
继前面的爬虫记,进行了静态页面的信息爬取后,我们来更进一步,了解一下动态渲染等技术。
一、一些网站基础知识
对于网站,我们最基础的,就是静态资源,比如一些个文本展示,以前大学的时候就试过,老师叫我们进行过个人简历的一个展示(通过网站资源挂载从而进行展示)。比如我们可以使用python中的web框架或者简单的nginx进行一个这样的实现。
1.1 网站静态资源
首先准备一个test.txt和nginx.conf(nginx的配置文件):
阿巴阿巴,测试user nginx;worker_processes auto;error_log /var/log/nginx/error.log notice;pid /var/run/nginx.pid;events {worker_connections 1024;}http {server {listen *:80;location / {root /usr/share/nginx/html ;autoindex on; # 如果你想列出目录下的所有文件}# 其他配置...}# 其他 server 或 http 全局配置...}
然后启动这个nginx就好:
$ docker run -d -p 8888:80 --name nginx-test -v ~/本地文件夹/nginx.conf:/etc/nginx/nginx.conf -v ~/本地文件夹:/usr/share/nginx/html nginx$ curl http://localhost:8888/test.txt阿巴阿巴,测试
如上,就能进行一个简单的静态资源的挂载和查看,比较简单,另外,常见的html文件也是静态资源,不过它们一般是这样的:
<!DOCTYPE html><html><head><title>Welcome to nginx!</title><style>html { color-scheme: light dark; }body { width: 35em; margin: 0 auto;font-family: Tahoma, Verdana, Arial, sans-serif; }</style></head><body><h1>Welcome to nginx!</h1><p>If you see this page, the nginx web server is successfully installed andworking. Further configuration is required.</p><p>For online documentation and support please refer to<a href="http://nginx.org/">nginx.org</a>.<br/>Commercial support is available at<a href="http://nginx.com/">nginx.com</a>.</p><p><em>Thank you for using nginx.</em></p></body></html>
这种文件用浏览器打开,就是我们常见的文本格式了:
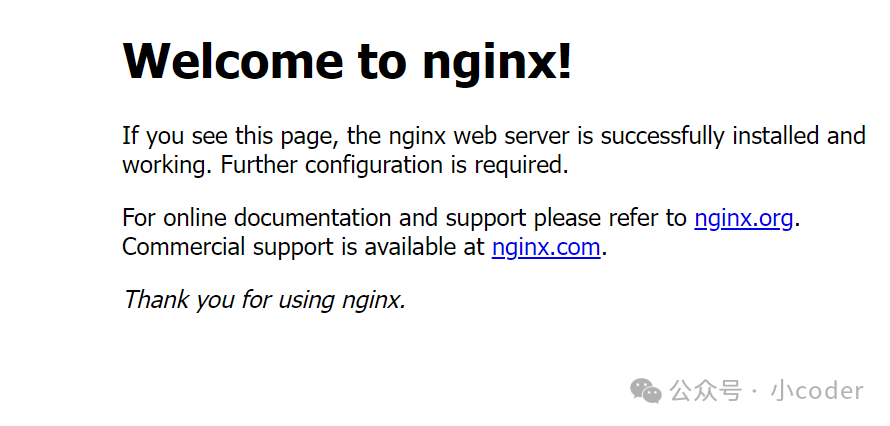
我们甚至可以把图片这些个都用上面txt文件的方式进行挂载从而让外界访问,这个就是所谓的静态资源,包括上面的html文件。但一个网站,静态页面往往是不够的,还需要一些个动态的交互,这种的实现就需要使用到js技术了。
1.2 动态网页
有一些页面并不像小说网站那种静态页面那样,这里所说的动态页面往往是需要后面的js渲染的,比如一些个视频网站页面,这种页面的爬取得到的html文本有比较大的区别。如下一个视频页面:
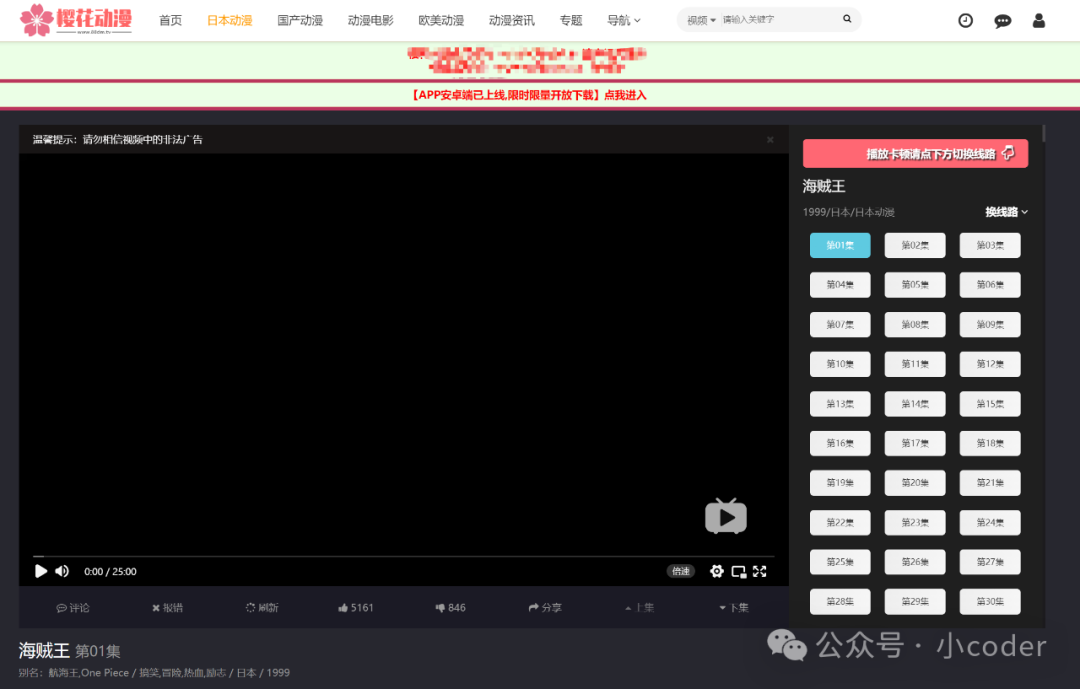
当我们使用简单的requests进行爬取,然后保存:
import requestsurl = 'http://balabalexample.com/'resp = requests.get(url)resp.raise_for_status()with open('res.html', 'wb') as f:f.write(resp.content)
如上得到的res.html断网后打开(因为对应的js脚本会在打开html文件的时候自动引入,所以断开网络以突出区别),是这样的:
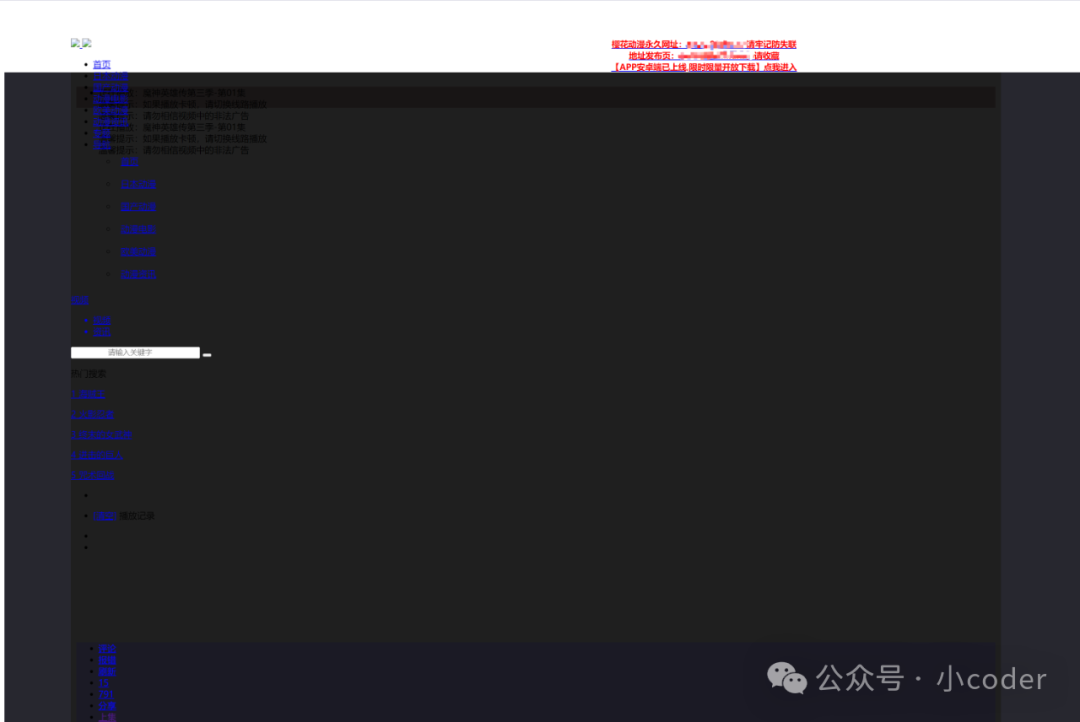
因为js渲染是在初次http请求后,继续向服务器或者其他仓库请求js脚本,也就是二次请求后才在浏览器最终加载完成的页面。面对这种二次请求,显然requests进行的一次请求是不够的,requests只是模拟http一次请求,更多还是要靠coder自定义,所以就需要一个模拟浏览器行为来进行这种特殊的爬取。
二、爬取动态页面
针对上面这种情况,我们可以使用selenium库来实现浏览器行为的模拟,从而爬取动态页面的信息:
pip install selenium这里需要交代一下版本关系,我这里使用的是python3.12.3,用的是windows系统,而且对应的selenium是4.21.0版本。如果下载失败,可能要考虑下更换一下镜像源,或者有4版本之前的下载的话,就需要针对一些浏览器驱动的下载,比如:谷歌浏览器驱动的下载安装
但是这种固定式的也挺麻烦的,要下载驱动来对上,而且国内进行谷歌的一些个浏览器驱动下载还是挺麻烦的,这里找了个好用的库来解决这个依赖问题,让这个环节能灵活一点。
pip install webdriver-manager使用这个第三方库可以针对这些进行浏览器驱动进行管理,挺方便的。如下展示Chrome的驱动简单使用:
from selenium import webdriverfrom selenium.webdriver.chrome.service import Service as ChromeServicefrom webdriver_manager.chrome import ChromeDriverManagerchrome_driver = webdriver.Chrome(service = ChromeService(ChromeDriverManager().install()))
如下为IE对应使用:
from selenium import webdriverfrom selenium.webdriver.ie.service import Service as IeServicefrom webdriver_manager.microsoft import IeDriverManagerie_driver = webdriver.Ie(service = IeService(IeDriverManager().install()))
如上使用,会弹出一个浏览器窗口,但在我们的日常信息爬取的过程中,往往并不需要这样一个窗口,我们只有在调试的时候看看是否符合预设就够了。需要注意的是,上面使用的install是实际进行了下载安装的动作的,后面就不需要了,可以直接调度的,如browser = webdriver.Chrome()。所以我们的日常使用应当是经常使用ChromeOptions来进行这个浏览器的一个自定义,比如:
from selenium import webdriverfrom selenium.webdriver import ChromeOptionsoption = ChromeOptions()option.add_argument('--headless')browser = webdriver.Chrome(options=option)browser.set_window_size(1366, 768)browser.get('https://www.baidu.com')browser.get_screenshot_as_file('preview.png')
如上进行,执行脚本可以获得百度搜索页面的主页图片,有意思的是,这玩意儿它夹带私货(-__*),输出如下:
"这是一个最好的时代,科技的发展给予了每个人创造价值的可能性;这也是一个最充满想象的时代,每一位心怀梦想的人,终会奔向星辰大海。百度与你们一起仰望星辰大海,携手共筑未来!", source: https://pss.bdstatic.com/r/www/cache/static/protocol/https/global/js/all_async_search_0702397.js (265)[0528/162111.332:INFO:CONSOLE(265)] "%c百度2023校园招聘简历投递:https://talent.baidu.com/jobs/list color:red", source: https://pss.bdstatic.com/r/www/cache/static/protocol/https/global/js/all_async_search_0702397.js (265)
这玩意儿。。。。。。
三、拓展一下selenium使用
使用selenium,我们除了可以加载动态页面,从而得到加载完成后的页面资源,还可以实现一系列模拟人类的动作,比如进行也页面内搜索这类动作。
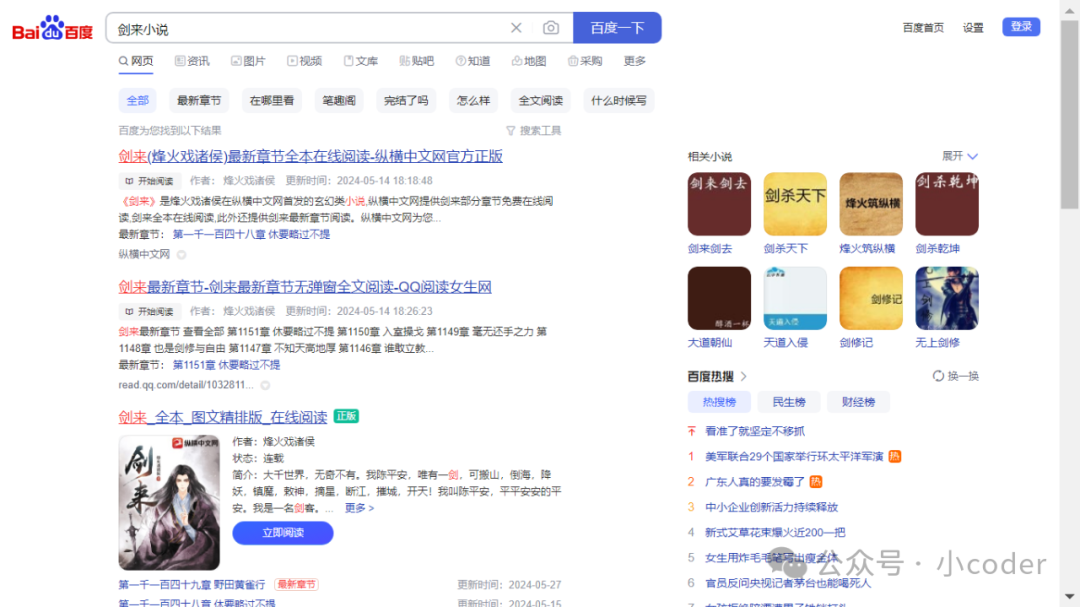
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver import ChromeOptionsfrom time import sleepoption = ChromeOptions()option.add_argument('--headless')browser = webdriver.Chrome(options=option)browser.set_window_size(1366, 768)browser.get('https://www.baidu.com')input = browser.find_element(By.ID, 'kw')input.send_keys('剑来小说')sleep(1)button = browser.find_element(By.ID, 'su')button.click()sleep(1)browser.get_screenshot_as_file('preview.png')
很多旧版的元素查找是直接使用find_element_by_id这种函数,但较新的版本是直接find_element函数,然后通过By.ID或者By.CLASS_NAME来进行对应功能调用。上面执行完以后,不就是我最喜欢的陈平安传记了嘛:
比如:
from selenium.webdriver import ActionChains...source = browser.find_element(By.CSS_SELECTOR, '#draggable')to_drag = browser.find_element(By.CSS_SELECTOR, '#droppable')actions = ActionChains(browser)actions.drag_and_drop(source, to_drag)actions.perform()
如上,可以把目标元素进行拖动,拖动到制定位置,我们可以用这个实现一些个网站的登录验证中的拖动操作。
执行js
一些熟悉前端的同学,他们会有js执行的需要,比如我们想要页面下拉到底。这类操作在一些个测试中,非常常见,比如针对某些数据页面,想要保存一下页面数据,拿一张截图,但如果页面过长,我们就需要进行滚动页面。
...browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
如上进行js的执行,可以直接拖动页面到达底部。
一些必要的等待
针对页面的加载,有时候不会马上就绪,有可能会有比较久的一个加载,而我们的处理过快导致没有理想的效果,这种时候就需要进行一个等待,但如果使用time.sleep(x)又好像太粗暴了,所以我们用它自己的等待函数:
简单的等待
这里都被叫做隐式等待,也就是当目前没有这个节点的时候就进行等待,当预设等待时间已过,还没有加载出该节点元素,那就抛出找不到节点的异常。如下:
...browser = webdriver.Chrome()browser.implicitly_wait(8)...
如上使用implicitly_wait进行等待操作。
针对特定节点的等待
前面的是漫无目的的等待,现在这种是有针对性的:
...from selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome()browser.get(url)wait = WebDriverWait(browser, 10)target = wait.until(EC.presence_of_element_located(By.ID, 'abaaba'))button = wait.until(EC.element_to_be_clickable(By.CLASS_NAME, 'bilibili'))browser.get_screenshot_as_file('preview.png')
一些个特定的条件等待函数:
| 函数 | 含义 |
|---|---|
| title_is | 标题是xxx |
| title_contains | 标题包含xxx |
| visibility_of | 节点可见 |
| element_attribute_to_include | 节点属性包含xxx |
| element_located_to_be_selecte | 节点可以进行选择,传入的是定位元祖 |
| element_selection_state_to_be | 节点状态对应xxx |
| element_to_be_clickable | 节点元素可点击 |
| element_to_be_selected | 节点可选,传入的是节点对象 |
| presence_of_all_elements_located | 全部节点加载出来 |
如上是一些简单的条件,但还有很多,实在懒得整上去了。
异常处理
进行作业的时候,我们常常会碰到各种异常,单个脚本的时候,可以慢慢调试,但目标非常多的时候,我们应该适当忽略一下,针对一些个节点找不到的情况,我们可以进行异常捕获:
>>> import selenium.common.exceptions as e>>> dir(e)['ERROR_URL', 'ElementClickInterceptedException', 'ElementNotInteractableException', 'ElementNotSelectableException', 'ElementNotVisibleException', 'ImeActivationFailedException', 'ImeNotAvailableException', 'InsecureCertificateException', 'InvalidArgumentException', 'InvalidCookieDomainException', 'InvalidCoordinatesException', 'InvalidElementStateException', 'InvalidSelectorException', 'InvalidSessionIdException', 'InvalidSwitchToTargetException', 'JavascriptException', 'MoveTargetOutOfBoundsException', 'NoAlertPresentException', 'NoSuchAttributeException', 'NoSuchCookieException', 'NoSuchDriverException', 'NoSuchElementException', 'NoSuchFrameException', 'NoSuchShadowRootException','NoSuchWindowException', 'Optional', 'SUPPORT_MSG', 'ScreenshotException', 'Sequence', 'SessionNotCreatedException', 'StaleElementReferenceException', 'TimeoutException', 'UnableToSetCookieException', 'UnexpectedAlertPresentException', 'UnexpectedTagNameException', 'UnknownMethodException', 'WebDriverException', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']>>>
如上,能捕捉的异常非常多,不过我们常用的应该就是超时(TimeoutException)和节点找不到(NoSuchElementException)。
针对selenium的屏蔽
因为selenium的使用非常便利,很多网站都出台针对selenium的一个检测和屏蔽,这种时候我们需要关注当前浏览器窗口的window.navigator对象的webdriver属性。
正常浏览器,webdriver属性为undefined,而selenium则是会设置webdriver属性有值。
根据这个特性,我们需要设置webdriver属性为空,在爬取特定网站的时候,要注意这一点。想要在selenium进行请求之前,就进行预设置:
from selenium.webdriver import ChromeOptionsoption = ChromeOptions()option.add_experimental_option('excludeSwitches', ['enable-automation'])option.add_experimental_option('useAutomationExtension', False)browser = webdriver.Chrome(options=option)browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})
上面的execute_cdp_cmd中的CDP,是chrome开发工具协议的意思,这里的使用,是执行Page.addScriptToEvaluateOnNewDocument方法,执行设定webdriver属性为undefined的js。
重申一句,爬取资源千万别爬取私密资源,尊重专利拥有,别爬太快从而挂了别人的服务器。要注意我们是面向兴趣编程、面向就业编程,而不是面向缝纫机编程(手动doge)
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/78985.html