

 WebScraper的主要特点
WebScraper的主要特点-
多页面数据抓取:您可以从多个网页上提取数据。 -
多种数据提取类型:支持文本、图片、URL等多种数据类型。 -
动态页面数据抓取:能够处理JavaScript和AJAX生成的内容,以及无限滚动页面。 -
数据预览:在抓取过程中即时查看数据。 -
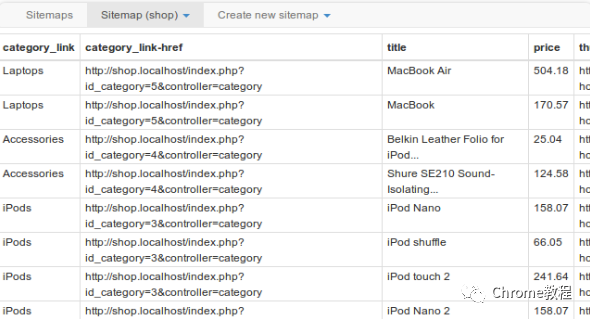
数据导出:支持将数据导出为CSV或XLSX格式,便于在Excel或Google Sheets等工具中进一步处理。
安装和启动
以下是WebScraper插件的安装步骤:

使用步骤详解
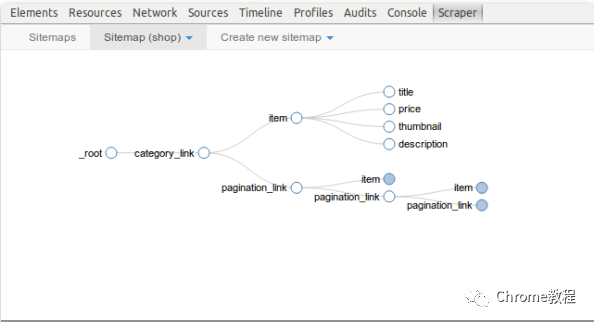
创建站点地图
-
打开您想要抓取的网站。 -
在“WebScraper”标签中点击“Create new sitemap”。 -
输入一个独特的站点地图名称和起始URL。 -
点击“Create Sitemap”按钮。
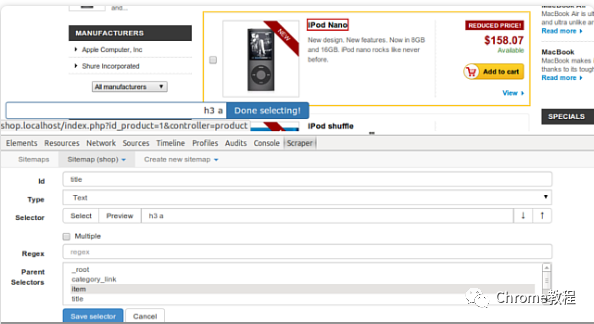
添加数据提取选择器
-
在站点地图中,点击“Add new selector”。 -
输入选择器名称,选择适当的类型(例如文本、链接、图片等)。 -
使用点选工具在网页上选择您想要提取的数据区域。 -
设置选择器的其他参数,例如选择器的父选择器或延迟时间(对于动态加载内容)。
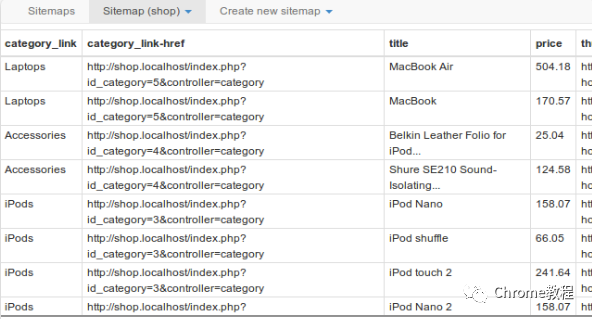
启动爬虫和导出数据
-
在站点地图视图中,点击“Scrape”按钮开始数据提取过程。 -
等待爬虫完成抓取。 -
抓取完成后,点击“Export data”以CSV或XLSX格式导出数据。
结语原创文章,作者:速盾高防cdn,如若转载,请注明出处:https://www.sudun.com/ask/77825.html