
1 发展历史
1943年,Warren McCulloch和Walter Pitts发表论文《A Logical Calculus of the Ideas Immanent in Nervous Activity》,首次提出神经元的M-P模型。
1958 年,在康奈尔航空实验室工作的Frank Rosenblatt 发明了一种称为感知器的人工神经网络。这可以看作是最简单形式的前馈神经网络。
1969年,Marvin Minsky和Seymour Papert出版了《:010》一书,从数学角度论证了单层神经网络的局限性,并指出神经网络在面对简单的“异或”逻辑问题时的无效性。由于这篇论文的发表,神经网络研究进入了历史上被称为“明斯基神经网络冰川”的停滞期。
1974年,Paul Werbos在哈佛大学攻读博士学位期间,在博士论文中发明了著名且广泛传播的BP神经网络学习算法,但并没有引起太多关注。
1986 年,当David E. Rumelhart、Geoffrey E. Hinton 和Ronald J. Williams 发表论文《Perceptrons: an introduction to computational geometry》 重申该技术时,BP 神经网络学习算法引起了人们的关注。
自此,反向传播算法正式成型,历史的车轮慢慢开始转动,神经网络和深度学习的密集研究和应用也慢慢开始起飞。
(你知道反向传播算法有多难、有多神奇吗?)
2 基本定义
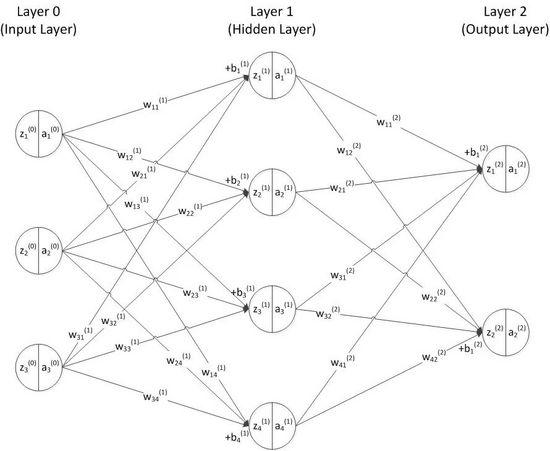
图2.1 神经网络
图2.1 是一个两层神经网络的例子。
第0层为输入层,最后一层为输出层,隐藏层也称为隐藏层。
神经网络的层数是从隐藏层开始计算的,总层数不包括输入层。
z表示每个神经元的输入信号,上标(l)表示该神经元位于神经网络的第l层,下标i表示该层的第i个神经元。
经过z 向量化后,它看起来像这样(假设神经网络的第l 层有k 个神经元):
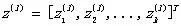
a表示每个神经元的输出信号,上标(l)表示该神经元位于神经网络的第l层,下标i表示该层的第i个神经元。
向量化后,a变为(假设第l层神经网络有k个神经元):
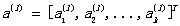
w 表示上一层神经元到下一层神经元的权重,上标(l)表示第l-1 层神经元到第l 层神经元的权重,下标i j 表示上一层的第i个神经元,表示该神经元到下一层的第j个神经元的权重。
向量化后,w为(假设第l-1层神经网络有k个神经元,第l层神经网络有q个神经元)。

b表示每个神经元输入信号的偏置值,也称为偏置项或偏置单元。上标(l)和下标i表示该偏差属于第l层第i个神经元。神经网络:
向量化后,b为(假设神经网络第l层有k个神经元):

注意:如果您是第一次阅读本文,请先跳过“矢量化”内容。
3 前向传播
前向传播是将样本数据输入到神经网络模型中,通过神经网络进行计算,最终输出预测值的过程。
每个神经元的输入信号z由参数w、b和上一层的输出信号a确定(假设第l层神经网络有k个神经元)。
矢量化后:
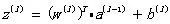
每个神经元的输出信号z由同一神经元的激活函数和输入信号a决定(为了方便起见,本文在整个神经网络中使用相同的激活函数。然而,在实际应用中,隐藏层和输出层激活函数通常不同):
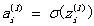
矢量化后:
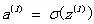
我们将以图3.1 为例进行说明。
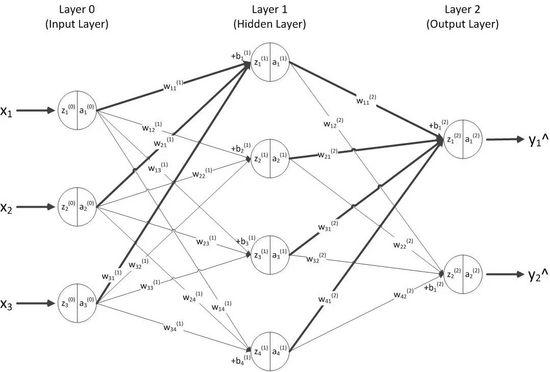
图3.1 前向传播模型
样本数据是(x,y)。其中,x=(x1,x2,x3),x的维度为3维,y=(y1,y2),y的维度为2维。
神经网络的输入层数据z0为:
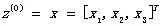
神经网络输出层的预测值y^为:
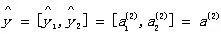
特定神经元节点的输入信号:
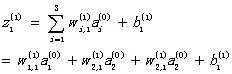
特定神经元节点的输出信号:
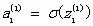
神经网络预测的损失/成本函数为:
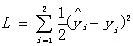
注1:损失函数LossFunction、误差函数ErrorFunction、成本函数CostFunction,它们的缩写L、E、C代表同一函数。
注2:损失函数的系数1/2是为了使函数求导的系数为1,是为了计算方便而设置的,没有实际意义。
4 反向传播
4.1 算法概念
为了获得高质量的神经网络模型,我们需要找到模型的两个参数w和b的最优值,以达到最小化损失函数值的目标。
显然,对于这个L优化问题,我们可以考虑使用偏导数的方法,利用梯度下降逐步逼近参数w和b的最优解。
然而,由于神经网络结构复杂、参数数量众多,传统的偏微分方法和梯度下降方法无法直接使用。直到反向传播算法的出现,神经网络模型求解最优参数的效率大大提高,神经网络实现了从理论到工业应用的飞跃,神经网络的学习和使用呈爆炸式增长。
反向传播算法:首先,使用损失函数求出模型的最终误差。然后将误差从后向前传递到每一层,得到每个神经元的误差。最后,对w和b求偏导数,推导出各层各神经元的误差,迭代得到w和b的最优解,构建损失函数最小的最优神经网络模型。当然,与梯度下降一样,神经网络需要多次迭代才能逼近并获得最佳模型。
注意:反向传播算法通过两种方式提高计算效率。一是计算过程的矢量化,二是能够实现分布式计算。
4.2 求误差
如下定义任意神经元的误差。
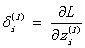
注1:这个误差完全是人为定义的;求误差的目的是用它求损失函数关于参数w和b的偏导数。您还可以将误差定义为神经元输出信号的损失函数的偏导数。
注2:虽然这个错误是人为定义的,但这个想法一直是可靠的,并且在机器学习领域得到广泛应用。例如,XGB 和LGB 残差也可以与超参数方法一起使用。
然后,对于神经网络的最后一层(L层),我们可以获得整个神经网络的第一组误差。
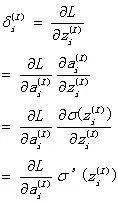
执行向量化并将其记录为表达式BP1。
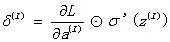
其中,右侧公式采用Hadamard积。这意味着将两个具有相同结构的矩阵相同位置的值相乘。
这样我们就得到了神经网络最后一层的误差。
接下来,为了向前传播误差层,我们需要找到具有l 层和l-1 层的两层神经网络的两个相邻层的误差之间的关系。
ZVpXYic9msI%2FNw6eB8ag%3D” alt=”5fb5db4f33474243a5ac9f97e9509260~noop.image?_iz=58558&from=article.pc_detail&lk3s=953192f4&x-expires=1717726333&x-signature=rnnY9J6ZVpXYic9msI%2FNw6eB8ag%3D” />
进行向量化,并记为 公式BP2 :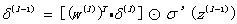
其中:右式的第二项和第三项之间用到了哈达玛积,表示将两个同样结构的矩阵的相同位置上的数值相乘。
现在,根据公式BP1我们能够获得网络最后一层的输出误差,接着根据公式BP2我们能够从后往前获得网络所有层的误差。
4.3 求参数w和b的偏导数
获取了各层各神经元的误差δ后,我们就能够利用误差δ作为中介,对模型参数w和b进行迭代求解。
先求解w的偏导数: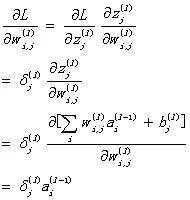
进行向量化,并记为 公式BP3 :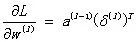
再求解b的偏导数: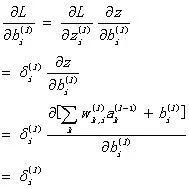
进行向量化,并记为 公式BP4 :
4.4 迭代
和梯度下降法类似,反向传播算法要进行多次迭代,以使得参数w和b趋向能够使损失函数最小的值。
每轮迭代时,参数w和b的变化公式如下: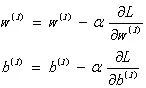
这里的α是超参数:学习效率(LearningRate)。用于控制参数w和b变化的速度。
注:本文的推导只涉及一个输入样本的数据,但是在实际应用中,一般会使用批量样本,这时只需要将各个样本求得的偏导数取均值,再进行迭代即可,具体内容这里就不作展开了。
4.5 算法流程总结
简要叙述下反向传播算法的流程:
启动一个循环,事先定义好循环终止的条件,循环内容如下:
步骤1:根据公式BP1,求得神经网络模型最后一层的误差δ(L)。
步骤2:根据公式BP2,自后向前,求得神经网络模型所有层的误差δ(l)。
步骤3:根据公式BP3和BP4,求得参数w和b的偏导数∂L/∂w和∂L/∂b。
步骤4:利用偏导数∂L/∂w和∂L/∂b,更新参数w和b。
步骤5:判断当前模型的损失函数L是否符合预期,如果“是”则跳出循环终止训练,否则继续训练。
5 实操技巧
只会推公式对解决问题没有任何帮助!!!
推导数学公式的目的在于了解算法,以达到建立和优化模型的目的。所以谷歌最喜欢用的算法就是“博士生下降”(grad student descent)算法,也就是靠那些数学很好的博士去调参。。。。。。
本节介绍几个和反向传播算法相关的实操技巧。
5.1 梯度消失
先回顾一下公式BP2:
我们重点关注下激活函数的导数: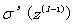
在模型刚开始学习的时候,激活函数σ的导数σ’变化得较快,这时候不会出现问题。但是,随着模型越来越逼近最优解,或者在训练的过程中不小心的一次扰动,σ’可能就等于0了。
这样,无论后一层的误差δ(l)是多少,乘上一个接近0的数,那么前一层的误差δ(l-1)自然也会近似于0。δ(l-1)一旦等于0后,那么误差就不会继续向前传播了。后续的w和b也就都等于0了。
所以,随着网络层数的增加,远离输出层(即接近输入层)的层不能够得到有效的学习,层数更深的神经网络有时反而会具有更大的训练误差。这就是梯度消失。
有时候为了预防梯度消失,我们会采用 梯度检验 的方法,以确认反向传播算法是否工作在正常状态。
5.2 激活函数的选择
我们先看看传统的sigmoid函数: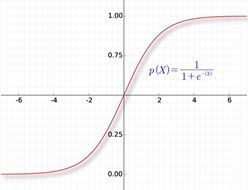
图5.1 Sigmoid函数
可以看出,Sigmoid函数只有一小段接近线性的区域,在输出趋近于0或1的区间,函数的值是保持不变或者变化很小的,反映到导数上,就是导数接近于0。
所以,我们为了避免梯度消失, 隐藏层不使用sigmoid函数作为激活函数 。
为了保证激活函数不至于那么容易就饱和,导致导数等于0,我们考虑将ReLU函数作为激活函数: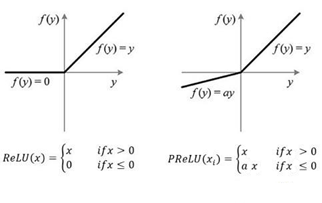
图5.2 ReLU函数和PReLU函数
在ReLU中,在自变量大于0的区间,能保证梯度不会消失,在自变量小于0的区间,函数的值被截断。在PReLU中,当x<0时,它不输出0,而是具有一个较小的斜率。
所以, 卷积神经网络钟爱的激活函数是ReLU ,它有利于反向传播阶段的计算,也能缓解过拟合。 在ReLU函数效果不好时,建议尝试PReLU函数 。此外, ReLu和PReLU一般只用于隐藏层 。
既然提到了激活函数,那么顺便列举一下其它几个Tip,虽然它们和反向传播算法无关:
激活函数最大的贡献就是将非线性引入神经网络模型,以使得算法能够学习更复杂的模型,否则即便增加网络的深度也依旧还是线性映射,起不到多层的效果。
如果是分类问题,输出层的激活函数一般会选择sigmoid函数。
在输入数据不是均值为0的正态分布时,Sigmoid函数输出的均值一般不为0,这是Sigmoid函数除了容易导致梯度消失外,另一个缺点。
5.3 参数w和b的初始化
5.3.1 参数w
在神经网络中,将权重值w初始化为0是不合适的。考虑全连接的深度神经网络,同一层中的任意神经元都是同构的,它们拥有相同的输入和输出,如果再将参数全部初始化为同样的值,那么无论前向传播还是反向传播的各个神经元的取值都将是完全相同的。
所以,我们采用 打破对称性 的方式,进行w初始值的随机化。
在使用ReLu作为激活函数时,为了避免梯度爆炸,建议w采用接近单位矩阵的初始化值。资料表明(我没验证过),初始化w为单位矩阵并使用ReLU作为激活函数,在一些应用中取得了与长短期记忆模型LSTM相似的结果。
两个比较流行的参数 w 的初始化方法:
( 1 ) HE 初始化 (He Initialization) 。将 w 初始化为均值为 0 ,方差为 2/dim_input 的正态分布随机数。其中 dim_input 为当前层输入数据的维度。
( 2 ) Xavier 初始化 。将 w 初始化为均值为 0 ,方差为 6/(dim_input+ dim_output) 的正态分布随机数。其中 dim_input 为当前层输入数据的维度, dim_output 为当前层输出数据的维度。
5.3.2 参数b
根据公式BP3:
在使用ReLU函数时,一个比较好的做法是用一个较小的正数来初始化参数b(参数b常常被初始化为1/0.1/0.01),以避免神经元节点输出为0的问题。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/80584.html