
一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎。
那么,一条更新语句的执行流程又是怎样的呢?
我们还是从一个表的一条更新语句说起,下面是这个表的创建语句,这个表有一个主键 ID 和一个整型字段 c:
create table T(ID int primary key, c int);
如果要将 ID=2 这一行的值加 1,SQL 语句就会这么写:
update T set c=c+1 where ID=2;
前面我有跟你介绍过 SQL 语句基本的执行链路,这里我再把那张图拿过来,你也可以先简单看看这个图回顾下。首先,可以确定的说,查询语句的那一套流程,更新语句也是同样会走一遍。
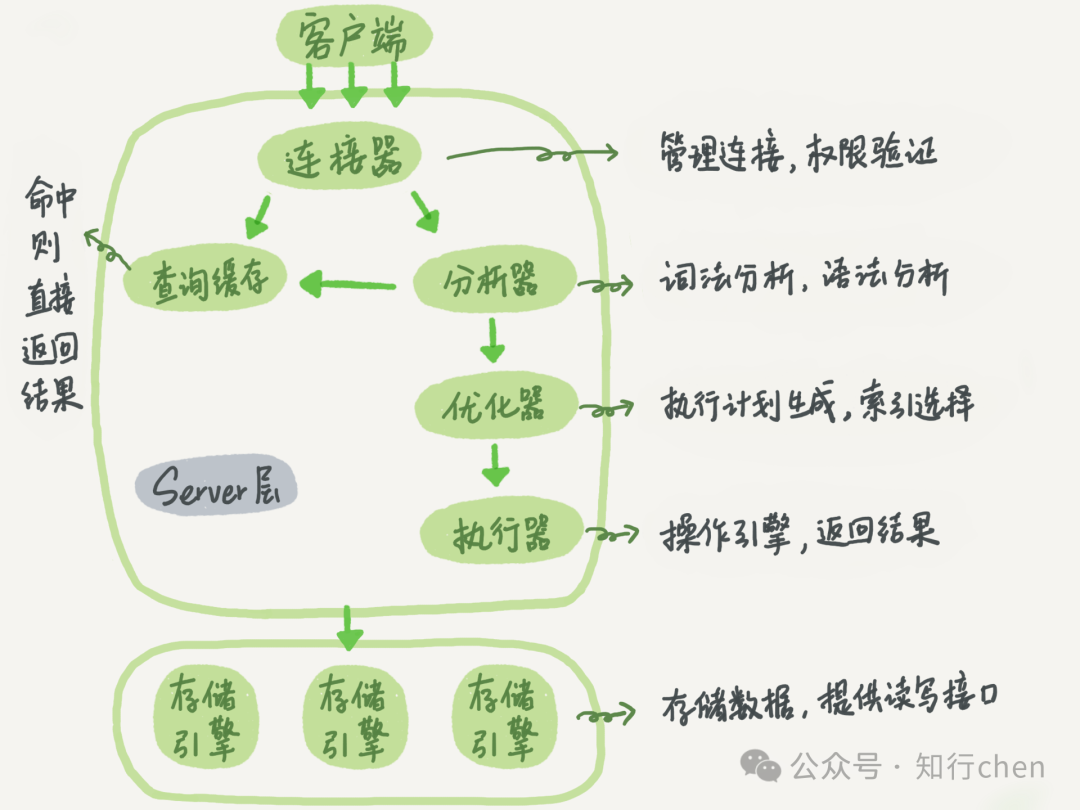

你执行语句前要先连接数据库,这是连接器的工作。
在一个表上有更新的时候,跟这个表有关的查询缓存会失效,所以这条语句就会把表 T 上所有缓存结果都清空。这也就是一般不建议使用查询缓存的原因。
接下来,分析器会通过词法和语法解析知道这是一条更新语句。优化器决定要使用 ID 这个索引。然后,执行器负责具体执行,找到这一行,然后更新。
与查询流程不一样的是,更新流程还涉及两个重要的日志模块:redo log(重做日志)和 binlog(归档日志)。
重要的日志模块:redo log
不知道你还记不记得《孔乙己》这篇文章,酒店掌柜有一个粉板,专门用来记录客人的赊账记录。如果赊账的人不多,那么他可以把顾客名和账目写在板上。但如果赊账的人多了,粉板总会有记不下的时候,这个时候掌柜一定还有一个专门记录赊账的账本。
如果有人要赊账或者还账的话,掌柜一般有两种做法:
- 一种做法是直接把账本翻出来,把这次赊的账加上去或者扣除掉;
- 另一种做法是先在粉板上记下这次的账,等打烊以后再把账本翻出来核算。
在生意红火柜台很忙时,掌柜一定会选择后者,因为前者操作实在是太麻烦了。首先,你得找到这个人的赊账总额那条记录。你想想,密密麻麻几十页,掌柜要找到那个名字,可能还得带上老花镜慢慢找,找到之后再拿出算盘计算,最后再将结果写回到账本上。
这整个过程想想都麻烦。相比之下,还是先在粉板上记一下方便。你想想,如果掌柜没有粉板的帮助,每次记账都得翻账本,效率是不是低得让人难以忍受?
同样,在 MySQL 里也有这个问题,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。为了解决这个问题,MySQL 的设计者就用了类似酒店掌柜粉板的思路来提升更新效率。
而粉板和账本配合的整个过程,其实就是 MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log(粉板)里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
如果今天赊账的不多,掌柜可以等打烊后再整理。但如果某天赊账的特别多,粉板写满了,又怎么办呢?这个时候掌柜只好放下手中的活儿,把粉板中的一部分赊账记录更新到账本中,然后把这些记录从粉板上擦掉,为记新账腾出空间。
与此类似,InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe(崩溃安全)。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/78820.html