

前段时间,微信PC版更新了OCR功能,可以识别照片中的文字。
老实说,这一定是微信在过去十年中推出的最有用的功能之一。
例如,如果您使用微信截图,只需点击下面的“识别文字”即可获取截图中的文字。
对于微信收到的照片,也可以直接选择复制文字。
除了实用的功能外,微信早已成为电脑上必备的软件,微信截图也是很多人默认的截图工具。
因此,微信OCR具有相同的系统功能,以后如果遇到无法复制的文字,只需调用微信即可。

一般来说,微信OCR可以满足大多数人的需求。
然而,它的功能相对基础,因此在特殊情况下可能显得有点笨拙。
例如,如果您有大量文本需要识别,您可能需要多次截图,重新识别,并一遍又一遍地复制。
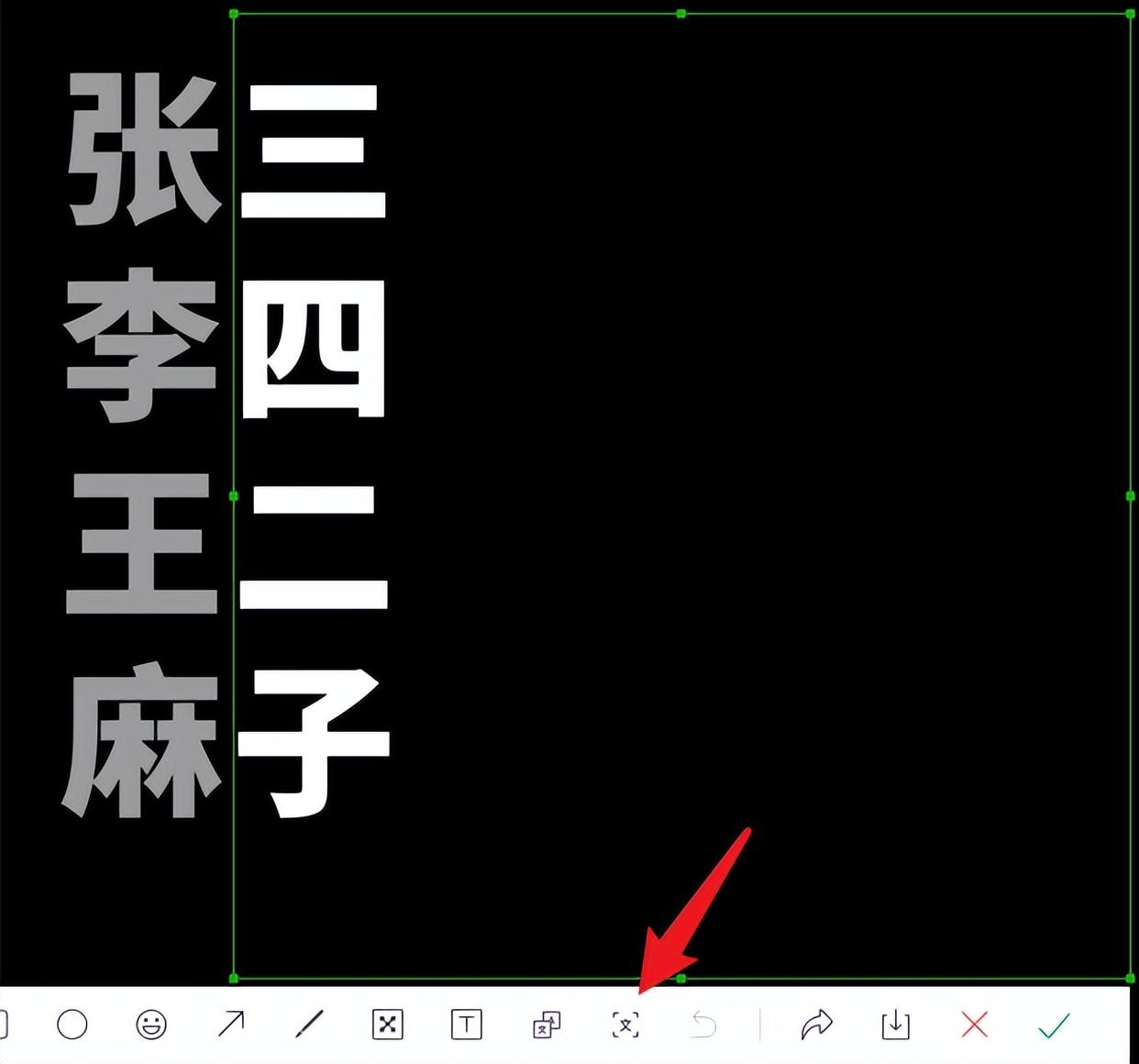
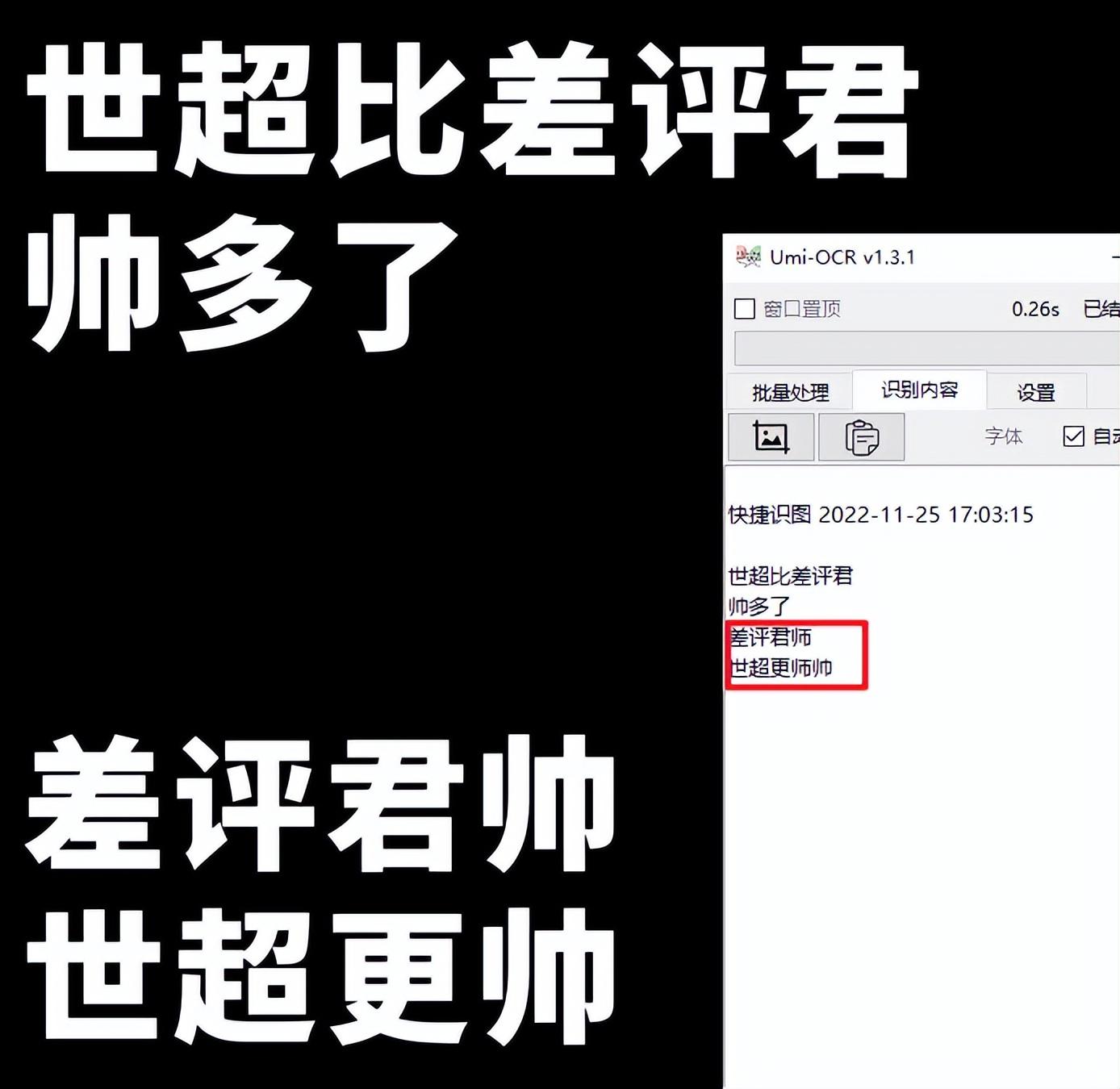
或者你想OCR一首古诗词,如果文字是竖排的、从右到左的,微信识别的顺序就会被打乱。
最近,世超发现了一个名为Umi-OCR(支持Win1011)的工具。
它的功能非常强大,可以批量识别图片,选择遮挡区域,指定文字方向,微信做不到的一切。
哦,最重要的是,它是免费和开源的,不需要安装或网络,并且可以离线使用。

让我们快速演示一下。
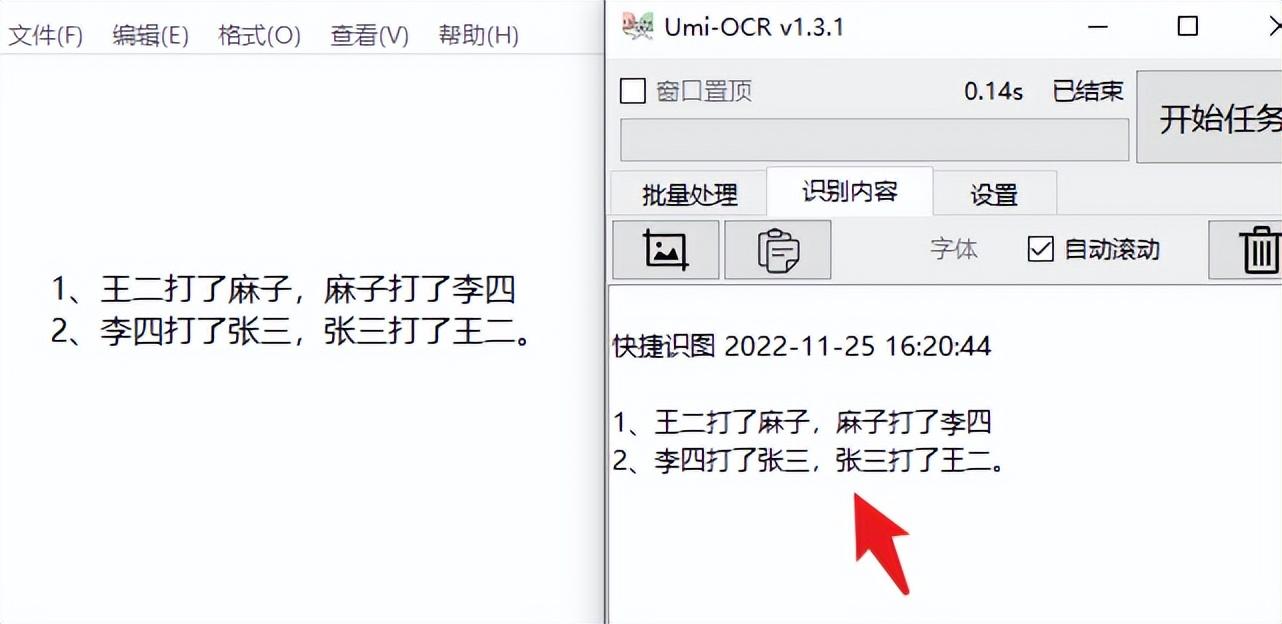
对于需要花钱复制的文字,比如下面的文字,你可以点击软件的截图功能,对文字进行取框,0.73秒即可获得文字。
它在本地运行,因此您的计算机速度越快,速度就越快。
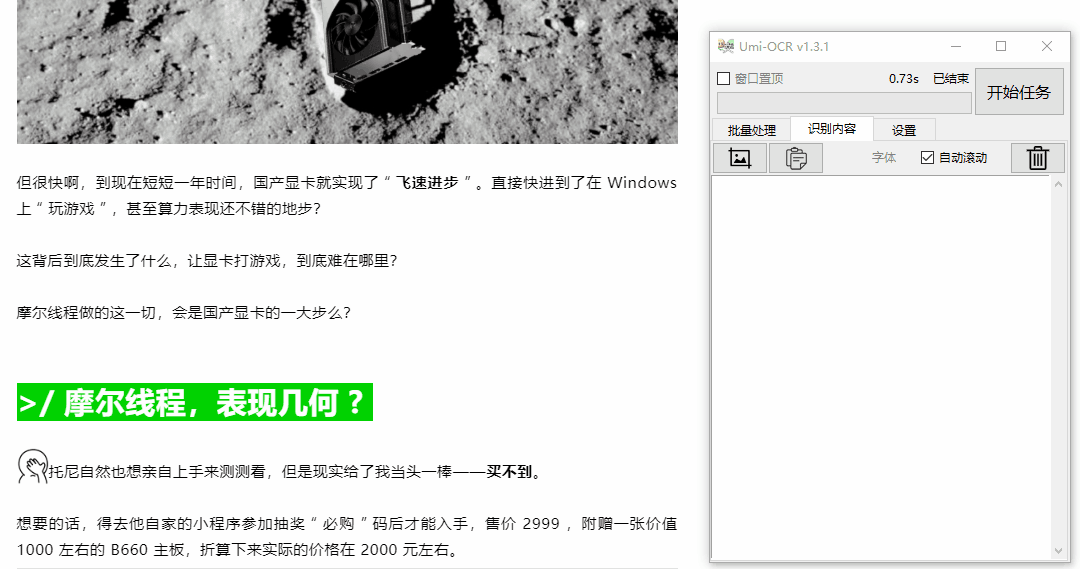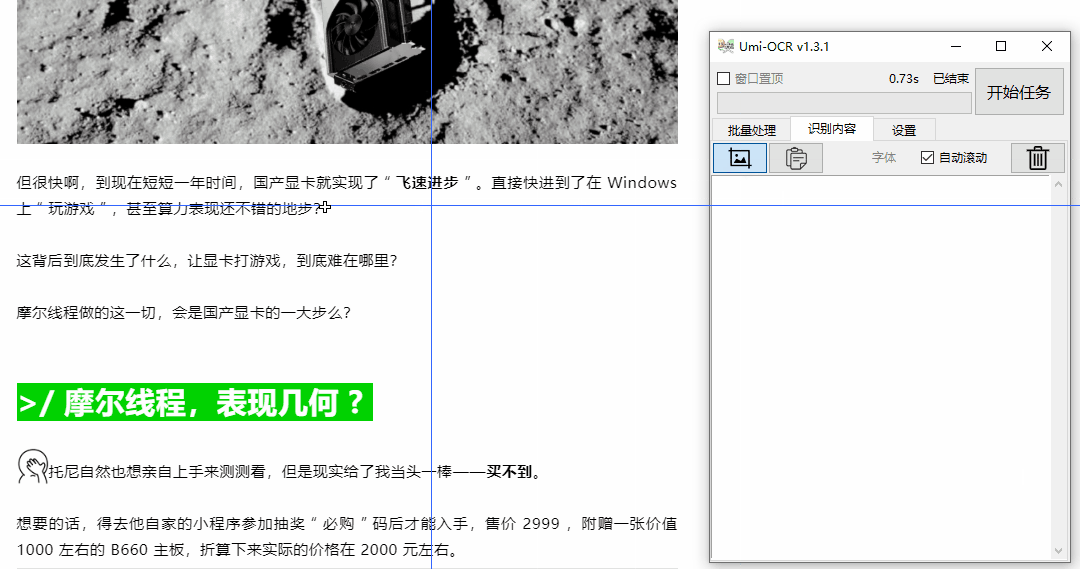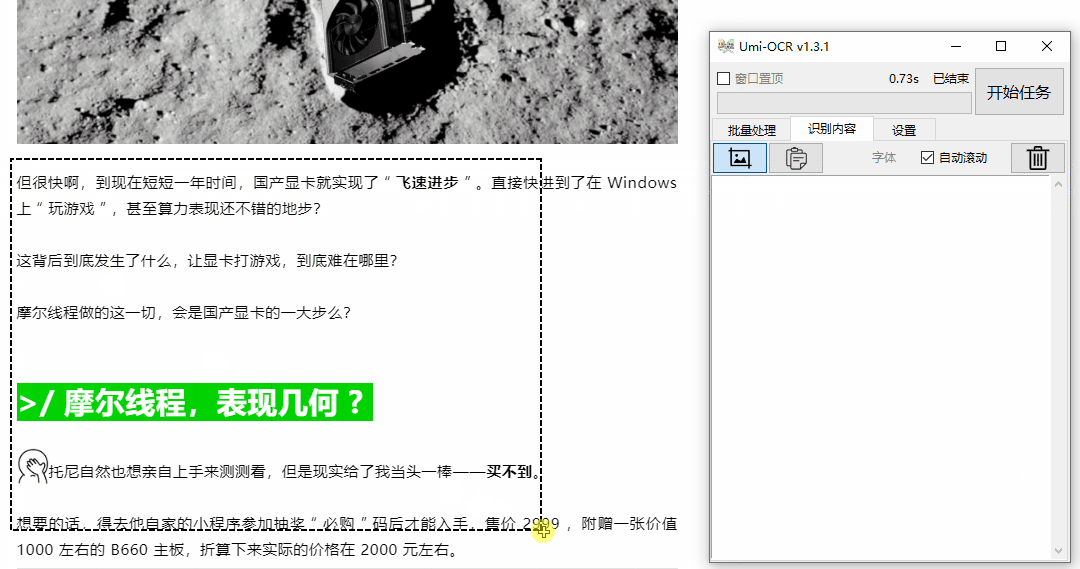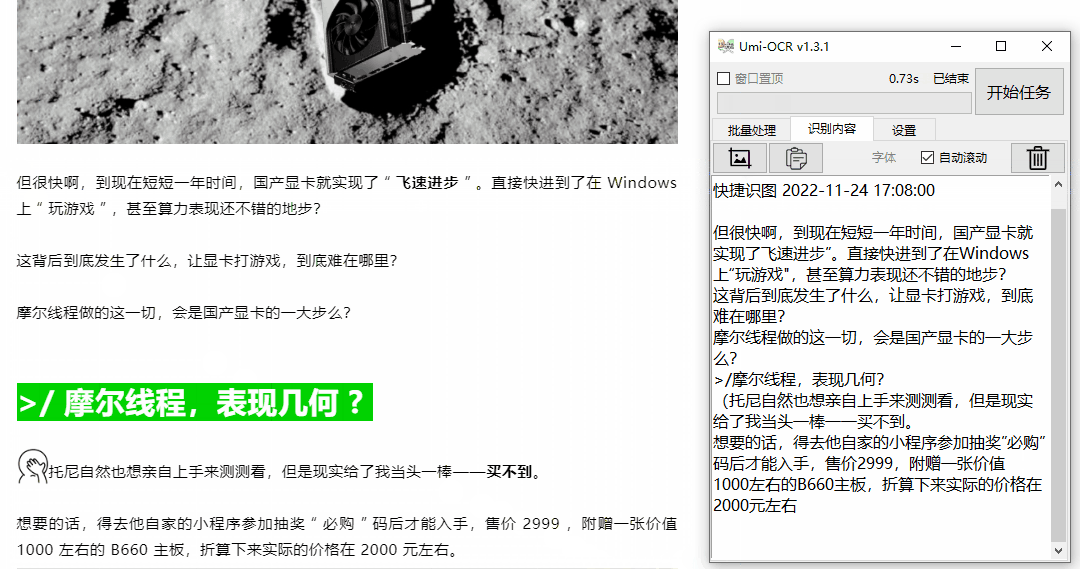
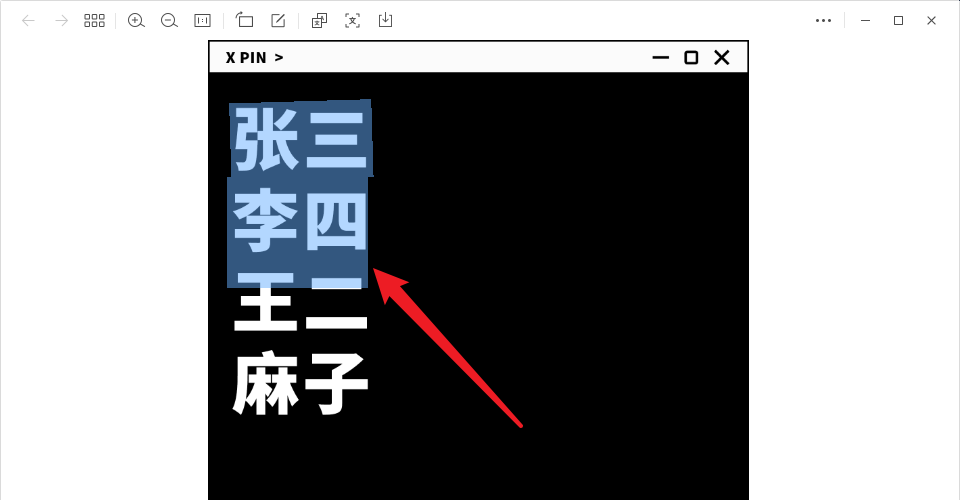
与微信不同的是,Umi-OCR 自带了一个记录板,每次识别出一条文字,都会显示并保存在记录板上。
这意味着,如果您有大量文本需要识别,您可以像连续狙击手一样进行连续截图。
拍完所有照片后,黑胶唱片上的所有文字都被识别了。
此时复制和粘贴就会容易得多。

当然,如果您已经将所有照片存储在本地,那就更方便了。
Umi-OCR支持批量识别。如果你是前面提到的连续狙击手,这个功能就是一键加特林。
只需输入几百张照片,然后让Umi-OCR 完成剩下的工作。
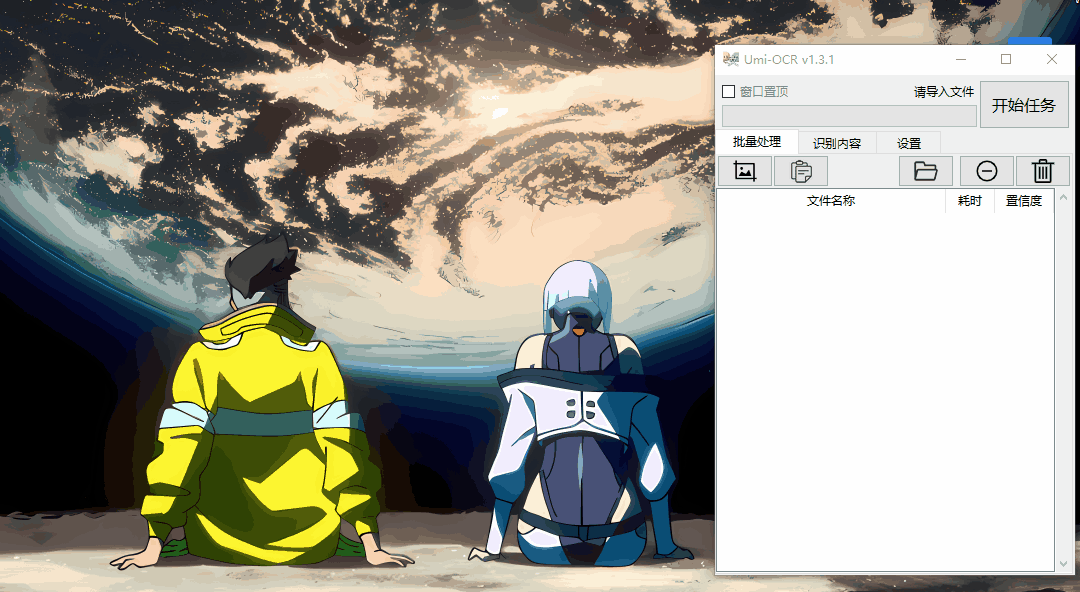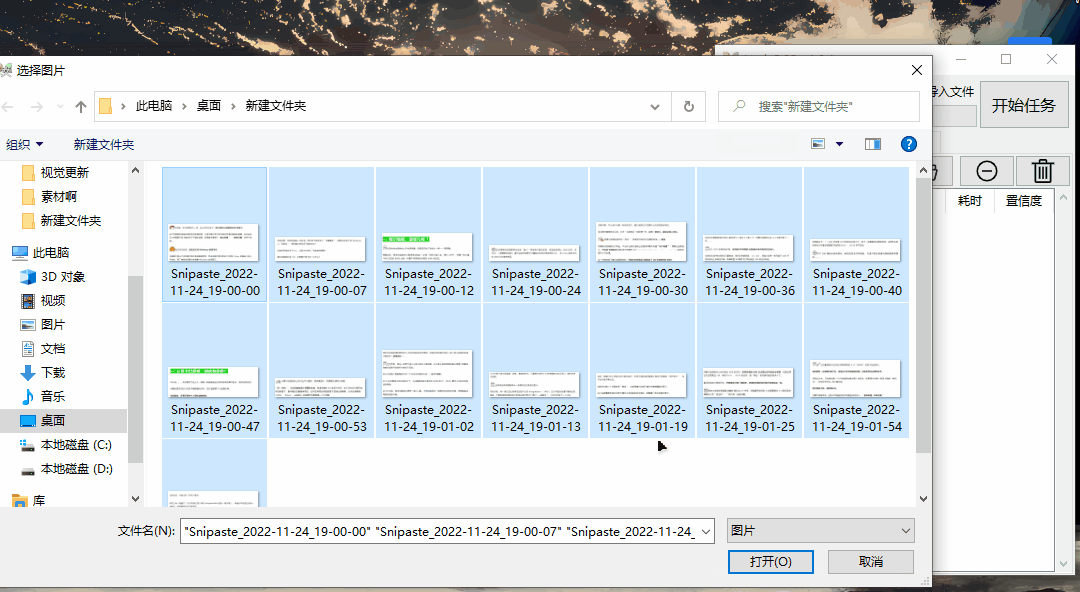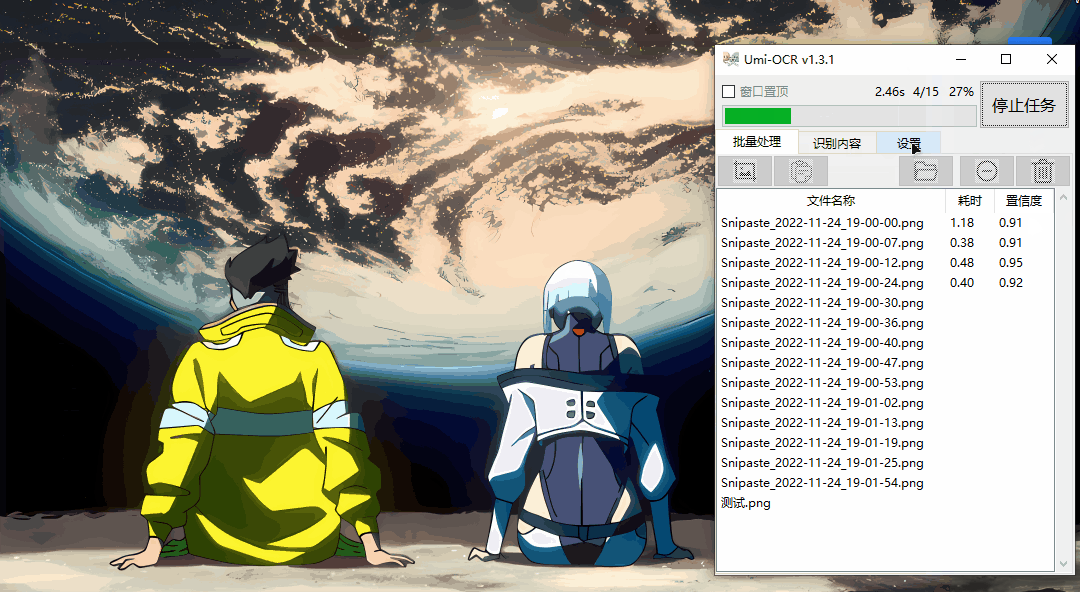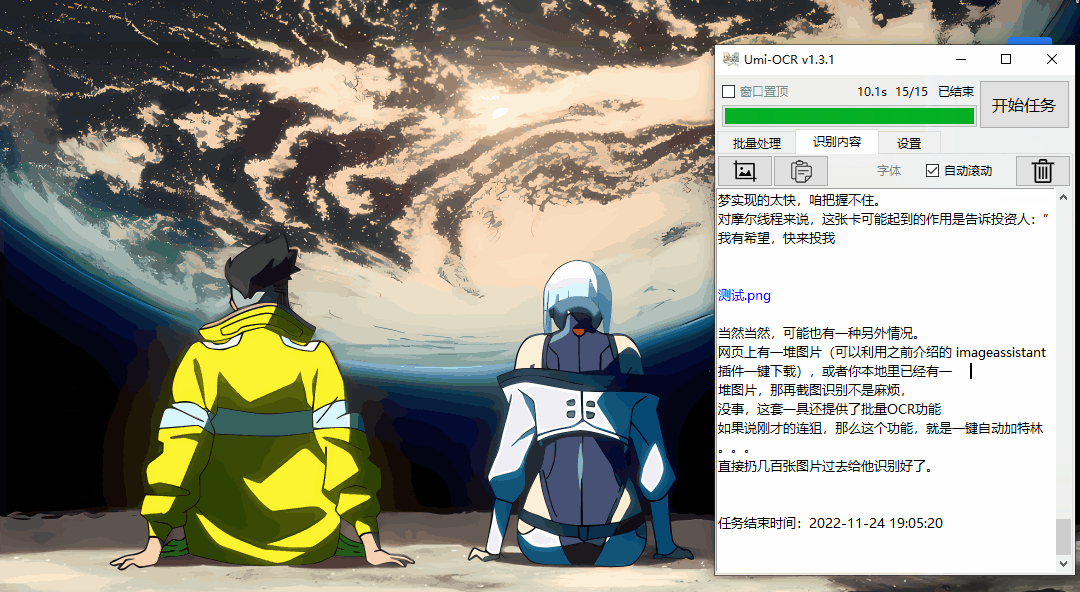
然后记录上将出现一串字符。
同时,识别结果也保存在txt文件中,成为完整的一站式服务。
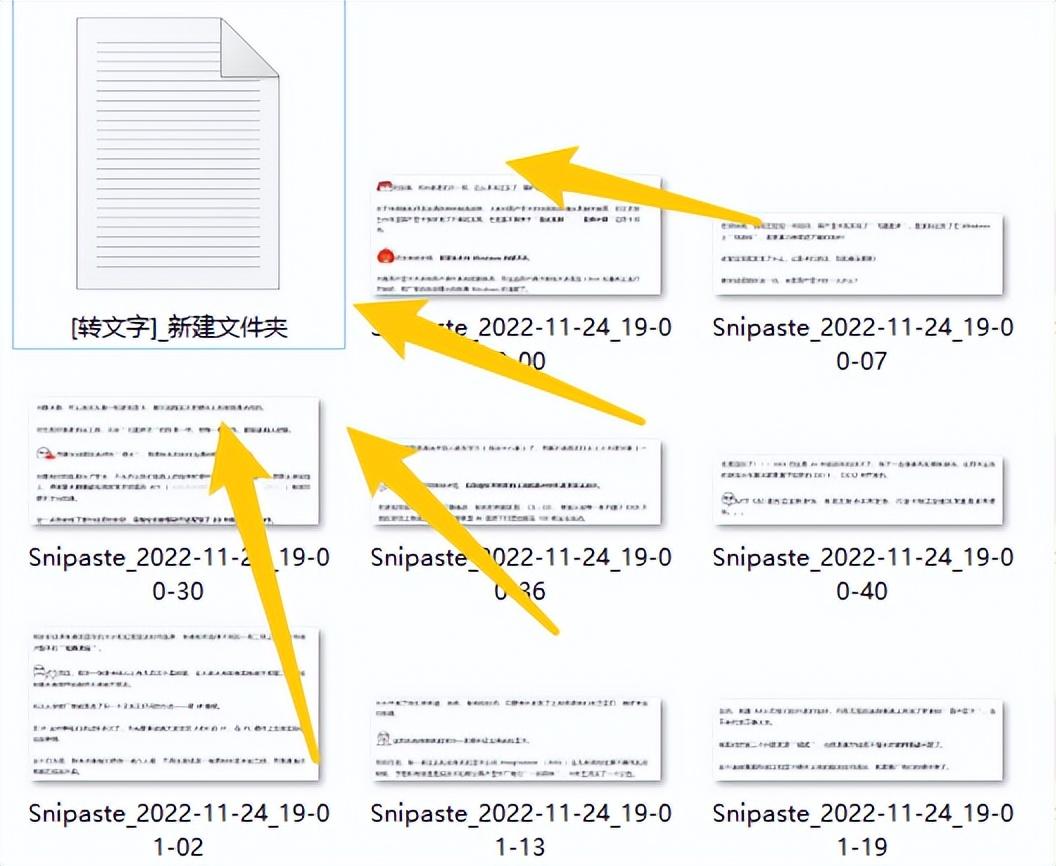
txt 不是必需的,如果您想要md 或jsonl 格式,也可以,因为它们都受支持。

除了上面列出的项目外,Umi-OCR 还具有一些可以处理特殊情况的详细功能。
例如,在下图中,我们只想要文本中的句子,而不想要水印等其他无效信息。
对于照片,只需截取屏幕截图并标记该区域即可。
但是如果你有100 张相似的图像怎么办?
该软件支持指定识别区域。
只要导入照片并选择要遮挡的区域,后续所有相同分辨率的图片在识别时都会自动遮挡这些区域。
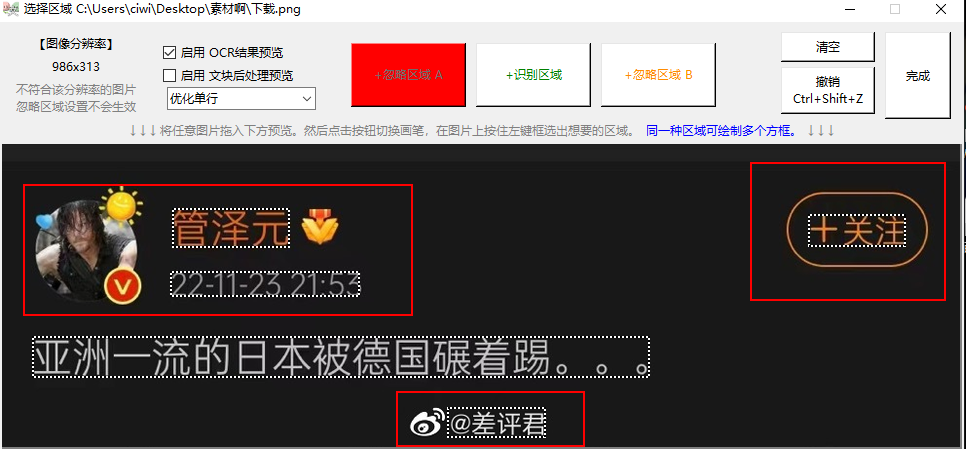
这样批量识别的结果就只是需要的部分。

此外,Umi-OCR 允许您调整段落。
这是什么意思呢?一般来说,OCR段落识别都是以行间距为参考,如果行间距大,就判定是下一个段落。

但是,如果遇到以下特殊格式,其中一个句子是一个段落,并且它们非常接近,OCR 工具会将它们识别为一个句子并将它们组合起来。
比如微信是这样识别的。

不过,Umi-OCR 支持段落优化,您可以为每种段落格式选择不同的设置,例如单行优化、左对齐和自然段落。
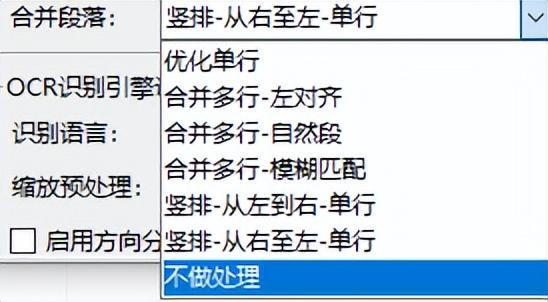
如果遇到上述格式,可以选择“优化单行”。
其他情况还有选项,如下图所示,供参考。

最后,Umi-OCR还支持改变文本识别方向。
例如,如果您想识别古诗词,只需选择“文字方向为垂直,从右到左”即可。

对了,忘了提一下,Umi-OCR 除了识别中文和英文之外,还可以通过导入多语言识别扩展包来识别繁体中文、日文、韩文、俄文、德文,还支持等语言。法语。链接将放在文章末尾。
我想大家关心的是它的识别准确率,但我只能说表现还可以。
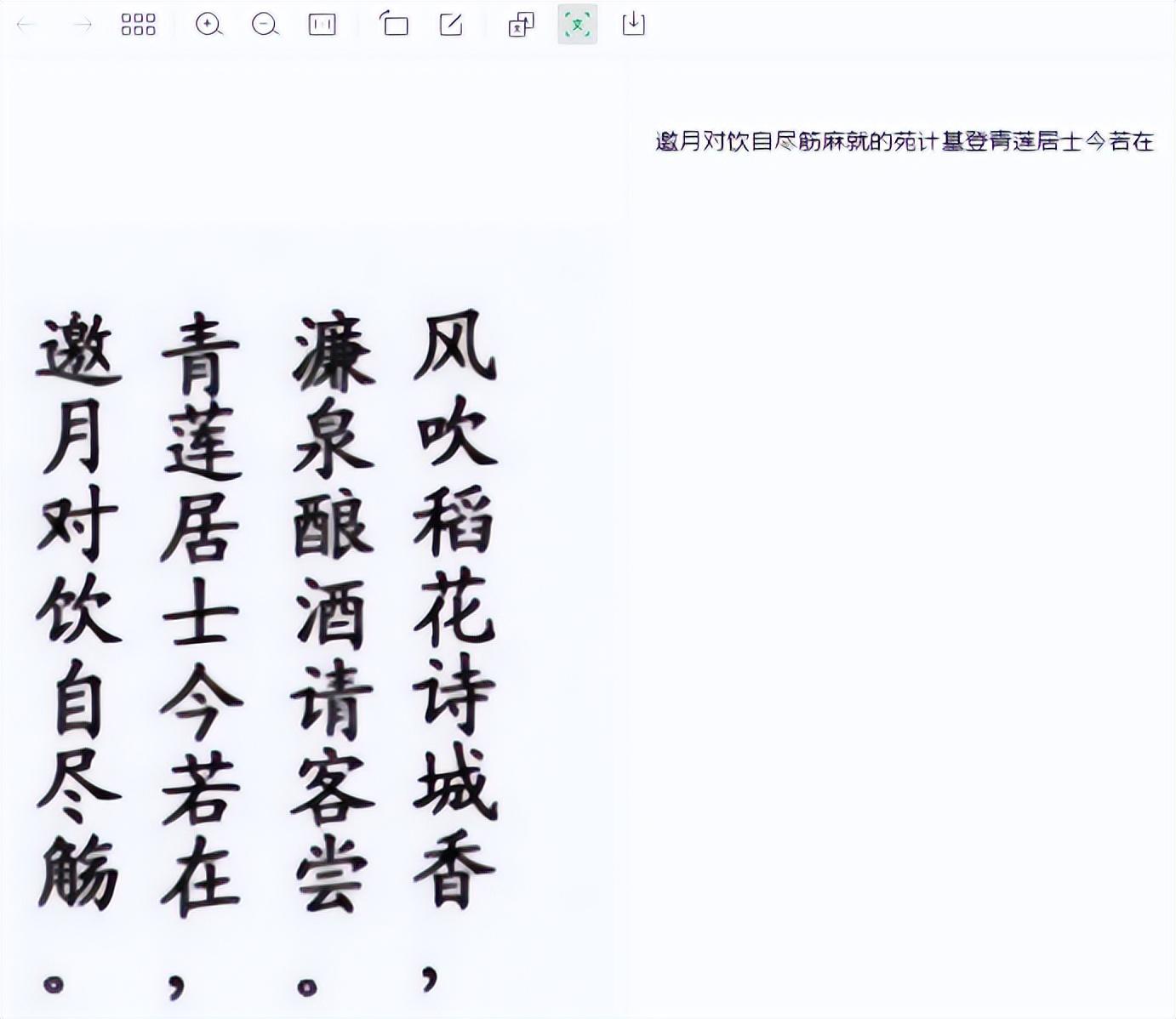
在第一张测试图像中,世超发现面对面的表情被识别为((),后面缺少引号和句号。
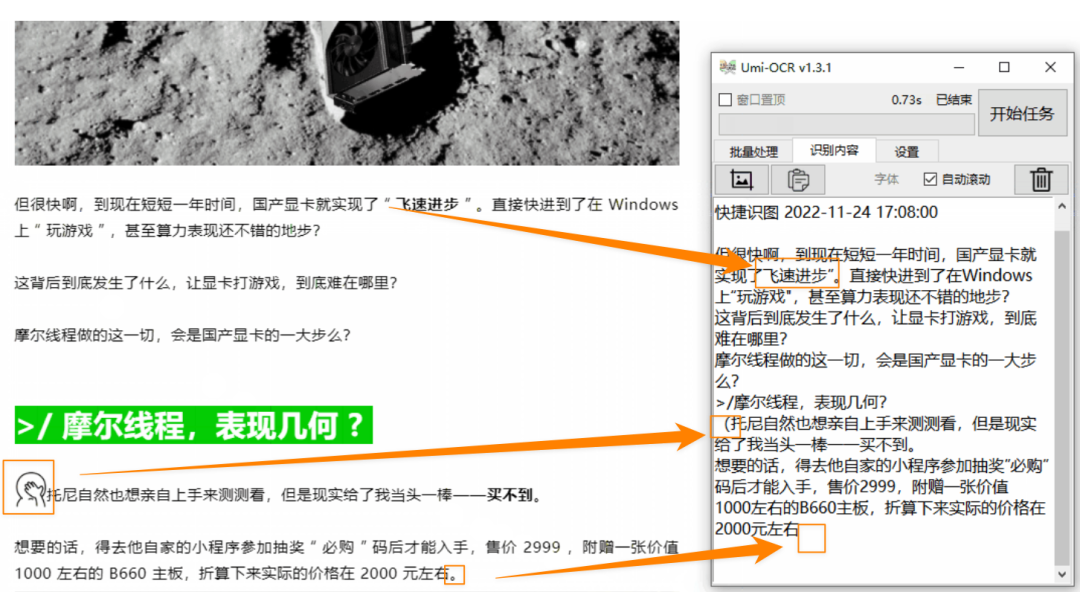
毕竟,像这篇文章一样每篇文章都包含表情符号的文章并不多。
它缺少引号和句号,但我认为它是无害的。
然而,除了这些问题之外,Umi-OCR 还识别出错误的单词,例如将“最终”识别为“花镜”。

另外,世超建议不要用它来识别一些粗体文本,因为效果并不理想。
当然,市面上没有任何OCR工具可以保证100%的准确率,所以不要拒绝使用Umi-OCR。
就像上面的古诗一样,Umi-OCR 把最后一个字弄错了,但微信OCR 识别后,正确的就很少了。
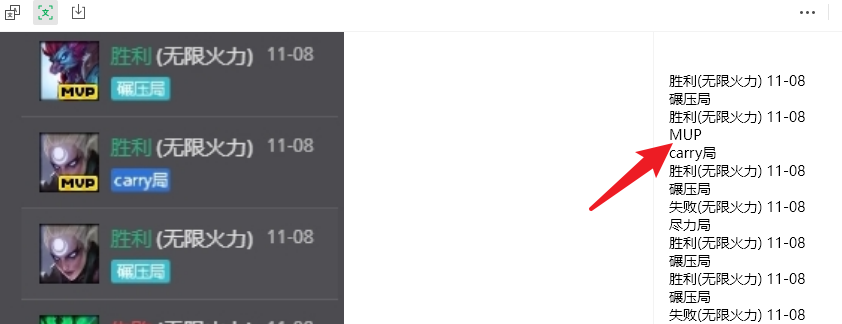
此外,微信OCR 还将MVP 粗体识别为MUP。
所以在使用OCR时,无论使用哪家公司,都要做好识别错误的准备。世超建议每次都自己检查一下。
再次强调,如果您只是偶尔需要OCR,微信是更好的选择。
但是,如果您的需求非常大且具体,并且担心隐私泄露,那么这款Umi-OCR 是更好的选择。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/84428.html