
站在2024这个时间点上,Java Hook可以说是一门过时的技术,好比明日黄花。那还有讨论的必要么?如果只是针对现有方案的原理解析,那确实没有必要。但如果可以针对现有方案提出些建议和创新,或许还有写成文章的价值。
几年前我曾经粗略地看过一些Java Hook的文章,但都浮于表面,浅尝辄止。直到最近机缘巧合地再次碰到这个话题,因此抽空实现了一套新的Hook方案。
虽说万丈高楼平地起,但软件开发还是要学习牛顿,站在巨人的肩膀上。因此,挑选哪个巨人给我站站就显得尤其重要。选来选去,选中了维术的epic和残页(目前刚上大一,初高中就开始研究framework了,属实NB)的pine。他们的源码给了我很多帮助,让我知道一个Hook方案应该由哪些核心部件组成。
构思
动手写代码之前,有三个核心问题需要考虑:
-
采用哪种Hook原理? -
最终的API长什么样? -
需要依赖哪些库?
第一个核心问题是Hook原理。基于ART的Java Hook有两个流派,一个是入口替换,另一个是指令替换(也称inline hook)。入口替换即修改ArtMethod的entry_point_from_quick_compiled_code_字段,让它指向别的代码。指令替换指的是修改方法体头部的指令,让它跳转到别的地方。这两个流派在之前的方案中各有优缺点:
-
入口替换可能导致栈回溯失败;另外Android N在编译代码时引入了一项优化,可以不寻找entry_point_from_quick_compiled_code_而直接跳转到目标方法中,这样基于入口替换的hook会失效。 -
指令替换需要方法编译成机器码,所以这类方案都需要主动JIT。而JIT是有限制的,譬如当方法过大时JIT就会拒绝编译。
我个人的构想是Hook方案要尽量少地改变现有运行机制,所以更加倾向于入口替换。但入口替换存在的问题怎么办?经过一番研究,发现这两个问题都可以解决。
首先是栈回溯的问题。栈回溯之所以失败,是因为指向的跳板函数并非一个真实的Java方法,因此通过ArtMethod::GetOatQuickMethodHeader找到的OatQuickMethodHeader(这里面会保存frame size等关键信息)是一个非法对象。但其实libart.so内部也有很多跳板函数,它们都可能被指定为某个方法的入口。那么ART是如何保证这种情况下栈回溯不出错的呢?
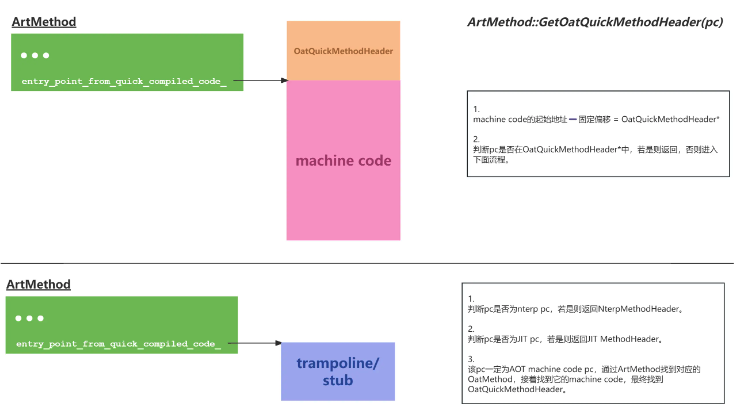

如此一来,只要我们手写的trampoline可以伪装成系统的trampoline,就可以让栈回溯正常运行。ART通过trampoline的地址是否在libart.so的r-x段内来判定它是否是系统trampoline。既然如此,我们可以找一个ART不用的方法,将trampoline写入其中,让其伪装成系统trampoline。同时,为了尽可能地减少对系统的影响,我们可以在libart.so中写入一个最简单的一级跳板,它的唯一作用就是跳转到真实处理逻辑的二级跳板。

至于Android N引入的那项优化,其实它只存活了一个版本。为了配合后续对non-PIC(Position-independent Code)的移除,Google对这种direct call的优化也进行了移除。
至此,横亘在入口替换前的两座大山彻底被搬走。
第二个核心问题是API。现有的方案也分成了两个流派,一派滥觞于Xposed,写法较为飘逸灵动;另一派的代表人物是YAHFA和FastHook,它们需要为每个hook写一个参数匹配的方法。从使用角度来说,Xposed那种API更加方便,因此最终的API设定如下。
xxxHook.setHook(method, new Hook() {
@Override
void before(Param param) throws Throwable {
...
}
@Override
void after(Param param) throws Throwable {
...
}
});
第三个核心问题是依赖库。一个Hook方案通常需要在两个维度和ART打交道,一是获取ART中重要对象的地址和某些数据结构的布局,二是调用ART的内部方法。这就需要我们有一个稳定的dlsym方案,用于查找libart.so中的全局变量和函数的地址。可是如今的Android版本中,linker namespace和hidden visibility的存在,让传统的dlsym寸步难行。好在开源社区中有一些优秀的方案,它们可以从.gnu_debugdata中解析symbol,让符号的获取变得更加可靠。这里我选择了蔡克伦的xDL,里面的文件不多,方便直接复用。
实现
至此,大的框架出来了,接下来需要进入到每个具体的板块。
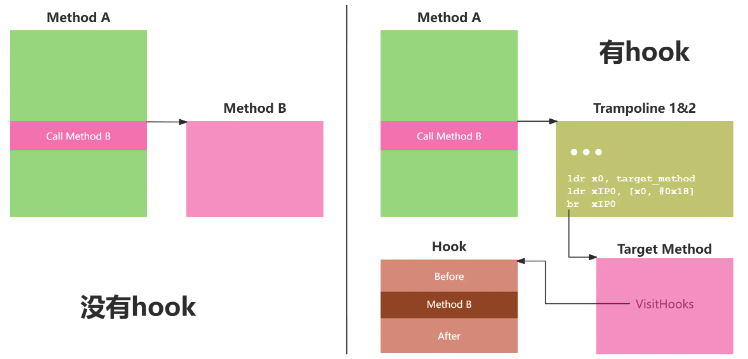
首先是Trampoline的设计。它的核心作用是将传入的参数转换为如下格式,然后调用Target Method。
(Object thisObject, Object[] args, long art_method)
thisObject和args是为了方便之后通过Method.invoke调用原方法逻辑的,而art_method则是为了找出调用方法对应的Hook信息的。这个转换过程有两个重要的问题需要考虑:
-
转换过程中,有些传递参数的寄存器会被使用,因此这些值需要提前找个地方存一下。 -
参数转换的过程中不能进行GC,否则会产生对象的移动或回收。由于转换过程拿到的是对象的原指针,移动或回收会导致原指针失效。
epic和pine在这两处的处理方法是类似的,不过尚有些改进的空间,所以我采取了一些不同的实现。
针对第一个问题,epic和pine在trampoline的尾部开辟了一块空间,用于存储可能被使用的寄存器的值。但这样需要为每个hook方法都生成一个独立的trampoline;且trampoline的运行过程需要加锁,用来防止多线程对尾部空间的并行访问,而这个加锁的动作甚至会产生一些死锁问题。
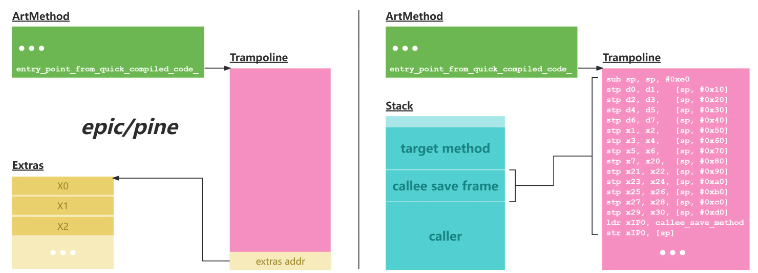
我选择将这些参数保存在栈上,这样既没有多线程的问题,也可以让所有的hook方法共用一个trampoline,从而节约内存资源。既然保存在栈上有这么多好处,那为什么之前的方案中没有这么设计?原因是栈上增加额外的空间会导致栈回溯无法工作,因为它改变了栈帧的大小。但其实ART自身也有栈上开辟空间的需求,它通常用于Java到runtime的切换过程。开辟出来的这块空间属于一个Runtime Method(非真实方法,具体类型为CalleeSaveMethod),它会参与栈回溯过程并处理好栈空间的计算,因此我们只需要按照CalleeSaveMethod的栈空间开辟格式进行压栈,就可以解决这个问题。
针对第二个问题,epic和pine并没有很好的解决,原因是它们的参数转换放到了一个Java方法中去进行,而Java方法的入口处会进行suspend check,是有可能被GC挂起来执行GC操作的。好在Android有@FastNative注解,它可以在没有线程状态切换的环境中进行native方法调用。没有线程状态切换,也就意味着没有suspend check。这样一来,只要我们将参数处理放到由@FastNative注解的JNI函数中,就可以避免在参数转换过程中发生GC。
但其实这里还有个更深入的问题:不是说参数会自动作为GC root吗?既然如此,GC还会对它进行移动或回收么?如果是GC root,自然不会。但问题的关键是,方法一旦被hook后,原方法在栈上的痕迹就会被抹去,转而由参数处理的那个方法替代。因此GC在判别哪些参数作为GC root时,是按照参数处理的那个方法去进行的,而不是原方法。这才导致作为原方法的参数不会被判定为GC root。
接着是Target Method的设计。它的核心作用是调用hook逻辑,同时保证返回参数类型的正确。
由于Target Method将直接返回到caller,所以它的返回值类型一定要和原方法一致。返回值类型有10种(void, int, long…),因此Target Method也有10个。那么Trampoline如何选择Target Method呢?这里有个小技巧,参数转换的JNI函数会通过方法的shorty字符串拿到返回值类型,它可以将这个类型存在栈上返回给Trampoline。之后,Trampoline便可以通过tbnz这样的条件跳转指令获取到匹配的Target Method。
最后是Hook的设计。其中最核心也最有难度的就是对原有逻辑的调用。
之所以称为“原有逻辑”而非“原有方法”,是因为“原有方法”的entry_point_from_quick_compiled_code_已经被修改。为了能够调用到原有逻辑,我们需要在修改entry_point_from_quick_compiled_code_之前对原有方法进行备份。epic和pine采用了同样的处理方式,它们在native层对ArtMethod进行了拷贝,然后让拷贝出来的ArtMethod关联上一个新创建的Executable对象。不过这种处理方式有一个缺陷,即拷贝之后的ArtMethod无法被GC感知到,因此GC对Class对象的移动也无法更新到ArtMethod中。所以它们在每次“原有逻辑”调用之前都需要手动更新ArtMethod的declaring_class_,但即便是手动更新,依然会留下导致崩溃的GC窗口。
所以问题的重点在于如何让拷贝的ArtMethod被GC感知到。一种可行的方案是为每一个hook方法都事先准备一个空的方法接收备份,但hook的方法越多,需要准备的方法也就越多,这显然不是一种优雅的方式。更无感的设计应该是动态生成代理类,它里面的方法就可以供我们来接收备份。这样一来,备份的ArtMethod里面的declaring_class_便会在GC时自动更新。
增强兼容性/稳定性的设计
说完主体的设计之后,再补充两个增强方案兼容性/稳定性的设计细节,它们分别是:
-
如何找到ART内部的对象? -
如何hook正在JIT的方法?
寻找ART的内部对象, 根源就是确定这些对象在所属类中的偏移。在现有的方案中,这些偏移基本都是依照每个版本的ART源码固定死的。所以它们缺乏一定的灵活性,同时兼容性也有短板。那有没有更加动态的方案?回到libart.so的视角,它里面的机器码(汇编)在运行时一定也需要找到这些对象,如果它可以找到,那我们根据这些汇编指令是不是也可以找到?
以如下代码为例。从代码逻辑可以推断,该函数第一步要做的就是GetClassLinker(),而GetClassLinker()获取的正是Runtime类里的class_linker_字段。
C++代码
ArtMethod* Runtime::CreateResolutionMethod() {
auto* method = CreateRuntimeMethod(GetClassLinker(), GetLinearAlloc());
...
}
ClassLinker* GetClassLinker() const {
return class_linker_;
}
编译后的汇编代码
0000000000813320 <art::Runtime::CreateResolutionMethod()>:
813320: d503233f paciasp
813324: a9bd7bfd stp x29, x30, [sp, #-0x30]!
813328: f9000bf5 str x21, [sp, #0x10]
81332c: a9024ff4 stp x20, x19, [sp, #0x20]
813330: 910003fd mov x29, sp
813334: d0001068 adrp x8, 0xa21000 <SAVE_SIZE+0xa20f50>
813338: aa0003f3 mov x19, x0
81333c: f941d108 ldr x8, [x8, #0x3a0]
813340: f9412c00 ldr x0, [x0, #0x258] //x0是this指针,也即Runtime*
从汇编代码可以看到,函数里第一个从x0中load的动作(813340处)就是获取class_linker_的动作,而load时的0x258这个偏移,也即class_linker_在Runtime类中的偏移。对于这种各个版本相对稳定且OEM不太去改的方法,就可以从它的汇编代码中抽取出我们想要的偏移。那有人会问,为什么不直接从GetClassLinker()方法中抽取,这样不是更直接?原因是这种函数体很小的方法基本都被inline了,我们找不到它独立的汇编。
另外关于ArtMethod里entry_point_from_quick_compiled_code_的偏移,这里也介绍一种方法。
我们可以通过Instrumentation::InitializeMethodsCode为一个方法指定入口,譬如art_quick_to_interpreter_bridge,接着再遍历ArtMethod的内部字段,当找到某个字段和art_quick_to_interpreter_bridge相同时,该字段便为entry_point_from_quick_compiled_code_。
Hook正在JIT的方法, 似乎不太可能,因为JIT编译完成后会再次修改ArtMethod的entry_point_from_quick_compiled_code_。
一种优雅的方式是为SetHook增加boolean返回值,告知调用方是否hook成功。当遇到JIT这种情况时,直接返回false,而不是等待JIT完成。至于是否重新发起hook,由调用方决定。因此,问题的关键变为如何判断hook是否成功?
运行过程中,每一个线程都可以触发JIT,但进行JIT编译的只有一个线程。所以这里需要有task queue来记录编译的任务。JIT编译有三种模式,分别为baseline、optimized和osr。
对于方法的替换而言,我们只关心baseline和optimized这两种。所以我们可以遍历这两种类型的task queue,如果其中包含我们正在hook的方法,则表明该方法等待被JIT编译,因此可以判定此次hook失败。否则我们可以hook成功。
至此,一个完整的基于ART的Java Hook方案便被设计出来。
这个设计考虑了GC、JIT、WalkStack及各种优化可能对Hook方案产生的影响,最大程度地去保证了稳定性和兼容性,同时尽可能少地更改运行机制,做到性能和内存的最小牺牲。但它仍然具有缺陷。首先是我个人的理解一定会有短板和盲区,其次是现有的方案有一个问题无法解决:JIT/AOT编译过程中被inline的方法无法被hook。Deoptimize方法的caller或许可以,但由于深度inline(inline了好几层)和caller众多等问题的存在,这显然不是一个合适的解决方案。所以这个问题,我目前也没有更好的想法。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/78904.html