
许多文章告诉你Python技巧,但很少告诉你为什么这样做,在网上随便搜索一下,很容易找到关于Python技巧的文章。
它们要么使代码更“Pythonic”,要么让我们的程序更快。
大多数技巧都相当有用,但是他们没有解释这些技巧应该适用于什么场景,对我们来说我们应该明白什么时候使用它们以及什么时候不使用它们。
在本文中,我们将讨论三个python技术,并详细解释其背后的机制。
你通常如何连接字符串?
例如,假设我们有一个字符串列表需要连接在一起。
strs = ['Life', 'is', 'short,', 'I', 'use', 'Python']
当然,最直观的方法是遍历列表并使用 + 运算符连接所有子字符串并加上空格。
def join_strs(strs):
result = ''
for s in strs:
result += ' ' + s
return result[1:]
join_strs(strs)

在上面的代码中,我们简单地定义了一个空字符串,并不断将一个空格和列表中的一个子字符串追加到这个字符串中。
最后,我们返回从第二个字符开始的结果字符串,以便去掉前导空格。
然而,在这种情况下,我们有一个更好的方法来实现它,那就是使用 join() 函数,如下所示。
def join_strs_better(strs):
return ' '.join(strs)
join_strs_better(strs)

这不仅更易读,而且更快,可以看看性能比较。

为什么使用 join() 函数会更快?
首先,让我们看看使用 for 循环和 + 运算符的方法的步骤。
-
对于每次循环,在列表中找到字符串
-
Python 执行器解释表达式 result += ‘ ‘ + s 并为空格 ‘ ‘ 申请内存地址。
-
然后,执行器意识到空格需要与字符串连接,因此它会为字符串 s 申请内存地址,对于第一次循环来说是“Life”。
-
对于每次循环,执行器需要申请两次内存地址,一次用于空格,另一次用于字符串
-
总共有12次内存分配
让我们看看使用 join() 函数的方法的步骤。
-
执行器将计算列表中有多少个字符串。一共有6个。
-
这意味着用于连接列表中字符串的字符串需要重复6-1=5次。
-
它知道总共需要11个内存空间,因此所有这些空间将一次性申请并预先分配。
-
按顺序放置字符串,并返回结果。
很明显,主要的区别在于内存分配次数,这是性能提升的主要原因。
一些额外的备注
不建议大家在所有字符串连接的场景中都使用join() 函数。
假设我们只是在数据分析脚本中连接两个字符串,可以简单地使用 my_str = “A” + “B”,这实际上更易读。
从性能角度来看,这也没有多大价值,除非我们需要连接成千上万次字符串。
此外,如果你的子字符串不在一个集合中,不要仅仅为了使用 join() 函数而创建一个列表。
实际上,初始化一个列表的开销远大于使用 join() 函数带来的好处。
在Python中,列表无疑是最常用的数据结构,因为它具有灵活性。
然而,创建一个空列表并非只有一种方法。
有些人认为使用 list() 更具可读性,而使用字面量 [] 只是盲目追求所谓的“Pythonic”。
事实上,这两种创建列表的方法机制不同,而后者更快。
my_list_1 = list()
my_list_2 = []

为什么使用字面量更快?
它们为何不同?我们可以利用内置模块 dis 将它们拆解成字节码
from dis import dis
dis("[]")
dis("list()")
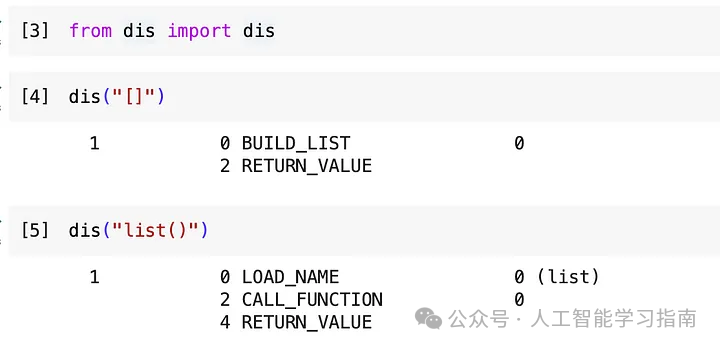
当我们使用 [] 时,字节码显示只有两个步骤。
-
BUILD_LIST —— 顾名思义,构建一个Python列表
-
RETURN_VALUE —— 返回值
非常简单,对吧?当Python解释器看到表达式 [] 时,它只知道需要构建一个列表。因此,这是非常直接的。
那么 list() 呢?
-
LOAD_NAME —— 尝试找到对象“list”
-
CALL_FUNCTION —— 调用“list”函数以构建Python列表
-
RETURN_VALUE —— 返回值
每次我们使用一个带名称的东西,Python解释器都会在现有变量中搜索这个名称。
搜索顺序是局部作用域 -> 闭包作用域 -> 全局作用域 -> 内置作用域。
这个搜索确实需要一些时间,并且在很大程度上影响了性能。
如前所述,列表在Python中非常常用。
但是大家考虑过我们是否应该使用其他东西?
我们知道Python列表对其项有顺序,但如果顺序不重要呢?
例如,有时我们只需要一个“容器”来存放某些东西,Python集合(Set)就能满足我们的所有需求。
在这种情况下,集合的性能将远远优于列表。
让我们定义一个具有完全相同值的列表和集合。
my_list = list(range(100))
my_set = set(range(100))
因此,它们都包含从0到99的100个整数,唯一的区别是数据结构类型。
现在,假设我们想检查容器中是否有数字“99”,并比较性能。
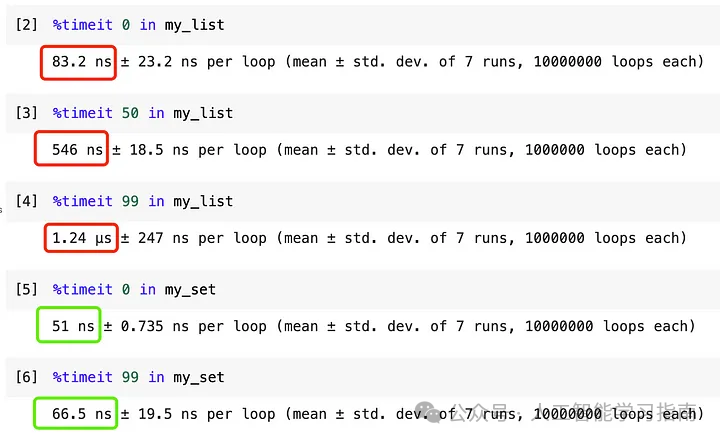
可以看出,列表的性能取决于它需要扫描的距离。
在上述示例中,如果我们测试列表中是否有“0”,性能大约与集合相同。
如果我们测试位于中间的“50”,性能会变差。如果我们测试最后一个元素,性能会比其他任何情况都慢得多。
另一方面,集合的性能趋于稳定,无论我们测试哪个数字,性能都不会改变。
为什么集合的性能优于列表?
简短的回答是,列表和集合的数据结构完全不同。Python集合使用哈希表实现,而Python列表是典型的数组。
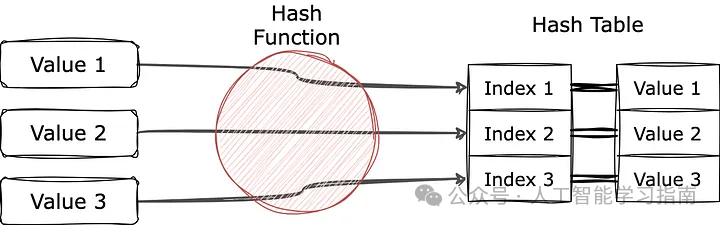
哈希表是什么样的?通常,值将被输入到一个哈希函数中,这个哈希函数将原始值转换为另一个值,这个值将用作哈希表的索引。
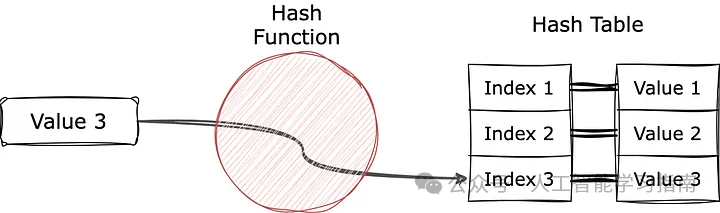
当我们试图找到一个值时,它将再次被输入到函数中。因此,我们直接获得索引,并将其用于立即从哈希表中获取相应的值。

现在,让我们看看Python列表,它是一种数组类型的数据结构。列表中的项以固定顺序链接在一起。

当我们寻找某个值时,它必须从列表的开头开始,并检查每一项,直到找到目标项(或到达末尾未匹配)。
但是幸运的情况是第一个项正是我们要找的,结果会立即返回。
最糟糕的情况是我们要找的项是最后一个,这也解释了为什么在尝试查找列表中的0、50和99时,性能有所不同。
在本文中,我们解释了三个流行的Python技巧,并解释了其背后的原因。
它为什么有效以及为什么性能更好,这也将帮助我们决定何时使用这些技巧以及何时不需要使用它们。

原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/79262.html