
一、Kafka概述
Kafka是Linkedin最初开发的一个支持分区和多副本的分布式消息系统,其主要特点是能够实时处理大量消息。各种需求场景:用Scala语言编写的基于Hadoop的批处理系统、低延迟实时系统、Storm/Spark流引擎、Web/nginx日志、访问日志、消息服务等,Linkedin 2010年贡献Apache基金会并已成为顶级开源项目。
1)Kafka的特性
高吞吐量和低延迟:Kafka 每秒可以处理数十万条消息,延迟仅为几毫秒。 可扩展性:Kafka集群支持热扩容。消息保存到您的本地磁盘。支持数据备份,防止数据丢失。 容错:允许集群中的节点故障(如果副本数为n,则允许n-1个节点故障)。 高并发:支持数千个客户端的读写。
2)应用场景
同时收集日志:企业使用Kafka收集不同服务的日志,Kafka用于将这些日志以统一接口服务的形式分发给不同的消费者,例如Hadoop、Hbase、Solr可以发布。稍后我们将讨论结合Kafka 的企业级日志系统应用(每天20TB 数据)。消息系统:生产者和消费者分离、消息缓存等。跟踪用户活动:Kafka通常用于记录Web和应用程序用户的各种活动,例如网页浏览、搜索、点击等活动。这些活动信息由各个服务器发布到Kafka 主题,供订阅者订阅。可以用于实时监控和分析,也可以加载到Hadoop或数据仓库中进行离线分析和挖掘。运营指标:Kafka也常用于记录运营监控数据。这包括从各种分布式应用程序收集数据并为各种操作(例如警报和报告)生成集中反馈。流处理:Spark Streaming、Storm Event Sources 等。
二、Kafka架构简介
Kafka 中的发布和订阅对象是主题。您可以为每种类型的数据创建主题。向主题发布消息的客户端称为生产者,订阅主题消息的客户端称为消费者。生产者和消费者可以同时从多个主题读取和写入数据。 Kafka集群由一台或多台负责持久化和备份特定Kafka消息的代理服务器组成。
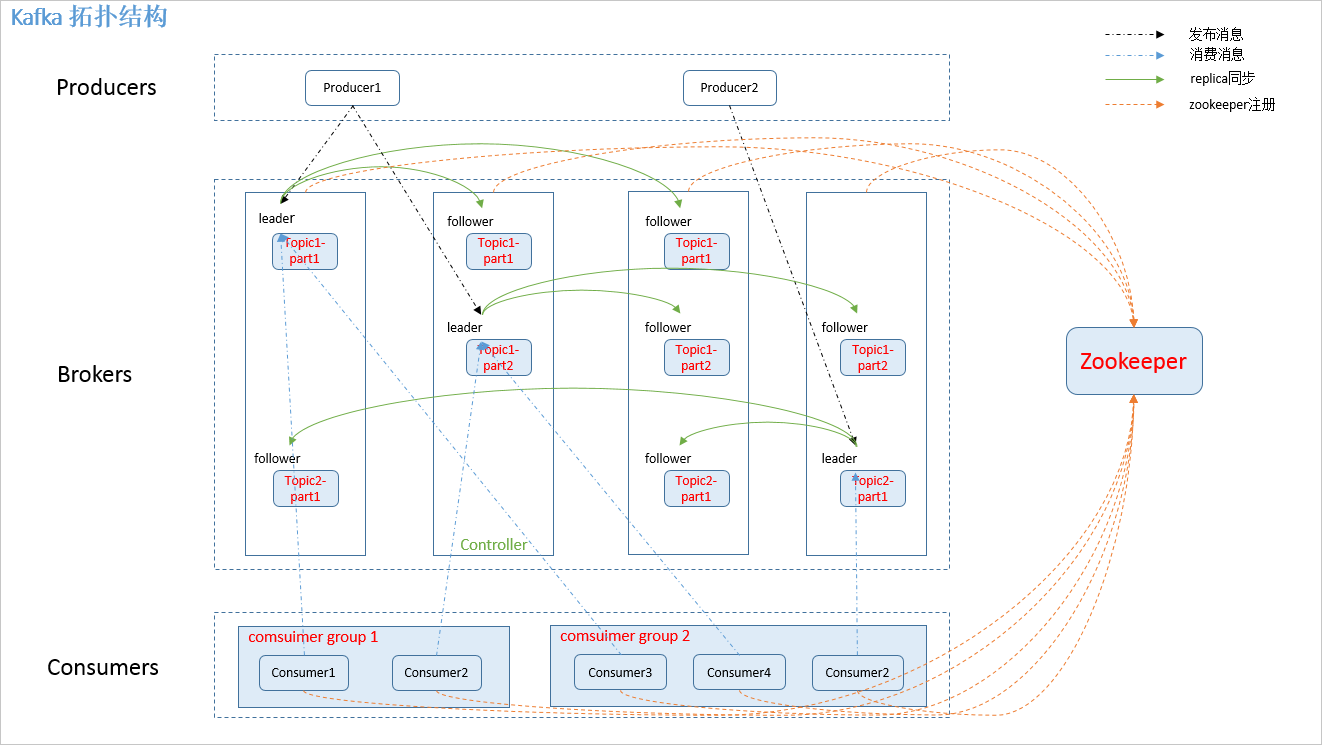
生产者:消息和数据的生产者。它主要负责编写消息并将其推送到指定的代理主题。 Broker:Kafka节点称为broker,主要负责创建主题、存储生产者发布的消息、记录消息处理过程以及将当前消息存储在内存中并持久化到磁盘。主题:同一主题的消息可以分发给一个或多个代理。 Topic包含一个或多个分区,数据存储在多个分区中。消费者:消费来自Kafka 集群的消息的端点或服务。消费者组:在高级消费者API 中,每个消费者都属于一个消费者组。每条消息只能被一个消费者组内的一个消费者消费,但也可以被多个消费者组消费。 Controller:Kafka在所有broker中选举一个controller领导者,所有分区的领导者选举由controller决定。控制器领导者还负责管理集群中分区和副本的状态。例如,如果分区的领导者副本发生故障,则控制器负责在修改后为该分区重新选择新的领导者副本。如果在ISR 列表中检测到,控制器会通知集群中的所有代理更新其MetadataCache 信息。添加主题分区时,控制器还管理分区重新分配。 Leader:副本中的角色。生产者和消费者只与领导者互动。 Follower:副本中从领导者复制数据的角色。副本:分区的副本,以保证分区的高可用性。分区:每个分区都有多个副本,副本充当备份轮。如果主分区(Leader)发生故障,备胎(Follower)就会被选举为接管并成为Leader。 Kafka默认的最大副本数为10,并且副本数不能超过broker的数量。保证跟随者和领导者位于不同的机器上,并且同一机器上只能存储一个副本(包括其自身)。相同的分区。 ZooKeeper:ZooKeeper负责维护整个Kafka集群的状态,存储各个Kafka节点的信息和状态,为Kafka集群提供高可用性,协调Kafka的工作。
写入流程
生产者首先从Zookeeper的’/brokers/./state’节点找到分区的leader生产者,向leader发送消息,将消息写入本地日志follower,将leader的消息写入到在从所有ISR 副本拉取并接收ACK 后,它会增加HW(高水位线,上次提交的偏移量)并向生产者发送ACK 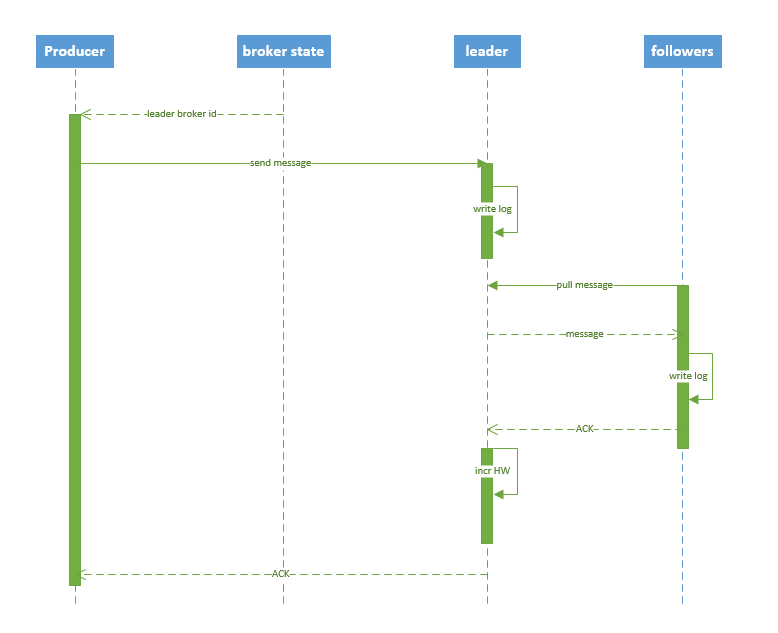 。
。
三、Kakfa的设计思想
Kakfa Broker Leader 选举:Kakfa Broker 集群由Zookeeper 管理。所有Kafka Broker节点都到Zookeeper一起注册临时节点。这是因为只有一个Kafka Broker 会注册成功,其他的都会失败。因此,成功向Zookeeper 注册临时节点的Kafka Broker 成为Kafka Broker 控制器,其他Kafka Broker 称为Kafka Broker Follower。 (这个过程称为控制器向ZooKeeper 注册手表。)该控制器监控其他Kafka 代理的所有信息。如果Kafka Broker 控制器发生故障,Zookeeper 上只会注册一个临时节点,因此所有Kafka Broker 都会一起注册。因此,在Zookeeper中成功注册临时节点的Kafka Broker成为Kafka Broker控制器,其他Kafka Broker称为Kafka Broker Follower。 Consumergroup:每个消费者(消费者线程)可以组成一个组(消费者组)。如果一条消息被多个消费者消费,那么一个分区中的每条消息只会被该组(消费者组)中的一个消费者(消费者线程)消费。 (对于消费者线程),这些消费者必须属于不同的组。 Kafka 不支持分区中的消息由同一消费者组内的两个或多个消费者线程处理,除非启动了新的消费者组。因此,一个消费者线程只能处理一个分区。 Consumer Rebalance的触发条件:增加或删除Consumer会触发Consumer Group的RebalanceBroker增加或减少。 Consumer RebalanceConsumer:Consumer在处理分区中的消息时以O(1)的顺序读取消息。因此,必须维护最后读取位置的异地信息。对于高级API,偏移量存储在Zookeeper 中,对于低级API,偏移量自行维护。通常,使用高级API。消费者投递保证默认读取消息后提交,然后autocommit默认设置为true,如果处理失败则更新offsite+1。此时消息就丢失了,但是你也可以将其设置为在提交之前读取并处理消息。这种情况下,消费端的响应会很慢,需要等待处理完成。主题分区:主题相当于传统消息系统MQ中的队列。生产者发送的消息必须指定发送到的主题,但不需要指定该主题下的哪些分区,因为Kafka 会对收到的消息进行负载均衡。信息。均匀分布在该主题的不同分区中(Hash(Message) % [代理数量])。从物理存储的角度来看,该主题被分为一个或多个分区,每个分区代表一个子队列。物理上,每个分区对应一个物理目录(文件夹),文件夹名称为[主题名称][分区][序号]。根据您的业务需求和数据量,主题可以具有无限数量的分区。您可以通过更改kafka配置文件中的num.partitions参数来配置随时更改主题的分区数量。创建主题时通过参数指定分区数量。创建主题后,您还可以使用Kafka提供的工具更改分区数量。主题中的分区数量大于或等于代理数量,这会增加吞吐量。为了确保高可用性,同一分区的副本应尽可能分布在不同的计算机上。
推拉: Kafka 生产者和消费者采用推拉模式。也就是说,生产者只向代理推送消息,消费者只从代理拉取消息。两者是异步的。 Kafka集群中broker之间的关系:这不是主从关系。任何代理节点都可以随意添加或从集群中删除。
四、Zookeeper在Kafka中的作用
Zookeepers是kafka不可或缺的一部分。接下来我们来说说Kafka中zookeeper的作用。
1)记录和维护broker状态
zookeeper记录所有broker的生存状态,broker向zookeeper发送心跳请求报告其状态。 Zookeeper 维护属于集群的正在运行的代理的列表。
2)控制器(leader )选举
Kafka集群有多个broker,其中一个被选为控制器。控制器负责管理集群中所有分区和副本的状态。例如,如果特定分区的领导者发生故障,控制器将选举新的领导者。 Zookeeper负责从多个broker中选择一个控制器。
3)限额权限
Kafka 允许您为某些客户端设置不同的生产和消费限制。这些限制配置信息存储在Zookeeper中。
4)记录 ISR(已同步的副本)
Kafka 为Zookeeper 上的每个主题维护一组称为ISR(同步副本)的集合。该集合是某些分区的副本。只有当这些副本与领导者中的副本同步时,Kafka 才会认为消息已发送,并向消息的生产者提供反馈。当这个集合增加或减少时,kafka 会更新Zookeeper 的记录。动物园管理员发现其中一只动物出现异常,立即将其消灭。
5)node 和 topic 注册
Zookeeper存储所有节点和主题的注册信息,因此您可以轻松找到每个代理持有哪些主题。一旦您与Zookeeper 的会话结束,节点和主题就会以临时节点的形式存在。
6)topic 配置
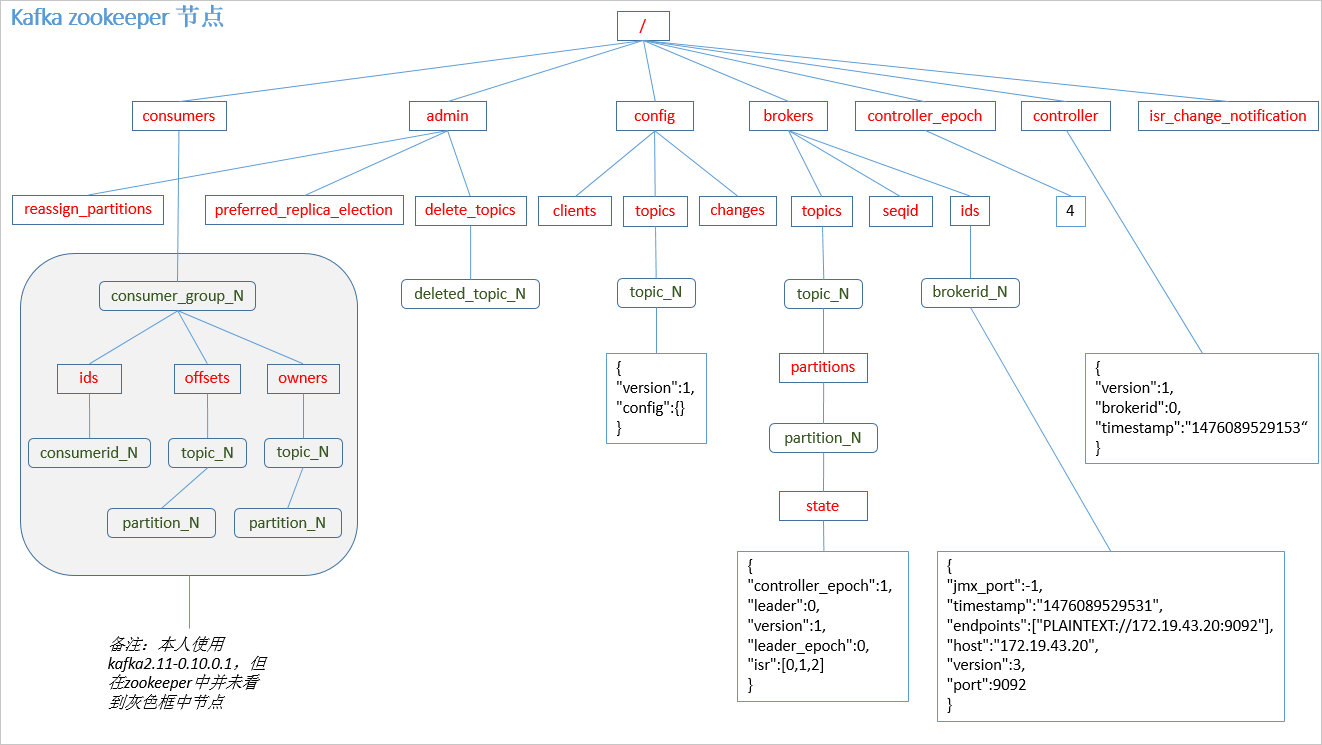
Zookeeper 存储主题相关的设置,例如主题列表、每个主题的分区数和副本位置。下图展示了Zookeeper的Kafka存储结构。
五、Leader选举
1)控制器(Broker)选举Leader机制
一个Kafka集群有多个broker节点,但其中必须选出一个leader,其他broker作为follower。集群中启动的第一个代理通过在Zookeeper 中创建临时节点/控制器来使自己成为控制器。其他代理在启动时也会在zookeeper中创建临时节点,但例外的是,当控制器意识到它已经存在时,zookeeper会监视该对象被创建,并且现在可以接收控制器更改的通知。
然后,当控制器与ZooKeeper 断开连接或由于网络原因异常终止时,其他代理会通过监视接收控制器更改的通知,并尝试创建临时节点/控制器。当一个broker创建成功后,其他broker会收到创建异常通知。这意味着控制器已经存在于集群中,其他broker只需要创建监控对象即可。如果集群中的代理异常终止,控制器会检查该代理是否具有该分区的副本读取器,如果有,则需要该分区的新领导者。此时,控制器会检查其他副本以确定哪一个将成为领导者。创建新的领导者并同时更新分区的ISR 集。当broker加入集群时,控制器使用broker ID来确定新添加的broker是否包含现有分区的副本,如果是,则从该分区的副本中同步数据。每次在集群中选举控制器时,Zookeeper 都会创建一个控制器纪元。如果代理收到早于该纪元的数据,则该纪元将被忽略。它还用于防止集群内的“脑裂”。
2)分区副本选举Leader机制
Kafka集群有多个主题,每个分区在集群内有多个副本,以防止数据丢失。副本角色一共有三种类型。
Leader副本:这意味着每个分区都有一个Leader副本,通过它处理所有生产者和消费者的请求,以保证数据的一致性。 Follower副本:除了Leader副本之外的所有副本都是Follower副本。 follower副本不处理客户端的请求,只负责同步leader副本的数据,保证与leader的一致性。如果领导者副本崩溃,则会从中选出领导者。 Preferred Replica:创建分区时指定的首选leader。如果未指定,则为分区的第一个副本。默认情况下,如果跟随者与领导者之间超过10 秒没有发送请求,或者没有收到请求数据,则该跟随者被视为“不同步副本”。持续请求的副本是“同步副本”,如果领导者失败,则只有“同步副本”被选为领导者。请求超时可通过replica.lag.time.max.ms参数进行配置。
我希望能够将每个分区的领导者分配给不同的代理,以实现尽可能多的负载平衡。因此,将参数auto.leader.rebalance.enable 设置为true 将检查首选领导者。首选领导者是否是实际领导者。如果没有,就会触发选举,让首选的领导者成为领导者。
3)消费组(consumer group)选举机制
组协调员选举消费者组中所有消费者的领导者。这次选举的算法也非常简单。一旦领导者退出消费者,第一个加入的消费者就会成为领导者。消耗
组,那么会重新 随机 选举一个新的leader。
六、kubernetes(k8s) helm3安装zookeeper、kafka
k8s上安装kafka,可以使用helm,将kafka作为一个应用安装。当然这首先要你的k8s支持使用helm安装。helm的介绍和安装见:Kubernetes(k8s)包管理器Helm(Helm3)介绍&Helm3安装Harbor
1)前期准备
1、创建命名空间
$ mkdir -p /opt/bigdata/kafka$ cd /opt/bigdata/kafka$ kubectl create namespace bigdata2、创建持久化存储SC(bigdata-nfs-storage)
cat << EOF > bigdata-sc.yamlapiVersion: v1kind: ServiceAccountmetadata: name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: bigdata #根据实际环境设定namespace,下面类同—kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata: name: nfs-client-provisioner-runner namespace: bigdatarules: – apiGroups: [“”] resources: [“persistentvolumes”] verbs: [“get”, “list”, “watch”, “create”, “delete”] – apiGroups: [“”] resources: [“persistentvolumeclaims”] verbs: [“get”, “list”, “watch”, “update”] – apiGroups: [“storage.k8s.io”] resources: [“storageclasses”] verbs: [“get”, “list”, “watch”] – apiGroups: [“”] resources: [“events”] verbs: [“create”, “update”, “patch”]—kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata: name: run-nfs-client-provisionersubjects: – kind: ServiceAccount name: nfs-client-provisioner namespace: bigdata # replace with namespace where provisioner is deployedroleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io—kind: RoleapiVersion: rbac.authorization.k8s.io/v1metadata: name: leader-locking-nfs-client-provisioner namespace: bigdata # replace with namespace where provisioner is deployedrules: – apiGroups: [“”] resources: [“endpoints”] verbs: [“get”, “list”, “watch”, “create”, “update”, “patch”]—kind: RoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata: name: leader-locking-nfs-client-provisioner namespace: bigdatasubjects: – kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: bigdataroleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io—kind: DeploymentapiVersion: apps/v1metadata: name: nfs-client-provisioner namespace: bigdataspec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: – name: nfs-client-provisioner image: quay.io/external_storage/nfs-client-provisioner:latest volumeMounts: – name: nfs-client-root mountPath: /persistentvolumes #容器内挂载点 env: – name: PROVISIONER_NAME value: fuseim.pri/ifs – name: NFS_SERVER value: 192.168.0.113 – name: NFS_PATH value: /opt/nfsdata volumes: – name: nfs-client-root #宿主机挂载点 nfs: server: 192.168.0.113 path: /opt/nfsdata—apiVersion: storage.k8s.io/v1kind: StorageClassmetadata: name: bigdata-nfs-storage namespace: bigdataprovisioner: fuseim.pri/ifs # or choose another name, must match deployment’s env PROVISIONER_NAME’reclaimPolicy: Retain #回收策略:Retain(保留)、 Recycle(回收)或者Delete(删除)volumeBindingMode: Immediate #volumeBindingMode存储卷绑定策略allowVolumeExpansion: true #pvc是否允许扩容EOF执行
$ kubectl apply -f bigdata-sc.yaml$ kubectl get sc -n bigdata$ kubectl describe sc bigdata-nfs-storage -n bigdata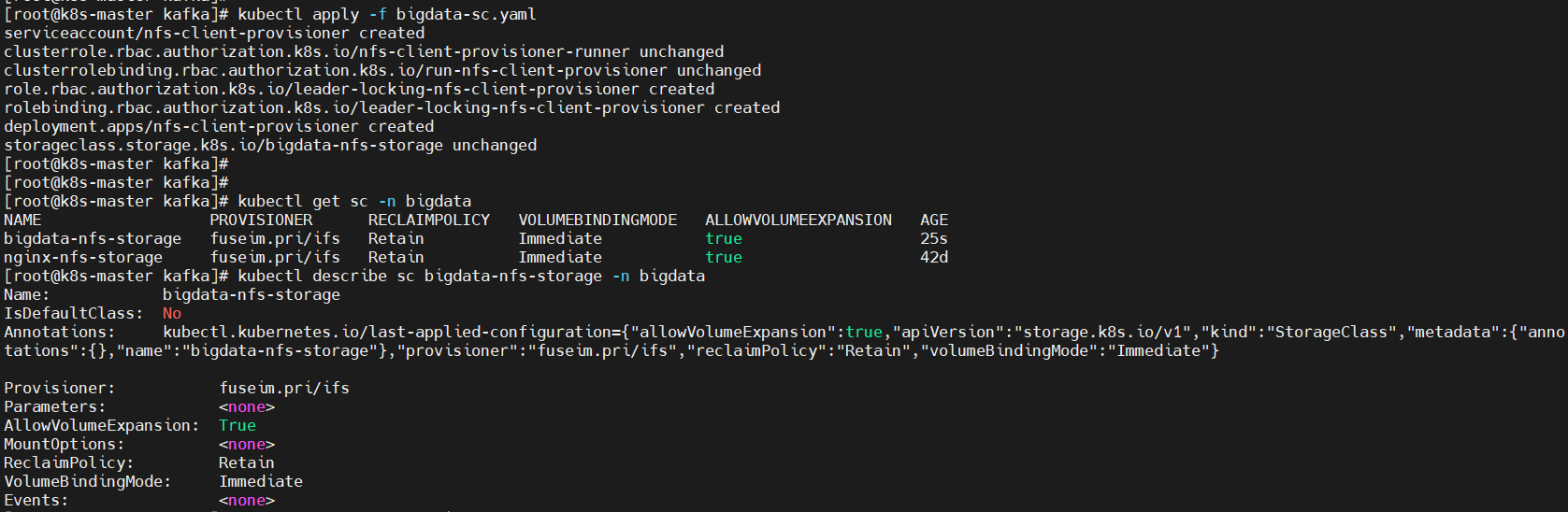
3、helm添加bitnami仓库
$ helm repo add bitnami https://charts.bitnami.com/bitnami
2)部署zookeeper集群
$ helm install zookeeper bitnami/zookeeper \–namespace bigdata \–set replicaCount=3 –set auth.enabled=false \–set allowAnonymousLogin=true \–set persistence.storageClass=bigdata-nfs-storage \–set persistence.size=1Gi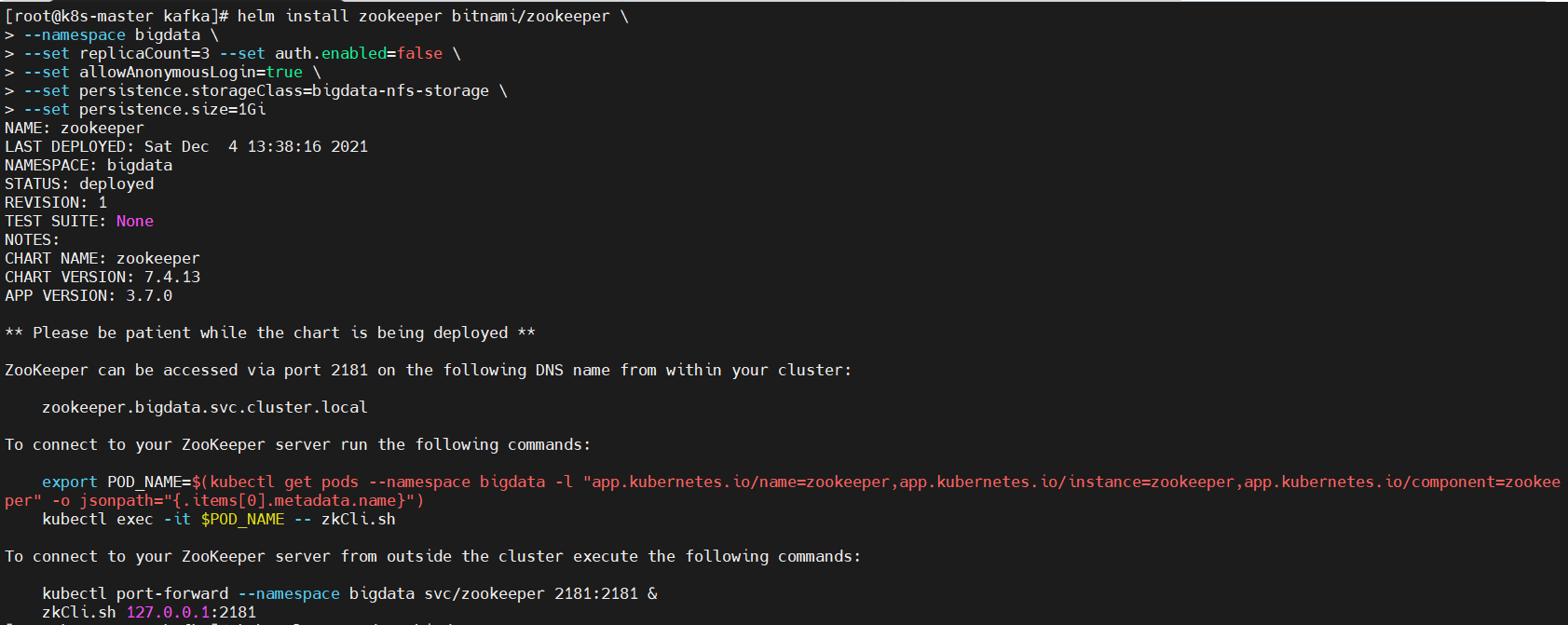
查看,一定看到所有pod都是正常运行才ok
$ kubectl get pod,pv,svc -n bigdata -o wide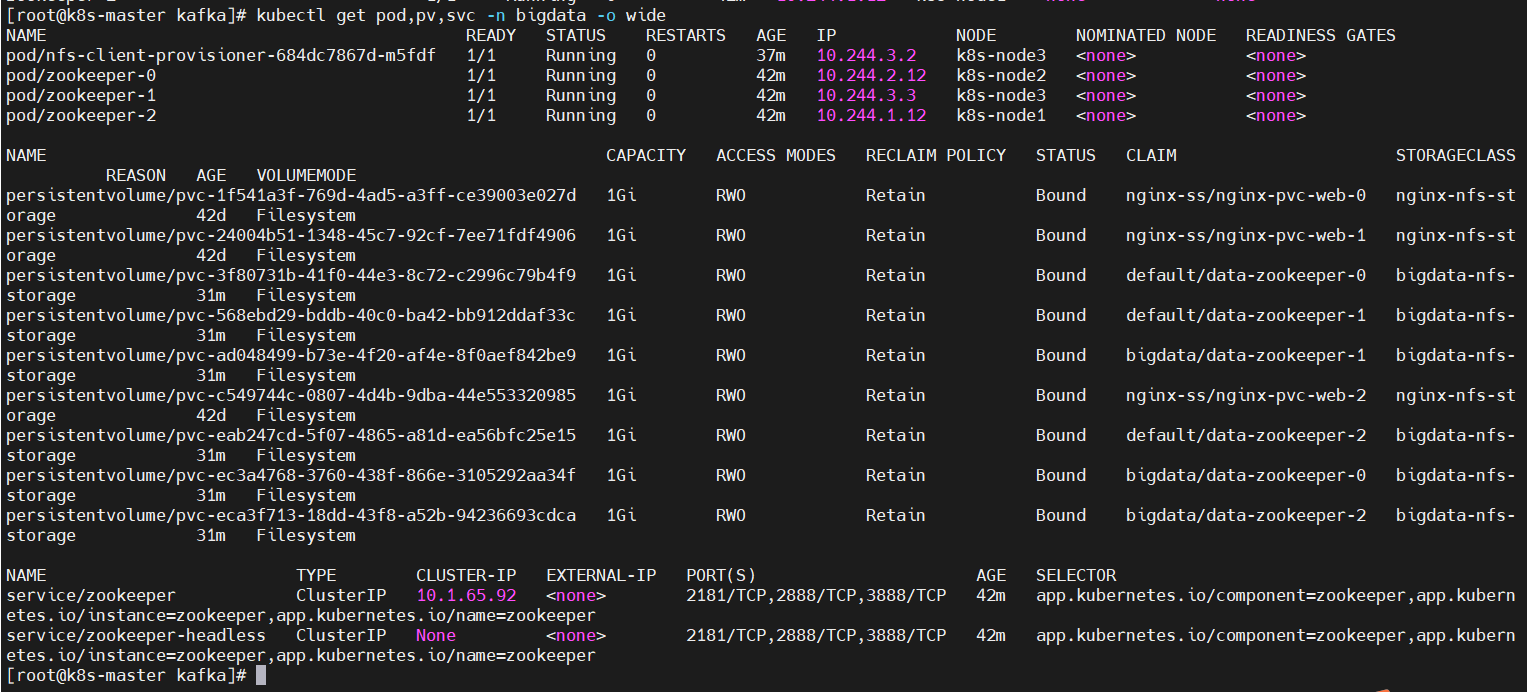
验证内部连接测试
$ export POD_NAME=$(kubectl get pods –namespace bigdata -l “app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/component=zookeeper” -o jsonpath=”{.items[0].metadata.name}”)$ kubectl exec -it $POD_NAME -n bigdata — zkCli.sh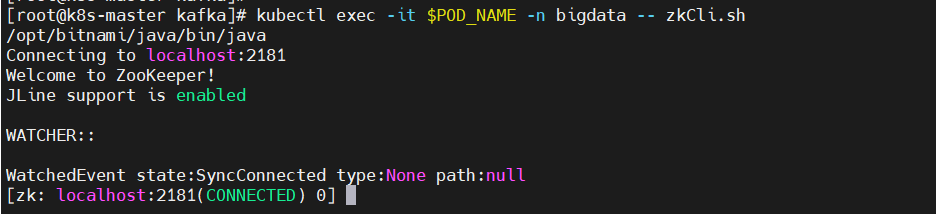
外部连接测试
# 先删掉本地端口对应的进程,要不然就得换连接端口了$ netstat -tnlp|grep 127.0.0.1:2181|awk ‘{print int($NF)}’|xargs kill -9# 外部连接测试$ kubectl port-forward –namespace bigdata svc/zookeeper 2181:2181 需要本机安装zk客户端$ zkCli.sh 127.0.0.1:21
3)部署kafka集群
1、查看zookeeper集群状态
$ helm status zookeeper -n bigdata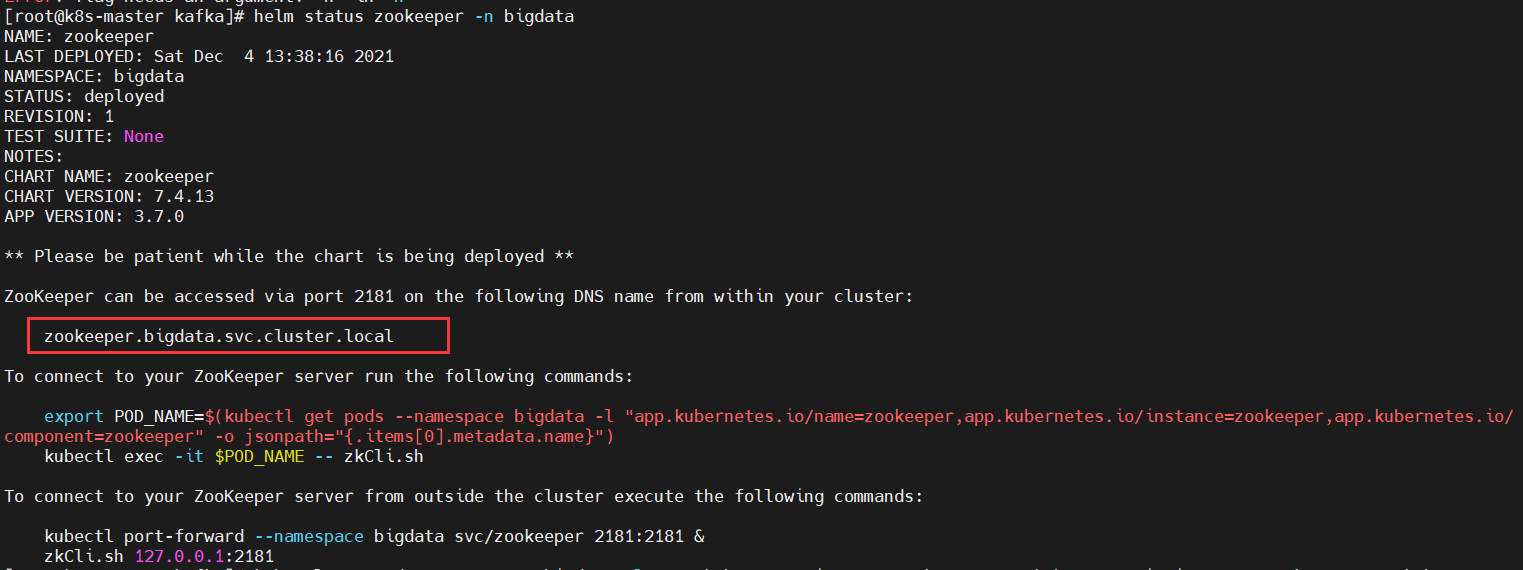
NAME: zookeeperLAST DEPLOYED: Sat Dec 4 13:38:16 2021NAMESPACE: bigdataSTATUS: deployedREVISION: 1TEST SUITE: NoneNOTES:CHART NAME: zookeeperCHART VERSION: 7.4.13APP VERSION: 3.7.0** Please be patient while the chart is being deployed **ZooKeeper can be accessed via port 2181 on the following DNS name from within your cluster: zookeeper.bigdata.svc.cluster.localTo connect to your ZooKeeper server run the following commands: export POD_NAME=$(kubectl get pods –namespace bigdata -l “app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/ component=zookeeper” -o jsonpath=”{.items[0].metadata.name}”) kubectl exec -it $POD_NAME — zkCli.shTo connect to your ZooKeeper server from outside the cluster execute the following commands: kubectl port-forward –namespace bigdata svc/zookeeper 2181:2181 & zkCli.sh 127.0.0.1:2181ZooKeeper can be accessed via port 2181 on the following DNS name from within your cluster:
zookeeper.bigdata.svc.cluster.local安装
$ helm install kafka bitnami/kafka \–namespace bigdata \–set zookeeper.enabled=false \–set replicaCount=3 \–set externalZookeeper.servers=zookeeper.bigdata.svc.cluster.local \–set persistence.storageClass=bigdata-nfs-storage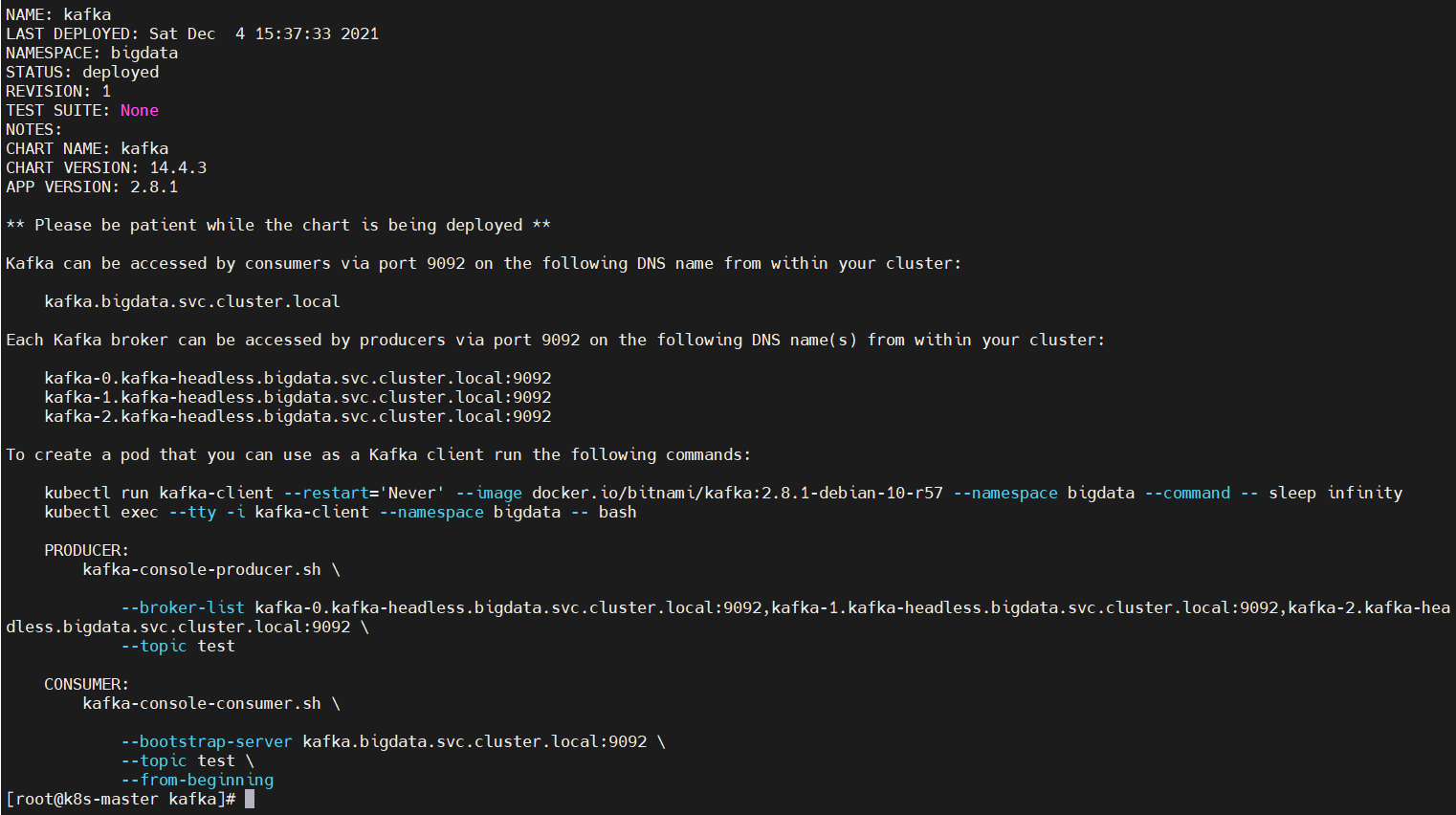
NAME: kafkaLAST DEPLOYED: Sat Dec 4 15:37:33 2021NAMESPACE: bigdataSTATUS: deployedREVISION: 1TEST SUITE: NoneNOTES:CHART NAME: kafkaCHART VERSION: 14.4.3APP VERSION: 2.8.1** Please be patient while the chart is being deployed **Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster: kafka.bigdata.svc.cluster.localEach Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster: kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 kafka-1.kafka-headless.bigdata.svc.cluster.local:9092 kafka-2.kafka-headless.bigdata.svc.cluster.local:9092To create a pod that you can use as a Kafka client run the following commands: kubectl run kafka-client –restart=’Never’ –image docker.io/bitnami/kafka:2.8.1-debian-10-r57 –namespace bigdata –command — sleep infinity kubectl exec –tty -i kafka-client –namespace bigdata — bash PRODUCER: kafka-console-producer.sh \ –broker-list kafka-0.kafka-headless.bigdata.svc.cluster.local:9092,kafka-1.kafka-headless.bigdata.svc.cluster.local:9092,kafka-2.kafka-hea dless.bigdata.svc.cluster.local:9092 \ –topic test CONSUMER: kafka-console-consumer.sh \ –bootstrap-server kafka.bigdata.svc.cluster.local:9092 \ –topic test \ –from-beginning查看
$ kubectl get pod,svc -n bigdata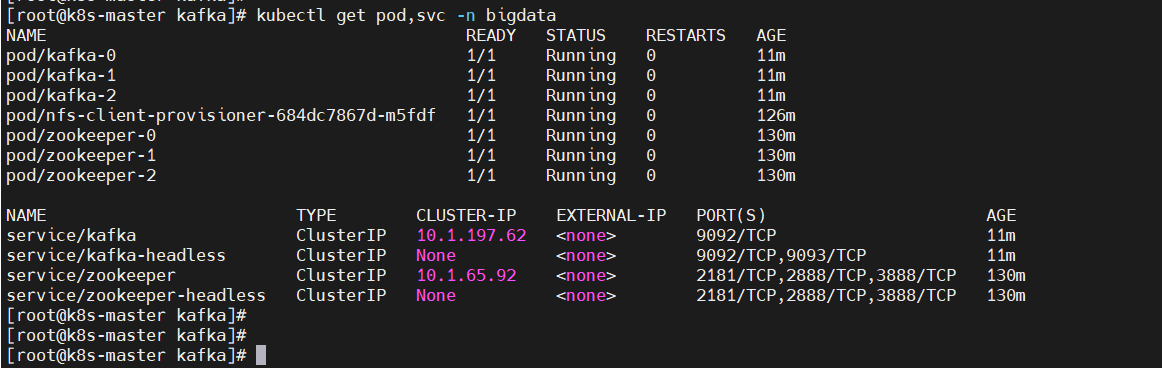
4)简单使用
测试,安装上面提示,先创建一个client
$ kubectl run kafka-client –restart=’Always’ –image docker.io/bitnami/kafka:2.8.1-debian-10-r57 –namespace bigdata –command — sleep infinity打开两个窗口(一个作为生产者:producer,一个作为消费者:consumer),但是两个窗口都得先登录客户端
$ kubectl exec –tty -i kafka-client –namespace bigdata — bashproducer
$ kafka-console-producer.sh \–broker-list kafka-0.kafka-headless.bigdata.svc.cluster.local:9092,kafka-1.kafka-headless.bigdata.svc.cluster.local:9092,kafka-2.kafka-headless.bigdata.svc.cluster.local:9092 \–topic testconsumer
$ kafka-console-consumer.sh \–bootstrap-server kafka.bigdata.svc.cluster.local:9092 \–topic test \–from-beginning在producer端输入,consumer会实时打印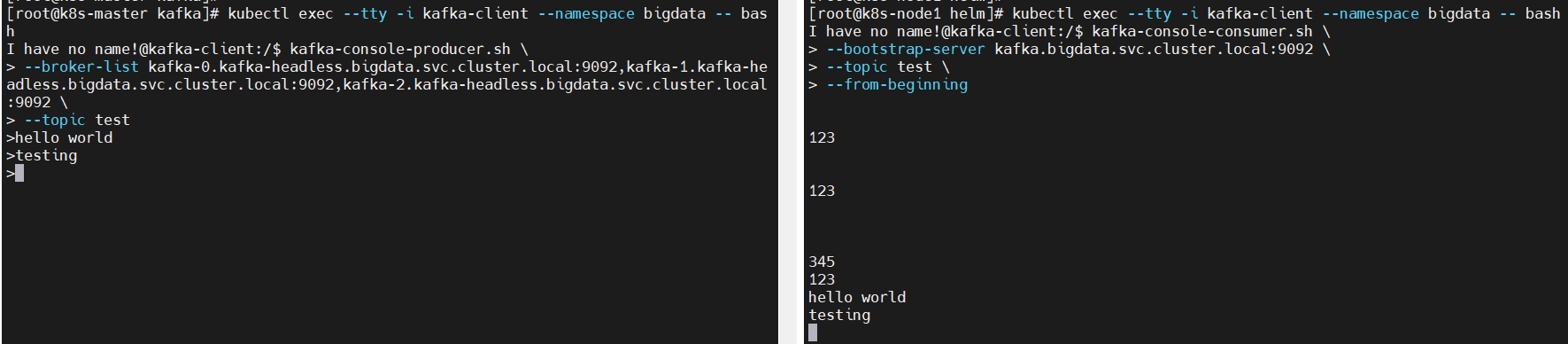
1、创建Topic(一个副本一个分区)
–create: 指定创建topic动作–topic:指定新建topic的名称–zookeeper: 指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样–config:指定当前topic上有效的参数值,参数列表参考文档为: Topic-level configuration–partitions:指定当前创建的kafka分区数量,默认为1个–replication-factor:指定每个分区的复制因子个数,默认1个$ kafka-topics.sh –create –topic mytest –zookeeper zookeeper.bigdata.svc.cluster.local:2181 –partitions 1 –replication-factor 1# 查看$ kafka-topics.sh –describe –zookeeper zookeeper.bigdata.svc.cluster.local:2181 –topic mytest
2、删除Topic
# 先查看topic列表$ kafka-topics.sh –list –zookeeper zookeeper.bigdata.svc.cluster.local:2181# 删除$ kafka-topics.sh –delete –topic mytest –zookeeper zookeeper.bigdata.svc.cluster.local:2181# 再查看,发现topic还在$ kafka-topics.sh –list –zookeeper zookeeper.bigdata.svc.cluster.local:2181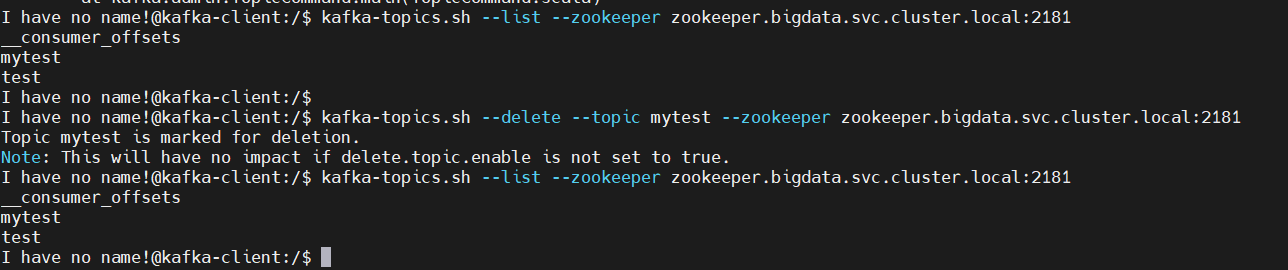
其实上面没删除,只是标记了(只会删除zookeeper中的元数据,消息文件须手动删除)
Note: This will have no impact if delete.topic.enable is not set to true.## 默认情况下,删除是标记删除,没有实际删除这个Topic;如果运行删除Topic,两种方式:
方式一:通过delete命令删除后,手动将本地磁盘以及zk上的相关topic的信息删除即可方式二:配置server.properties文件,给定参数delete.topic.enable=true,重启kafka服务,此时执行delete命令表示允许进行Topic的删除3、修改Topic信息
kafka默认的只保存7天的数据,时间一到就删除数据,当遇到磁盘过小,存放的数据量过大,可以设置缩短这个时间。
# 先创建一个topic$ kafka-topics.sh –create –topic test001 –zookeeper zookeeper.bigdata.svc.cluster.local:2181 –partitions 1 –replication-factor 1# 修改,设置数据过期时间(-1表示不过期)$ kafka-topics.sh –zookeeper zookeeper.bigdata.svc.cluster.local:2181 -topic test001 –alter –config retention.ms=259200000# 修改多字段$ kafka-topics.sh –zookeeper zookeeper.bigdata.svc.cluster.local:2181 -topic test001 –alter –config max.message.bytes=128000 retention.ms=259200000$ kafka-topics.sh –describe –zookeeper zookeeper.bigdata.svc.cluster.local:2181 –topic test001
4、增加topic分区数
$ kafka-topics.sh –zookeeper zookeeper.bigdata.svc.cluster.local:2181 –alter –topic test –partitions 10$ kafka-topics.sh –describe –zookeeper zookeeper.bigdata.svc.cluster.local:2181 –topic test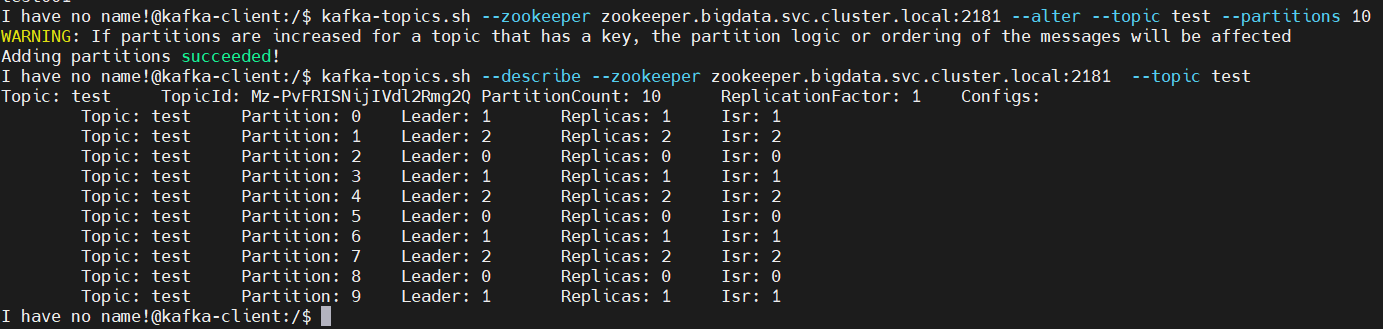
5、查看Topic列表
$ kafka-topics.sh –list –zookeeper zookeeper.bigdata.svc.cluster.local:2181
6、列出所有主题中的所有用户组
$ kafka-consumer-groups.sh –bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 –list7、查询消费者组详情(数据积压情况)
# 生产者$ kafka-console-producer.sh \–broker-list kafka-0.kafka-headless.bigdata.svc.cluster.local:9092,kafka-1.kafka-headless.bigdata.svc.cluster.local:9092,kafka-2.kafka-headless.bigdata.svc.cluster.local:9092 \–topic test# 消费者带group.id$ kafka-console-consumer.sh –bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 –topic test –consumer-property group.id=mygroup# 查看消费组情况$ kafka-consumer-groups.sh –bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 –describe –group mygroup 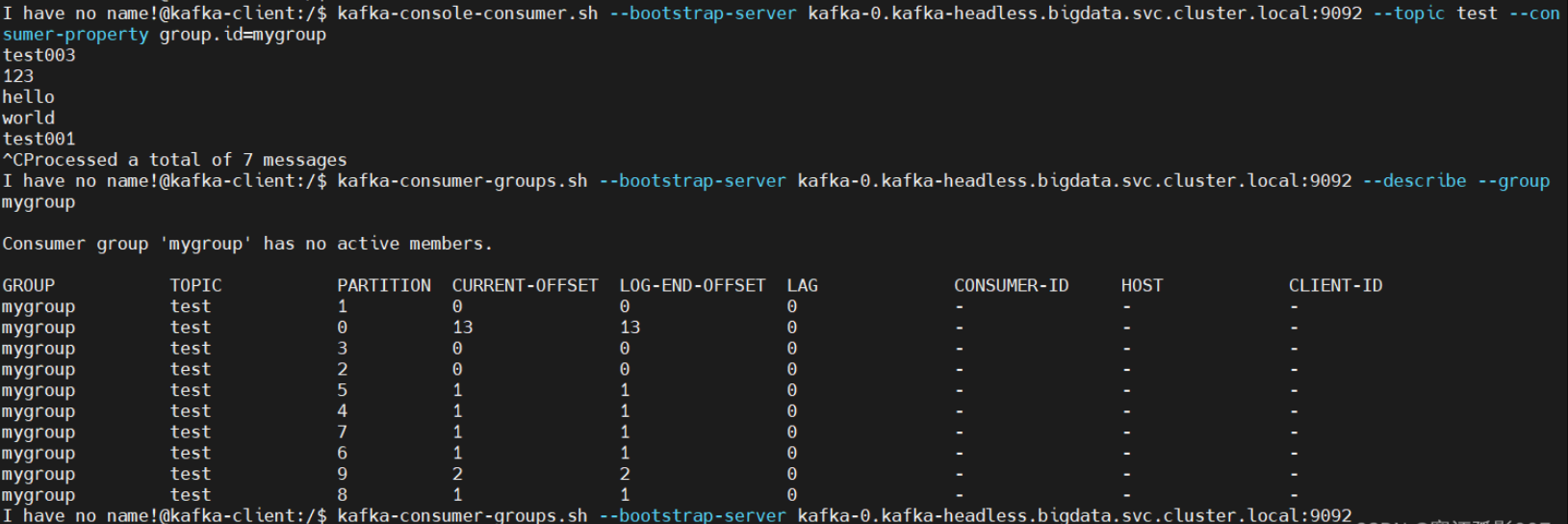
消费积压情况分析
LogEndOffset:下一条将要被加入到日志的消息的位移CurrentOffset:当前消费的位移LAG:消息堆积量:消息中间件服务端中所留存的消息与消费掉的消息之间的差值即为消息堆积量也称之为消费滞后量生产和消费的操作上面已经实验过了,这里就不再重复了,更多的操作,可以参考kafka官方文档
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/83593.html
