
在阅读《人工智能》之前,建议先阅读前面的三篇文章。如何一般性地理解神经网络
如何理解深度学习中流行的梯度下降法张雨绮和袁百元的《理解神经网络中的交叉熵》!
补完上一篇文章的坑后,我将继续解释上一篇文章的问题。
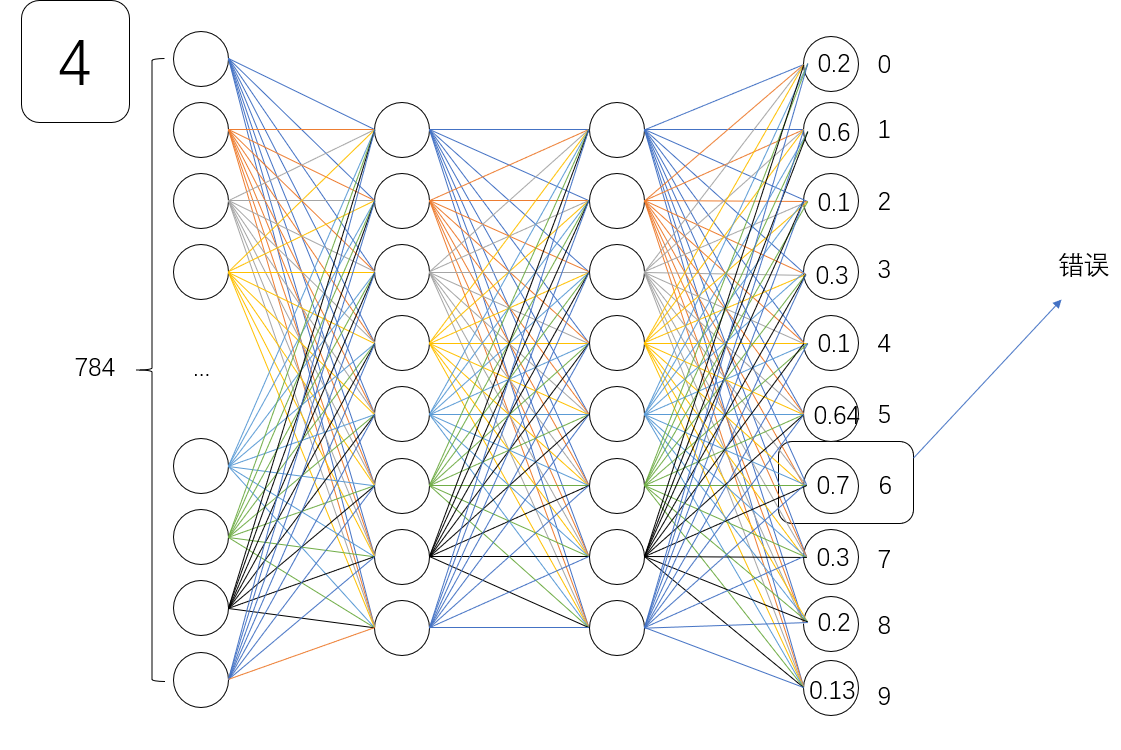 如何调整神经网络?
如何调整神经网络?
现在您已经对上一篇文章中的梯度下降有了很好的了解,梯度向您展示如何改变神经网络上所有连接的所有值和偏差,从而使成本函数下降得更快。使用逆神经算法来找到这个高度复杂的梯度。
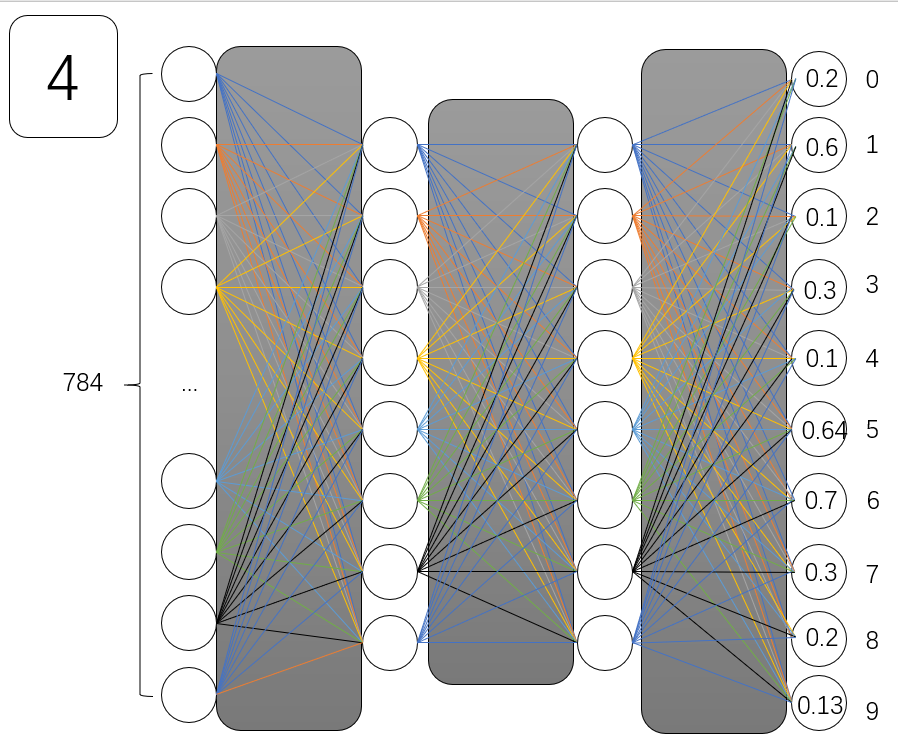 连接代表权重和偏差
连接代表权重和偏差
从下图中可以看出,梯度向量中每个值的大小总是告诉计算机成本函数对每个参数数量的“敏感性”。
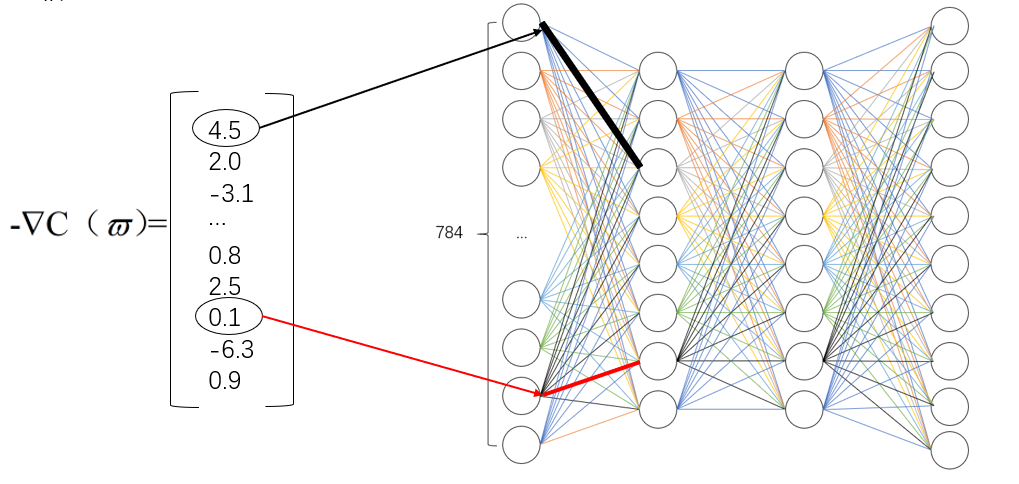
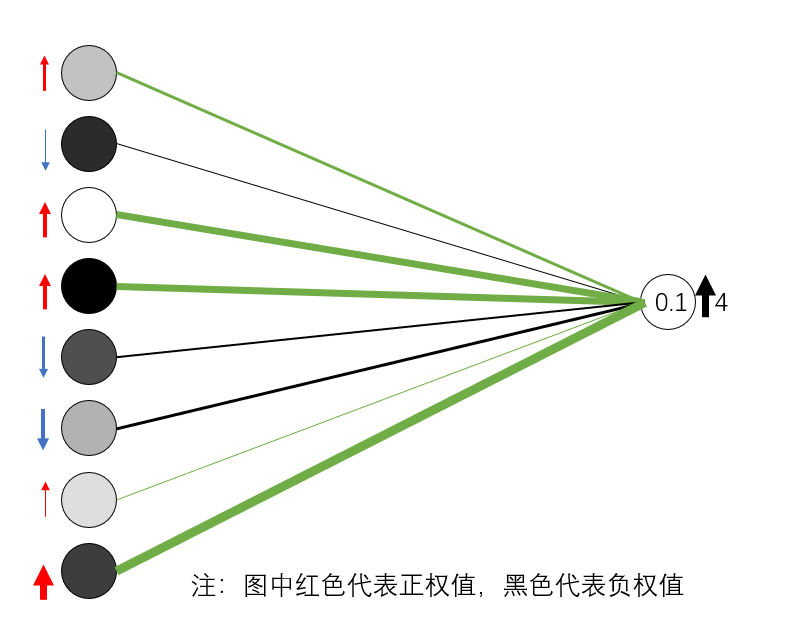
在上图中,如果梯度值4.5代表神经网络顶部的黑线,0.1代表神经网络底部的红线,那么第一条黑线代表的权重是成本函数影响力的32倍。换句话说,改变第一条黑线代表的权重对成本函数的影响是第二条红线代表的权重的32 倍。
现在,回到之前的问题。如下所示,计算机对字体4 的识别是错误的,所以我们来修复它,使其正确识别(从左边的预测值0.1 到右边的真实值)。对1)。接下来,我们需要增加代表“4”的预测值并减少其他预测值。
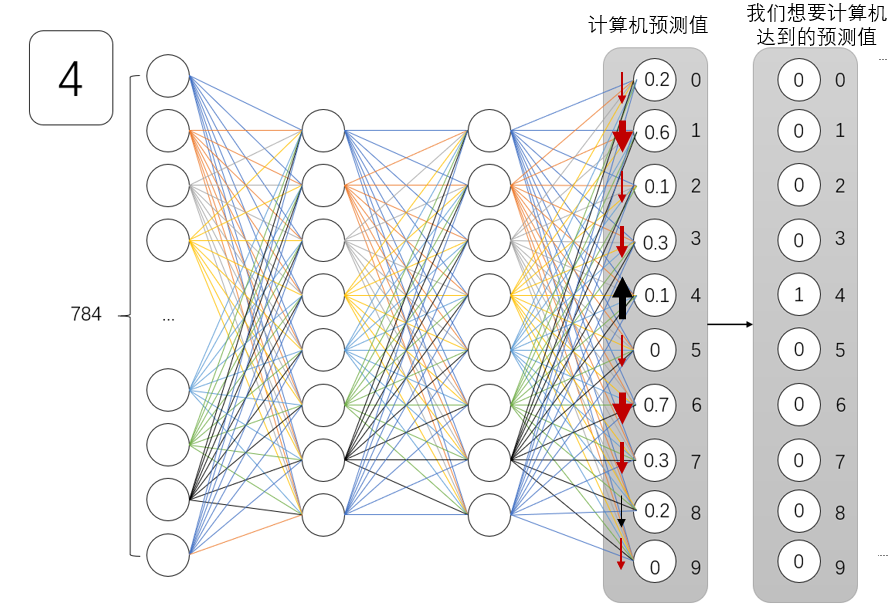 箭头表示增加或减少
箭头表示增加或减少
那么问题就出现了!如何才能增加数字“4”代表的预测值,并减少其他错误预测的预测值呢?
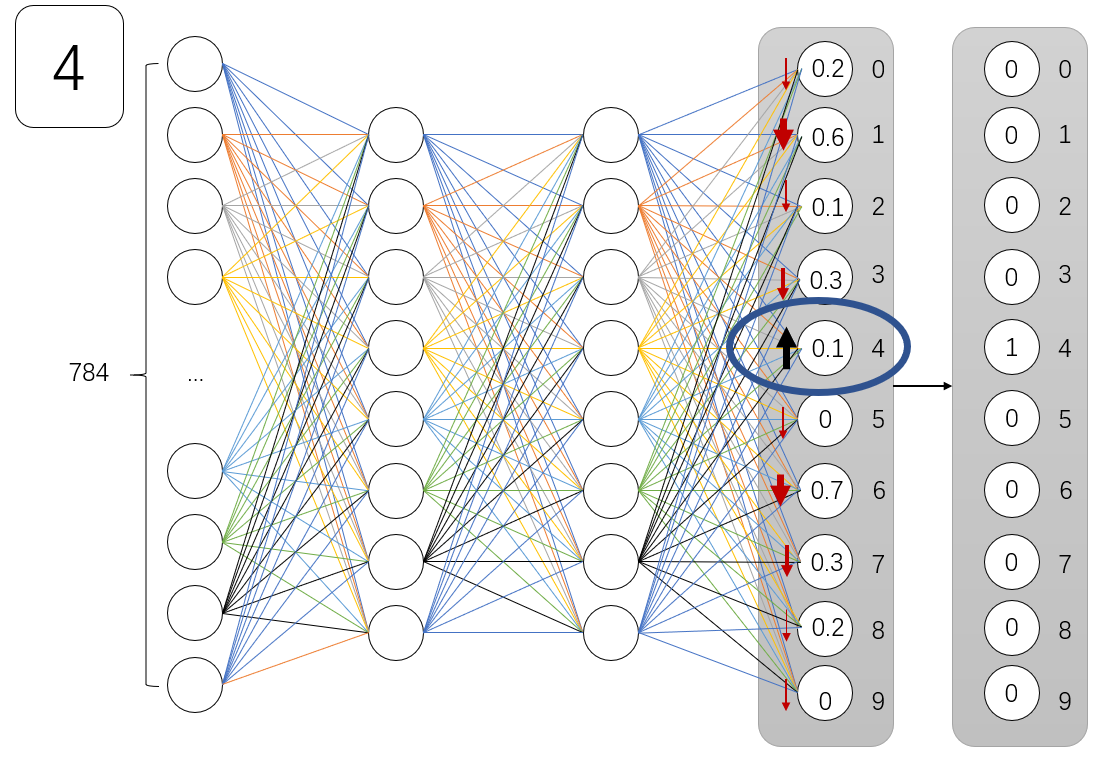 如何将值增加0.1?
如何将值增加0.1?
从前面三篇文章中,我们了解到“4”的预测值是通过以下公式计算的:
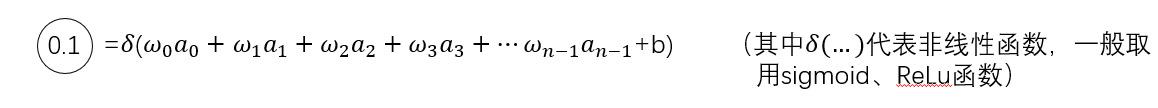 配方
配方
如何将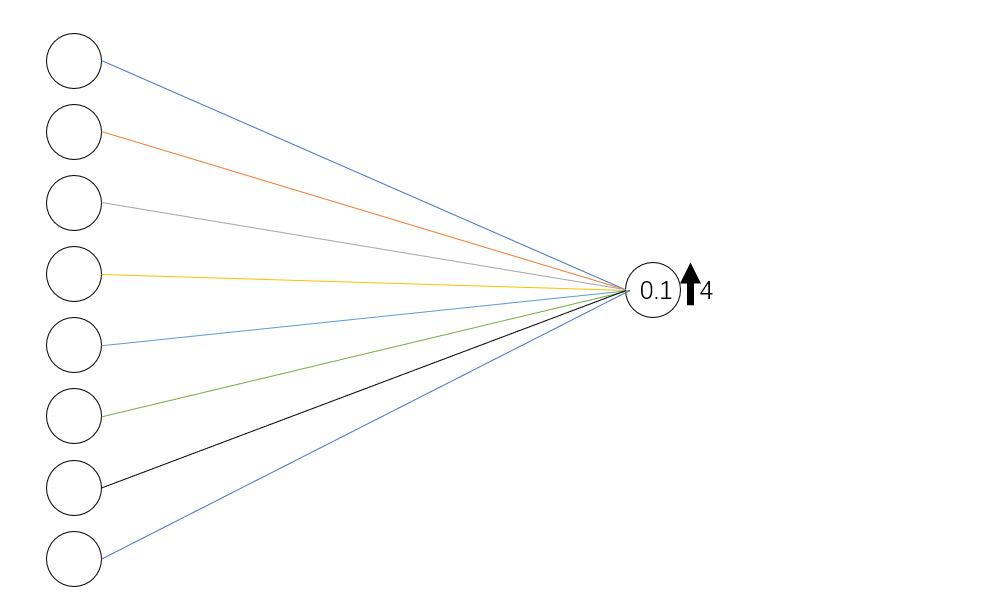 增加0.1
增加0.1
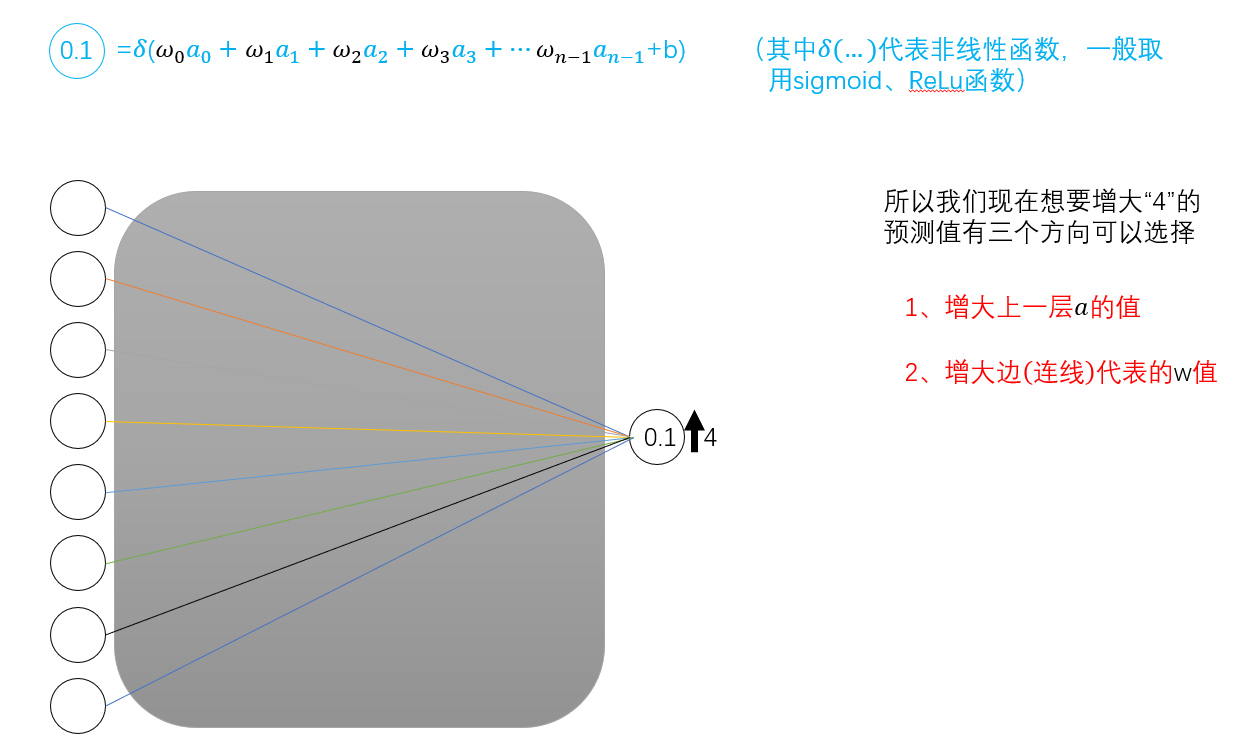
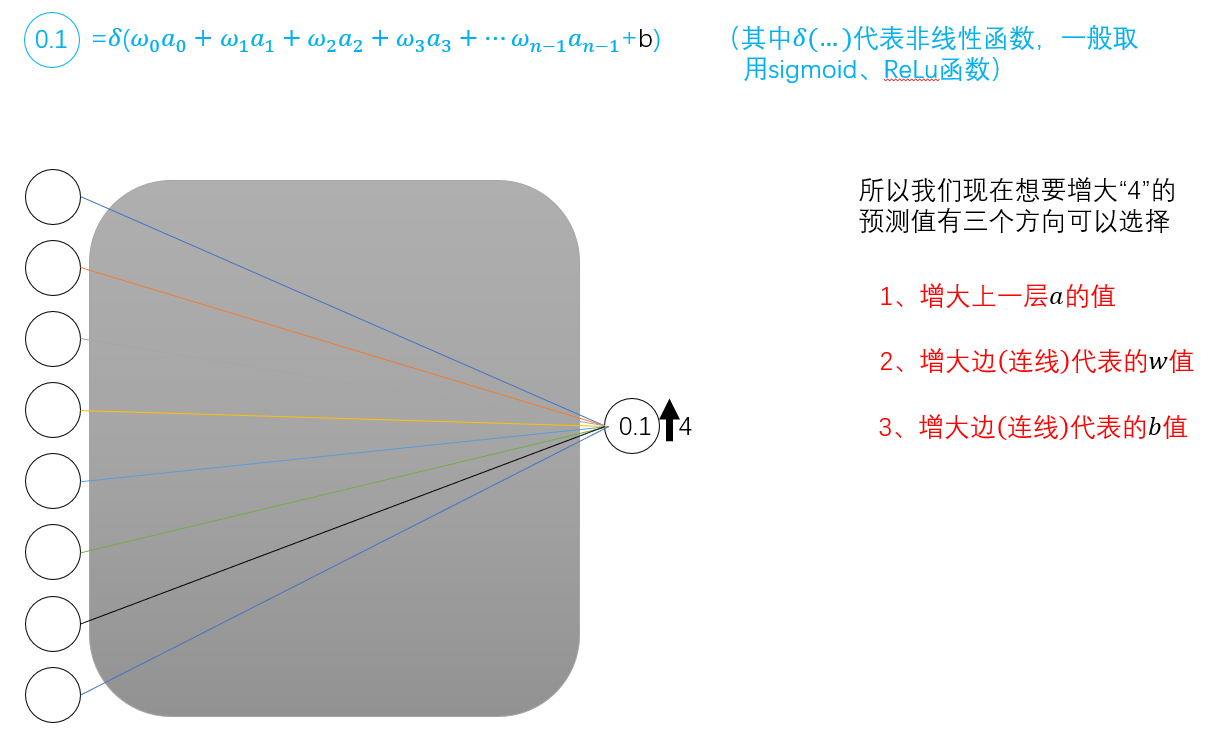
因此,我们希望增加代表“4”的预测值。有三种方法可供选择。
1.增加上一层的a值。
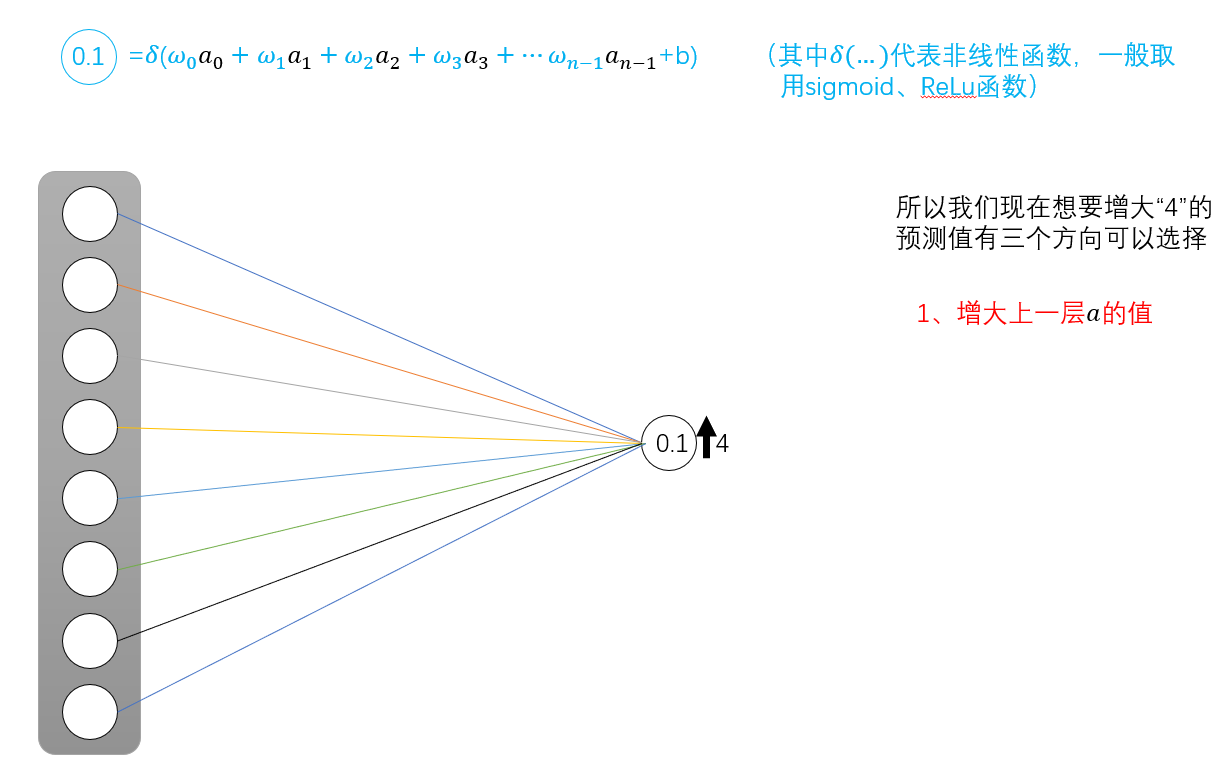 增加
增加
2. 增大权重w的值。
 增加重量
增加重量
3.增加偏差b
 偏差增加b
偏差增加b
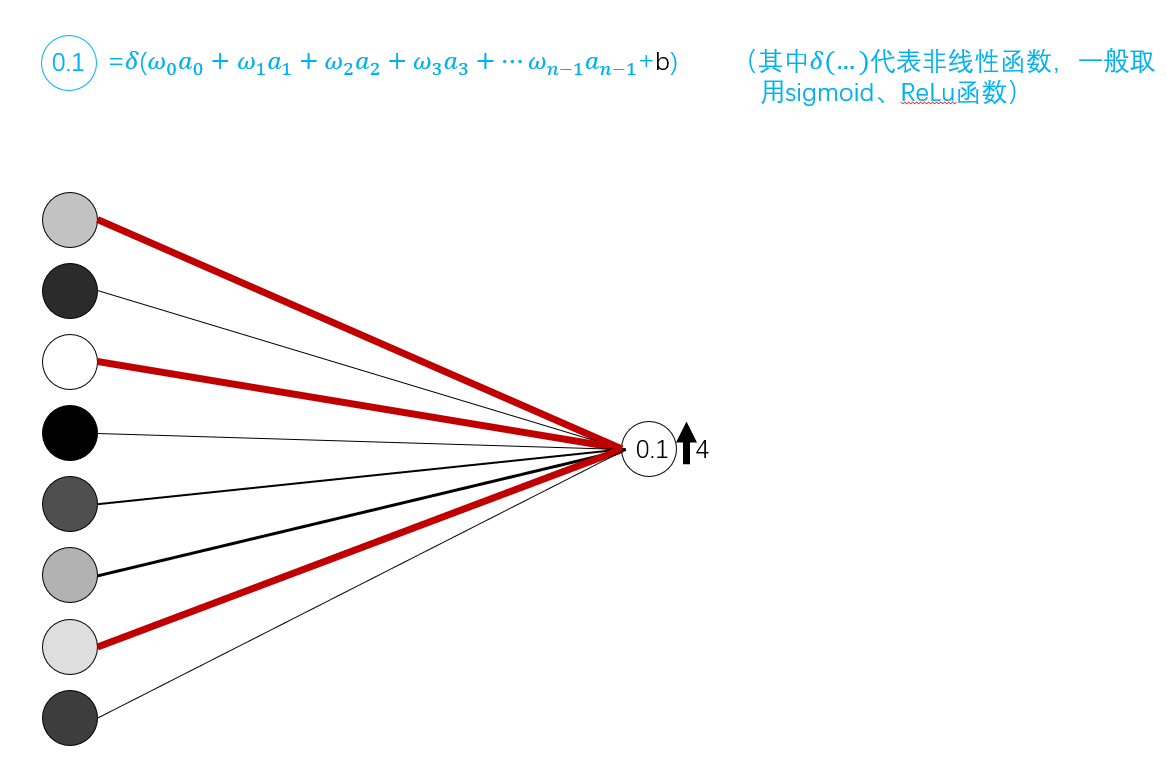
经过我们的介绍,我们可以看到,增加成本函数向量中较大值所代表的权重,比增加成本函数向量中较小值所代表的权重要划算得多。
因此,可以增大连接的具有正权值的上层神经网络节点的值a,减小连接的具有负权值的上层神经网络节点的值a。这样我们就可以尽可能的增大数字“4”的预测值。
a值的增减由成本函数-C(.)决定。
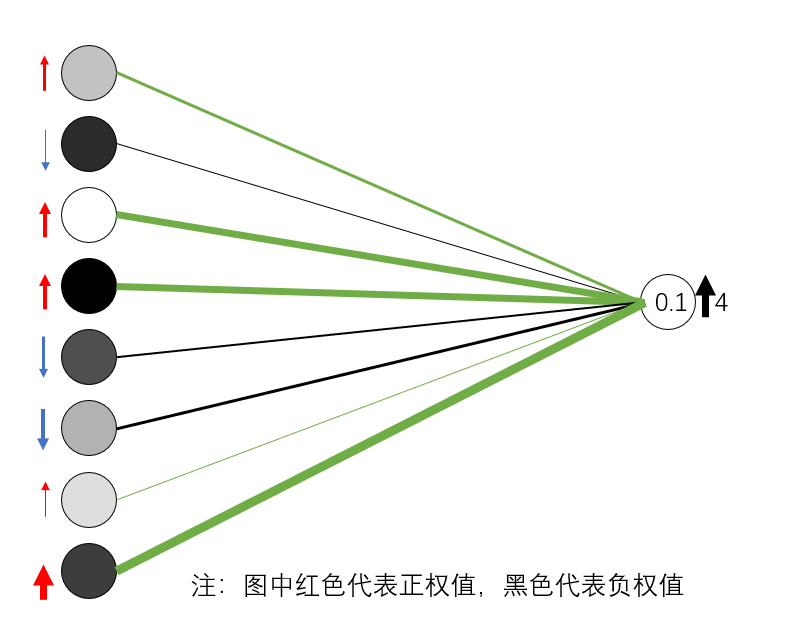 a的值的增减由成本函数-C(.)决定。
a的值的增减由成本函数-C(.)决定。
这样,每个单元就按照自己对每一项进行增减的思路进行累加,最终得到这一层的最终结果。 (比较难理解,请看下图才能理解)
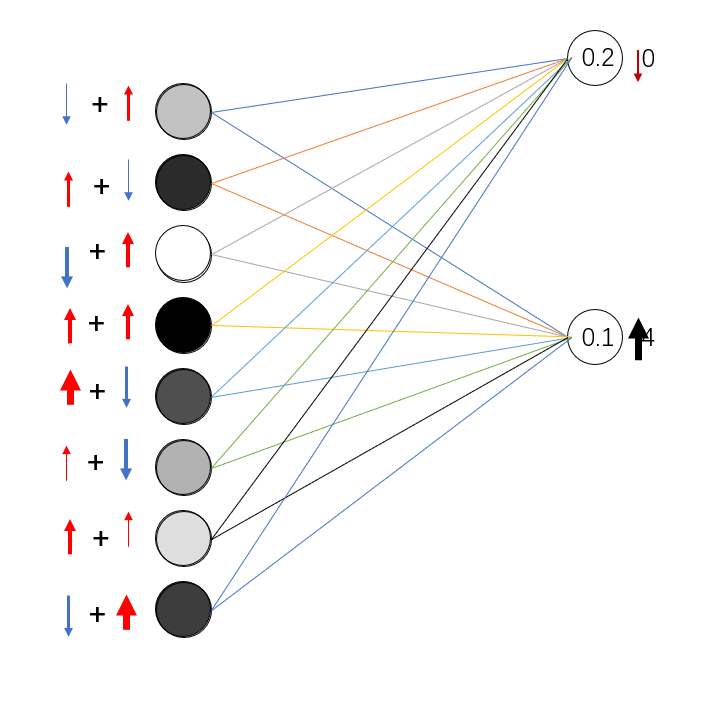
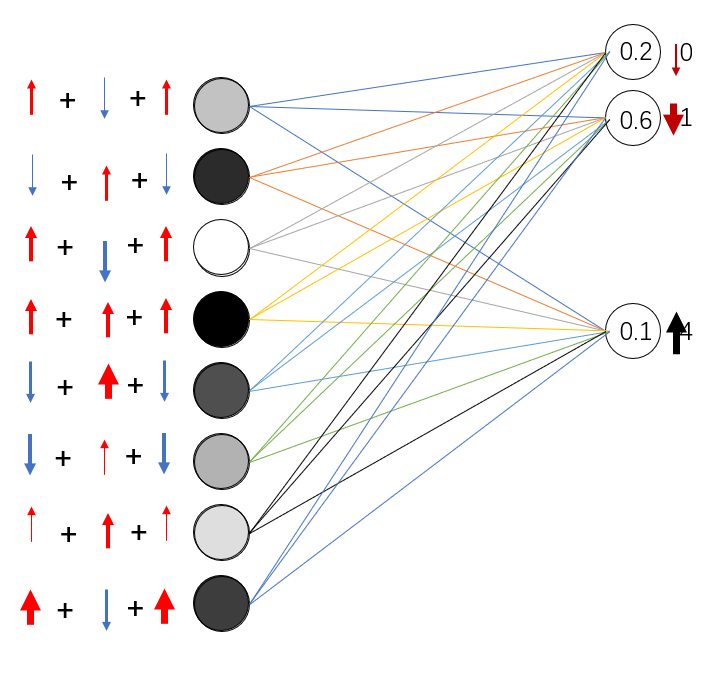
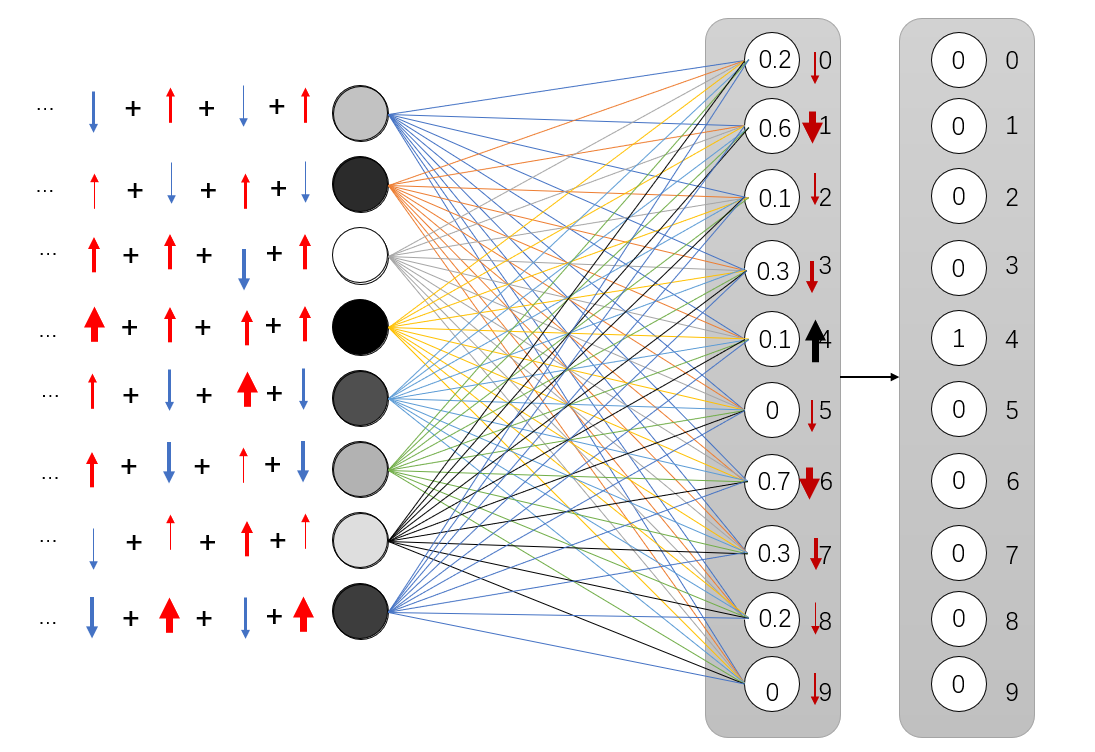
然后每一层都像这样向后传播,改变值来实现优化。事实上,这些都是反向传播神经网络的概念。

原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/80653.html
