUPTIBLE状态,然后加入到node的pgdat->pfmemalloc_wait,并且会设置超时时间为1s
* 2.如果分配标志没有禁止了文件系统操作,则将要进行内存回收的进程加入到node的pgdat->pfmemalloc_wait,并设置为TASK_KILLABLE状态,表示允许 TASK_UNINTERRUPTIBLE 响应致命信号的状态
* 返回真,表示此进程加入过pgdat->pfmemalloc_wait等待队列,并且已经被唤醒
* 返回假,表示此进程没有加入过pgdat->pfmemalloc_wait等待队列
*/
if (throttle_direct_reclaim(sc.gfp_mask, zonelist, nodemask))
return 1;set_task_reclaim_state(current, &sc.reclaim_state);
trace_mm_vmscan_direct_reclaim_begin(order, sc.gfp_mask);/* 进行内存回收,有三种情况到这里
* 1.当前进程为内核线程
* 2.最优node是平衡的,当前进程没有加入到pgdat->pfmemalloc_wait中
* 3.当前进程接收到了kill信号
*/
nr_reclaimed = do_try_to_free_pages(zonelist, &sc);trace_mm_vmscan_direct_reclaim_end(nr_reclaimed);
set_task_reclaim_state(current, NULL);return nr_reclaimed;
}主要通过throttle_direct_reclaim()函数判断是否加入到pgdat->pfmemalloc_wait等待队列中,主要看此函数:
static bool throttle_direct_reclaim(gfp_t gfp_mask, struct zonelist *zonelist, nodemask_t *nodemask) { struct zoneref *z; struct zone *zone; pg_data_t *pgdat = NULL;/* 如果标记了PF_KTHREAD,表示此进程是一个内核线程,则不会往下执行 */
if (current->flags & PF_KTHREAD)
goto out;/* 此进程已经接收到了kill信号,准备要被杀掉了 */
if (fatal_signal_pending(current))
goto out;/* 遍历zonelist,但是里面只会在获取到第一个pgdat时就跳出 */
for_each_zone_zonelist_nodemask(zone, z, zonelist,
gfp_zone(gfp_mask), nodemask) {
/* 只遍历ZONE_NORMAL和ZONE_DMA区 */
if (zone_idx(zone) > ZONE_NORMAL)
continue;/* 获取zone对应的node */
pgdat = zone->zone_pgdat;
/* 判断node是否平衡,如果平衡,则返回真
* 如果不平衡,如果此node的kswapd没有被唤醒,则唤醒,并且这里唤醒kswapd只会对ZONE_NORMAL以下的zone进行内存回收
* node是否平衡的判断标准是:
* 此node的ZONE_DMA和ZONE_NORMAL的总共空闲页框数量 是否大于 此node的ZONE_DMA和ZONE_NORMAL的平均min阀值数量,大于则说明node平衡
*/
if (allow_direct_reclaim(pgdat))
goto out;
break;
}if (!pgdat)
goto out;count_vm_event(PGSCAN_DIRECT_THROTTLE);
if (!(gfp_mask & __GFP_FS))
/* 如果分配标志禁止了文件系统操作,则将要进行内存回收的进程设置为TASK_INTERRUPTIBLE状态,然后加入到node的pgdat->pfmemalloc_wait,并且会设置超时时间为1s
* 1.allow_direct_reclaim(pgdat)为真时被唤醒,而1s没超时,返回剩余timeout(jiffies)
* 2.睡眠超过1s时会唤醒,而allow_direct_reclaim(pgdat)此时为真,返回1
* 3.睡眠超过1s时会唤醒,而allow_direct_reclaim(pgdat)此时为假,返回0
* 4.接收到信号被唤醒,返回-ERESTARTSYS
*/
wait_event_interruptible_timeout(pgdat->pfmemalloc_wait,
allow_direct_reclaim(pgdat), HZ);
else
/* 如果分配标志没有禁止了文件系统操作,则将要进行内存回收的进程加入到node的pgdat->pfmemalloc_wait,并设置为TASK_KILLABLE状态,表示允许 TASK_UNINTERRUPTIBLE 响应致命信号的状态
* 这些进程在两种情况下被唤醒
* 1.allow_direct_reclaim(pgdat)为真时
* 2.接收到致命信号时
*/
wait_event_killable(zone->zone_pgdat->pfmemalloc_wait,
allow_direct_reclaim(pgdat));/* 如果加入到了pgdat->pfmemalloc_wait后被唤醒,就会执行到这 */
/* 唤醒后再次检查当前进程是否接受到了kill信号,准备退出 */
if (fatal_signal_pending(current))
return true;out:
return false;
}-
分配标志中没有__GFP_NO_KSWAPD,只有在透明大页的分配过程中会有这个标志。 -
node中有至少一个zone的空闲页框没有达到 空闲页框数量 >= high阀值 + 1 << order + 保留内存,或者有至少一个zone需要进行内存压缩,这两种情况node的kswapd都会被唤醒。
-
swapin
使用kprobe跟踪swap_readpage()内核函数,这会在触发换页所在的进程上下文中进行,可以跟踪触发换页操作的进程的信息。展示了哪个进程正在从换页设备中换入页,前提是系统中有正在使用的换页设备。
换页操作在应用程序使用那些已经被换出到换页设备上的内存时触发。这是⼀个很重要的由于换页导致的应用性能影响指标。其他的换页相关指标,例如扫描和换出操作, 并不直接影响应用程序的性能。
extern int swap_readpage(struct page *page, bool do_poll);
hfaults
使用kprobe跟踪hugetlb_fault()函数,可以从该函数的参数中抓取很多的详细信息,包括mm_struct结构体和vm_area_struct结构体。可以通过vm_area_struct结构体来抓取文件名信息。
通过跟踪巨页相关的缺页错误信息,按进程展示详细信息,同时可以用来确保巨页确实被启用了。
vm_fault_t hugetlb_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)原创文章,作者:速盾高防cdn,如若转载,请注明出处:https://www.sudun.com/ask/57207.html
