
例如,在打印出您辛辛苦苦写下的信息后,您意识到自己收集了一些名片,但却丢失了文件。信息一一传递起来非常麻烦。
那么,有没有技术可以帮助解决这些问题呢?
是的,这就是OCR字符识别技术。

OCR的正式英文名称为Optical Character Recognition,中文名称为光学字符识别。它利用光学和计算机技术来读取打印或写在纸上的文本,并将其转换成计算机可以接受、人类可以理解的格式。
例如,手机应用程序可以通过扫描名片或身份证来帮助识别汽车中的信息。读书时还采用了车牌识别技术,进入停车场或收费站时无需手动登记。您会看到一个您不明白的问题,您可以扫描手机并使用该应用程序在线查找该问题的答案。这一切都得益于OCR 技术。

OCR识别系统的目的非常简单:如果有一张表格,它就会对图像进行转换,以便能够继续保留图像中的图形。通过转换为计算机文本,可以减少图像数据的存储容量,并重新利用和分析识别出的文本,大大节省了键盘输入所需的精力和时间,提高了OA程度,实现了真正的目的。 – 端到端业务流程自动化。
下图显示了一个典型的OCR 流程。

其中,影响识别准确率的技术瓶颈是文本检测和文本识别,这两部分也是OCR技术的重中之重。
1. 图像预处理
纸张厚度、平滑度和打印质量会造成字符变形、断笔、粘连、脏污等干扰,因此在字符识别之前必须对噪声图像进行处理。
这种处理称为预处理,因为它发生在文本识别之前,通常包括灰度、二值化、倾斜检测和校正、行和词分割、平滑、归一化等。
传统OCR基于数字图像处理和传统机器学习等方法处理图像并提取特征。常用的二值化过程对于增强简单场景中的文本信息很有效,但对复杂背景的二值化效果不大。
随着深度学习的快速发展,基于CNN的神经网络已成为常用的特征提取方法。得益于CNN强大的学习能力,可以利用大量的数据来增强特征提取的鲁棒性,在面对模糊、畸变、畸变、复杂背景、光照不清晰等图像问题时也提供了优异的性能。
2. 文本检测
CTPN(连接主义文本提议网络)是当今使用最广泛的文本检测模型之一。
基本前提是单个字符比高度异构的文本行更容易检测,因此首先检测单个字符,就像R-CNN 一样。
然后将双向LSTM 添加到检测网络中,检测结果形成一个提供文本上下文特征的序列,允许多个字符组合以获得一行文本。
一些研究引入了注意力机制。下图所示的模型使用密集注意力模型来评估图像权重。这有助于分离前景和背景图像,并使检测结果更加准确,因为它专注于文本内容而不是背景图像。
3.文字识别
视觉注意力模型(CNN + LSTM + 考勤技术)。该模型首先使用滑动窗口CNN(卷积神经网络)方法提取图像上的图像特征,然后堆叠LSTM(长短期记忆网络)。 )进行序列特征提取,最后使用注意力模型作为解码器输出最终的文本序列。
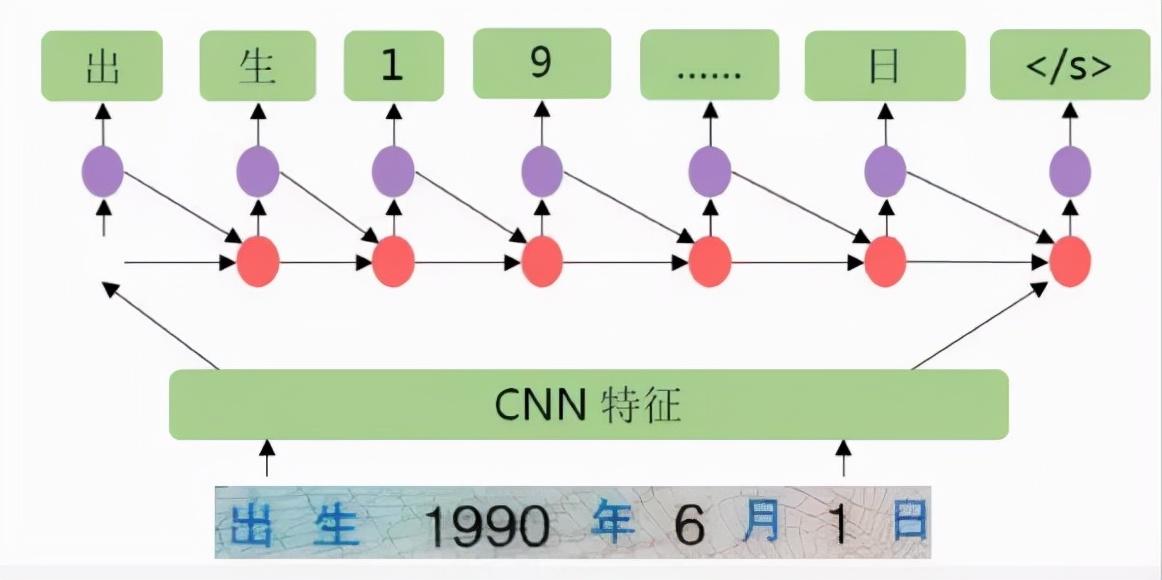
虽然基于深度学习的OCR性能优于传统方法,但深度学习技术在OCR领域仍然需要专业化。另一方面,数据在推动深度学习方面发挥着关键作用,这需要大量的数据收集。现阶段,高质量的数据也是OCR性能的重要衡量标准之一。
利用OCR技术,可以快速高效地收集和录入信息,无需在录入和登记上花费人力资源或大量物理资源。不仅节省了时间和成本,大大提高了工作效率,而且颠覆了传统的工作模式,为各领域信息化的进步做出了贡献。

原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/84452.html