
Apache Druid 是一个实时分析数据库,专为快速查询和分析大型数据集(“OLAP”查询)而设计。
Druid最常用作数据库,支持实时摄取、高查询性能、高稳定性等应用场景。 例如,Druid 经常被用作数据源,为图分析工具提供数据,或者当你有一个需要高收敛和高并发的后端API 时。 同时,Druid也非常适合面向事件的数据。
通常使用Druid 作为数据源的系统包括:
点击流量分析(Web 或移动分析) 网络监控分析(网络性能监控) 服务器存储指标供应链分析(生产数据指标) 应用程序性能指标数字广告分析业务集成/OLAPDruid 的核心架构集成了数据仓库和系列数据库概念和日志检索系统。
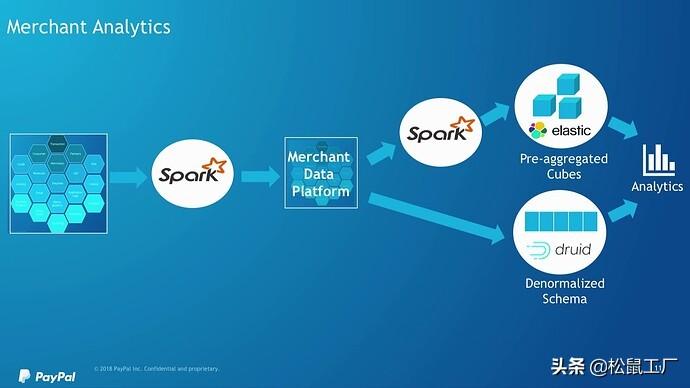
最大分辨率默认1280720 83.7 KB
如果您对上面列出的各种数据类型和数据库不是很熟悉,我们建议您进行一些搜索以了解所提供的相关定义和功能。
德鲁伊的主要特点包括:
面向列的存储格式Druid 使用面向列的存储。这意味着某些数据查询只需要查询某些列。 这种设计显着提升了子列查询场景的性能。此外,每列数据都针对特定数据类型进行优化存储,以支持快速扫描和聚合。 Druid 是一个可扩展的分布式系统,通常部署在数十到数百台服务器的集群中,每秒提供数百万个数据导入并处理数万亿个数据点,同时实现从100 毫秒到数秒的查询延迟。高性能并发(大规模并行)Druid 可以跨集群并行处理查询。实时或批量摄取Druid可以实时导入摄取的数据库(导入和摄取的数据立即可用于查询)或批量摄取的数据。自愈、自平衡、易操作(Self-healing, self-balancing, and easy to操作) 集群运维操作人员只需添加或删除服务即可扩展集群,集群自动不会出现任何问题重新平衡时会发生停机。 如果任何Druid服务器发生故障,系统会自动绕过损坏的节点以保持不间断运行。 Druid 设计为24/7 运行,无需任何计划停机(例如配置更改或软件更新)。云原生、容错架构,无数据丢失(Cloud-native,容错架构,无数据丢失)当Druid检索数据时,它会将其安全地存储在深度存储中,通常是云存储。HDFS 或共享文件系统)。如果一项Druid 服务出现故障,可以从深度存储中恢复数据。在仅影响少数Druid 服务的有限中断的情况下,保存的副本可确保您可以在系统恢复期间运行查询。快速过滤索引Druid 使用Roaring 或CONCISE 压缩位图索引,以创建支持跨多个列快速过滤和搜索的索引。基于时间的分区Druid 首先按时间对数据进行分区,也可以根据其他字段进行分区。 这意味着基于时间的查询仅访问与查询时间范围匹配的分区,从而显着提高基于时间的数据处理性能。近似算法Druid 应用近似计数判别、近似排序以及近似直方图和分位数计算的算法。 这些算法的内存使用量有限,并且通常比精确计算快得多。在精度比速度更重要的场景下,Druid 还可以通过精确计数来提供准确的排名。摄取期间自动汇总Druid 支持在数据摄取阶段进行可选的数据汇总,这可以部分预聚合数据,可以节省大量成本并提高性能。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/82334.html
