
接下来我们来说一下Druid的数据流。流程图有许多节点,每个节点都有独特的作用。中间有一个Zookeeper,每个节点都或多或少地与其连接,每个节点不做任何强关联工作,只需要与Zookeeper同步即可。从左到右,数据写入过程包括离线数据和批量数据。
中心节点代理是一个查询节点,它向外界提供REST接口,接受来自外部客户端的查询,并将这些查询转发到实时和历史节点。它从这两个节点检索数据,将节点返回给代理,合并数据,然后返回给客户端。这里的broker节点起到转发和合并的作用。合并过程需要指定的内存。我们建议配置相对较大的内存。
历史节点历史节点是处理、存储和查询非实时数据的地方,它只响应代理请求。当您查询数据时,先在本地搜索数据,然后在深层存储中搜索数据。搜索结果返回给代理,不与其他节点关联。它在Zookeeper的管理下提供服务,并使用Zookeeper来监控加载或删除新数据段的信号。该节点消耗大量内存。该节点还建议使用多个节点来分离信息。
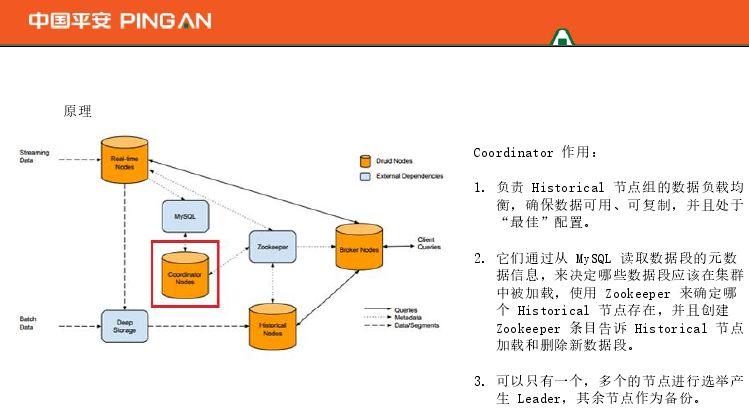
协调器充当管理器,负责一组历史节点的数据负载均衡,以确保数据可用、可复制且处于“最佳”配置。同时,它从My SQL中读取数据段元数据信息,确定哪些数据段加载到集群中,使用Zookeeper判断存在哪些历史节点,并创建Zookeeper条目来告诉节点加载和加载历史节点。删除新的数据段。该节点可以是一个或多个节点来选举领导者,其余节点作为备份。两个节点通常足以满足您的需求。
实时节点Realtime 是数据的实时摄取,负责监控传入的数据流并使它们立即可供内部Druid 系统使用。如果不需要实时加载数据,只需响应broker请求并将数据返回给broker即可删除节点。如果Realtime节点和Historical节点同时返回相同类型的数据,则Broker认为Historical节点的数据是可靠的。一旦数据进入深度存储,Druid 的默认数据就保持不变。节点本身存储数据,当窗口超过一定时间时,将数据转移到深度存储,深度存储将数据提供给历史节点。
MySQL、Zookeeper、Deep Storage 都是Druid 的外部依赖。这用于存储“冷数据”。一是批量数据摄取。另一种是来自实时节点。 ZooKeeper集群:提供集群服务来发现和维护当前的数据拓扑。 My SQL实例:用于维护系统服务所需的数据段元数据(如加载位置)。数据段和每个数据段的元数据。

综上所述,各节点之间职责分工明确,特定节点故障不影响其他节点运行,且易于扩展、容错性高。冷热数据分离,不同数据通过硬件资源进行物理隔离。将查询要求与数据在集群内如何分布的要求分开。防止用户查询请求影响集群内数据分布,避免局部过热,不影响查询性能。没有绝对的主结构,它不仅仅是一个内存数据库,还具有额外的内存映射功能。 Lamada架构可以实时修改数据。如果输入到节点的数据没有被消耗,数据就会被丢弃,并且会出现数据库性能问题。社区中比较成熟的框架都是实时将数据写入Kafka,一次在存储节点,一次在Hadoop。如果数据不完整,Hadoop会执行嵌入操作。数据。
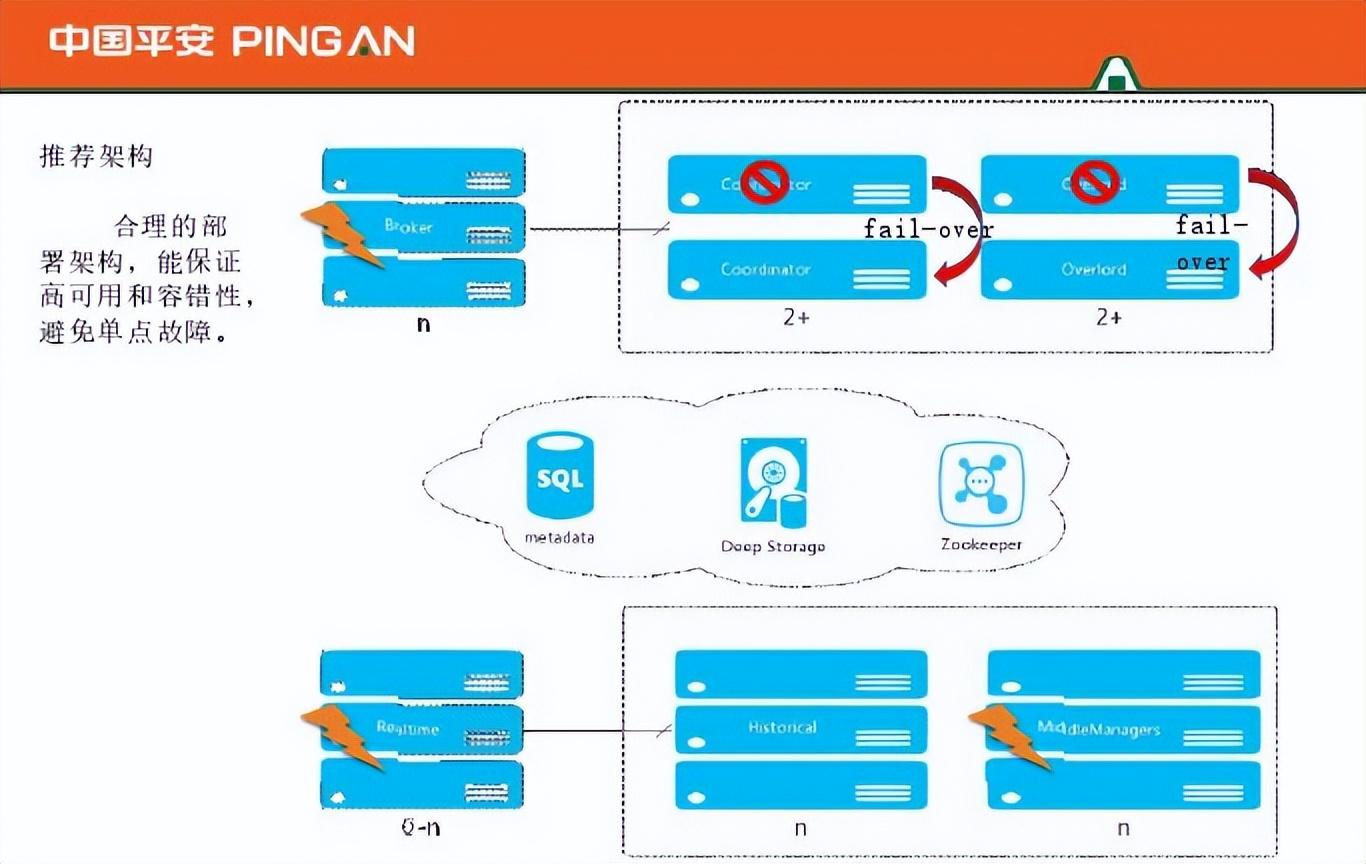
以上是推荐的架构,broker节点较多,最好是两个协调器节点,两个过载节点,其他实时节点尽可能多。在性能方面,也有不同的性能改造。我们的调优经验表明,对于消耗大量内存的broker,建议使用20G到30G的堆内存来释放协调器消耗的IO,因为除了内存之外,它还消耗硬盘。对内存的要求相对较少,只需要满足要求即可。尝试在查询时执行聚合优化,在摄取时执行聚合,并尽可能避免分组。历史和实时分离,协调器和broker分离,在broker中添加Nginx,实现负载均衡和高可用。对于不同的硬件,层次结构被分割,以便历史可以加载不同时间范围的数据。

—
02
BDAS使用场景(功能介绍)
接下来,我们将讨论具体的项目应用。财产/意外伤害保险最初使用Cognos(Oracle)来处理列表报告,但它已经在线10年了。随着数据量的增长和分析处理需求的增加,立方体过大的弊端越来越明显,限制了Cognos,使其无法满足现实操作需求。我们需要实现的第一件事是快速性,第二件事是在行级别拥有完整的列控制。
去年5月份我们把DBAS系统迁移到Druid,9月份我们推出了列表功能,可以直接查看hives上的数据进行业务分析,12月份我们切换到Druid,实现多维度分析功能全面实现。网上有几十个数据源,最大的数据源有数百个维度,单个维度内最大的属性可以达到数亿个。聚合后的单表有数十亿行记录,单个数据源最大几十GB,日均访问量主要用于产险中的内部分析,并发峰值时有发生。数百个案例,平均响应时间为2秒。


接下来我们展示一个HDFS的使用场景。第一种场景允许用户在某些条件(连续衰减)下查看数据的概览,通常使用top-N 查询。秒。响应方式是前端一次拖动一个维度,后端缓存最后的结果,最后只查询几个维度。 Top N 查询中的第一个查询仅检查一个维度。添加维度会将Redis 中最后缓存的结果添加到下一个维度,从而快速增加多维性并显着减慢查询速度。
当我们引入单线程时,我们考虑了两种方法。第一种方法是依次检查N维中的前N个,然后构造M*N*P个多线程。这种方法的查询速度非常快。可能是top N次,所以问题是顺序不保证。第二种方法采用递归方法,由线程池统一执行(线程?没有)。更细粒度的缓存:比如从维度A、维度A+维度B变为维度A+A1、维度A+A2、维度A+A1+维度B+B1,可以充分利用Druid的升序和降序,以及N*M顶N次,可能需要更多时间。
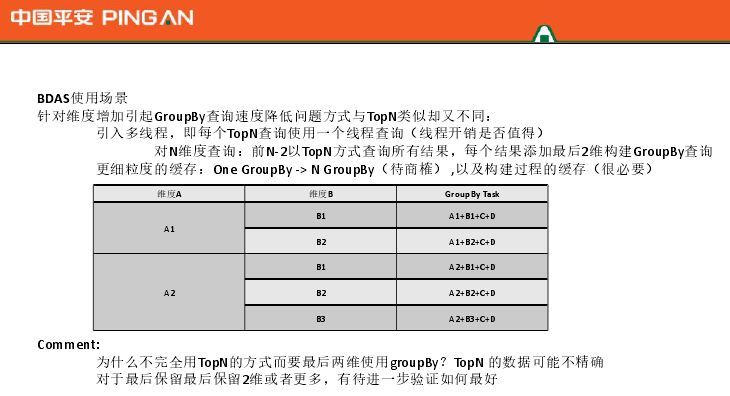
第二种情况是交叉表。分析师需要查看完整的数据,而不是摘要数据。起初,无论你检查多少个维度,你仍然可以组装它,但一旦你有超过4或5个维度,它就变得非常低效。改进的方法还使用了多线程。之前的结构基本都是基于top-N的方式,A1+B1+C维度在查询时有缓存策略。它使用块缓存,消除了网络传输。有两种情况。一个使用top N,另一个使用group by。两者的区别在于,Top N 可能不准确,但Top 1000 可以保证前900 个是准确的。
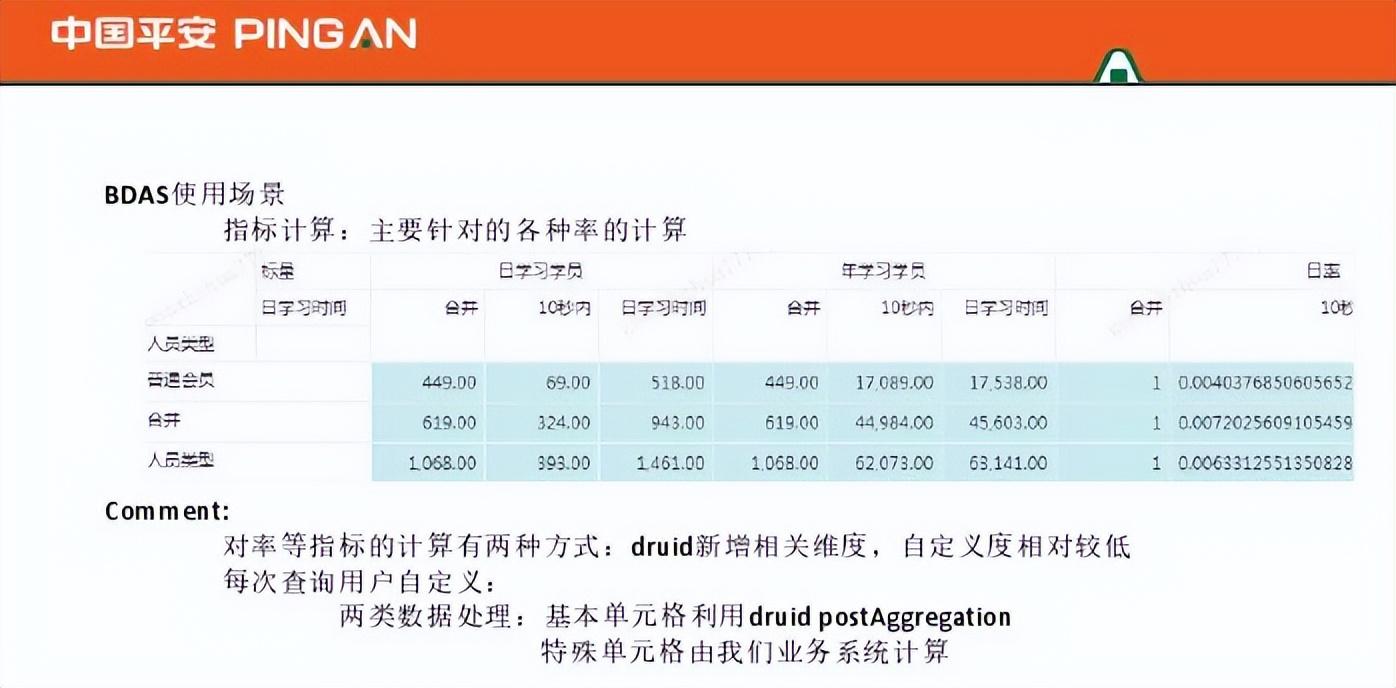
第三种场景是指标计算。第一种方法是在进入德鲁伊之前计算好并存储在蜂巢中,但这非常昂贵。第二种方法是使用Druid 进行计算,它允许您自定义每个查询以获得更快的结果。
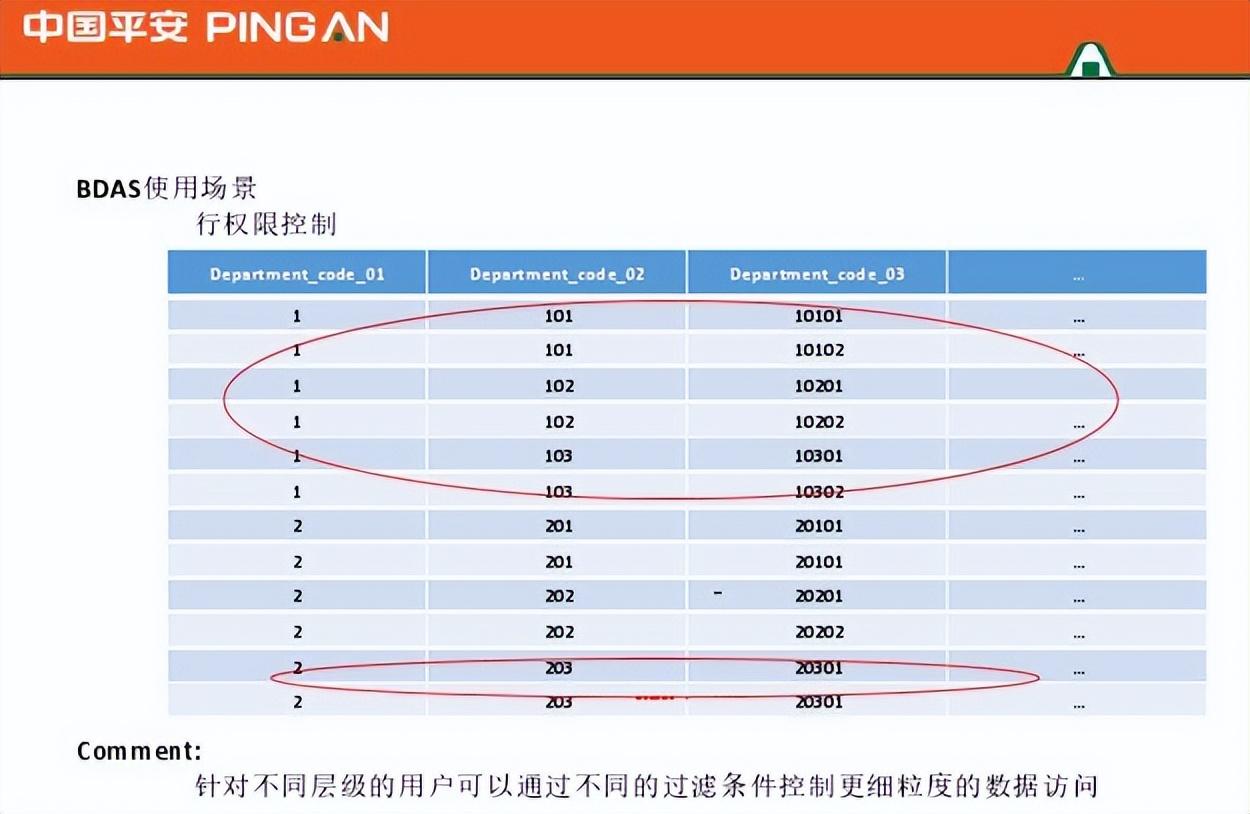
合并和隐藏维度意味着用户统一对待一些属性值。事实上,更好的方法是减少一维。第四,提供完整的生产线控制。这只能通过访问用户帐户来实现,因此过滤后每个数据源将有四列。
今天的分享就到这里,谢谢大家。
01/分享嘉宾
李凯波、管志华老师在大数据领域拥有多年的工作经验,对bdas系统、Druid数据库系统等有深入的了解,专注于大数据技术应用的研究和开发。在金融领域。
02/报名观看直播,免费领取PPT

03/关于我们
DataFun:专注于大数据和人工智能技术应用的分享与交流。自2017年推出以来,我们已在北京、上海、深圳、杭州等城市举办了100多场线下和100多场线上沙龙、论坛、峰会,邀请了2000多名专家学者参与分享。其公众号DataFunTalk累计产出原创文章700多篇,阅读量超过100万人,精准粉丝超过14万。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/82357.html