
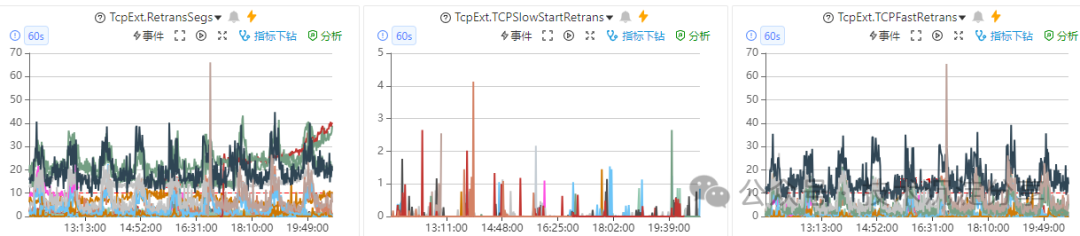
在排查一次业务网络抖动的问题时,发现K8S节点的业务TCP重传比较明显,而且呈现出周期性抖动,经过分析大概每个小时抖动一次,并且是从每个小时的40分开始,持续大概25分钟左右才恢复,而且节点上的几乎所有在线服务都表现一致,该现象在很多机器上都有出现。
排查过程
看到该现象的一次反应就是可能有什么定时任务导致的,按照以往的经验确实出现过类似的问题。排查主机后发现并没有定时任务,并反馈给了云也没有定时任务执行。
会不会和内核或者机型有关系?
查看抖动的节点的内核版本发现内核既有高版本也有低版本,初步排除是内核导致的;对抖动节点的机型进行分析发现机型有汇聚的现象,都汇聚在了同一个机型上面。初步怀疑应该和机型有关系。
在内部排查的同时也反馈了给云厂商一起排查,因为毕竟有机型汇聚的现象,所以也不能排除是云厂商的问题导致的。
接下来分析下重传的包到底是什么包?
首先想到的就是使用BCC的tcpretrans工具抓取重传包信息,在机器上安装上了bcc和bpftrace工具,用bcc的tcpretrans工具抓取结果如下(这里是在抖动剧烈的时间点抓取的结果):
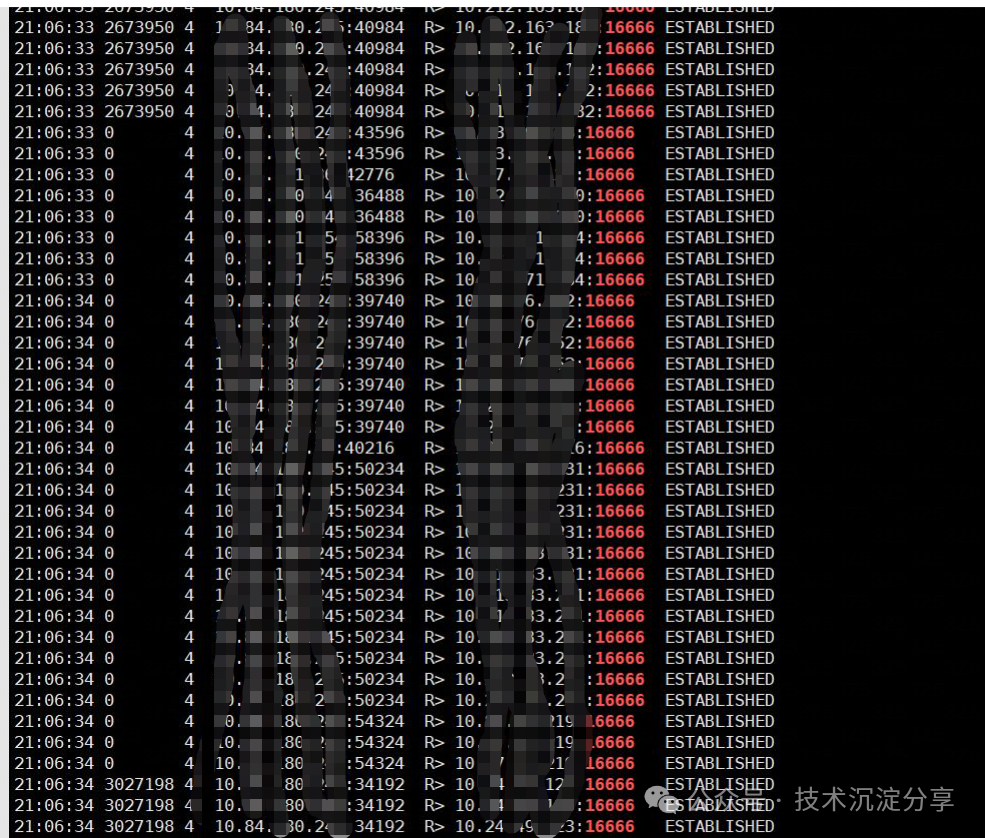
从抓取的结果看,抖动剧烈的时间点,有不少重传包都是到目的端口是16666端口的包。将目的ip在CMDB上查询发现都是监控的服务。一般在线业务的代码里会调用监控SDK进行打点上报数据,和监控到底有没有关系,需要和监控研发确认。
经和监控开发确认,SDK确实有每个小时会集中重连consumer的逻辑,但连接很快,基本几秒就完成了。但从监控看,对应时间点的服务的重传增加趋势会持续比较长时间,和监控开发同学的说法不一致。那到底是不是发往port 16666端口的重传包增加了呢?
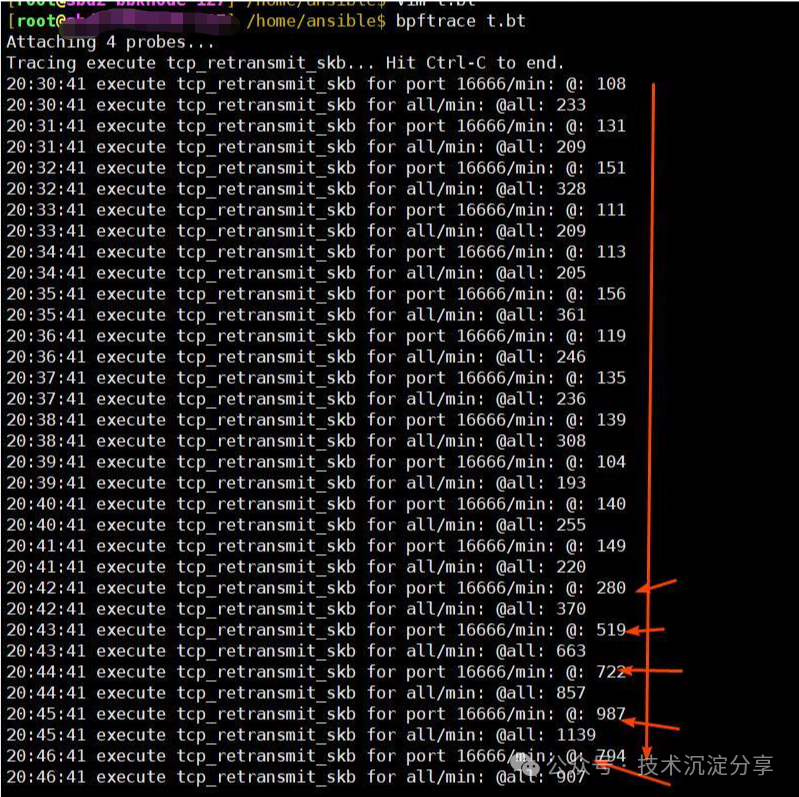
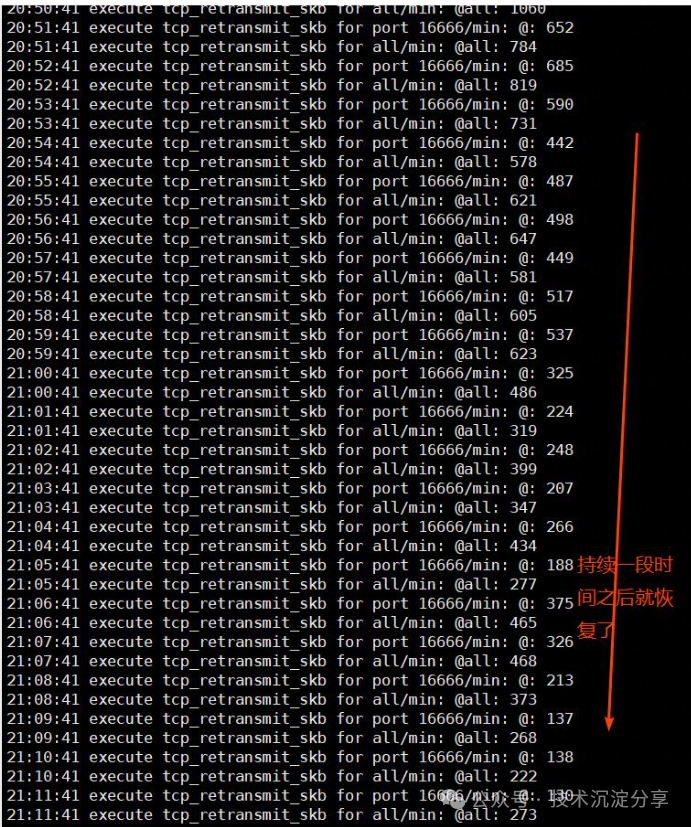
接下来我们写个bpftrace脚本trace结果如下:
bpftrace脚本如下:
#!/usr/bin/bpftrace#include <net/sock.h>#include <linux/skbuff.h>#include <net/sock.h>#include <linux/skbuff.h>#include <linux/ip.h>#include <linux/tcp.h>#include <linux/types.h>#include <net/tcp.h>BEGIN{printf("Tracing execute tcp_retransmit_skb... Hit Ctrl-C to end.n");}kprobe:tcp_retransmit_skb{$skb=((struct sk_buff *)arg1);$sk = ((struct sock *)arg0);$family = $sk->__sk_common.skc_family;$state = $sk->__sk_common.skc_state;$dport = $sk->__sk_common.skc_dport;$tcp = (struct tcphdr *)($skb->head + $skb->transport_header);$ip = (struct iphdr *)($skb->head + $skb->network_header);$sport = $tcp->source;// $dport = $tcp->dest;$sp = (((uint16)($sport) & 0xff00) >> 8) | (((uint16)($sport) & 0x00ff) << 8);$dp = (((uint16)($dport) & 0xff00) >> 8) | (((uint16)($dport) & 0x00ff) << 8);$saddr = $ip->saddr;$daddr = $ip->daddr;$st = $sk->sk_state;if($dp==16666){@ = count();}@all = count();}interval:s:60{time("%H:%M:%S execute tcp_retransmit_skb for port 16666/min: ");print(@);clear(@);time("%H:%M:%S execute tcp_retransmit_skb for all/min: ");print(@all);clear(@all);}END{clear(@);clear(@all);}
从监控可以看到,从时间点20:42分左右开始,重传包总量以及发现端口16666的重传包都增加了,并且在持续了20+分钟左右之后又降下来了,和监控图的趋势是一致的,而且重传包的大头主要就是发往端口16666的包。
通过trace发现重传包主要都是到16666端口的包,再次和监控研发确认,监控server会在每个小时的40分左右向client下发指令,即client会重新选择consumer进行连接,这个过程确实可能会有重传包的现象出现。但这不影响业务,只是监控SDK的重传包而已。
为什么只有该机型会出现呢?
通过分析发现集中出现的这个机型的规格很大,比其他机型大很多,猜测可能是上面部署的在线业务多导致的,于是查看了另外一个云厂商的同规格的机器发现TCP重传也有类似的抖动问题。基本可以确定是大量业务的内置监控SDK在周期性的集中时间点重连consumer导致的重传。
本文通过BCC&bpftrace工具分析出业务TCP重传的问题,并排查到导致重传的原因,该问题并没有对线上业务造成影响,不过可能会干扰其他问题的排查和分析,因此后续遇到问题排查时遇到该问题时可以忽略
原创文章,作者:速盾高防cdn,如若转载,请注明出处:https://www.sudun.com/ask/58867.html
