
零、类图流程预览
本文以getConnection 作为入口点来探索druid 中的连接生命周期。一般流程分为以下几个主要流程:
 张图片
张图片
主流程1:获取连接流程
首先我们看一下从入口连接时的操作。
上面是建立连接时的流程图。首先调用init初始化连接池,最后运行getConnectionDirect获取实际的连接对象。当打开testOnBorrow时,每次都会测试连接的可用性(这也是为什么官方不鼓励将testOnBorrow设置为true,因为它会影响性能。这里的测试是测试连接是否持续很长时间)。 mysql服务器将被断开。通常情况下,mysql服务器有8小时的长连接keepalive时间,如果连接使用超过keepalive时间,使用一次后就会刷新。距离上次使用已经过去很长时间了,所以当你再次使用它时,它将不再能够与MySQL服务器通信)。
如果testOnBorrow没有设置为true,则勾选testwhileIdle(官方建议设置该字段为true,默认值也是true)。在检查过程中,判断当前连接对象是否已存在一段时间。如果最后使用的时间超过了指定的检查,则这个检查时间由timeBetweenEvictionRunsMillis控制,默认为60秒。
每个连接对象都会记录上次使用的时间并捕获空闲时间。此后,将执行连接可用性检查。与testOnBorrow 相比,每次检查都会显着提高性能。如果测试后将该值设置为false,则默认值为true,因此使用时无需关注该值。 testOnBorrow 也设置为false,并且数据库服务器继续运行很长时间。如果60秒内没有使用连接,超过60秒会报连接错误。
使用testConnectionInternal 方法测试长连接,如果结果为false,则证明该连接被服务器断开或存在其他网络原因导致连接不可用,可以使用DiscardConnection 来回收该连接(相应的)。 )。由于连接正在被破坏,因此该方法启动主进程3来检查是否需要新的连接。)整个过程无限循环运行,直到获得空闲连接或者超过重试限制错误终止(如果连接没有超过连接池限制,则最多可以重试一次(默认为重试一次,这可以通过notFullTimeoutRetryCount 属性(控制)来确定。所以当发生连接等待时,如果连接池未满,则最大等待时间为2maxWait(这个应该检查)。
特别说明
为了保证性能,将testOnBorrow 设置为true 或对一些与长时间运行的发现相关的配置使用druid 的默认配置以确保最佳性能,不建议这样做。检查每60秒一次,所以如果你想确定而不启用testOnBorrow,你应该检查连接的mysql服务器的长连接keepalive时间(默认是8小时,但你的DBA可能会设置时间)。如果这个时间小于60 秒,则需要手动设置timeBetweenEvictionRunsMillis,因为在测试环境中它应该比这个短得多。如果您的mysql服务器有8小时或更长的长连接时间,请使用默认值。
特别说明
最小空闲连接数minIdle和池中最大连接数maxActive,防止一些QPS高的服务和网关服务在长时间运行的MySQL服务器连接足够的情况下,保持不变,增加它。如有必要,并启用keepAlive 以进行连接活动检查(请参阅流程4.1)。这可以防止以后动态发生新连接(建立连接仍然相对简单)。由于操作繁重,建议先应用所有连接(必填连接,个人意见,仅供参考)。然而,与管理后端一样,长期QPS非常低,但在某些情况下,当管理后端执行一些大型操作(例如导入数据)时,所需的连接性会突然增加。此外,管理后端不需要额外的性能,因此较小的minIdle 值是一个不错的选择。这样可以防止不必要的连接浪费,并防止需要突然增加连接时动态扩展连接。
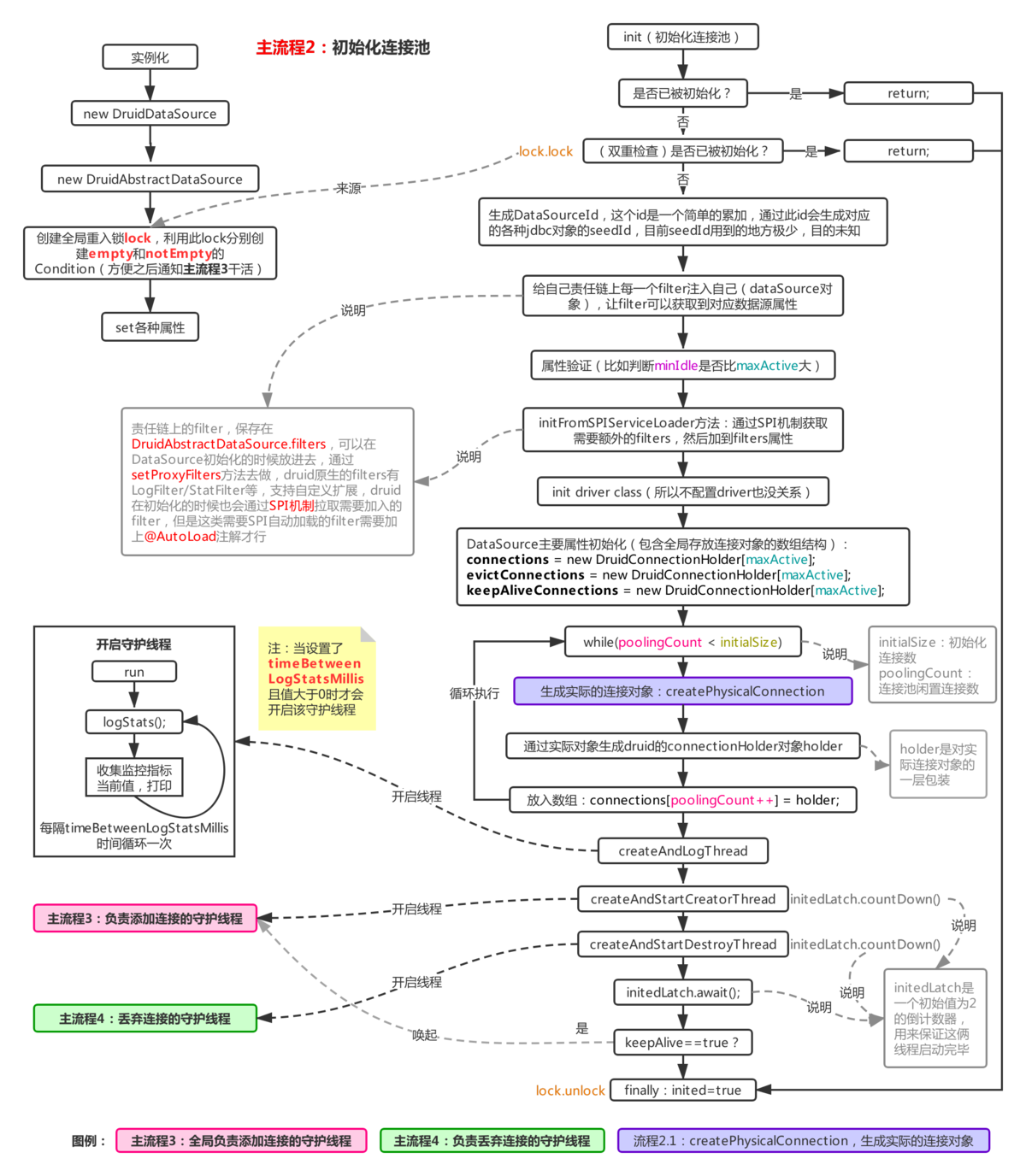
主流程2:初始化连接池
从上面的流程图可以看到,当获取连接时,首先会检查连接池是否已经初始化(initied,由bool类型控制,uninitialized为flase,initialized为true,这个判断过程在里面完成init方法),如果没有初始化,则调用init进行初始化(图中主流程1的紫色部分) init方法中做了哪些操作?
 图片
图片
可以看到初始化过程中初始化了全局可重入锁,其中包括后续的连接池操作。当连接池初始化时,首先会对该锁进行双重检查。检查是否已初始化。如果未初始化,此时将通过SPI 机制加载责任链上的其他过滤器。
然而,这种类型的过滤器需要类用@AutoLoad注释。接下来,用maxActive 容量初始化三个数组。首先,connections用于存储连接池中的连接对象,evictConnections用于存储每次检查后需要丢弃的连接(结合流程4.1来理解)。用于存储需要检查的连接(也与流程4.1相关)。然后,它生成初始连接数(initialSize),将它们添加到连接中,并生成添加连接所需的两个守护线程。由于这两个进程比较复杂,所以我们将它们分开讨论(主进程3和主进程4)。
特别说明
从进程的角度来看,如果第一次实例化时没有初始化连接池(这个初始化指的是池本身的初始化,而不仅仅是druid对象属性的初始化),第一次调用getConnection时,会出现一个如图所示,很多逻辑导致第一个getConnection 花费太长时间,特别是因为长时间运行的连接建立操作被重复多次。如果你的程序并发量较高,建议实例化连接池后调用init或getConnection方法进行预热,因为最初的getConnection初始化过程会导致连接过程中出现排队现象。
特别说明
构建全局可重入锁时,使用锁对象会生成两个条件。这两个条件解释如下。
当连接池中有足够的连接时,使用empty来阻止守护线程(主进程3)添加连接。如果连接池中没有足够的连接,则获取连接的线程(此处记为Business)。线程A) 在notEmpty 上阻塞,当您启动一个空且阻塞的守护线程并添加连接时,在notEmpty 上阻塞的业务线程A 将再次启动。尝试获取连接。
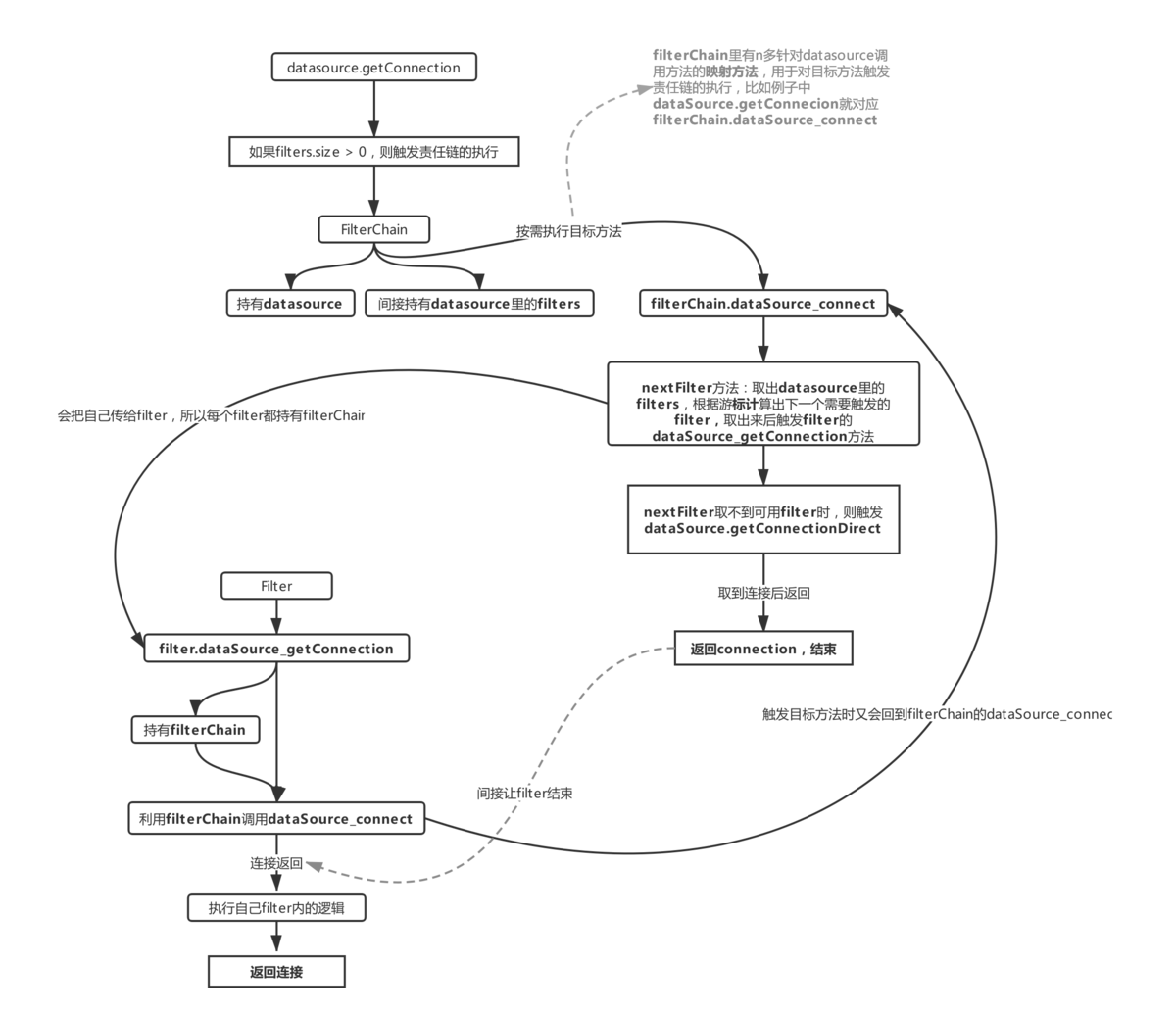
流程2.1:责任链
警告:结合源代码更容易理解。
 图片
图片
这对应于进程1 在获取连接时必须执行的一组职责。每个DruidAbstractDataSource 都包含过滤器属性。过滤器是Druid 过滤器接口的实现。当触发getConnection 方法时,会使用FilterChain 在每个过滤器上执行dataSource_getConnection。从流程1.1可以看到,datasource使用FilterChain来触发各个filter的执行。数据源有很多映射方法,比如上图中的dataSource_connect,它会执行数据源中的所有过滤器,直到nextFilter无法检索到任何值,之后会触发dataSource.getConnectionDirect。它使代码更容易理解。
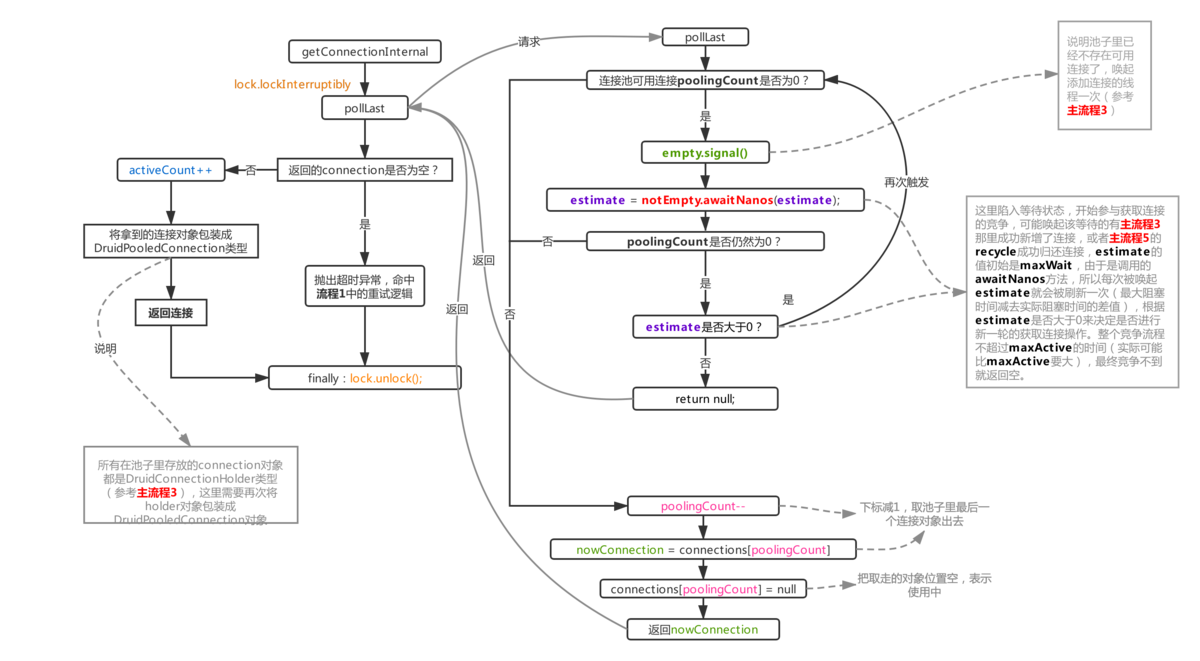
流程2.2:从池中获取连接的流程
 图片
图片
使用getConnectionInternal 方法从池中获取实际的连接对象。 Druid 支持两种添加新连接的方式。一种方法是通过await和signal通信来开启不同的守护线程(本文启用的方法也是默认方法)。另一种方式是通过await和signal通信来开启不同的守护线程。第一种是直接异步添加线程池,在druid初始化时传入asyncInit=true,然后将线程池对象赋值给createScheduler。我没有仔细研究过这种方法,这篇关于流程图和代码块的文章都避免了这种模式。
上面的过程很简单,只是poolingCount-1,一个数组值,返回,activeCount+1,整体复杂度为O(1)。重要的是当您无法连接时您该怎么做。如果无法获得连接,druid 首先启动一个新的连接守护线程,进入等待状态,然后启动一个等待点。连接回收(主进程5)耗尽并进入池后,又是一个新连接。激发await后,启动一个守护线程来添加连接并继续加入。在锁争用过程中,如果发现池中的连接数仍然为0(说明唤醒后刚刚提交参与锁争用;连接已被其他线程获取),继续下一步等待。这里使用了awaitNanos方法。初始值为maxWait,下次更新时将maxWait减去每次await实际花费的时间。虽然整体时间逐渐减少回零,但实际上比maxActive 要大,因为程序本身需要时间,唤醒后还要参与锁争用。所花费的时间。
如果最终无法获得连接,则返回null,并触发主进程1的重试逻辑。
druid如何防止在获取不到连接时阻塞过多的业务线程?
根据上面的流程图和流程描述,在非常极端的情况下,如果池中完全没有连接,则阻塞的业务线程过多或阻塞时间超过maxWait 是有可能的。有什么对策吗?那么,如果连接数不足,如何控制被阻塞的线程数量呢?
Druid实际上支持这个策略。 maxWaitThreadCount 属性的默认值(-1) 表示已启用。我不想加入池如果您遇到完全没有连接并且太多业务线程被阻塞的情况,您可以考虑设置此项。这意味着如果连接不足,可以阻塞的业务线程的最大数量。此开关的目的并未在Process 1.2 图中反映出来,但每次pollLast 方法等待时,notEmptyWaitThreadCount 属性都会在块完成后递增和递减。 notEmptyWaitThreadCount表示当前阻塞等待可用连接的业务线程总数,getConnectionInternal在调用pollLast之前确定了这段代码。
if (maxWaitThreadCount 0 notEmptyWaitThreadCount=maxWaitThreadCount) { connectErrorCountUpdater.incrementAndGet(this); throw new SQLException(‘maxWaitThreadCount ‘ + maxWaitThreadCount + ‘, current wait Thread count ‘ + lock.getQueueLength()); //不直接抛出异常抛出异常。如果设置等待线程数受到maxWaitThreadCount的限制,我们可以直接判断当前等待的业务线程数是否超过maxWaitThreadCount,就知道不会再调用pollLast。如果触发线程,则直接抛出错误(以防止新的等待)。
一般情况下,无需启用此项。我们建议您考虑maxWaitThreadCount 的值。典型的基本连接池配置不合理,maxActive配置对于高QPS的系统来说太小。例如,由于借出的连接没有及时关闭和返回,查询和事务速度变慢。连接租用时间过长。当然,设置为极限保护也没有坏处,但具体取值要根据实际情况来考虑。
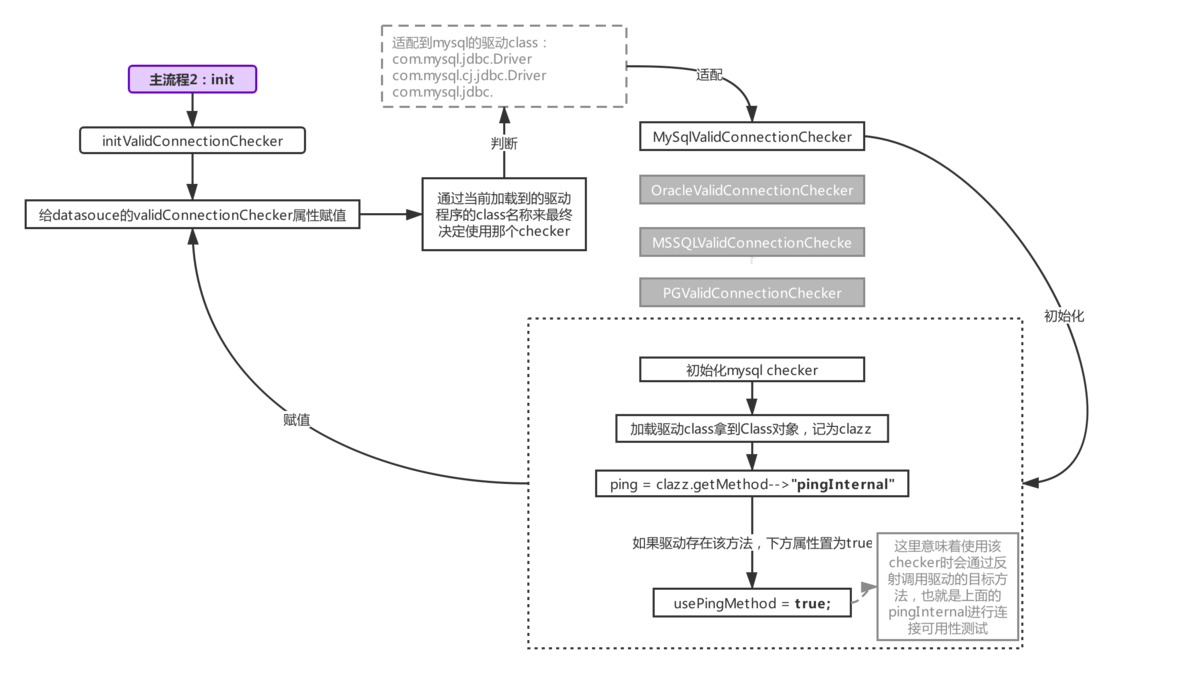
流程2.3:连接可用性测试
init-checker
在讨论这个之前,我们首先了解如何初始化检查器来检测连接。整个流程请看下图。
 图片
图片
初始化检查器发生在初始化阶段(由于篇幅限制,在主流程2(初始化阶段)中没有体现。由于Druid支持多个数据库连接源,因此初始化检查器请注意,这也发生在初始化阶段)。检查器是为了适应不同的驱动而设计的,所以可以看到图中的检查器根据加载的驱动类名匹配不同的数据库检查器,并且检查器被初始化。一是确定您的驱动程序是否具有ping 方法(jdbc4 开始支持它,并且mysql-connector-java 从版本3.x 开始实现了ping 方法)。 for 稍后用于确定检查器何时启用(如下所述,如果此处设置为true,将通过反射调用驱动程序的ping 方法;如果为false,将用于检测正常的SELECT 1 查询)将进行)。 SELECT 1 是一种常见的语句,它创建一条新语句并执行SELECT 1 以确定连接是否可用。
testConnectionInternal
接下来返回本节介绍的方法(testConnectionInternal,对应流程1.3)。
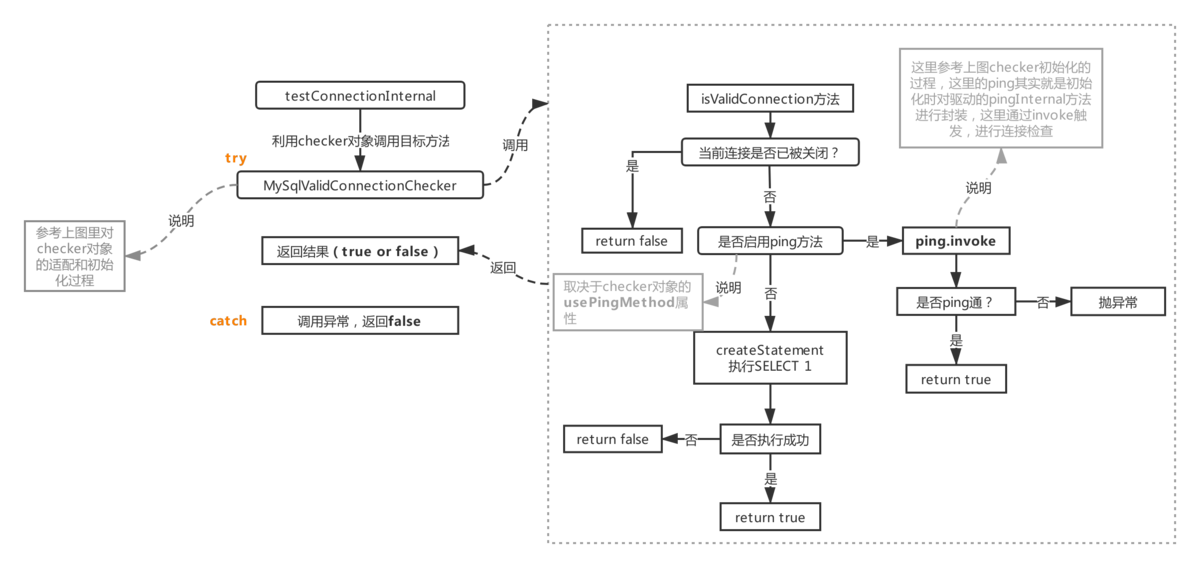
该方法使用在主进程2(初始化阶段)中初始化的检查器对象的isValidConnection方法(有关该过程,请参见init-checker)。如果启用了ping,则此方法使用invoke 来触发驱动程序上的ping 方法。如果未启用,请使用SELECT 1 方法ping 它(init-checker 告诉您它是否启用取决于加载的驱动程序是否有相应的方法)。
流程2.4:抛弃连接
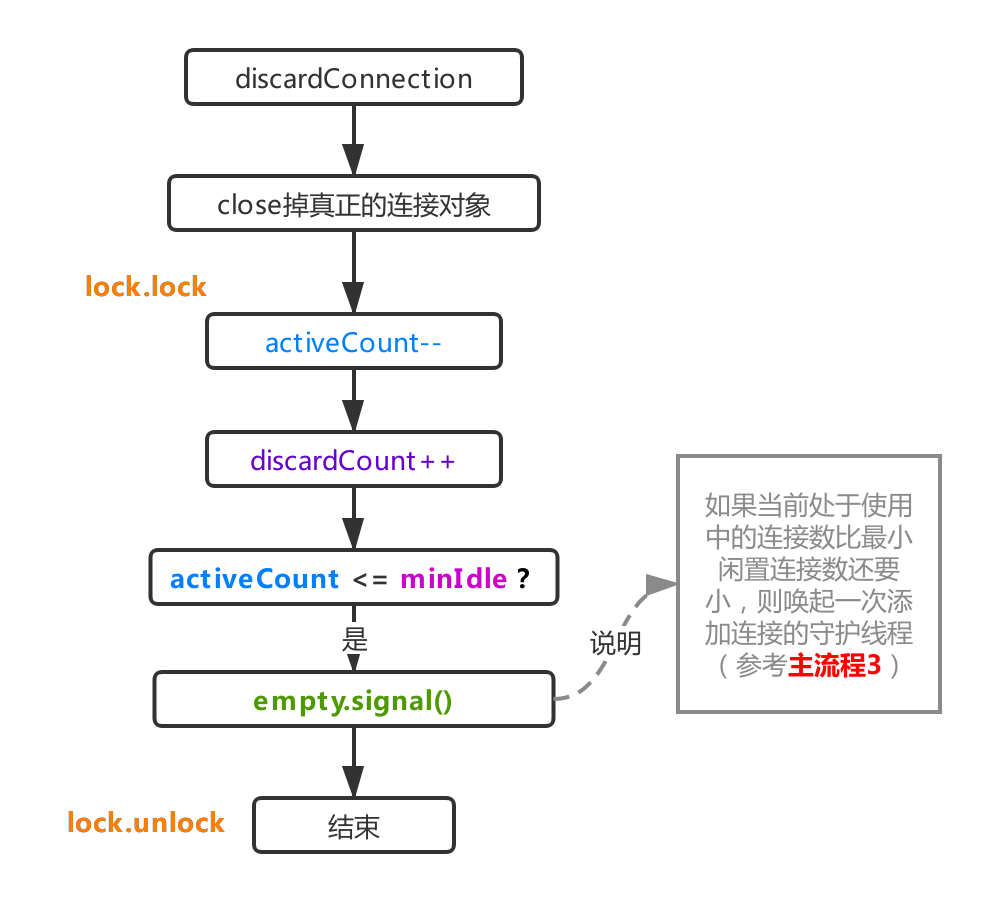
流程1.3返回测试结果后,如果发现连接不可用,这个流程很简单。如上图所示,当进程1.2获取连接时,activeCount就会累加。在此过程中将再次使用它。减1 表示检索到的连接不可用且无法进入活动状态。那么这里的close就是关闭驱动的连接对象。一般情况下,连接对象被druid封装成DruidPooledConnection对象。这是上图中的实际驱动程序Connection 对象。当对象关闭时,使用包装类DruidPooledConnection进行关闭。这意味着回收连接对象(参见回收,主流程5)。
主流程3:添加连接的守护线程
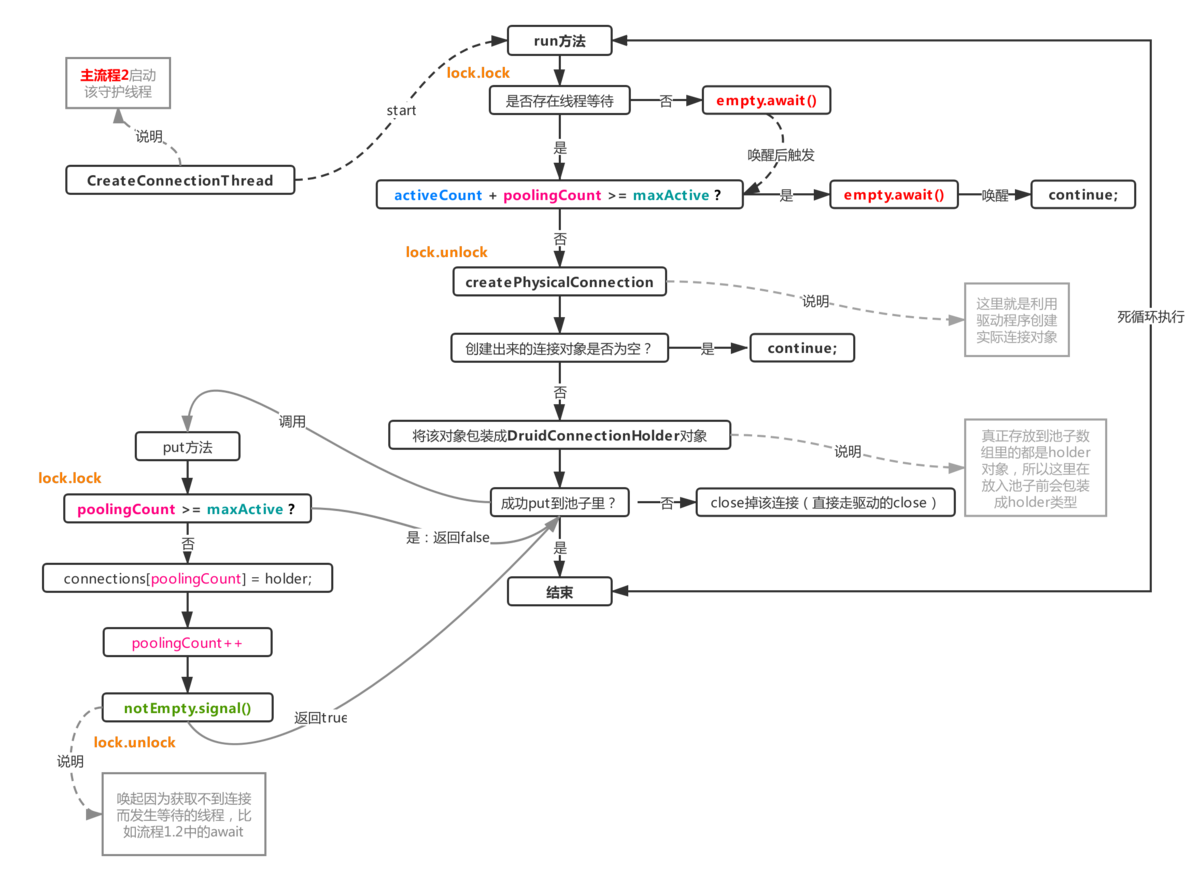
该进程在主进程2(初始化阶段)中启动,大部分时间处于空闲状态,不占用任何CPU,但在连接不足时调用。要添加额外的连接,在成功创建连接后,启动其他线程等待获取可用连接,例如:
结合流程1.2,如果连接数不足,会通过empty.signal唤醒一个线程来补偿连接数(唯一空且阻塞的线程是主流程3中的单线程),然后通过notEmpty 时。线程成功完成连接。 最后,阻塞在notEmpty 上的线程被唤醒并进入锁争用状态。理解这一点的一个简单方法是生产-消费模型。例如,池中正在使用的连接数(activeCount)加上池中剩余的连接数(poolingCount)指的是当前正在生成的连接总数。该数字不能大于maxActive。如果大于maxActive,则再次等待。将连接放入池中时,确定poolingCount 是否大于maxAc。
tive来决定最终是否入池。
主流程4:抛弃连接的守护线程
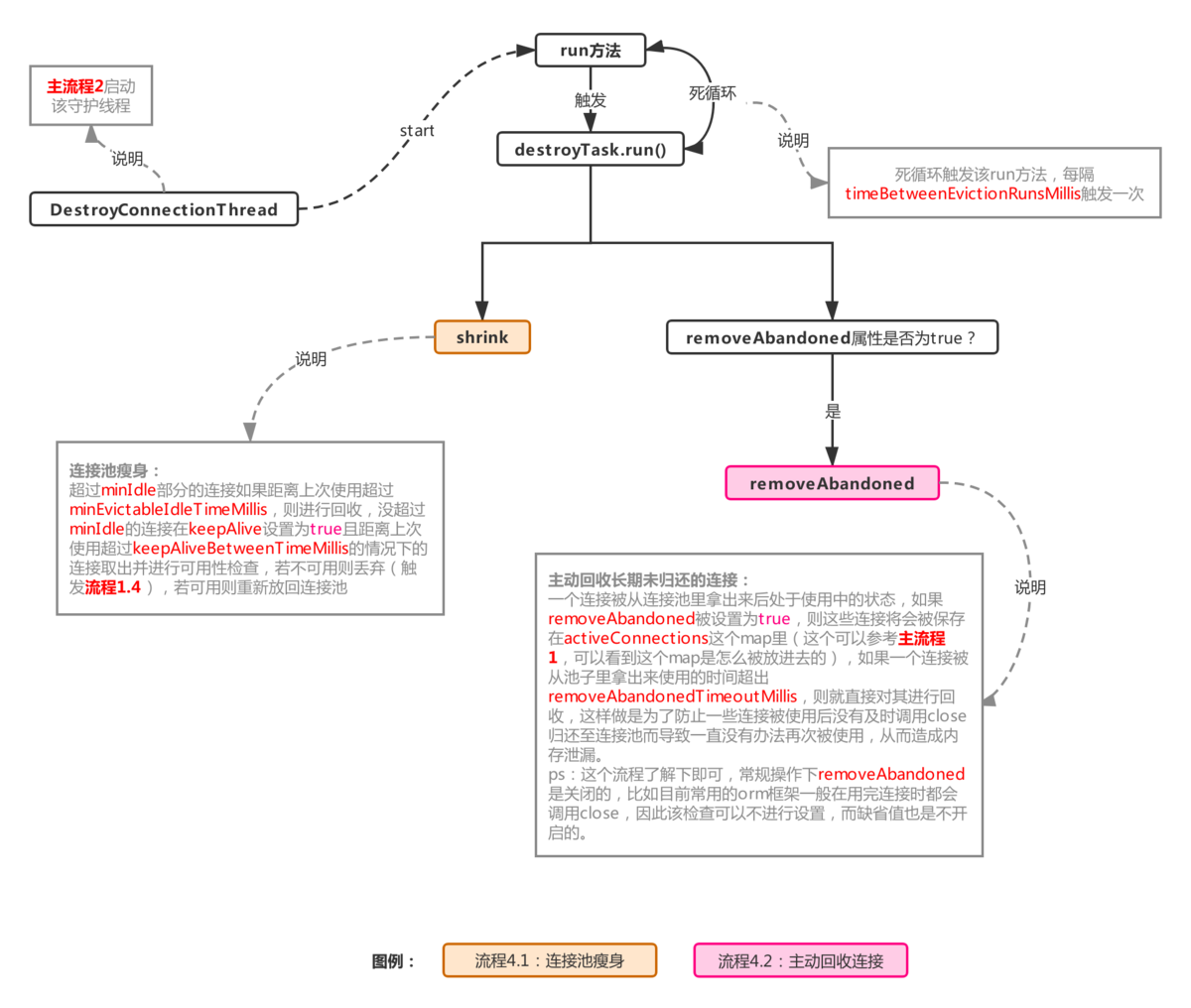
流程4.1:连接池瘦身,检查连接是否可用以及丢弃多余连接
整个过程如下: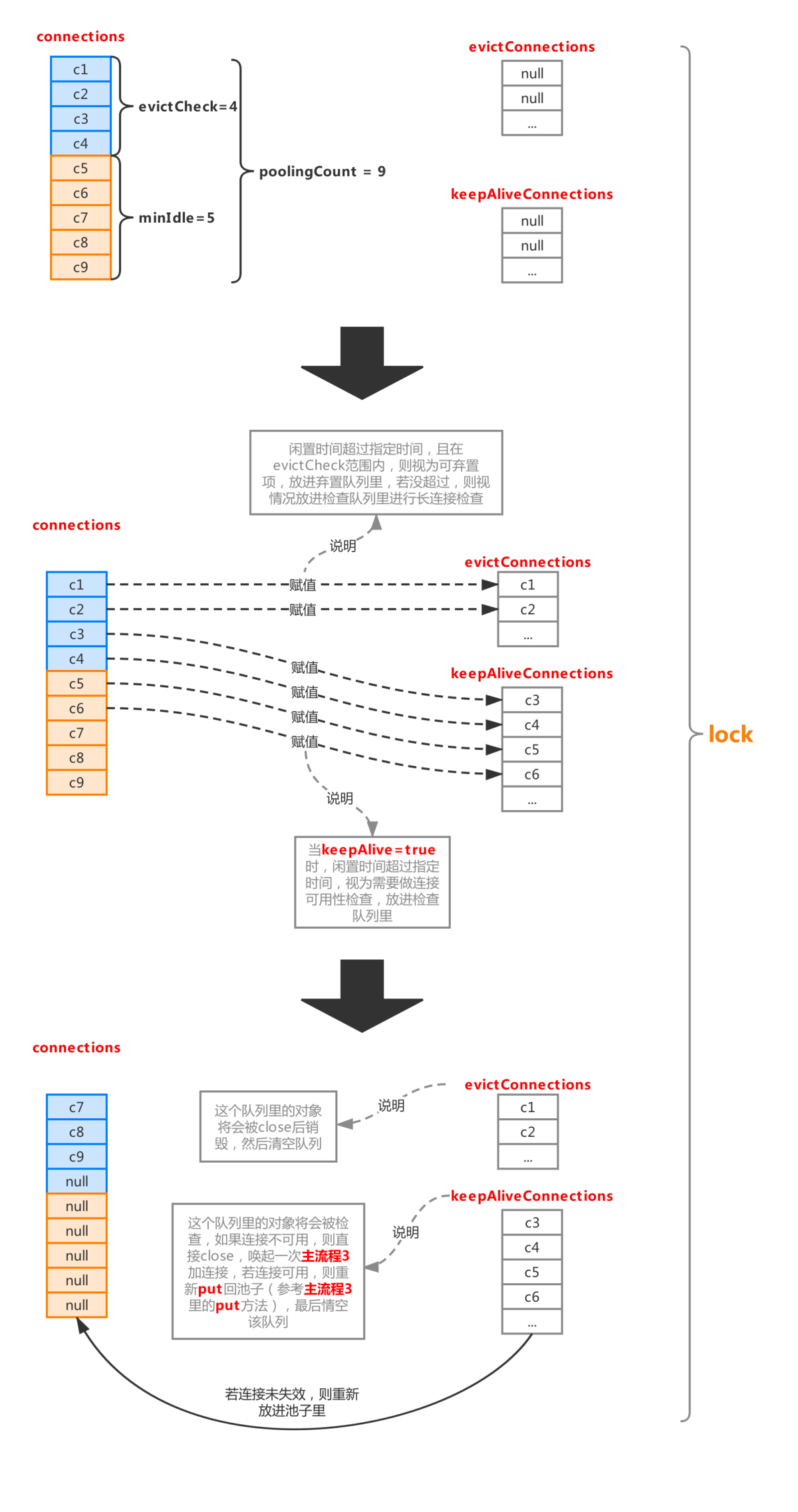
整个流程分成图中主要的几步,首先利用poolingCount减去minIdle计算出需要做丢弃检查的连接对象区间,意味着这个区间的对象有被丢弃的可能,具体要不要放进丢弃队列evictConnections,要判断两个属性:
minEvictableIdleTimeMillis:最小检查间隙,缺省值30min,官方解释:一个连接在池中最小生存的时间(结合检查区间来看,闲置时间超过这个时间,才会被丢弃)。
maxEvictableIdleTimeMillis:最大检查间隙,缺省值7h,官方解释:一个连接在池中最大生存的时间(无视检查区间,只要闲置时间超过这个时间,就一定会被丢弃)。
如果当前连接对象闲置时间超过minEvictableIdleTimeMillis且下标在evictCheck区间内,则加入丢弃队列evictConnections,如果闲置时间超过maxEvictableIdleTimeMillis,则直接放入evictConnections(一般情况下会命中第一个判断条件,除非一个连接不在检查区间,且闲置时间超过maxEvictableIdleTimeMillis)。
如果连接对象不在evictCheck区间内,且keepAlive属性为true,则判断该对象闲置时间是否超出keepAliveBetweenTimeMillis(缺省值60s),若超出,则意味着该连接需要进行连接可用性检查,则将该对象放入keepAliveConnections队列。
两个队列赋值完成后,则池子会进行一次压缩,没有涉及到的连接对象会被压缩到队首。
然后就是处理evictConnections和keepAliveConnections两个队列了,evictConnections里的对象会被close最后释放掉,keepAliveConnections里面的对象将会其进行检测(流程参考流程1.3的isValidConnection),碰到不可用的连接会调用discard(流程1.4)抛弃掉,可用的连接会再次被放进连接池。
整个流程可以看出,连接闲置后,也并非一下子就减少到minIdle的,如果之前产生一堆的连接(不超过maxActive),突然闲置了下来,则至少需要花minEvictableIdleTimeMillis的时间才可以被移出连接池,如果一个连接闲置时间超过maxEvictableIdleTimeMillis则必定被回收,所以极端情况下(比如一个连接池从初始化后就没有再被使用过),连接池里并不会一直保持minIdle个连接,而是一个都没有,生产环境下这是非常不常见的,默认的maxEvictableIdleTimeMillis都有7h,除非是极度冷门的系统才会出现这种情况,而开启keepAlive也不会推翻这个规则,keepAlive的优先级是低于maxEvictableIdleTimeMillis的,keepAlive只是保证了那些检查中不需要被移出连接池的连接在指定检测时间内去检测其连接活性,从而决定是否放入池子或者直接discard。
流程4.2:主动回收连接,防止内存泄漏
过程如下: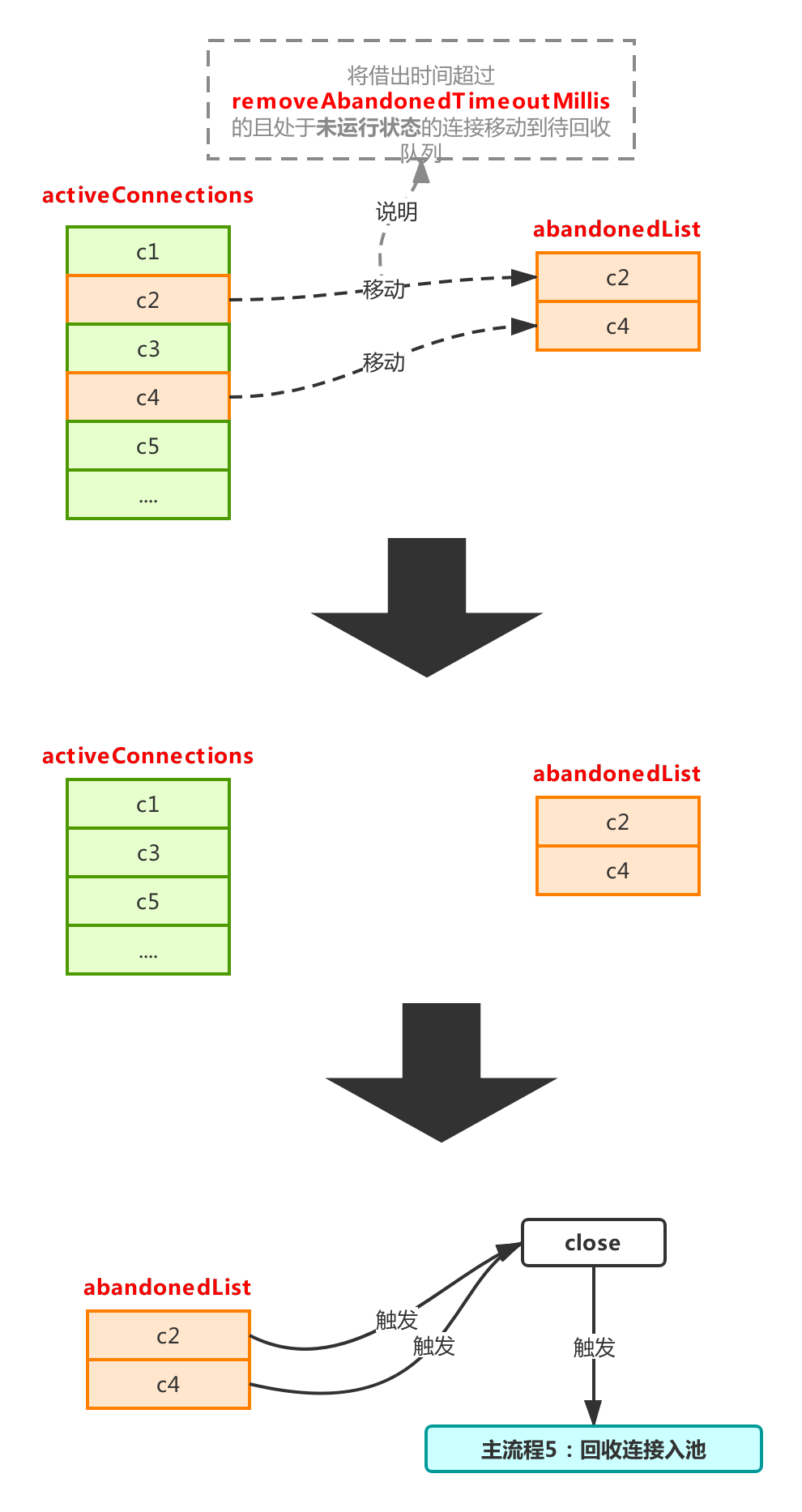
这个流程在removeAbandoned设置为true的情况下才会触发,用于回收那些拿出去的使用长期未归还(归还:调用close方法触发主流程5)的连接。
先来看看activeConnections是什么,activeConnections用来保存当前从池子里被借出去的连接,这个可以通过主流程1看出来,每次调用getConnection时,如果开启removeAbandoned,则会把连接对象放到activeConnections,然后如果长期不调用close,那么这个被借出去的连接将永远无法被重新放回池子,这是一件很麻烦的事情,这将存在内存泄漏的风险,因为不close,意味着池子会不断产生新的连接放进connections,不符合连接池预期(连接池出发点是尽可能少的创建连接),然后之前被借出去的连接对象还有一直无法被回收的风险,存在内存泄漏的风险,因此为了解决这个问题,就有了这个流程,流程整体很简单,就是将现金借出去还没有归还的连接,做一次判断,符合条件的将会被放进abandonedList进行连接回收(这个list里的连接对象里的abandoned将会被置为true,标记已被该流程处理过,防止主流程5再次处理)。
这个如果在实践中能保证每次都可以正常close,完全不用设置removeAbandoned=true,目前如果使用了类似mybatis、spring等开源框架,框架内部是一定会close的,所以此项是不建议设置的,视情况而定。
主流程5:回收连接
这个流程通常是靠连接包装类DruidPooledConnection的close方法触发的,目标方法为recycle,流程图如下: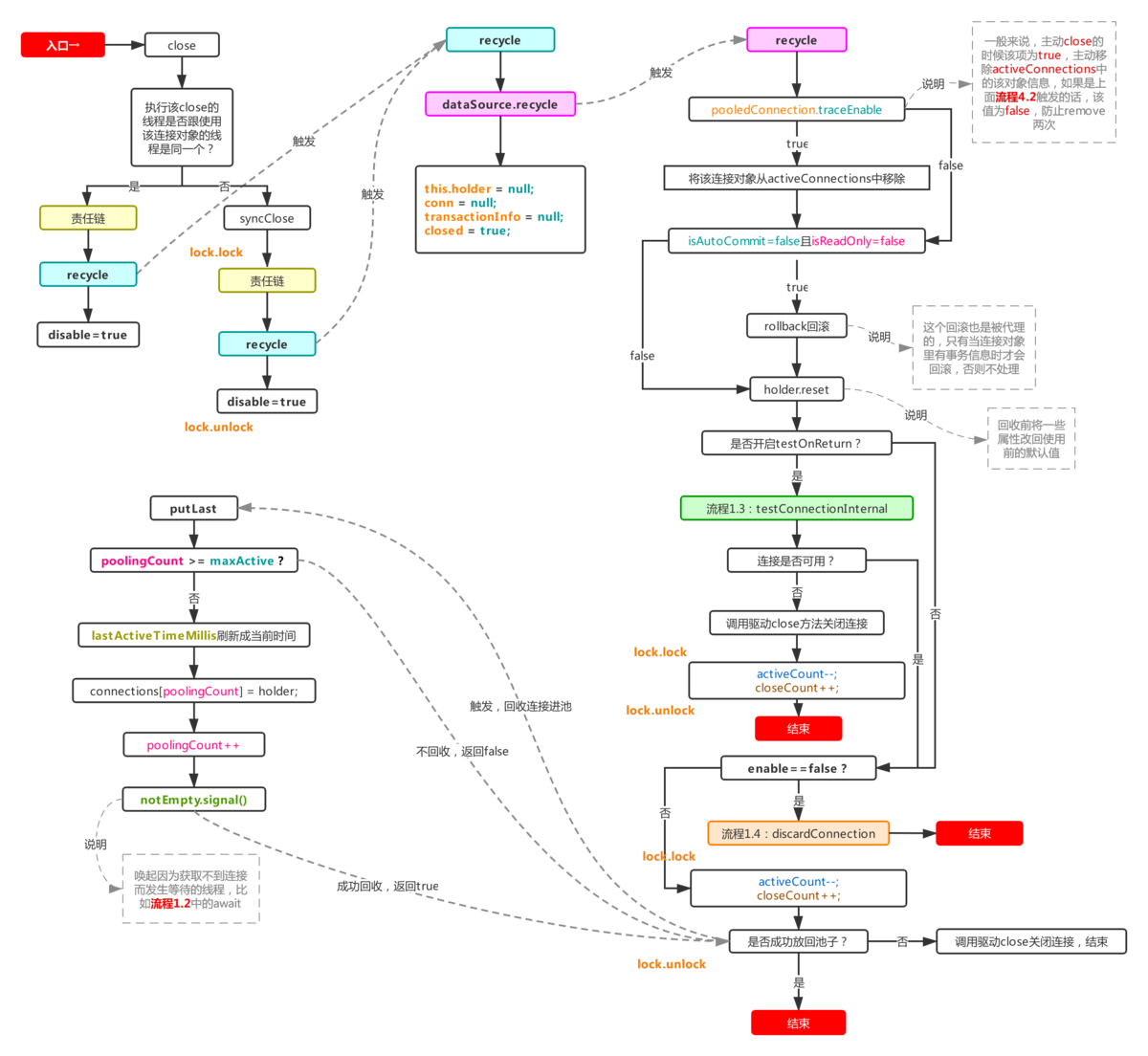
这也是非常重要的一个流程,连接用完要归还,就是利用该流程完成归还的动作,利用druid对外包装的Connecion包装类DruidPooledConnection的close方法触发,该方法会通过自己内部的close或者syncClose方法来间接触发dataSource对象的recycle方法,从而达到回收的目的。
最终的recycle方法:
①如果removeAbandoned被设置为true,则通过traceEnable判断是否需要从activeConnections移除该连接对象,防止流程4.2再次检测到该连接对象,当然如果是流程4.2主动触发的该流程,那么意味着流程4.2里已经remove过该对象了,traceEnable会被置为false,本流程就不再触发remove了(这个流程都是在removeAbandoned=true的情况下进行的,在主流程1里连接被放进activeConnections时traceEnable被置为true,而在removeAbandoned=false的情况下traceEnable恒等于false)。
②如果回收过程中发现存在有未处理完的事务,则触发回滚(比较有可能触发这一条的是流程4.2里强制归还连接,也有可能是单纯使用连接,开启事务却没有提交事务就直接close的情况),然后利用holder.reset进行恢复连接对象里一些属性的默认值,除此之外,holder对象还会把由它产生的statement对象放到自己的一个arraylist里面,reset方法会循环着关闭内部未关闭的statement对象,最后清空list,当然,statement对象自己也会记录下其产生的所有的resultSet对象,然后关闭statement时同样也会循环关闭内部未关闭的resultSet对象,这是连接池做的一种保护措施,防止用户拿着连接对象做完一些操作没有对打开的资源关闭。
③判断是否开启testOnReturn,这个跟testOnBorrow一样,官方默认不开启,也不建议开启,影响性能,理由参考主流程1里针对testOnBorrow的解释。
④直接放回池子(当前connections的尾部),然后需要注意的是putLast方法和put方法的不同之处,putLast会把lastActiveTimeMillis置为当前时间,也就是说不管一个连接被借出去过久,只要归还了,最后活跃时间就是当前时间,这就会有造成某种特殊异常情况的发生(非常极端,几乎不会触发,可以选择不看):
如果不开启testOnBorrow和testOnReturn,并且keepAlive设置为false,那么长连接可用测试的间隔依据就是利用当前时间减去上次活跃时间(lastActiveTimeMillis)得出闲置时间,然后再利用闲置时间跟timeBetweenEvictionRunsMillis(默认60s)进行对比,超过才进行长连接可用测试。
那么如果一个mysql服务端的长连接保活时间被人为调整为60s,然后timeBetweenEvictionRunsMillis被设置为59s,这个设置是非常合理的,保证了测试间隔小于长连接实际保活时间,然后如果这时一个连接被拿出去后一直过了61s才被close回收,该连接对象的lastActiveTimeMillis被刷为当前时间,如果在59s内再次拿到该连接对象,就会绕过连接检查直接报连接不可用的错误。
结束
到这里针对druid连接池的初始化以及其内部一个连接从生产到消亡的整个流程就已经整理完了,主要是列出其运行流程以及一些主要的监控数据都是如何产生的,没有涉及到的是一个sql的执行,因为这个基本上就跟使用原生驱动程序差不多,只是druid又包装了一层Statement等,用于完成一些自己的操作。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/82375.html