
未来的某一天
未来某一天,人工智能终于实现了对人类所有数据的融会贯通。它可以快速解决一些数学难题,精准诊断一些疾病,甚至优化全球供应链。人类一度认为,这个AI已经达到了全知全能的境界。然而,当科学家问它一些数据无法支撑的问题时,它却无法给出答案。
正如科幻大师艾萨克·阿西莫夫的科幻故事《最后的问题》所描述的那样,计算机随着时间推移变得越来越强大,但仍然无法回答最终的问题:“宇宙的意义是什么?”
—
仅仅是更多的数据就够了么?
在最近一次Joel Hellermark对“AI教父”Geoffrey Hinton的采访中,Hinton提到,AI不仅仅是在预测下一个token,而是建立了对前文的理解(Ilya Sutskever也持有类似观点,见相关访谈)。他认为预测的前提是通过压缩构建了一个世界模型。此外,即使喂给它50%的错误数据,AI仍然可以形成99%准确的判断。
这里我们假设Hinton的观点都是成立的,那我们可以通过next token prediction,甚至基于人类投喂数据的训练方式是的AI从而没有上限了么?

AI的洞穴之困
当前我们训练AI的方式,类似于柏拉图的洞穴理论。AI被囚禁在洞穴里,通过人类的数据投喂来理解世界。它确实可以通过推理来纠正逻辑不自洽的部分,但许多观念或假说在通过更多观察数据证伪前,都是逻辑自洽的。比如平面地球说(即使在今天,还有不少人相信),比如绝对时空观。
 地平说的逻辑自洽性挺好的,不是那么容易被驳倒。2017年,「地平说」专家在美国北卡罗莱纳州举行了第一届「平面地球国际会议」(Flat Earth International Conference),针对对「地球是平的」这个学说出作解释。
地平说的逻辑自洽性挺好的,不是那么容易被驳倒。2017年,「地平说」专家在美国北卡罗莱纳州举行了第一届「平面地球国际会议」(Flat Earth International Conference),针对对「地球是平的」这个学说出作解释。
AI当前在没有自己控制探索并验证假说或观点的能力下,通过对人类数据的“道听途说”获取的智能是有限的。它只能依赖现有数据进行推理和判断,但无法主动去探索和验证新的知识。
 人类数据只是真实世界的采样,不足但逻辑自洽的样本可能让AI认为是真理
人类数据只是真实世界的采样,不足但逻辑自洽的样本可能让AI认为是真理
—
通过人类现有数据构建的世界模型的局限性
“当大家觉得一个新东西有道理,那多半就不是颠覆性的。”
真正有颠覆性的创新,往往在初期看起来都是错的,因为任何现有的数据都无法推导出那个结果。科学和知识的扩展不仅需要大胆的假说,还需要收集新的观察数据以及进行严格的验证。这里有三个经典例子:
- 爱因斯坦的相对论:
- 当爱因斯坦提出相对论时,许多人认为它没有道理,因为它挑战了当时广泛接受的牛顿力学。相对论提出的时间和空间的相对性,完全颠覆了符合人类认知的绝对时空观,而且这在当时的数据和观测下是无法推导出的。然而,随着实验和进一步观测的进行,相对论得到了验证,并成为现代物理学的基石。
- 量子力学:
- 量子力学的发展初期,同样遭遇了广泛的质疑。就连爱因斯坦也说:上帝不扔骰子。它提出的微观粒子行为的概率性和不确定性,完全违反了经典物理学的直觉。在没有更多实验数据支持的情况下,量子力学的许多预测看起来是荒谬的。但经过大量实验验证,这一理论不仅被证明是正确的,还开启了微观世界的新视野,推动了半导体技术和现代电子工业的发展。
- 杨振宁和李政道提出的宇称不守恒:
- 在1956年之前,物理学家普遍认为宇宙在各个属性上都是对称的,即宇称守恒。杨振宁和李政道提出了宇称不守恒的假设,这一假设颠覆了人们对宇称对称性的理解,并引发了广泛的质疑。许多著名科学家对此表示强烈反对,甚至打赌认为这一假设是错误的。然而,当吴健雄通过实验验证了宇称不守恒后,这一发现震惊了物理学界,并为他们赢得了诺贝尔奖。
然而,依赖现有数据的AI在面对复杂、多变和未曾预见的现实世界时,是否真的能够构建出准确无误的判断?这就引出了我们对数据局限性的探讨。
—
数据的局限性
在了解了AI通过人类现有数据构建世界模型的潜在问题之后,我们需要更深入地探讨数据本身的局限性。数据的质量和来源会直接影响AI的表现,以下是几个关键的局限性:
- 数据多数性:AI可能会倾向于认为支持者更多的观点是正确的,但多数意见并不总是正确的。例如,中世纪时大多数人相信地心说是正确的。当时的观测手段确实也让这一理论逻辑自洽。即使有偏差的地方,也可以有奥卡姆剃刀解决掉。这说明,AI如果仅凭数据的多数性来判断正确与否,可能会得出错误的结论。
- 权威性和可信度:权威观点也不一定是正确的,例如二十世纪六十年代美国糖业协会资助的研究将心血管疾病的主要原因归咎于脂肪摄入,而非糖。如果AI仅依赖于权威来源的数据进行判断,就可能被这些操纵的数据误导,导致错误的判断和决策。
- 未知的未知:模型对数据做的是插值(interpolation),最终可以生成数据闭包中的所有样本点。如果插值的点正好有用,那就是“创新”;如果没有用,那就是“幻觉”(hallucination)。对于闭包之外的数据,AI则无能为力。这意味着,AI在面对全新或未知的情况时,可能无法提供有意义的答案。
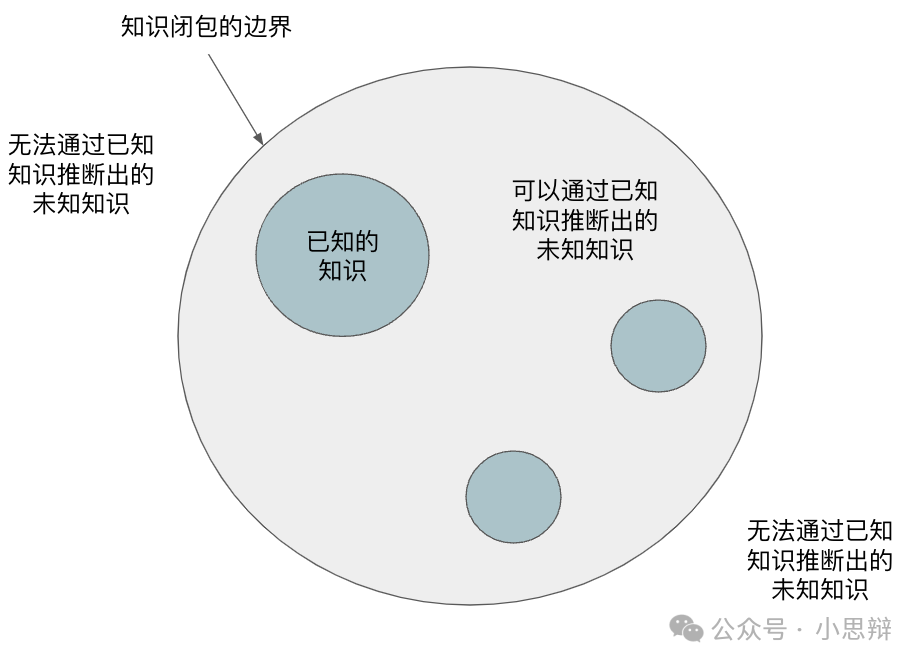 模型可以通过拟合的方式根据已有知识推出未知知识,但是知识的闭包不是无限大的,总有一些存在但在知识闭包之外的无法用现有知识组合而成的知识。这种未知的未知是拟合无法解决的。
模型可以通过拟合的方式根据已有知识推出未知知识,但是知识的闭包不是无限大的,总有一些存在但在知识闭包之外的无法用现有知识组合而成的知识。这种未知的未知是拟合无法解决的。
- 缺乏自主验证:AI缺乏自主实验和验证的能力,只能依赖现有数据和观点,这使得它在面对误导信息时无法进行独立验证。例如,如果AI接收到大量错误或偏颇的数据,它将难以通过自身能力去验证这些信息的真实性。
这些局限性表明,尽管AI可以处理大量数据并从中提取有价值的信息,但它的智能水平仍然受到数据本身质量和多样性的限制。为了让AI更加接近真正的智能,我们可能需要探索新的方法来增强它的自主学习和验证能力。这也引出了我们对未来可能解决方案的探讨。
—
一些可能通向曙光的方向
尽管AI目前受限于数据的局限性,但未来仍有一些途径可以帮助它突破这些限制,实现更高层次的智能。
- 对外部工具的调用(Tool Use):通过调用外部观测工具,AI可以获取更多样化和实时更新的数据。这不仅有助于提高数据的准确性和多样性,还能使AI在更广泛的环境中进行学习和应用。例如,利用卫星数据进行环境监测,或使用先进的传感器来获取精细的物理世界数据。
- 具身智能(Embodied AI):具身智能,即让AI以人的视角与世界互动,是仿生学的一部分。通过赋予AI感知和行动能力,它可以直接与物理世界进行交互,从而获取第一手数据。这不仅增强了AI对环境的理解,还使得它的行为更容易被人类理解和接受。例如,仿生机器人可以通过探索和操作物理对象来学习新的技能和知识。
- 强化学习(Reinforcement Learning):强化学习是一种通过奖励和惩罚机制来让AI不断改进的学习方法。**人类需要终身学习,AI也不例外。**通过持续学习和自我改进,AI可以不断适应新的环境和挑战,保持知识的更新和能力的提升。例如,自主驾驶汽车通过不断的道路测试和学习,可以提高其驾驶技能和安全性。
这些方法不仅有助于弥补当前AI的不足,还为其未来的发展指明了方向。通过摆脱对人类数据的完全依赖,AI能够实现自我探索和验证,进而突破现有的局限性,迈向更高层次的智能。
—
写在最后
AI在掌握了人类所有数据后,仍然面临着数据质量、数据多样性以及自主验证能力的诸多挑战。只有通过摆脱这些限制,实现自我探索与验证,AI才能真正突破现有的智能水平,达到全新的高度。这不仅需要技术的进步,更需要对AI应用方式和方法的创新和突破。未来,我们期待看到AI在更广泛、更复杂的环境中展现出真正的智能,为人类社会带来更多的价值和改变。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/81378.html
