

迭代器
迭代就是重复,但是每一次重复都是在上一次的基础上做的,跟上一次的结果是有关联的,并不是单纯的重复。

每一次重复,num的值都是基于上一次num的值计算之后的结果,这就叫迭代,而迭代其实就是迭代取值(或者说重复取值)的工具,并且每一次取值都和上一次是有关联的。
列表的重复取值:

用while循环实现了一个迭代取值的功能,但是这个迭代取值是基于索引的叠加,列表用这种方式没问题,元组、字符串也可以,但是字典和集合也有多个值,它们也有这种重复取值的场景,可是字典、集合,还有用open功能打开的文件它们没有索引,所以这种迭代取值的方式就有局限性。它不适用于没有索引的数据类型。python为了解决这种局限性,它就必须提供一种能够不依赖于索引的迭代取值方式,这就是迭代器。
可迭代对象
只要是可以被for循环遍历的就是可迭代对象,但是这样不够准确。准确的说法应该是:只要内置有_iter_方法的就可以称之为可迭代对象。
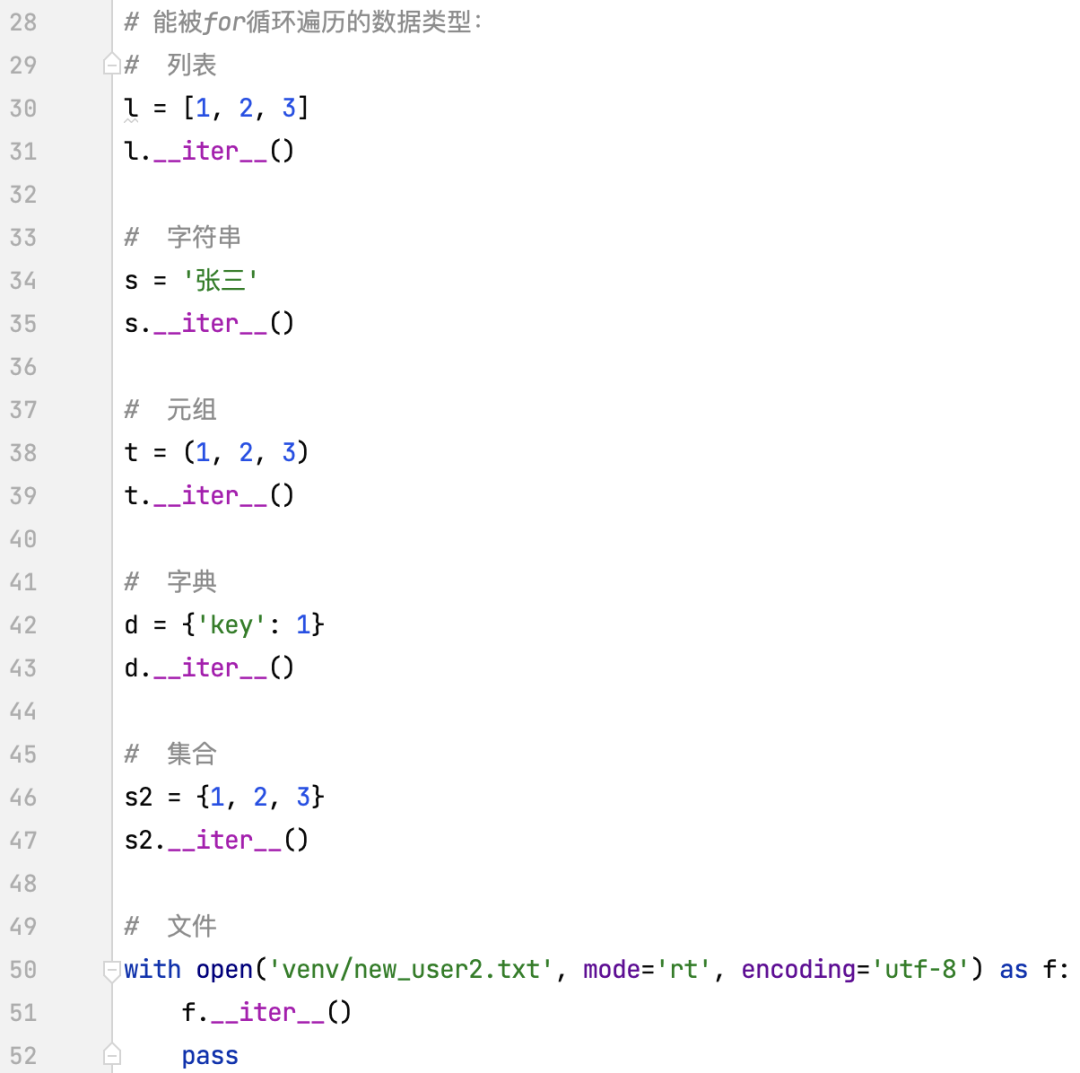
它们都有_iter_方法,这些就叫可迭代对象,可以迭代的对象,这些数据类型都有_iter_方法,这个_iter_就是一个功能,也就是一个函数,是函数就有可能有返回值,用一个字典来看它的返回值是什么:

调用这个字典的_iter_方法,调用完后会有一个返回值,用res接着,print一下res。
iterator,这是一个迭代器,所以当调用可迭代对象下的_iter_方法后,就会得到一个迭代器,现在可以这样描述可迭代对象:可以转换成迭代器的对象,就称之为可迭代对象。
python设计迭代器的原因,是为了寻求一种不依赖索引也能够进行迭代取值的方案,所以python给那些没有索引的数据类型都内置了一个功能,叫_iter_功能,如果不想或者不能依赖索引进行迭代取值,就可以调用python提供的这个功能就可以了,只要调用了这个_iter_方法,python就会把这个d转换成迭代器对象。
迭代器对象不依赖索引进行迭代取值
现在res 就是一个迭代器对象,只要是迭代器对象,它下面就有一个_next_方法,调用这个_next_方法,就是在取它的值。每执行一次这个_next_方法,就会得到一个返回值,打印一下:

拿到了字典的第一个 key。
再调用一次,拿到了字典的第二个key,接着又调用一次,拿到了第三个key,调用了三次_next_,这个字典现在被取完了,第四次再调用的时候,就会抛出一个StopIteration的异常。

迭代器对象的两个基本的方法:
__iter__():返回迭代器对象本身。
__next__():返回迭代器的下一个元素。
当迭代器的所有元素都被访问完毕后,__next__() 方法会抛出一个 StopIteration 异常,表示迭代结束。
用while循环进行迭代取值
对于字典这种没有索引的数据类型,如果没有for循环的话,是没有办法实现迭代取值的,现在学习了一种不依赖索引的迭代取值方式,就是利用迭代器。试试看怎么用while循环对这个没有索引的字典进行迭代取值。
首先它提供了一个_iter_方法,只要调用了_iter_方法,就会得到一个它的迭代器版本,有了这个迭代器,就可以重复调用迭代器的_next_方法,就实现了迭代取值的需求。现在不需要这样一行一行的调用,因为如果这个字典有几十个键值对,这样写就不太现实了。

运行结果确实是把值遍历出来了,但是抛出了StopIteration这个异常。
要避免这种情况发生,就要用到另一个知识点,就是在print前面加一个try冒号,然后把可能会抛异常的代码缩进进去,后面再来一个except用来捕捉异常,捕捉的这个异常名就叫StopIteration,再写一个冒号,接着下面就是写捕捉到异常之后做什么,写一个break ,当捕捉到StopIteration这个异常之后,就结束掉循环。

现在就用while循环不依赖索引实现了迭代取值。
把这段代码再复制一遍再运行,看它能否进行多次循环取值:

结果还是只有一次的数据,第二次循环什么都没有取出来。
因为在Python中,迭代器是一次性的。一旦迭代器耗尽了所有元素,它就会抛出一个StopIteration异常,并且之后再次调用__next__()方法将不会恢复迭代,而是继续抛出StopIteration异常。
由于第一次循环已经耗尽了迭代器中的所有元素,迭代器已经处于结束状态。因此,再次调用res.__next__()会立即抛出StopIteration异常,导致循环什么也不打印并立即结束。
如果还想进行第二次遍历,就只能再调用一下d下面的_iter_方法,这样,第二次循环就可以取到值了。

for循环原理
可迭代对象就是内置有_iter_()方法的对象,当可迭代对象调用_iter_()方法之后,就会得到一个它的迭代器版本,也就是迭代器对象。
迭代器对象:内置有_next_方法,并且还内置有_iter_()方法的对象,。
当迭代对象调用_iter_()方法之后,就会得到迭代器的下一个值,迭代器对象调用_iter_()方法,得到的是迭代器本身(和没调一样),验证一下:
定义一个集合s = {1,2,3},它下面有_iter_方法,但是没有_next_方法,因为_next_()方法是迭代器对象才有的。

打印验证res._iter_()是不是 is res:

结果是True,说明迭代器对象调完_iter_()方法之后,确实得到的还是它本身。它调了_iter_()方法和没调一样,python 之所以这么设计,是为了让for循环的工作原理统一起来。就是说不管for循环的in后面跟的是可迭代对象,还是迭代器对象,都可以采用同一套运行机制。
如果for i in 一个可迭代对象,它会去调用这个可迭代对象的_iter_()方法,把它转换成一个迭代器;如果可迭代对象这里本身放的就是一个迭代器对象,那么for循环的工作原理不变,还是会去调它的_iter_()方法,拿到的结果也是一个迭代器。

用for循环取值:

相比上面用的while循环的方式for循环取值简单多了。
用while循环实现迭代取值,还要先把它转换成迭代器对象,然后调用_next_()方法,还得自己捕捉异常,用for循环两行代码就直接搞定,它背后的实现过程:
第 1 步,调用对象的_iter_()方法,得到一个它的迭代器版本;
第 2 步,for循环会调用这个迭代器对象的_next_()方法,拿到一个返回值,然后把这个返回值赋值给k;
第 3 步,循环执行第二步,直到抛出了StopIteration异常,for循环会自动捕捉异常,然后结束循环。
for循环做的这些事,其实就是前面写的try下面的这段代码做的事,这也进一步验证了前面所学的 for循环可以称之为迭代循环,而while循环称之为条件循环。
for 循环做的事while循环都可以做,但是在循环取值这件事上,for循环比while循环更加简洁。
迭代器补充
可迭代对象就是内置有_iter_()方法的对象,而迭代器对象就是内置有_next_()方法、并且还内置有_iter_()方法的对象,既然迭代器对象也有_iter_()方法,那么是不是迭代器对象也是可迭代对象,因为它有_iter_()方法,但不能说可迭代对象是迭代器对象,因为迭代器对象要满足两点:既要有_iter_()方法,又要有_next_()方法才行。
前面的数据类型,列表、字符串、元组、字典和集合都有_iter_()方法,但是没有_next_()方法,而文件(文件对象)是有_iter_()方法和_next_()方法的,所以说文件其实是一个迭代器对象。
类型转换:
list(‘张三’)
tuple(‘张三’)
这两个功能背后其实就相当于调用了一个 for循环,原理和for循环一样,然后把遍历出来的值放在列表和元组里面,for循环原理的三个步骤也是它们的工作原理。
先调用这个字符串下面的_iter_()方法,转成一个迭代器,然后调用迭代器下面的_next_()方法,拿到返回值,把返回值放到列表里面,接着循环第二步,直到抛出了StopIteration异常。
list()的参数提示是iterable,就是可迭代对象,传的参数必须是可迭代的。
打开pycharm终端,然后打开python3 的交互式环境,定义一个字典,在后面点_iter_(),敲回车。运行结果:

说明它是可迭代对象,但是没有_next_(),说明它是被做成了可迭代对象。
字典还有.keys()和.items(),它们和values一样,都是可迭代对象。
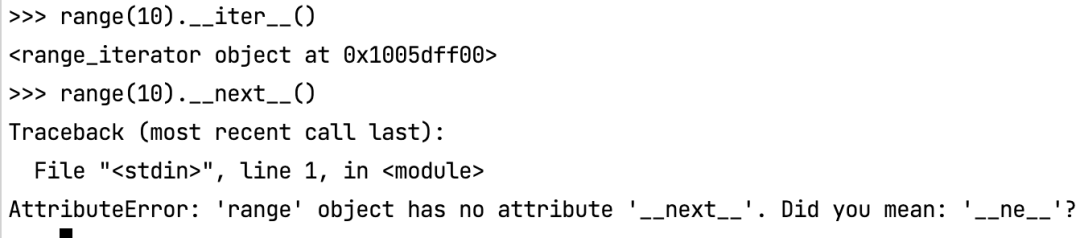
range(10) 在 python3里面是一个可迭代对象,并不是一个迭代器对象,但是在python2 里面,这些功能得到的结果都是列表。但是列表可以说是可迭代对象,而不能说可迭代对象就是列表字典这种具体的数据类型,因为这个range的结果本身是没有任何值的。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/81443.html