
如果对编程语言进行分类的话,一般可以分为静态语言和动态语言,也可以分为编译型语言和解释型语言。但个人觉得还可以有一种划分标准,就是是否自带垃圾回收。关于有没有垃圾回收,陈儒老师在《Python 2.5源码剖析》中,总结得非常好。
对于像 C 和 C++ 这类语言,程序员被赋予了极大的自由,可以任意地申请内存。但权力的另一面对应着责任,程序员最后不使用的时候,必须负责将申请的内存释放掉,并把无效指针设置为空。可以说,这一点是万恶之源,大量内存泄漏、悬空指针、越界访问的 bug 由此产生。
而现代的开发语言(比如 C#、Java)都带有垃圾回收机制,将开发人员从维护内存分配和清理的繁重工作中解放出来,开发者不用再担心内存泄漏的问题,但同时也剥夺了程序员和内存亲密接触的机会,并牺牲了一定的运行效率。不过好处就是提高了开发效率,并降低了 bug 发生的概率。
由于现在的垃圾回收机制已经非常成熟了,把对性能的影响降到了最低,因此大部分场景选择的都是带垃圾回收的语言。
而 Python 里面同样具有垃圾回收,只不过它是为引用计数机制服务的。所以解释器通过内部的引用计数和垃圾回收,代替程序员进行繁重的内存管理工作,关于垃圾回收我们后面会详细说,先来看一下引用计数。

引用计数
Python 一切皆对象,所有对象都有一个 ob_refcnt 字段,该字段维护着对象的引用计数,从而也决定对象的存在与消亡。下面来探讨一下引用计数,当然引用计数在介绍 PyObject 的时候说的很详细了,这里再回顾一下。
但需要说明的是,比起类型对象,我们更关注实例对象的行为。引用计数也是如此,只有实例对象,我们探讨引用计数才是有意义的。
因为内置的类型对象超越了引用计数规则,永远都不会被析构,或者销毁,因为它们在底层是被静态定义好的。
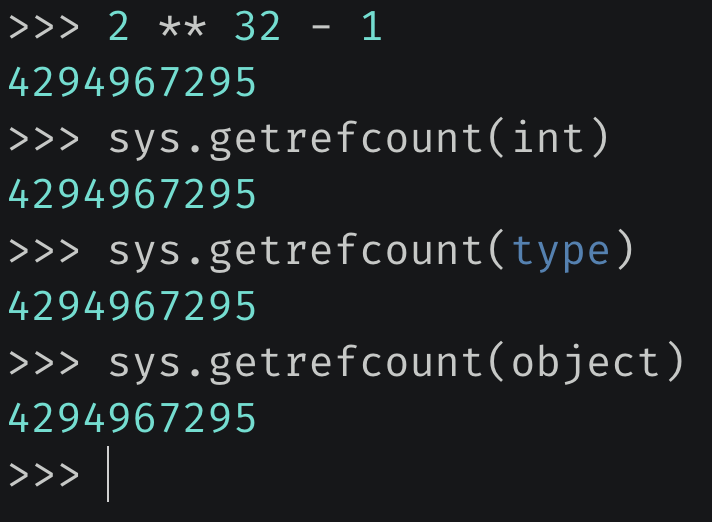
很明显,内置的类型对象属于永恒对象。关于永恒对象之前解释过,指的是那些永远不会被回收的对象,像 None、小整数对象池里面的整数、以及内置的类型对象,它们都是永恒对象。
如果对象是永恒对象,那么它的引用计数会直接被初始化为 uint32 最大值。当然,如果一个对象原本不是永恒对象,但它的引用计数之后达到了 uint32 最大值(有 2 ** 32 – 1 个变量在引用它),那么它也会被判定为永恒对象,但很明显这只是理论情况,现实不可能出现,因为一个对象不可能有这么多的变量在引用它。
同理,我们自定义的类,虽然可以被回收,但是探讨它的引用计数也是没有价值的。我们举个栗子:
class A:
pass
del A首先 del 关键字只能作用于变量,不可以作用于对象,比如 e = 2.71,可以 del e,但是不可以 del 2.71,这是不符合语法规则的。因为 del 的作用是删除变量,并让其指向对象的引用计数减 1,所以我们只能 del 变量,不可以 del 对象。
同样的,使用 def、class 关键字定义完之后拿到的也是变量,比如上面代码中的 A,只要是变量,就可以被 del。但是 del 变量只是删除了该变量,换言之就是让该变量无法再被使用,至于变量指向的对象是否会被回收,就看是否还有其它的变量也指向它。
总结:对象是否被回收完全由解释器判断它的引用计数是否为 0 所决定。
永恒对象
我们一直说对象的 ob_refcnt 字段负责维护引用计数,当然这是没问题的。但 Python 从 3.12 开始又引入了 ob_refcnt_split 字段,也负责维护引用计数。

ob_refcnt_split 是一个长度为 2、类型为 uint32 的数组,但只会用其中一个元素来维护引用计数。如果达到了 uint32 最大值,那么判定为永恒对象,相关源码后续聊。
我们来看看永恒对象的初始化过程,以 list 类型对象为例,看看它的引用计数是怎么设置的。
// Objects/listobject.c
// 引用计数和类型由宏 PyVarObject_HEAD_INIT 负责设置
PyTypeObject PyList_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"list",
sizeof(PyListObject),
0,
...
};
// Include/object.h
#define PyVarObject_HEAD_INIT(type, size)
{
PyObject_HEAD_INIT(type)
(size)
},
#define PyObject_HEAD_INIT(type)
{
{ _Py_IMMORTAL_REFCNT },
(type)
},
#define _Py_IMMORTAL_REFCNT UINT_MAX 我们看到类型对象在初始化的时候,引用计数直接被设置成了 uint32 最大值。当然啦,这并不是说有 2 ** 32 – 1 个变量在引用,而是通过将引用计数设置为 uint32 最大值,来表示这是一个不会被销毁的永恒对象。
源码解密引用计数的相关操作
操作引用计数无非就是将其加一或减一,至于什么时候加一、什么时候减一,在介绍 PyObject 的时候已经说的很详细了,可以看一下。这里我们通过源码,看看引用计数具体是怎么操作的。
在底层,解释器会通过 Py_INCREF 和 Py_DECREF 两个函数来增加和减少对象的引用计数,而当对象的引用计数减少到 0 后,Py_DECREF 将调用对应的析构函数来释放该对象所占的内存和系统资源。这个析构函数由对象的类型对象中定义的函数指针来指定,也就是 tp_dealloc。
下面我们来看看底层实现,不过在介绍 Py_INCREF 和 Py_DECREF 之前,先来看几个其它的函数,这些函数非常常见,有必要单独说一下。
// Include/object.h
// 返回对象的引用计数,说白了就是获取对象的 ob_refcnt 字段
// 因为该字段负责维护引用计数
static inline Py_ssize_t Py_REFCNT(PyObject *ob) {
return ob->ob_refcnt;
}
// 设置对象的引用计数
static inline void Py_SET_REFCNT(PyObject *ob, Py_ssize_t refcnt) {
// 如果对象是永恒对象,那么直接返回
// 不会再对永恒对象的引用计数做任何设置
if (_Py_IsImmortal(ob)) {
return;
}
ob->ob_refcnt = refcnt;
}
// 返回对象的类型,获取 ob_type 字段
static inline PyTypeObject* Py_TYPE(PyObject *ob) {
return ob->ob_type;
}
// 设置对象的类型
static inline void Py_SET_TYPE(PyObject *ob, PyTypeObject *type) {
ob->ob_type = type;
}
// 返回对象的 ob_size
static inline Py_ssize_t Py_SIZE(PyObject *ob) {
// _PyVarObject_CAST(ob) 等价于 (PyVarObject *)(ob)
return _PyVarObject_CAST(ob)->ob_size;
}
// 设置对象的 ob_size
static inline void Py_SET_SIZE(PyVarObject *ob, Py_ssize_t size) {
ob->ob_size = size;
}这几个函数是用来设置引用计数、类型和 ob_size 的,比较简单,即使不看源码也能猜出内部都做了什么。需要注意的是,这些函数在之前的 Python 源码中都是以宏的形式存在,但在 3.12 里面变成内联函数了,本质上没有太大差异。
然后来看看 Py_INCREF 和 Py_DECREF,它们负责对引用计数执行加一和减一操作。
注意:这两个函数里面存在宏判断,我们这里只保留判断之后的结果。
// Include/object.h
static inline Py_ALWAYS_INLINE void Py_INCREF(PyObject *op)
{
// ob_refcnt_split 是长度为 2 的数组,但只会使用一个元素
// 至于使用哪一个,则取决于字节序,是大端存储还是小端存储
PY_UINT32_T cur_refcnt = op->ob_refcnt_split[PY_BIG_ENDIAN];
// 将当前引用计数加一
PY_UINT32_T new_refcnt = cur_refcnt + 1;
// 如果 cur_refcnt 已经达到了 uint32 最大值,那么加一之后会产生环绕,继续从零开始
// 所以如果 new_refcnt 为 0,证明当前对象的引用计数为 uint32 最大值
// 那么该对象就是永恒对象,而永恒对象不会被回收,引用计数也不再做处理,因此直接返回
if (new_refcnt == 0) {
return;
}
// 否则说明不是引用计数,那么进行更新
op->ob_refcnt_split[PY_BIG_ENDIAN] = new_refcnt;
// 稍后解释
_Py_INCREF_STAT_INC();
}这里估计有人发现了一个问题,就是当前只更新了 ob_refcnt_split,而没有更新 ob_refcnt。原因很简单,因为这两个字段组成的是共同体,它们占用同一份内存。
ob_refcnt 是 int64 整数,ob_refcnt_split 是长度为 2 的 uint32 数组,它们都是 8 字节,并且占用的是同一份 8 字节的内存。所以 ob_refcnt_split 里面的两个元素正好对应 ob_refcnt 的低 32 位和高 32 位。
因此在修改 ob_refcnt_split 的时候,同时也修改了 ob_refcnt,所以整个操作只进行了一次。并且从源码中也可以看出,对象的引用计数不会超过 uint32 最大值,因为当达到这个值的时候会被判定为永恒对象,而永恒对象的引用计数不会再做任何操作,因为永恒对象会永远存在。
但还是那句话,除非一开始就将引用计数设置为 uint32 最大值,让对象成为永恒对象,否则单靠创建变量是不可能让对象的引用计数达到这一限制的,因为不管再复杂的项目,也不会出现一个对象被 2 ** 32 – 1 个变量指向的情况,所以 uint32 是完全够用的。
然后在函数的最后出现了一个 _Py_INCREF_STAT_INC 函数,它负责对一些全局统计信息进行更新,目前无需关注。
以上是 Py_INCREF,负责将引用计数加一,再来看看 Py_DECREF,它负责将引用计数减一。
// Include/object.h
static inline Py_ALWAYS_INLINE void Py_DECREF(PyObject *op)
{
// 如果对象是永恒对象,那么直接返回,因为永恒对象不会被回收
// 它的引用计数不会再发生变化,始终保持 uint32 最大值
if (_Py_IsImmortal(op)) {
return;
}
// 更新一些全局统计信息,和 _Py_INCREF_STAT_INC 作用一样
_Py_DECREF_STAT_INC();
// 重点来了,首先将 ob_refcnt 减一,然后判断它是否等于 0
// 如果为 0,说明对象已经不被任何变量引用了,那么应该被销毁
if (--op->ob_refcnt == 0) {
// 调用 _Py_Dealloc 将对象销毁,这个函数内部的逻辑很简单
// 虽然里面存在很多宏判断,导致代码看起来很复杂
// 但如果只看编译后的最终结果,那么代码就只有下面三行
/*
PyTypeObject *type = Py_TYPE(op);
destructor dealloc = type->tp_dealloc;
(*dealloc)(op);
*/
// 会获取类型对象的 tp_dealloc,然后调用,销毁实例对象
_Py_Dealloc(op);
}
}以上就是 Py_INCREF 和 Py_DECREF 两个函数的具体实现,但是它们不能接收空指针,如果希望能接收空指针,那么可以使用另外两个函数。
Py_XINCREF 和 Py_XDECREF 会额外对指针做一次判断,如果为空则什么也不做,不为空再调用 Py_INCREF 和 Py_DECREF。
在一个对象的引用计数为 0 时,与该对象对应的析构函数就会被调用。但是要特别注意的是,我们之前说调用析构函数之后会回收对象,或者销毁对象、删除对象等等,意思是将这个对象从内存中抹去,但并不意味着要释放空间。换句话说就是对象没了,但对象占用的内存却有可能还在。
如果对象没了,占用的内存也要释放的话,那么频繁申请、释放内存空间会使 Python 的执行效率大打折扣,更何况 Python 已经背负了人们对其执行效率的不满这么多年。
所以 Python 底层大量采用了缓存池的技术,使用这种技术可以避免频繁地申请和释放内存空间。因此在析构的时候,只是将对象占用的空间归还到缓存池中,并没有真的释放。
这一点,在后面剖析内置实例对象的实现中,将会看得一清二楚,因为大部分内置的实例对象都会有自己的缓存池
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/78291.html
