
1.2 有监督数据压缩方法-线性判别分析方法
1.2.1 基本原理
线性判别分析方法(LDA)与PCA算法的原理非常类似,主要区别在于PCA是无监督方法,LDA是有监督方法,很适合用于分类任务中。
其基本原理是:
1. 标准化d维数据集;
2. 计算每个类别数据的d维均值向量;
3. 构造类间散布矩阵Sb,和类内散布矩阵Sw;
4. 计算矩阵Sb和Sw的逆矩阵Sw_inv的特征值和对应的特征向量;
5. 特征向量按其相应特征值降序的方式进行排序;
6. 选择与k个最大特征值对应的特征向量,使用这些特征向量作为变换矩阵的列,构造一个dXk的变换矩阵W;
7. 使用变换矩阵W将样本投影到新的特征子空间中。
1.2.2 sklearn中的LDA
书中还使用了和PCA相同的演示方式,手推一遍再用sklearn实现一遍。这里跳过手推过程,直接使用sklearn实现,毕竟能用现成的就别自己写了。使用的数据集还是之前葡萄酒数据:
# 导入LDA类,因为名字太长了,给他简称LDAfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA# 初始化LDA并设置特征向量为2个lda = LDA(n_components=2)# 训练LDA模型X_train_lda = lda.fit_transform(X_train_std, y_train)
# 导入逻辑回归from sklearn.linear_model import LogisticRegression# 初始化逻辑回归模型lr = LogisticRegression(multi_class='ovr', random_state=1, solver='lbfgs')# 训练模型lr = lr.fit(X_train_lda, y_train)# 画出决策区域plot_decision_regions(X_train_lda, y_train, classifier=lr)plt.xlabel('LD 1')plt.ylabel('LD 2')plt.legend(loc='lower left')plt.tight_layout()plt.show()
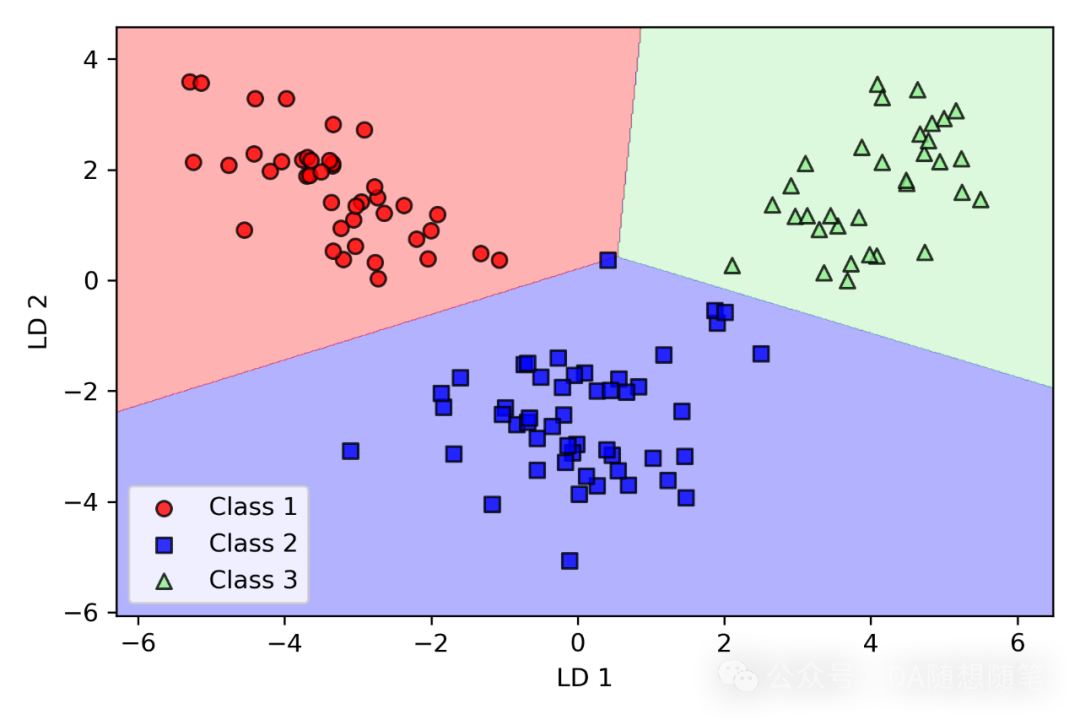
# 在测试集上使用LDA并画出决策区域X_test_lda = lda.transform(X_test_std)plot_decision_regions(X_test_lda, y_test, classifier=lr)plt.xlabel('LD 1')plt.ylabel('LD 2')plt.legend(loc='lower left')plt.tight_layout()plt.show()

以上,非常简单得介绍了一下LDA降维方法,如果任务是有标签的分类任务,可以优先考虑使用这个方法进行降维。
1.3 非线性降维和可视化
之前介绍的PCA和LDA都是属于线性变换的方法,这一部分要介绍的t分布随机邻域嵌入(t-SNE)属于非线性降维方法。常用于在二维或三维空间可视化高维数据。这一节书中介绍了使用t-SNE可视化手写字数据集。
1.3.1 非线性降维的不足
机器学习中,大部分算法假设输入数据是线性可分的。比如感知机,要求输入数据是完全线性可分的才能收敛。其他如逻辑回归、支持向量机等都假设数据存在噪音,不要求完全线性可分。
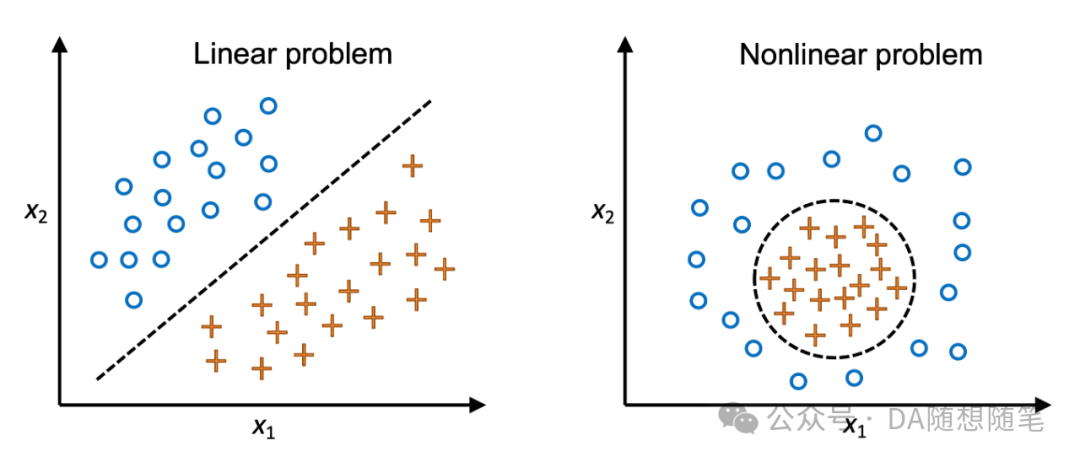
但是当数据是完全非线性的,在应用中会遇到各种奇奇怪怪的问题。当遇到非线性数据集的时候,PCA和LDA等线性降维方法都不是很好的选择。下图展示了线性和非线性问题的区别。
Scikit-learn中有一些高级的非线性降维方法,可以查看官方文档(http://scikit-learn.org/stable/modules/manifold.html )书中也表达了一下,虽然这些算法能强,但是难用,尤其是当超参数选择不理想的时候,可能弊大于利。所以书中也没做具体介绍,降维的时候主要还是使用简单方法,比如PCA和LDA。
1.3.2 t-SNE可视化数据
书中介绍了使用t-SNE算法将复杂数据进行二维或三维可视化的例子。它的原理是对原始高维特征空间中的数据点之间的距离进行建模,然后在低维子空间中寻找与原始高维空间中类似的距离概率分布。即在保持原始空间中的数据之间距离的前提下,将高维数据嵌入到低维空间中。
书中用了一个python自带的手写数字图片数据集来做举例。每个手写数字的图片都是8×8的灰度图像,共1797张图像,书中通过t-SNE将64维的图片数据压缩到二维空间中:
# 导入这个图片数据集from sklearn.datasets import load_digitsdigits = load_digits()# 显示前四张图片看看fig, ax = plt.subplots(1, 4)for i in range(4):ax[i].imshow(digits.images[i], cmap='Greys')plt.show()

# 查看数据集的样本数和维度digits.data.shape
# 将标签和特征分别赋值y_digits = digits.targetX_digits = digits.data
# 导入t-SNE算法from sklearn.manifold import TSNE# 初始化算法,设置降维到2维,设置使用pca方法初始化嵌入tsne = TSNE(n_components=2,init='pca',random_state=123)# 使用t-SNE算法进行降维X_digits_tsne = tsne.fit_transform(X_digits)
# 把降维后的数据分布可视化出来import matplotlib.patheffects as PathEffectsdef plot_projection(x, colors):f = plt.figure(figsize=(8, 8))ax = plt.subplot(aspect='equal')for i in range(10):plt.scatter(x[colors == i, 0],x[colors == i, 1])for i in range(10):xtext, ytext = np.median(x[colors == i, :], axis=0)txt = ax.text(xtext, ytext, str(i), fontsize=24)txt.set_path_effects([PathEffects.Stroke(linewidth=5, foreground="w"),PathEffects.Normal()])plot_projection(X_digits_tsne, y_digits)plt.show()

通过上图可以看出,t-SNE能有效识别出不同的数字,当然也有很多没正确识别的,在这样的非线性数据集上还是比PCA等好用的。
但是我个人觉得,比起深度学习来说,其能力还是有局限性,因此如果算力能支持,可以考虑使用深度学习方法来处理非线性数据集。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/78998.html