
译自An SQL Vector Database To Enhance Text Search: How We Did It,作者 Mochi Xu。
全球数据的爆炸式增长,预计到2025 年将达到 181 泽字节,其中 80% 为非结构化数据,这对无法有效处理非结构化文本数据的传统数据库构成了挑战。全文搜索通过支持对非结构化文本数据的直观高效访问来解决此问题,允许用户根据主题或关键思想进行搜索。
为了增强文本搜索功能,MyScaleDB,一个针对向量搜索进行了优化的 ClickHouse 开源分支,集成了Tantivy,一个全文搜索引擎库。此升级极大地使那些将 ClickHouse 用于日志记录的人受益,通常作为 Elasticsearch 或 Loki 的替代品。它还使在检索增强生成 (RAG) 中利用 MyScaleDB的用户受益,其中使用了大语言模型 (LLM),结合向量和文本搜索以提高准确性。
本文探讨了 Tanvity 集成的技术细节以及我们如何衡量其对性能的影响。
ClickHouse 原生文本搜索的局限性
ClickHouse 提供了基本的文本搜索功能,如hasToken、startsWith和multiSearchAny,适用于简单术语查询。但是,这些功能对于更复杂的要求来说还不够,例如短语查询、模糊文本匹配和最佳匹配 25 (BM25) 相关性排名。因此,我们引入了 Tantivy 作为全文索引的基础实现,赋予 MyScaleDB 全文搜索功能。Tantivy 的全文索引支持模糊文本查询和 BM25 相关性排名,并加速了现有功能,如hasToken和multiSearchAny术语匹配。
我们为何选择 Tantivy
Tantivy 是一个用Rust编写的开源全文搜索引擎库。它专为速度和效率而设计,尤其是在处理大量文本数据时。
Tantivy 的核心原则
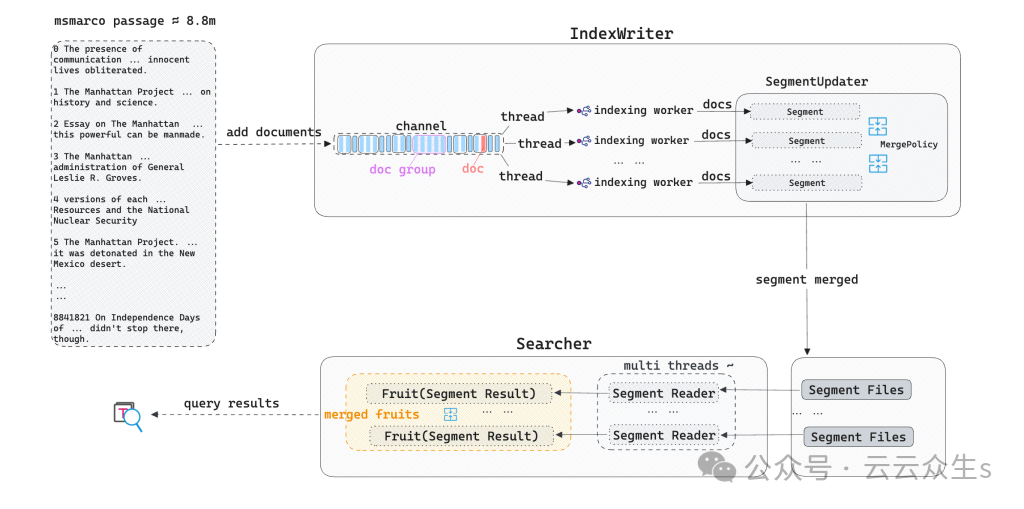
- 构建索引:Tantivy 对输入文本进行标记化,将其拆分为独立的标记。然后,它创建一个倒排索引(发布列表)并将其写入索引文件(段)。同时,Tantivy 的后台线程利用合并策略来合并和更新这些段索引文件。
- 执行文本搜索:当用户发起文本搜索查询时,Tantivy 解析查询语句,提取标记,并在每个段上根据查询条件和 BM25 相关性算法对文档进行排序和评分。最后,基于相关性分数合并这些段的查询结果并返回给用户。
Tantivy 的关键功能
- BM25 相关性评分:Elasticsearch、Lucene 和 Solr 都将 BM25 用作默认相关性排名算法。BM25 分数评估文本搜索的准确性和相关性,增强用户搜索体验。
- 可配置标记器:此功能支持各种语言标记器,满足用户多样化的标记化需求。
- 自然语言查询:用户可以使用
AND、OR和IN等关键字灵活地组合文本查询,降低 SQL 语句编写的复杂性。
有关更多功能,请参阅Tantivy 的文档。
无缝集成能力
MyScaleDB 用C++编写,建立在 ClickHouse 的基础上,并作为人工智能原生应用程序的强大搜索引擎。为了丰富全文搜索功能,我们需要一个可以直接嵌入 MyScaleDB 的库。
Tantivy 是一个受 Apache Lucene 启发的全文搜索库。与 Elasticsearch、Apache Solr 和其他类似引擎不同,Tantivy 可以集成到各种数据库中,包括 MyScaleDB。由于 Tantivy 是用 Rust 编写的,因此可以使用Corrosion轻松地将其与 C++ 程序集成。
集成过程
为 Tantivy 构建 C++ 封装器
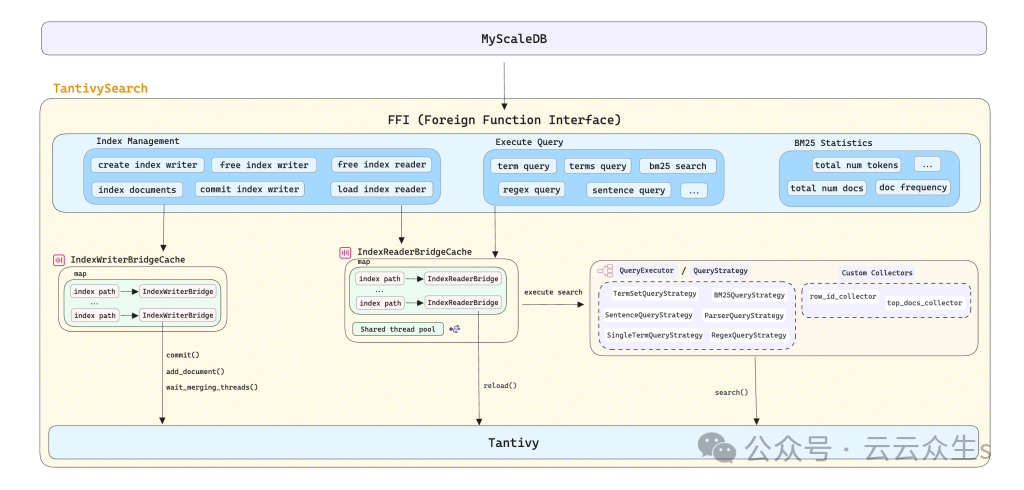
原始 Tantivy 库不能直接在 MyScaleDB 中使用。为了解决跨语言开发(C++ 和 Rust),我们开发了tantivy-search,一个 Tantivy 的 C++ 封装器。它为 MyScaleDB 提供了一组外函数接口 (FFI),支持直接管理索引创建、销毁、加载和灵活处理各种场景中的文本搜索要求。
在 ClickHouse 中将 Tantivy 实现为跳过索引
ClickHouse 的跳过索引主要用于加速带有 WHERE 子句的查询。我们实现了一种名为全文搜索 (FTS) 的新跳过索引类型,以 Tantivy 作为底层实现。因此,对于 ClickHouse 中带有 FTS 索引的每个数据分区,我们都会为其构建一个 Tantivy 索引。为了减少每个索引需要存储在数据分区中的段文件数量,MyScaleDB 将这些段文件序列化为两个文件并将其存储在数据分区中。skp_idx_[index_name].meta文件记录每个段文件的名称和偏移量,而skp_idx_[index_name].data文件存储每个段文件的原始数据。
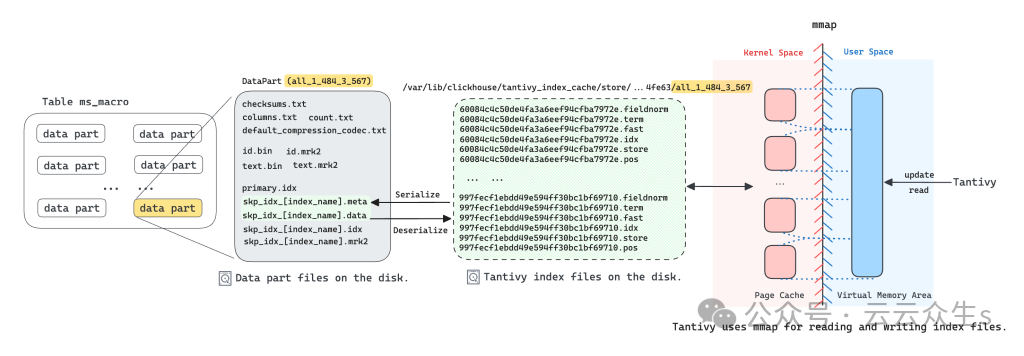
Tantivy 利用内存映射 (mmap) 访问段文件。这种方法不仅提高了并发搜索速度,还提高了索引构建效率。由于 Tantivy 无法直接将skp_idx_[index_name].data文件映射到内存,因此当用户发起需要 FTS 索引的查询时,MyScaleDB 将索引文件(.meta 和 .data)反序列化为 Tantivy 段文件到临时目录并加载 Tantivy 索引。Tantivy 通过内存映射加载这些反序列化的段文件,以便执行各种类型的文本搜索。因此,用户发起的初始查询请求可能需要几秒钟才能完成。
在我们的托管服务中,我们将 Tantivy 的段索引文件存储在 NVMe SSD 上。这减少了 I/O 等待时间,并提高了在需要随机访问和处理页面错误异常的情况下 mmap 的性能。
增强 ClickHouse 的原生文本搜索功能
当对包含 FTS 索引的列发起带有过滤条件的请求时,MyScaleDB 首先访问 FTS 索引。它检索满足 SQL 过滤条件的列的所有行 ID,并将这些行 ID 存储在称为roaring bitmap的高级位图数据结构中。在遍历粒度时,它确定粒度的行 ID 范围是否与位图相交,指示是否可以删除粒度。最终,MyScaleDB 仅访问未被删除的粒度,从而实现查询加速。
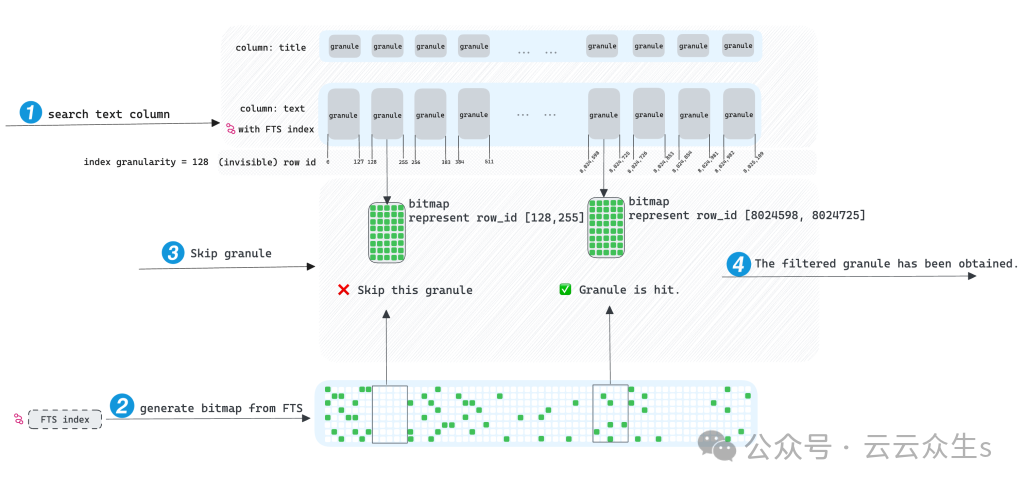
理想情况下,跳过索引确实会加速查询,但我们发现它的效果有限。如果搜索词出现在几乎所有粒度中,则 MyScaleDB 会跳过少量粒度。这需要访问大量粒度进行查询,在这种情况下,跳过索引无效。
使用 TextSearch 解决低效率问题
为了解决跳过索引的低效率问题并充分利用 Tantivy 的全文搜索功能,我们将 TextSearch 函数纳入 MyScaleDB。此函数允许用户执行模糊文本检索请求并获取按 BM25 分数相关性排序的一组文档。此外,用户可以在 TextSearch 函数中使用自然语言查询,大大降低了 SQL 编写的复杂性。
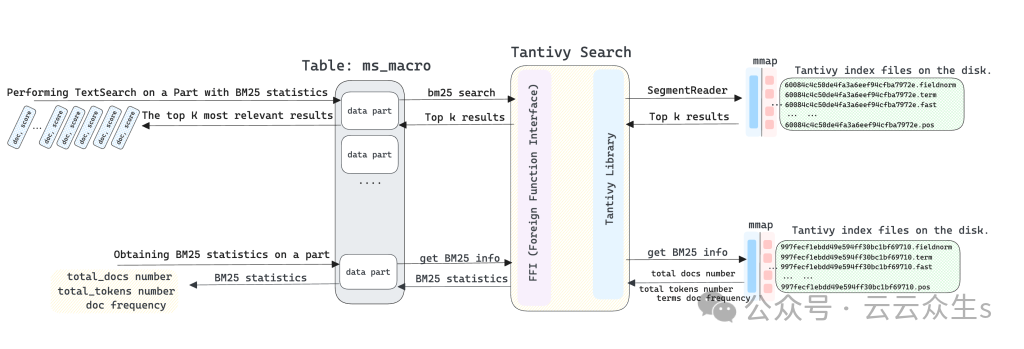
TextSearch 函数在搜索文本时从表中检索前一千个(或k)最相关的结果。在执行方面,MyScaleDB 对所有数据分区并发执行 TextSearch 文本检索。因此,每个分区收集一千个按 BM25 分数排序的最相关结果。MyScaleDB 然后根据 BM25 分数汇总从数据分区获得的结果。最后,它保留前一千个结果,根据用户 SQL 查询中指定的 ORDER BY 和 LIMIT 子句。TextSearch 函数不会直接从数据分区中读取数据。相反,它直接通过 Tantivy 检索索引搜索结果,使其非常快速。
需要注意的是,MyScaleDB 使用多个数据分区来存储数据,每个数据分区负责存储整个表数据的一部分。我们不能简单地对从每个分区获得的相同答案文本对应的 BM25 分数求平均值并对其进行排序。这是因为每个分区在计算 BM25 分数时只考虑当前分区中的“总文档数”、“总标记数”和“文档频率”,而不考虑其他分区中其他与 BM25 算法相关的参数。因此,这会导致最终合并结果的准确性下降。
为了解决这个问题,我们在发起 TextSearch 查询之前首先计算每个分区中的 BM25 统计信息。然后,我们将它们合并到整个表的逻辑对应 BM25 统计信息中。此外,我们修改了 Tantivy 库以支持使用共享 BM25 信息。这确保了跨多个分区 TextSearch 搜索结果的正确性。
下面是一个使用 TextSearch 函数对 ms_macro 数据集执行基本文本搜索的简单示例。
SELECTid,text,TextSearch(text, 'who is Obama') AS scoreFROM ms_macroORDER BY score DESCLIMIT 5
输出:
| id | text | score |
|---|---|---|
| 27174 | Sasha Obama Biography. Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.44808850 |
| 16433 | Sasha Obama Biography. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.40754756 |
| 4474 | Michelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million. Michelle Obama was born January 17, 1964 in Chicago, Illinois. | 14.88242501 |
| 16431 | Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. | 14.63069194 |
| 9756 | Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $40 million. Michelle Obama was born January 17, 1964 in Chicago, Illinois. She is best known for being the wife of the 44th President of the United States, Barack Obama. She attended Princeton University, graduating cum laude in 1985, and went on to earn a law degree from Harvard Law School in 1988. | 14.23084908 |
性能评估
我们使用clickhouse-benchmark比较了 MyScaleDB 在不同索引下的搜索性能,包括 MyScaleDB 实现的 FTS 索引、ClickHouse 内置的倒排索引以及没有索引的场景。
基准设置
数据集详细信息
为了测试 TextSearch 性能,我们使用了 Microsoft 提供的ms_macro 数据集。ms_macro 数据集包含 8,841,823 条文本记录,我们将其转换为 parquet 格式以便轻松导入 MyScaleDB。此外,我们创建了一组 SQL 文件,用于根据不同的词频测试搜索性能。我们使用的数据集通过 S3 公开提供:
- ms_macro_text.parquet:1.6GB
- ms_macro_query_files.tar.gz:5.8MB
ms_macro_query_files.tar.gz 文件包含此测试中使用的所有 SQL 文件。每个 SQL 文件的名称表示 ms_macro 数据集中搜索词的频率以及 SQL 文件中包含的查询数量。例如,ms_macro_count_hastoken_100_100k.sql 文件包含 100,000 个查询,并且每个查询中的单词在数据集中出现 100 次。
以下是 hasToken 和 TextSearch 查询的示例:
SELECT count(*) FROM ms_macro WHERE hasToken(text, 'Crimp');SELECT count(*) FROM (SELECT TextSearch(text, 'Crimp') AS scoreFROM ms_macro ORDER BY score DESC LIMIT 10000000) as subquery;
测试环境
尽管我们的测试环境有 64GB 内存,但 MyScaleDB 在测试期间的内存消耗仍然保持在 2.5GB 左右。
| 项目 | 值 |
|---|---|
| 系统版本 | Ubuntu 22.04.3 LTS |
| CPU | 16 核(AMD Ryzen 9 6900HX) |
| 内存速度 | 64GB |
| 磁盘 | 512GB NVMe SSD |
| MyScaleDB | v1.5 |
导入数据
要导入数据,请为 ms_macro 数据集创建一个表:
CREATE TABLE default.ms_macro(`id` UInt64,`text` String)ENGINE = MergeTreeORDER BY idSETTINGS index_granularity = 128;
直接从 S3 导入数据到 MyScaleDB:
INSERT INTO default.ms_macroSELECT * FROMs3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/ms_macro_text.parquet','Parquet');
将 ms_macro 的数据部分合并为一个以提高搜索速度。请注意,此操作是可选的。
OPTIMIZE TABLE default.ms_macro final;SELECT count(*) FROM system.parts WHERE table = 'ms_macro';
输出:
验证 ms_macro 包含 8,841,823 条记录:
SELECT count(*) FROM default.ms_macro;输出:
| count() |
|---|
| 8841823 |
创建索引
我们评估了三种类型的索引的性能:FTS、倒排和无(无索引的情况)。
- FTS 索引
-- Ensure that when creating the FTS index, no other index exists on the text column of ms_macro.ALTER TABLE default.ms_macro DROP INDEX IF EXISTS fts_idx;ALTER TABLE default.ms_macro ADD INDEX fts_idx text TYPE fts;ALTER TABLE default.ms_macro MATERIALIZE INDEX fts_idx;
- 倒排索引
-- Ensure that when creating the Inverted index, no other index exists on the text column of ms_macro.ALTER TABLE default.ms_macro DROP INDEX IF EXISTS inverted_idx;ALTER TABLE default.ms_macro ADD INDEX inverted_idx text TYPE inverted;ALTER TABLE default.ms_macro MATERIALIZE INDEX inverted_idx;
- 无索引:确保 ms_macro 的文本列上没有其他索引。
运行基准测试
使用clickhouse-benchmark执行压力测试。有关更多使用说明,请参阅ClickHouse 文档。
clickhouse-benchmark -c 8 --timelimit=60 --randomize --log_queries=0 --delay=0 < ms_macro_count_hastoken_100_100k.sql -h 127.0.0.1 --port 9000 评估结果

当搜索词的频率较高(100,000 到 100 万)时,跳过索引的加速效果非常有限(与未建立索引时的性能相比,仅提高了十倍)。但是,当搜索词的频率较低(100 到 1,000)时,跳过索引可以实现显著的加速(与未建立索引时的性能相比,提高了高达一百倍)。
另一方面,TextSearch函数在所有场景中始终优于跳过索引和倒排索引。这是因为TextSearch直接利用了 Tantivy 的全文搜索功能,绕过了扫描颗粒的需要,而是直接从索引中检索结果。这导致了更快速、更高效的搜索过程。
结论
将 Tantivy 集成到 MyScaleDB 中显著增强了其文本搜索功能,使其成为文本数据分析和使用大型语言模型 (LLM) 进行 RAG 的强大工具。通过解决 ClickHouse 的原生文本搜索功能的局限性并引入 BM25 相关性评分、可配置的标记器和自然语言查询等高级功能,MyScaleDB 为复杂的文本搜索需求提供了一个强大且高效的解决方案。
为 Tantivy 实现 C++ 包装器、创建新的跳过索引以及引入TextSearch函数都促成了这一改进。这些增强不仅提升了 MyScaleDB 的性能,还扩展了其在各种应用程序中进行高效且准确的文本搜索的用例。
有关如何使用TextSearch函数和其他功能的更多信息,请参阅我们关于文本搜索和混合搜索的文
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/80954.html