
Kafka是近年来非常流行的分布式平台。这意味着它可以处理高频读写并存储大量数据。数据可靠性始终得到保证,并且还支持从故障中恢复的强大机制。
今天我想和大家聊聊Kafka,也为想要学习Kafka的同学提供一个入门指南。
消息中间件基本架构

消息中间件基本上可以分为三个部分。
产品生产者或消息生产者将消息发送到消息队列。队列消息队列。接受并保存来自生产者的消息。 Consumer Consumer 消费消息队列中的消息。
消息中间件的作用
消息队列的主要特点是调峰、异步、解耦。
消费消息的两种模式
两种消息消费模式,发布/订阅模式和点对点模式:
发布订阅模式(一对多)
消息在消费者消费后会存储一段时间。该模式下的消息被所有消费者消费。
该模式下有两种消费消息的方式。
推送模式。在该方法中,队列直接将消息推送给消费者。由于每个消费者的消息处理能力不同,所以有些消费者可能无法消费推送的消息。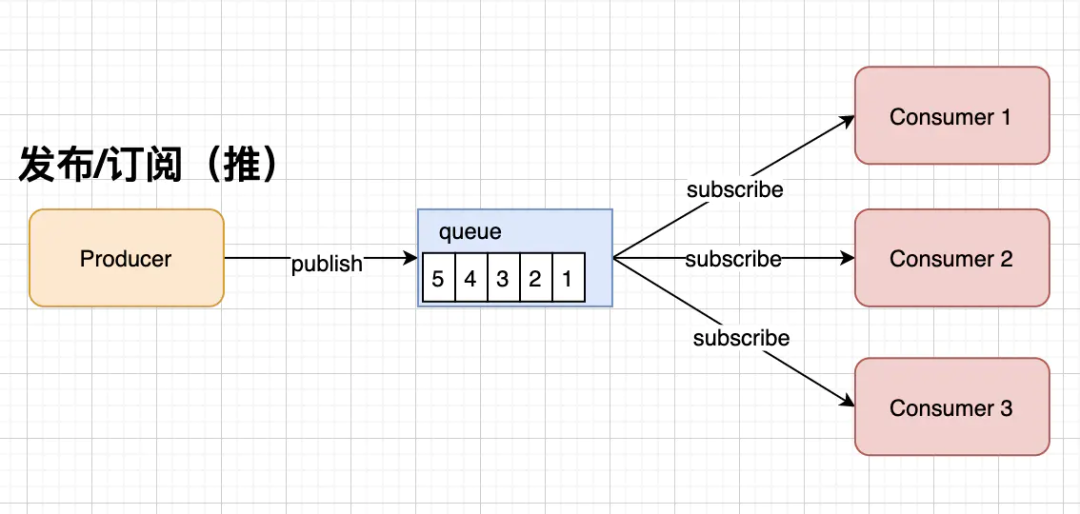
拉动模式。这种方式允许消费者根据自己的消费能力拉取数据,但是每个消费者必须维护及时拉取消息的任务。该任务无法停止,因为它在队列中。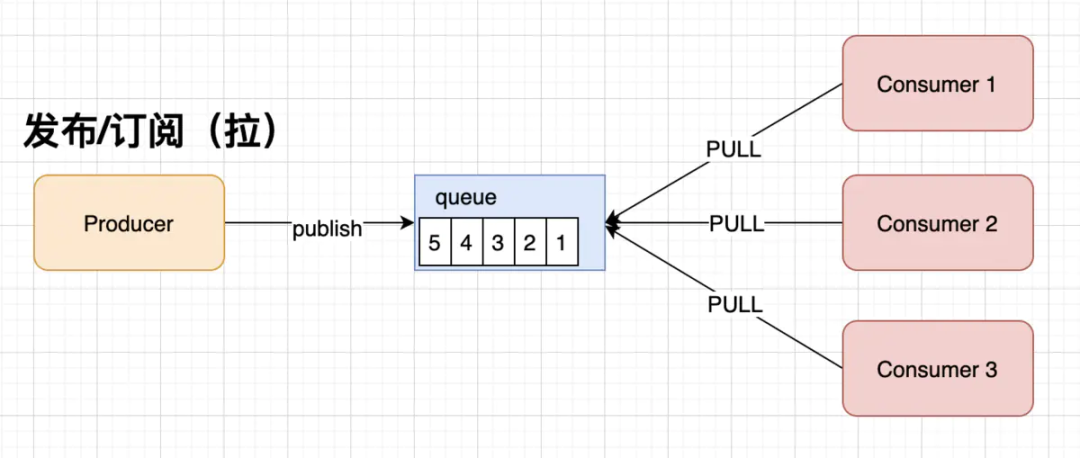
点对点模式(一对一):在点对点模式下,消费者在确认消息已被消费后,将队列中的消息移除。一条消息只能被一个消费者消费。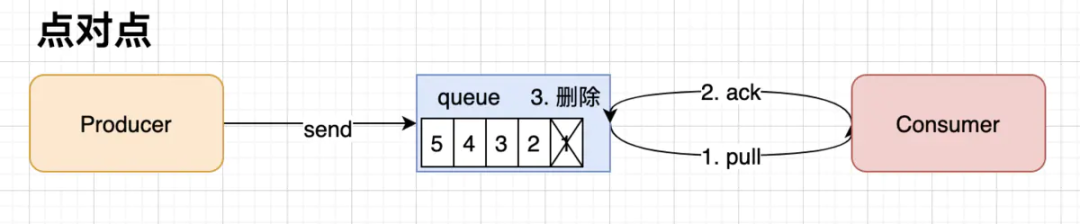
Kafka基本概念
Kafka是一个分布式消息队列,使用Zookeeper进行集群管理。
不同的消费者组是基于发布/订阅拉取模型来实现的。同一消费组内的消费者以点对点的方式消费消息,但消息消费后并不会被删除。
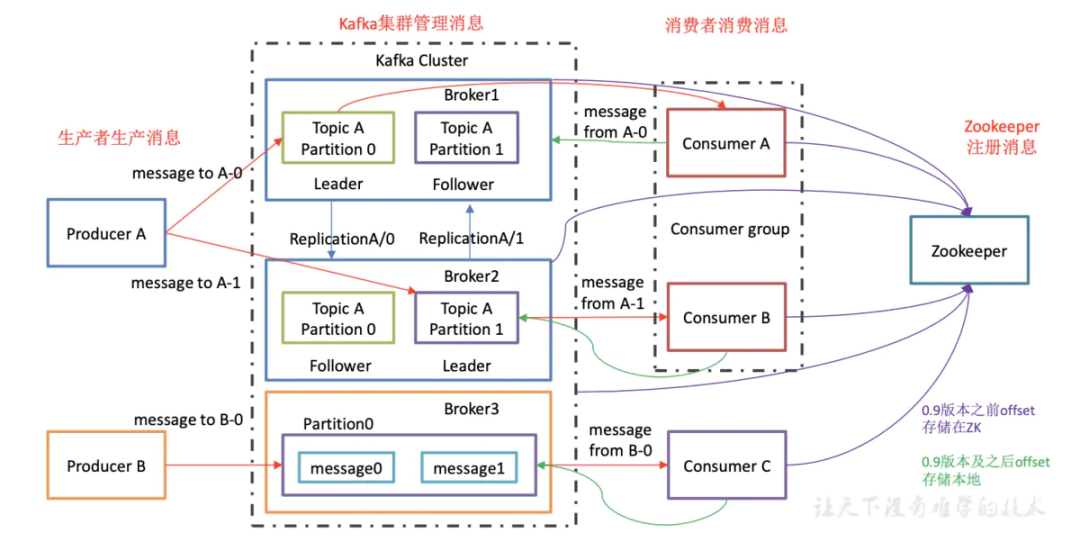
Producer
消息生产者是向kafka 代理发送消息的客户端。
Broker
Kafka 服务器是一个代理。 Kafka集群由多个broker组成,集群通过Zookeeper进行管理。
Consumer
消息消费者,从kafka代理检索消息的客户端。
Consumer Group
由多个消费者组成的消费者组。同一消费者组中的消费者只能使用一个分区中的数据。
Topic
Topic是一个逻辑消息队列。相同类型的消息可以放入主题(消息队列)中。它的主要作用是屏蔽底层分区和副本的复杂逻辑。
Partition
分区是Kafka中数据存储的基本单位。这是一个物理概念。主题可以分为多个分区。每个分区是一个有序队列,可以同时被不同的消费者组使用,但同一个消费者组只能被一个消费者使用。这可以通过增加同一主题的划分数量来改善。
Replica
副本是分区的备份。一个分区只能有一个领导者,但同一台机器上不能有同一分区的多个副本。也就是说,如果有两个broker,则一个分区最多只有一份副本。阅读器的主要功能是完成与生产者和消费者的交互。 follower的主要功能是在leader无法保证Kafka可用性的情况下成为新的leader。
如果需要提高Kafka消费性能,则应该同时扩展分区数量和同一消费者组中的消费者数量。
我们用数据库设计中的分库、分表设计来类比。对于order数据库,DB分为db_order_1、db_order_2,每个数据库的t_order表又分为t_order_1、t_order_2表。这里, db_order_1 和db_order_2 对应于kafka中的broker, t_order_1 和t_order_2 对应于kafka中的分区,如果有从数据库,则t_order_1 , t_order_2 。相当于kafka的Replica(副本)。
代码示例
发送消息
@ResourceprivateKafkaTemplateString,StringkafkaTemplate;publicTvoidplainNotify(Stringtopic,Tobj){try{this.kafkaTemplate.send(topic,JSON.toJSONString(obj));}catch(Exceptione){//TODO}} :0 1 0 – 1010 @Service@Slf4jpublicclassConsumer{@KafkaListener(id=’ConsumerGroupId’,topics={‘TOPIC1′,’TOPIC2’})publicvoidconsumer(ListStringmsgs,Acknowledgmentack){for(Stringmsg:msgs){//TODO}ack.acknowledge(); } }
消费消息
今天我将分享一个免费文档《Kafka知识点》。由于文章限制,本文档包含所有基础和高级知识。
福利



想要完整版的朋友请看下图获取。

注:本文来源于网络,因侵犯版权已被删除。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/83583.html