
在广阔的网络世界中,代理服务器充当无声的守护者,调解客户端(如您的 Web 浏览器)和 Internet 上的服务器之间的通信。本指南揭开了代理服务器的秘密,探索了它们的优势、不同类型,甚至提供了开发人员示例来说明它们的强大功能。
无论您是经验丰富的开发人员,还是刚刚开始了解复杂的网络,了解代理服务器都可以显著增强您对 Web 流量的理解,并为开发任务提供有价值的工具。
以下是您将在本综合指南中发现的内容:
- 代理服务器的强大功能:我们将深入探讨代理服务器提供的主要好处,包括改进的性能、增强的安全性和内容过滤功能。
- 代理类型的世界:探索各种类型的代理服务器,每种服务器都针对特定目的量身定制,从转发代理到缓存代理等。
- 面向开发人员的代码示例:深入了解实际代码示例,演示如何使用 Python 等流行语言在开发项目中利用代理服务器。
在本指南结束时,您将掌握以下知识:
- 解释代理服务器在网络通信中的作用。
- 根据您的特定需求选择正确的代理服务器类型。
- 在开发工作流中有效利用代理服务器。
因此,让我们准备好踏上迷人的代理服务器世界的旅程吧!
1.代理服务器的强大功能
代理服务器为用户和网络管理员提供了一系列优势。以下是它们的主要优势的细分:

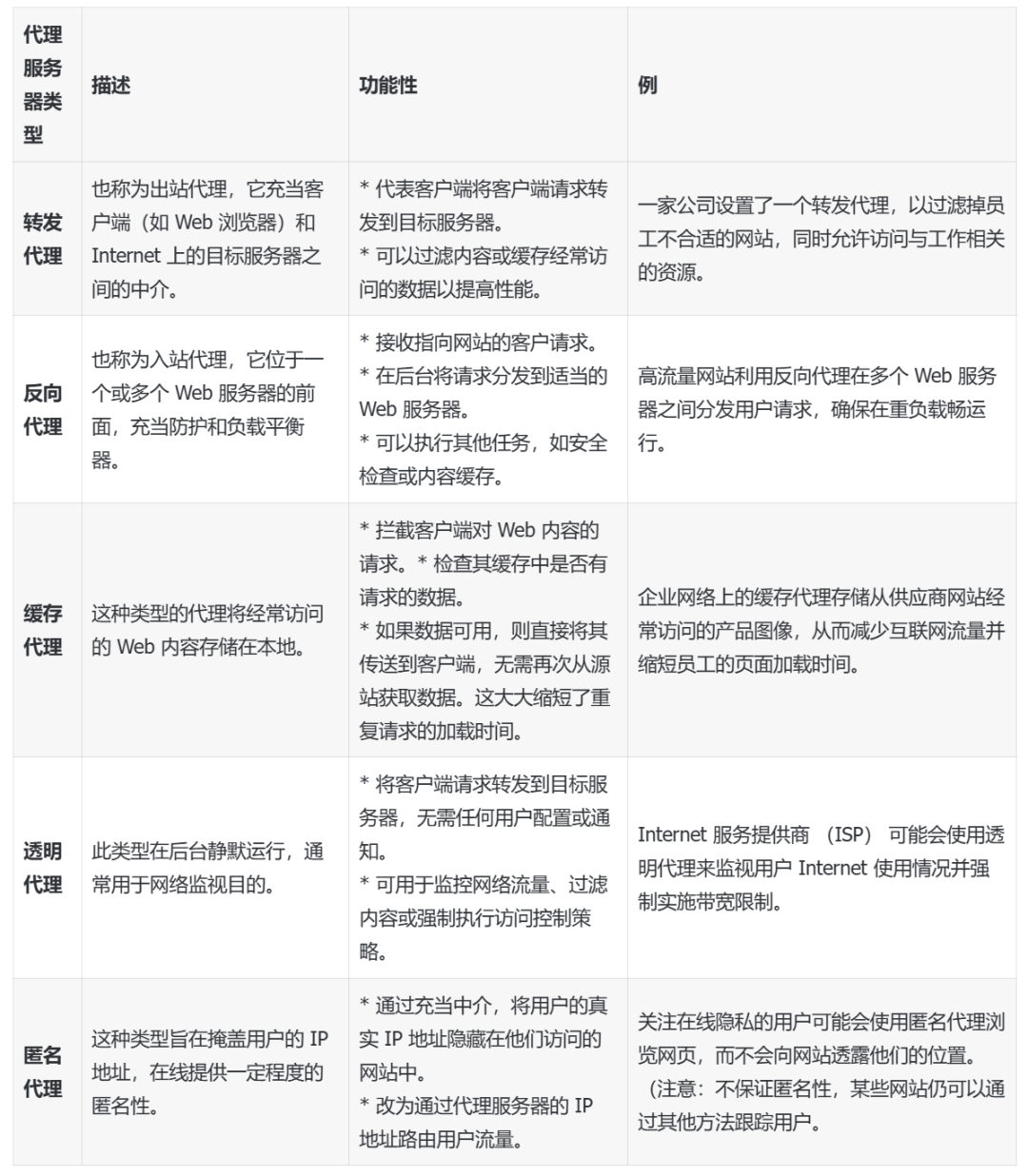
2. 代理服务器的分类
代理服务器有多种风格,每种风格都满足特定需求。以下是一些常见类型及其功能的细分:
3. 代理服务器的实际应用:开发人员示例
代理服务器为开发人员提供了有价值的工具,可以执行访问受限制的网站、高效抓取网页和监控网络流量等任务。以下是一些演示其应用程序的 Python 代码示例:
示例 1:访问被阻止的网站(使用请求库)
此示例利用该库通过代理服务器访问您所在区域被阻止的网站。requests
import requests# Proxy server details (replace with actual proxy details)proxy_host = "your_proxy_host"proxy_port = your_proxy_portproxy_username = "your_proxy_username" (if username/password required)proxy_password = "your_proxy_password" (if username/password required)# Website URL to accesstarget_url = "https://www.blockedwebsite.com"# Build proxy dictionary (if username/password required)if proxy_username and proxy_password:proxy_auth = requests.auth.HTTPBasicAuth(proxy_username, proxy_password)proxies = {"http": f"http://{proxy_host}:{proxy_port}", "https": f"https://{proxy_host}:{proxy_port}"}else:proxies = {"http": f"http://{proxy_host}:{proxy_port}", "https": f"https://{proxy_host}:{proxy_port}"}try:# Send request through the proxyresponse = requests.get(target_url, proxies=proxies, auth=proxy_auth if proxy_username else None)response.raise_for_status() # Raise an exception for unsuccessful requests# Access the website contentprint(response.content)except requests.exceptions.RequestException as e:print(f"Error accessing website: {e}")
解释:
- 该脚本导入用于发出 HTTP 请求的库。
requests - 将占位符替换为实际的代理详细信息(主机、端口、用户名和密码,如果适用)。
- 该变量存储您要访问的网站。
target_url - 创建一个字典 proxies() 来定义代理服务器地址(包括协议)。
- 如果代理身份验证需要用户名和密码,则使用并包含在请求中。
HTTPBasicAuth - 该脚本通过指定的代理服务器向目标 URL 发送 GET 请求。
- 成功响应后,将打印网站内容。
- 捕获并显示请求期间遇到的任何错误。
重要提示:尊重网站和抓取目标的服务条款。此示例仅用于教育目的。
示例 2:使用代理轮换进行网页抓取(将 Selenium 与代理管理器一起使用)
此示例演示了将 Selenium 与代理管理器库一起使用,以在 Web 抓取时轮换代理,从而降低检测风险。
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom fake_useragent import UserAgentfrom pyvirtualdisplay import Display # Optional for headless scraping# Proxy manager library (replace with your chosen library)from proxy_rotator import ProxyRotator# Website URL to scrape and element selectortarget_url = "https://www.example-data.com"data_selector = ".product-item"# Configure proxy manager (replace with your provider's details)proxy_rotator = ProxyRotator(provider_url="your_proxy_provider_url", username="your_username", password="your_password")# Optional: Set up headless scraping with virtual displaydisplay = Display(visible=0, size=(800, 600)) # Comment out for non-headless executiondisplay.start()# Create a new Chrome session with UserAgent and proxyuser_agent = UserAgent().chromechrome_options = webdriver.ChromeOptions()chrome_options.add_argument(f"user-agent={user_agent}")chrome_options.add_argument("--proxy-server=" + proxy_rotator.get_proxy())driver = webdriver.Chrome(options=chrome_options)try:driver.get(target_url)# Extract data from the target elementsdata_elements = driver.find_elements(By.CSS_SELECTOR, data_selector)for element in data_elements:# Process and extract desired data from each element# Rotate proxy after each scrape iteration (optional)proxy_rotator.rotate()except Exception as e:print(f"Error during scraping: {e}")finally:driver.quit()display.stop() # Stop virtual display if used
解释:
- 此示例利用 Selenium 实现 Web 浏览器自动化,并利用库为每个请求生成随机用户代理。
fake_useragent - 包含一个用于无头抓取(在后台运行浏览器)的可选库。
pyvirtualdisplay - 将占位符替换为所选代理旋转器库的详细信息(提供程序 URL、用户名和密码)。
- 该脚本将代理旋转器配置为在每次抓取迭代之前检索新的代理地址。
- 该代码使用检索到的代理地址和随机用户代理设置一个无外设 Chrome 浏览器会话,以模拟真实用户。
- 然后,它导航到目标 URL,并使用 CSS 选择器从指定元素中提取数据。
- 您需要替换循环中的数据处理逻辑,以处理要抓取的特定数据。
- 每次抓取迭代后,可以选择调用该函数,以切换到新的代理并降低被阻止的风险。
proxy_rotator.rotate() - 错误处理和浏览器清理是使用 和 blocks 实现的。
try-exceptfinally
示例 3:使用代理服务器监视网络流量(使用 Scapy)
此示例演示如何使用 Scapy(网络数据包操作库)设置捕获和分析网络流量的简单代理服务器。
from scapy.all import sniff, IP, TCP, Rawdef handle_packet(packet):# Check if it's a TCP packet (modify for other protocols if needed)if packet[TCP]:print(f"Source IP: {packet[IP].src}")print(f"Destination IP: {packet[IP].dst}")print(f"Source Port: {packet[TCP].sport}")print(f"Destination Port: {packet[TCP].dport}")# Access packet data if needed (modify for specific use cases)# data = packet[Raw]# print(f"Packet Data: {data}")# Set up the proxy server (modify IP address and port as needed)sniff(iface="eth0", prn=handle_packet, filter="tcp", store=False)
解释:
- 此示例利用 Scapy 捕获和分析网络流量。
- 该函数用于捕获特定网络接口上的数据包(将“eth0”替换为您的实际接口名称)。
sniff - 为每个捕获的数据包调用该函数。
handle_packet - 在函数内部,我们检查数据包是否为 TCP 数据包(如果需要,可以修改其他协议)。
- 然后,我们提取并打印源和目标 IP 地址、端口等信息。
- 您可以进一步修改代码以访问数据包数据(例如,使用 ),以便根据您的特定需求进行更详细的分析。
packet[Raw]
这是一个非常基本的例子,仅用于教育目的。设置成熟的代理服务器涉及更复杂的配置和安全注意事项。
4. 结论
本指南揭示了代理服务器的强大功能。您已经探索了它们的优势,从增强的安全性到内容过滤。我们甚至通过 Python 代码示例将这些知识付诸实践,演示了如何利用代理:
- 征服被阻止的网站:通过代理路由流量来访问受限内容。
- 使用隐身进行网页抓取:通过代理轮换有效地抓取数据,以避免被发现。
- 网络流量速览:设置代理服务器以监视和分析网络活动以进行调试。
原创文章,作者:速盾高防cdn,如若转载,请注明出处:https://www.sudun.com/ask/76560.html
