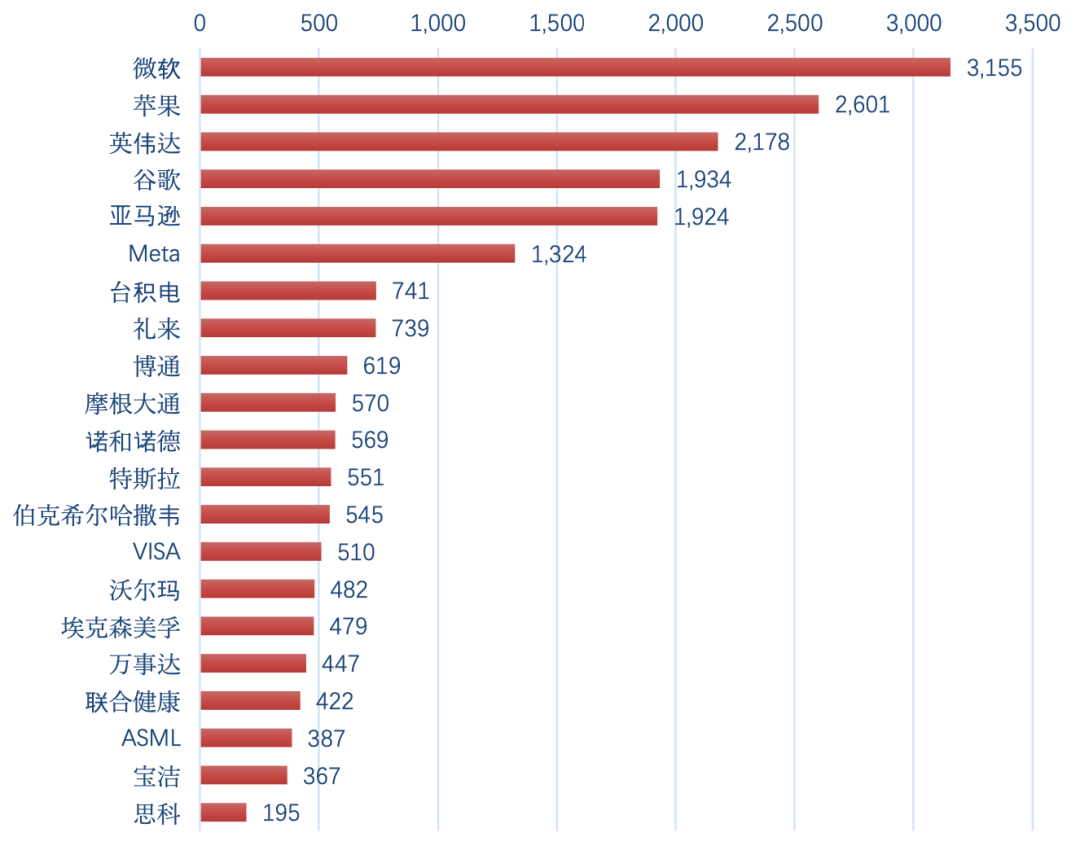
-
以LLM为代表的AI技术,对算力的庞大需求是否会延续? -
在AI运算中,短期内是否会出现比GPU更加高效的芯片? -
英伟达在当前生态中,是否可以被替代?

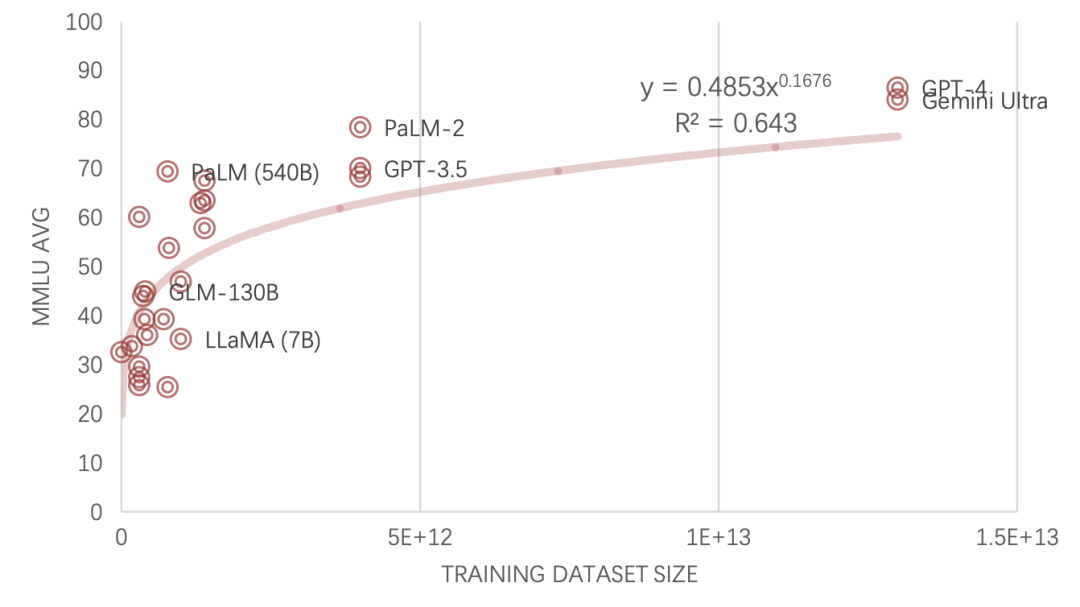
大语言模型:
昙花一现,还是变革前夜?
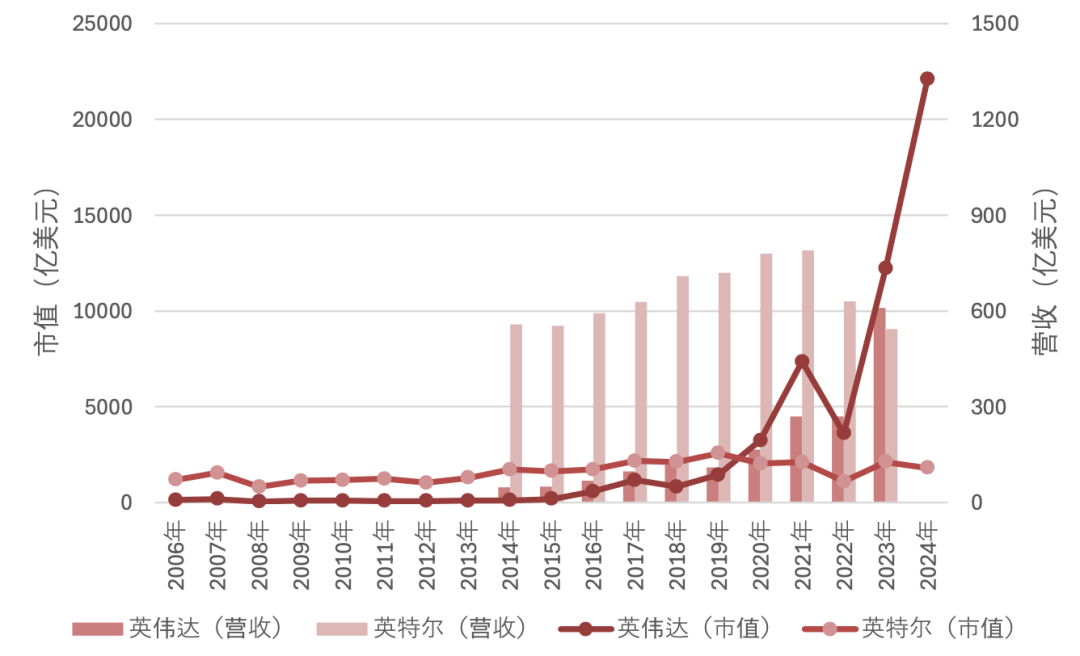
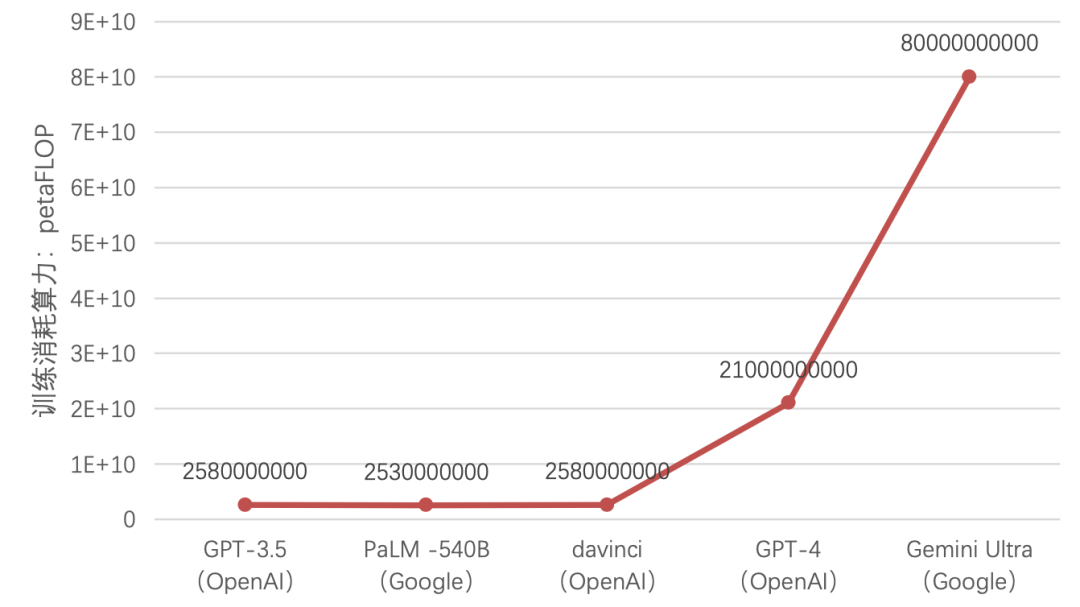
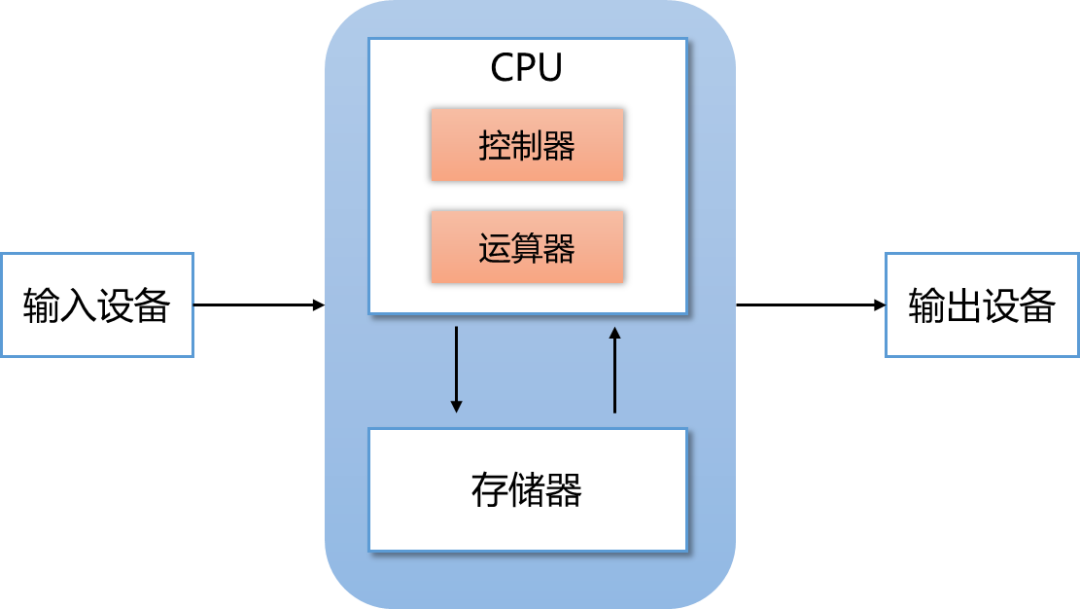
CPU:昔日王者,
为何失位AI时代?
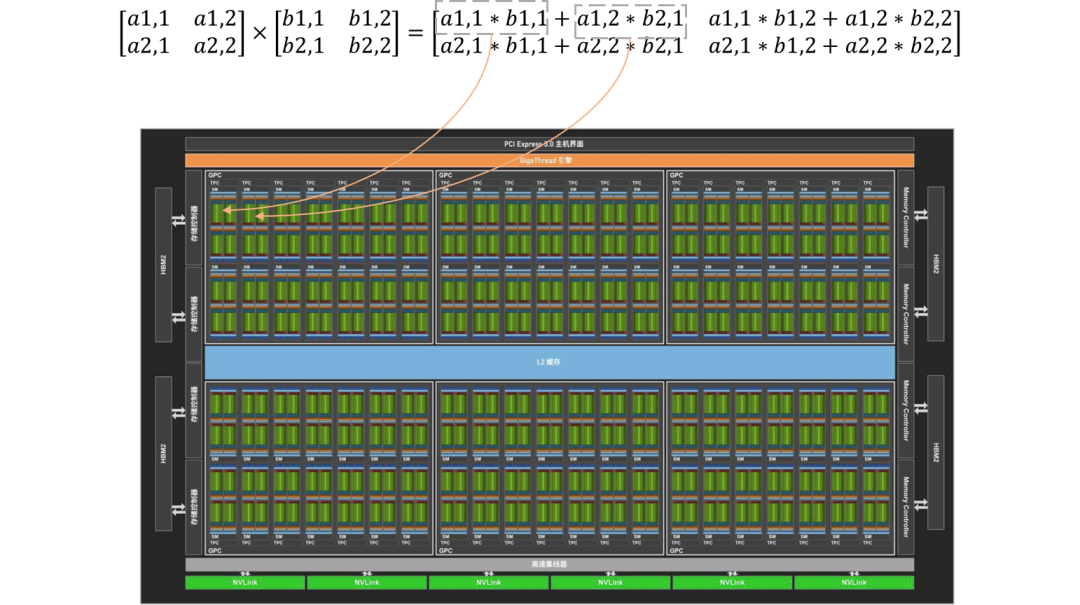
GPU新王登基:
游戏中诞生的生产力


异构计算崛起,
英伟达还能辉煌多久?
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/79376.html

大语言模型:
CPU:昔日王者,
GPU新王登基:
异构计算崛起,
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/79376.html
渲染是做效果图很重要的一个步骤,如果要渲染出一张高质量的效果图就需要花费大量的时间,一般一张全景图渲染时长需要2-8小时,如果用自己的电脑渲图的话这段时间内就没
「请问什么是5W2H?」创作不易,点赞收藏+关注就是最大的动力[送心]5W2H法第一次出现于第二世界大战中美国陆军兵器修理部。其简单、方便,易于理解、实用,富有
在信息技术飞速发展的今天,云服务器行业备受关注。在众多的云服务器产品中,虚拟机无疑是最受欢迎的。那么,你知道什么是虚拟机吗?它的特点和好处是什么?常见的虚拟机软件有哪些?如果你想了…
云服务器行业近年来发展迅速,越来越多的企业都开始选择使用云服务器来存储和管理数据。然而,面对众多的CS服务器出租服务商,如何选择合适的服务商却成为了一个令人头疼的问题。今天,我们就…
