
神经网络概述
神经网络的结构模仿生物神经元。当生物神经元网络中的每个神经元变得“兴奋”时,它会向连接到下一级的神经元发送化学物质,从而改变这些神经元的电位。如果神经元的电位超过阈值,则它被激活;否则,它不被激活。
神经网络最基本的单元是神经元模型(neuron)。在生物神经网络的原始结构中,每个神经元通常具有多个树突(dendrites)、轴突(axons)和细胞体(cellbody)。树突短且多分枝,轴突长且存在。从功能上讲,树突用于传递其他神经元传递来的神经冲动,而当来自树突或细胞体的神经冲动兴奋神经元时,轴突会传递兴奋。其他神经元通过轴突传播。神经元的生物结构如下图所示。
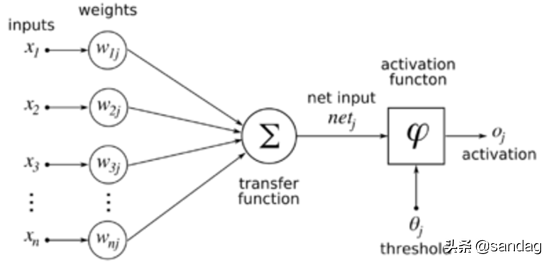
迄今为止使用的“MP神经元模型”就是这种结构的抽象,也称为“阈值逻辑单元”,其中树突对应于输入部分,每个神经元接收n个接收信号。这些权重通过加权连接传递到单元体。也称为连接权重。细胞体分为两部分,前者计算输入信号的加权和,或累积水平。后者首先计算输入信号之和与阈值之间的差。它接收一个神经元的信号,并使用激活函数(activation function)生成输出,通过其轴突发送到其他神经元。 M-P神经元模型如下图所示。

迄今为止使用的“MP神经元模型”就是这种结构的抽象,也称为“阈值逻辑单元”,其中树突对应于输入部分,每个神经元接收n个接收信号。这些权重通过加权连接传递到单元体。也称为连接权重。细胞体分为两部分,前者计算输入信号的加权和,或累积水平。后者首先计算输入信号之和与阈值之间的差。计算神经元的输入值,并使用激活函数(activation function)来计算总输入值与神经元的函数阈值之间的差值,产生从轴突发送到其他神经元要做的输出。 M-P神经元模型如下图所示。
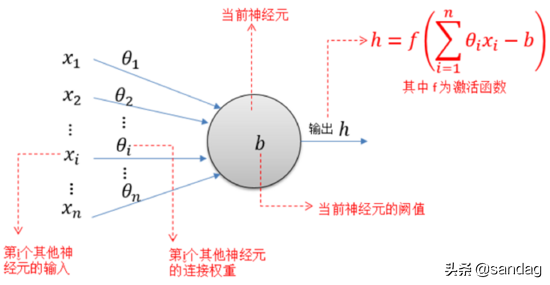
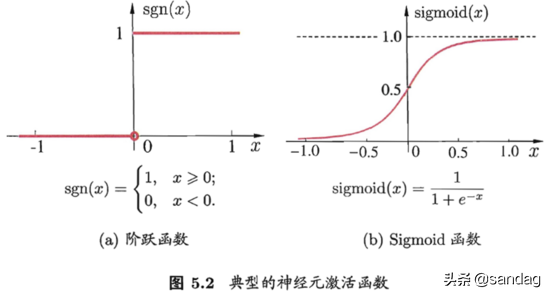
与线性分类非常相似,神经元模型最理想的激活函数也是阶跃函数。也就是说,神经元的输入值与阈值之间的差值被映射为输出值1 或0。如果差异较大,则如果差异为零,则输出1 对应于兴奋。如果该值小于零,则输出0 对应于抑制。然而,阶跃函数是不连续且不平滑的(在其定义的域内不完全可微)。因此,M-P神经元模型使用sigmoid函数来压缩变化的输入值。它也称为压缩函数,因为它将输出值范围内的较宽范围转换为(0,1 )。
神经网络是将多个神经元按照一定的层次结构连接起来而得到的。这是一个具有多个参数的模型。例如,如果10个神经元成对连接,则需要学习100个参数(每个神经元有9个连接权重和1个阈值)。整个神经网络由这些相互嵌套的函数组成。
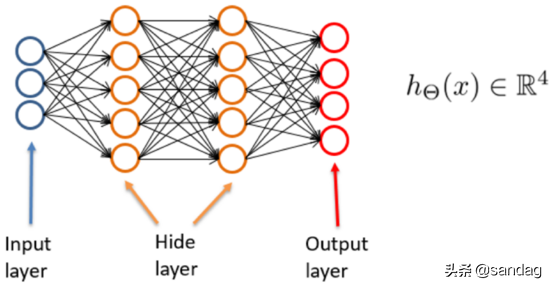
多前馈神经网络由三部分组成:输入层、隐藏层和输出层。可能有也可能没有隐藏层,但输入和输出层必须存在。没有隐藏层的神经网络是线性的,只能处理线性可分的问题(线性可分的问题是指从二维角度看分界线是一条直线;多维是指从二维角度看分界线是一条直线)维度观点;意味着有一个线性超平面来对它们进行分类)。没有隐藏层且输出层只有一个单元的神经网络相当于线性逻辑模型。
感知机与多层网络
感知器是一个由两层神经元组成的简单模型,但只有输出层是M-P 神经元。即只有输出层的神经元执行激活函数的处理,也称为功能神经元。输入层仅接收外部信号。 (样本的属性)并将其传递到不带激活函数的输出层(输入层的神经元数量等于样本的属性数量)。这样一来,感知器的思想与之前的线性回归基本相同,都是通过对属性进行加权并与另一个常数求和,并使用sigmoid 函数求解来压缩输出值来解决分类问题。 0-1 之间。不同的是,感知器的输出层需要多个神经元,从而可以实现多个分类问题。同时,两个模型所采用的参数估计方法也存在显着差异。
给定一个训练集,通过学习可以得到感知器的n+1个参数(n个权重+1个阈值)。阈值可以被视为具有固定输入值-1的虚拟节点权重。也就是说,假设有一个固定的输入。
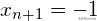
由于输入层神经元为,对应的权重为,因此权重和阈值被整合到权重学习中。简单感知器的结构如下图所示。
感知器权重的学习规则如下:对于训练样本(x,y),当样本进入感知器训练时,如果输出值与样本的实际标签不匹配,则会生成输出值。感知器调整权重。如果激活函数是阶跃函数,调整方法类似于逻辑回归(基于梯度下降)。
感知器通过一次输入一个样本来更新权重。首先,设置初始权重(通常是随机的),逐个输入样本数据,如果输出值与实际标记相同,则继续输入下一个样本。如果不一致,则更新权重,并逐一重新测试每个样本数据,直到输出值与真实标签相同。这很容易理解。感知器模型总能准确预测训练数据中的每个样本。正如决策树模型总是可以分离所有训练数据一样,感知器模型也很容易出现过度拟合问题。
BP神经网络算法
从上面可以看出,神经网络训练主要涉及到权重和阈值。在多层网络中,使用上述简单的感知器权重调整规则显然是不够的。 BP神经网络算法是一种误差反向传播算法,是为训练多层前馈神经网络而设计的,是最成功的神经网络训练算法。神经网络中的BP BP代表Back Propagation,BP(Back Propagation)神经网络分为两个过程。
操作信号前向发送子过程和误差信号后向发送子过程BP神经网络在单个样本中具有输入和输出,并且输入层和输出层之间通常存在多个隐藏层。事实上,1989年Robert Hecht-Nielsen证明了任何闭区间连续函数都可以用隐含层BP网络来逼近。这就是万能逼近定理。因此,三层BP网络可以完成任意维度之间的映射。所以这三层是输入层(I)、隐藏层(H)和输出层(O)。一般来说,当我们谈论BP网络算法时,默认使用的是用BP算法训练的多层前馈神经网络。
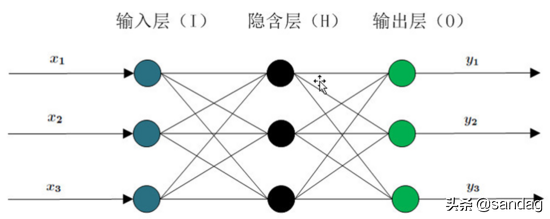
正向传递子过程
假设节点i和节点j之间的权重为,节点j的阈值为,每个节点的输出值为,每个节点的输出值基于上层所有节点的输出值,即当前节点。所有节点权重和当前节点阈值均由激活函数实现。具体计算方法如下。
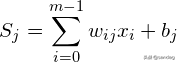
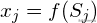
其中,f为激活函数,通常选择S型(sigmoid函数)函数或线性函数。转账转账的过程比较简单,根据上面的公式计算即可。在BP神经网络中,输入层节点没有阈值。
反向传递子过程
在BP神经网络中,误差信号反向传播子过程相对复杂。假设输出层的所有结果均为,则误差函数为:
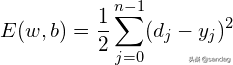
BP神经网络的主要目标是迭代地修改权重和阈值以最小化误差函数值。 Widlow-Hoff学习规则是沿着相对误差平方和最快下降的方向不断调整网络权重和阈值。根据梯度下降,权重向量的修正与当前位置成正比。
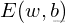
第j 个输出节点的梯度为:
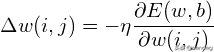
假设激活函数选择如下:
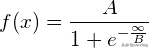
激活函数的推导如下。
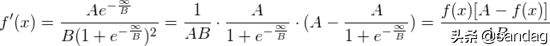
所以:

包括:
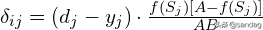
以下也同样。
p;x-expires=1717726368&x-signature=%2FikoEGXaAnNMQF591We3mro92AM%3D” alt=”3504d41310a54144b8bea1c87d2740e7~noop.image?_iz=58558&from=article.pc_detail&lk3s=953192f4&x-expires=1717726368&x-signature=%2FikoEGXaAnNMQF591We3mro92AM%3D” />
这就是著名的学习规则,通过改变神经元之间的连接权值来减少系统实际输出和期望输出的误差,这个规则又叫做Widrow-Hoff学习规则或者纠错学习规则。
上面是对隐含层和输出层之间的权值和输出层的阀值计算调整量,而针对输入层和隐含层和隐含层的阀值调整量的计算更为复杂。假设是输入层第k个节点和隐含层第i个节点之间的权值,那么有:

其中有:
有了上述公式,根据梯度下降法,那么对于隐含层和输出层之间的权值和阀值调整如下:
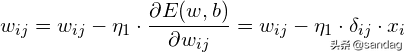
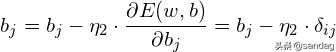
而对于输入层和隐含层之间的权值和阀值调整同样有:
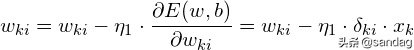
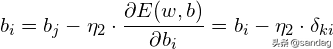
容易看出,BP学习算法中,各层权值调整公式形式上都是一样的,均由3个因素决定,即:
学习率本层输出的误差信号本层输入信号Y或X
隐含层的选取
在BP神经网络中,输入层和输出层的节点个数都是确定的,而隐含层节点个数不确定,那么应该设置为多少才合适呢?实际上,隐含层节点个数的多少对神经网络的性能是有影响的,有一个经验公式可以确定隐含层节点数目,如下:
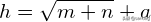
其中h为隐含层节点数目,m为输入层节点数目,n为输出层节点数目,a为1~10之间的调节常数。
BP神经网络的注意点
BP神经网络一般用于分类或者逼近问题。如果用于分类,则激活函数一般选用Sigmoid函数或者硬极限函数,如果用于函数逼近,则输出层节点用线性函数。
BP神经网络在训练数据时可以采用增量学习或者批量学习。增量学习要求输入模式要有足够的随机性,对输入模式的噪声比较敏感,即对于剧烈变化的输入模式,训练效果比较差,适合在线处理。批量学习不存在输入模式次序问题,稳定性好,但是只适合离线处理。
标准BP神经网络的缺陷:
容易形成局部极小值而得不到全局最优值。BP神经网络中极小值比较多,所以很容易陷入局部极小值,这就要求对初始权值和阀值有要求,要使得初始权值和阀值随机性足够好,可以多次随机来实现。训练次数多使得学习效率低,收敛速度慢。隐含层的选取缺乏理论的指导。训练时学习新样本有遗忘旧样本的趋势。BP算法的改进:
增加动量项。引入动量项是为了加速算法收敛,即如下公式。动量因子一般选取1~0.8。自适应调节学习率,如随着迭代次的代数t动态变化的学习率: 引入陡度因子通常BP神经网络在训练之前会对数据归一化处理,即将数据映射到更小的区间内,比如[0,1]或[-1,1]。
BP神经网络的Python实现
# coding:UTF-8import numpy as npfrom math import sqrt def load_data(file_name): ”’导入数据 input: file_name(string):文件的存储位置 output: feature_data(mat):特征 label_data(mat):标签 n_class(int):类别的个数 ”’ # 1、获取特征 f = open(file_name) # 打开文件 feature_data = [] label_tmp = [] for line in f.readlines(): feature_tmp = [] lines = line.strip().split(“\t”) for i in range(len(lines) – 1): feature_tmp.append(float(lines[i])) label_tmp.append(int(lines[-1])) feature_data.append(feature_tmp) f.close() # 关闭文件 # 2、获取标签 m = len(label_tmp) n_class = len(set(label_tmp)) # 得到类别的个数 label_data = np.mat(np.zeros((m, n_class))) for i in range(m): label_data[i, label_tmp[i]] = 1 return np.mat(feature_data), label_data, n_class def sig(x): ”’Sigmoid函数 input: x(mat/float):自变量,可以是矩阵或者是任意实数 output: Sigmoid值(mat/float):Sigmoid函数的值 ”’ return 1.0 / (1 + np.exp(-x)) def partial_sig(x): ”’Sigmoid导函数的值 input: x(mat/float):自变量,可以是矩阵或者是任意实数 output: out(mat/float):Sigmoid导函数的值 ”’ m, n = np.shape(x) out = np.mat(np.zeros((m, n))) for i in range(m): for j in range(n): out[i, j] = sig(x[i, j]) * (1 – sig(x[i, j])) return out def hidden_in(feature, w0, b0): ”’计算隐含层的输入 input: feature(mat):特征 w0(mat):输入层到隐含层之间的权重 b0(mat):输入层到隐含层之间的偏置 output: hidden_in(mat):隐含层的输入 ”’ m = np.shape(feature)[0] hidden_in = feature * w0 for i in range(m): hidden_in[i,] += b0 return hidden_in def hidden_out(hidden_in): ”’隐含层的输出 input: hidden_in(mat):隐含层的输入 output: hidden_output(mat):隐含层的输出 ”’ hidden_output = sig(hidden_in) return hidden_output def predict_in(hidden_out, w1, b1): ”’计算输出层的输入 input: hidden_out(mat):隐含层的输出 w1(mat):隐含层到输出层之间的权重 b1(mat):隐含层到输出层之间的偏置 output: predict_in(mat):输出层的输入 ”’ m = np.shape(hidden_out)[0] predict_in = hidden_out * w1 for i in range(m): predict_in[i,] += b1 return predict_in def predict_out(predict_in): ”’输出层的输出 input: predict_in(mat):输出层的输入 output: result(mat):输出层的输出 ”’ result = sig(predict_in) return result def bp_train(feature, label, n_hidden, maxCycle, alpha, n_output): ”’计算隐含层的输入 input: feature(mat):特征 label(mat):标签 n_hidden(int):隐含层的节点个数 maxCycle(int):最大的迭代次数 alpha(float):学习率 n_output(int):输出层的节点个数 output: w0(mat):输入层到隐含层之间的权重 b0(mat):输入层到隐含层之间的偏置 w1(mat):隐含层到输出层之间的权重 b1(mat):隐含层到输出层之间的偏置 ”’ m, n = np.shape(feature) # 1、初始化 w0 = np.mat(np.random.rand(n, n_hidden)) w0 = w0 * (8.0 * sqrt(6) / sqrt(n + n_hidden)) – \ np.mat(np.ones((n, n_hidden))) * \ (4.0 * sqrt(6) / sqrt(n + n_hidden)) b0 = np.mat(np.random.rand(1, n_hidden)) b0 = b0 * (8.0 * sqrt(6) / sqrt(n + n_hidden)) – \ np.mat(np.ones((1, n_hidden))) * \ (4.0 * sqrt(6) / sqrt(n + n_hidden)) w1 = np.mat(np.random.rand(n_hidden, n_output)) w1 = w1 * (8.0 * sqrt(6) / sqrt(n_hidden + n_output)) – \ np.mat(np.ones((n_hidden, n_output))) * \ (4.0 * sqrt(6) / sqrt(n_hidden + n_output)) b1 = np.mat(np.random.rand(1, n_output)) b1 = b1 * (8.0 * sqrt(6) / sqrt(n_hidden + n_output)) – \ np.mat(np.ones((1, n_output))) * \ (4.0 * sqrt(6) / sqrt(n_hidden + n_output)) # 2、训练 i = 0 while i <= maxCycle: # 2.1、信号正向传播 # 2.1.1、计算隐含层的输入 hidden_input = hidden_in(feature, w0, b0) # mXn_hidden # 2.1.2、计算隐含层的输出 hidden_output = hidden_out(hidden_input) # 2.1.3、计算输出层的输入 output_in = predict_in(hidden_output, w1, b1) # mXn_output # 2.1.4、计算输出层的输出 output_out = predict_out(output_in) # 2.2、误差的反向传播 # 2.2.1、隐含层到输出层之间的残差 delta_output = -np.multiply((label – output_out), partial_sig(output_in)) # 2.2.2、输入层到隐含层之间的残差 delta_hidden = np.multiply((delta_output * w1.T), partial_sig(hidden_input)) # 2.3、 修正权重和偏置 w1 = w1 – alpha * (hidden_output.T * delta_output) b1 = b1 – alpha * np.sum(delta_output, axis=0) * (1.0 / m) w0 = w0 – alpha * (feature.T * delta_hidden) b0 = b0 – alpha * np.sum(delta_hidden, axis=0) * (1.0 / m) if i % 100 == 0: print(“\t——– iter: “, i, ” ,cost: “, (1.0 / 2) * get_cost(get_predict(feature, w0, w1, b0, b1) – label)) i += 1 return w0, w1, b0, b1 def get_cost(cost): ”’计算当前损失函数的值 input: cost(mat):预测值与标签之间的差 output: cost_sum / m (double):损失函数的值 ”’ m, n = np.shape(cost) cost_sum = 0.0 for i in range(m): for j in range(n): cost_sum += cost[i, j] * cost[i, j] return cost_sum / m def get_predict(feature, w0, w1, b0, b1): ”’计算最终的预测 input: feature(mat):特征 w0(mat):输入层到隐含层之间的权重 b0(mat):输入层到隐含层之间的偏置 w1(mat):隐含层到输出层之间的权重 b1(mat):隐含层到输出层之间的偏置 output: 预测值 ”’ return predict_out(predict_in(hidden_out(hidden_in(feature, w0, b0)), w1, b1)) def save_model(w0, w1, b0, b1): ”’保存最终的模型 input: w0(mat):输入层到隐含层之间的权重 b0(mat):输入层到隐含层之间的偏置 w1(mat):隐含层到输出层之间的权重 b1(mat):隐含层到输出层之间的偏置 output: ”’ def write_file(file_name, source): f = open(file_name, “w”) m, n = np.shape(source) for i in range(m): tmp = [] for j in range(n): tmp.append(str(source[i, j])) f.write(“\t”.join(tmp) + “\n”) f.close() write_file(“weight_w0”, w0) write_file(“weight_w1”, w1) write_file(“weight_b0”, b0) write_file(“weight_b1″, b1) def err_rate(label, pre): ”’计算训练样本上的错误率 input: label(mat):训练样本的标签 pre(mat):训练样本的预测值 output: rate[0,0](float):错误率 ”’ m = np.shape(label)[0] err = 0.0 for i in range(m): if label[i, 0] != pre[i, 0]: err += 1 rate = err / m return rate if __name__ == “__main__”: # 1、导入数据 print(“——— 1.load data ————“) feature, label, n_class = load_data(“data.txt”) # 2、训练网络模型 print(“——— 2.training ————“) w0, w1, b0, b1 = bp_train(feature, label, 20, 1000, 0.1, n_class) # 3、保存最终的模型 print(“——— 3.save model ————“) save_model(w0, w1, b0, b1) # 4、得到最终的预测结果 print(“——— 4.get prediction ————“) result = get_predict(feature, w0, w1, b0, b1) print(“训练准确性为:”, (1 – err_rate(np.argmax(label, axis=1), np.argmax(result, axis=1))))
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/80626.html