
来源:【公众号】
Python技术
爬虫(在FOAF 社区中也称为网络蜘蛛、网络机器人或网络追逐者)是一种按照特定规则自动爬取网络信息的程序或脚本。
如果把互联网比作一张大蜘蛛网,那么你电脑上的数据就是蜘蛛网的猎物,而爬虫程序沿着网络爬行,捕获它想要的猎物或数据。
爬虫的基本流程

网页的请求与响应
网页请求和响应方式分别为请求和响应
请求:用户通过浏览器(socket客户端)将自己的信息发送到服务器(socket服务器)。
响应:服务器接收请求,分析用户提交的请求信息,收到请求信息后返回数据(返回的数据可能包括图片、js、css等其他链接)。
浏览器收到响应后,解析其内容并将其显示给用户。另一方面,爬虫程序模拟浏览器发送请求并接收响应,然后提取有用的数据。
发起请求:Request
通过http库向目标站点发起请求。即发送请求。
Request 对象的功能是与客户端交互并收集客户端表单、cookie 和超链接或服务器端环境变量。
Request 对象是从客户端发送到服务器的请求,其中包括用户发送的信息和客户端发送的一些信息。客户端可以通过HTML表单或在网页地址后指定参数来提交数据。
然后,服务器通过请求对象的关联方法检索该数据。各种请求方法主要用于处理客户端浏览器发送的请求中的不同参数和选项。
请求包括请求URL、请求标头、请求正文等。
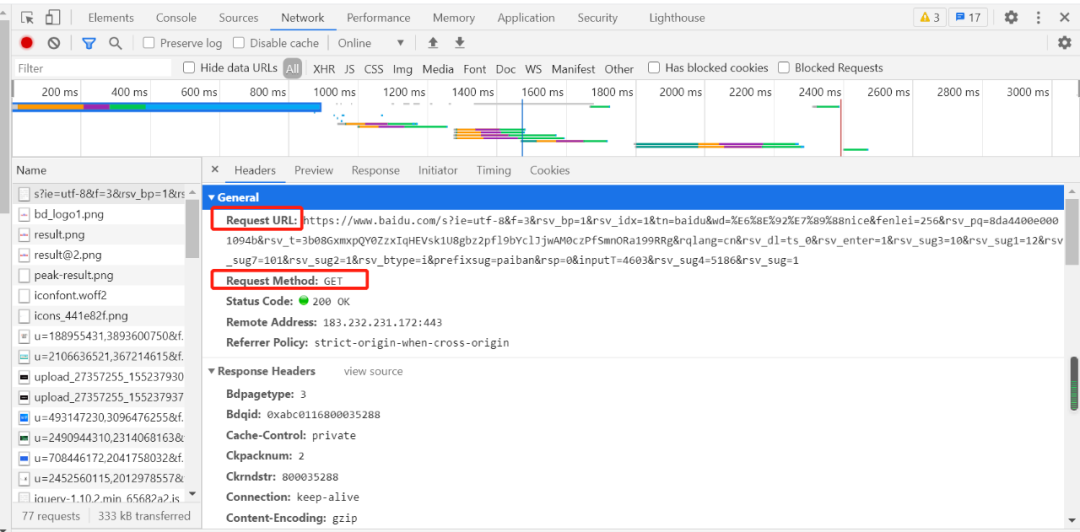
请求请求方式:GET/POST
请求url: URL 的正式名称是统一资源定位器。 Web 文档、图像、视频等由其URL 唯一确定。
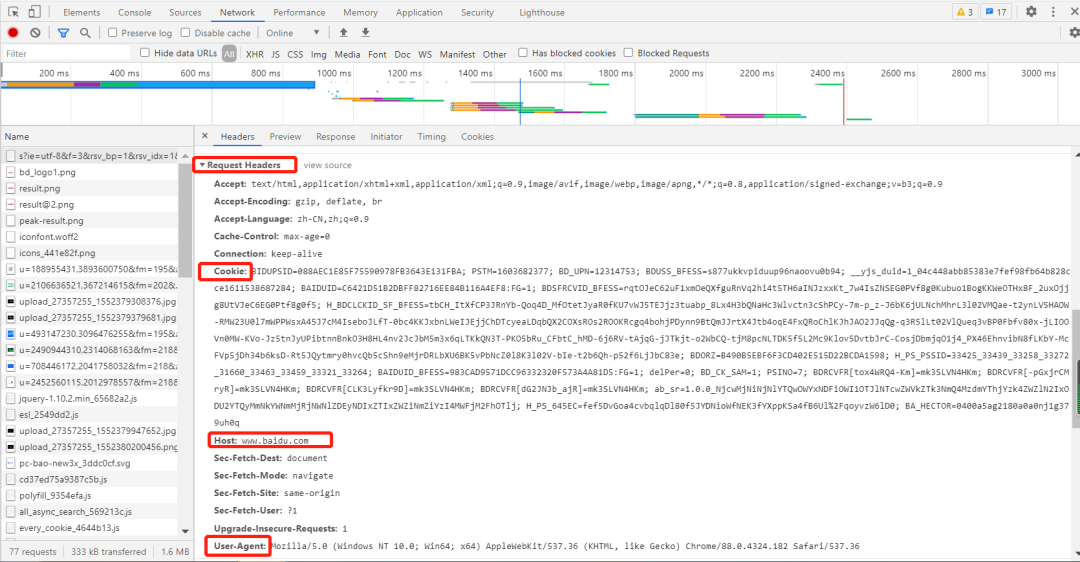
请求标头: 用户代理:如果请求标头中缺少用户代理客户端配置,服务器可能会将用户视为未经授权的用户。
Cookie:Cookie 用于保存登录信息。
通常,当您运行爬网程序时,会添加请求标头。示例:抓取百度URL的数据请求信息为:
获取响应内容
爬虫程序发送请求后,会收到Response,如果服务器能够响应成功。
响应信息包括html、json、照片、视频等。如果没有报错,则可以查看网页的基本信息。示例:这是一个检索网页响应内容的程序。
importrequestsrequest_headers={‘接受’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-交换;v=B3’,’cookie’3360’bidupsid=1603682377;BFESS=S877UKKVPIDUP96NAOOVU0B94;S_DUID=1_04C448ABB85383E7FEF98FB64B828CCE1611538687284; MOEQXFGURNVQ2HI4THI4TH6AINJZXXKT_7W4ISZNSE G0KUBUO1BOGKKKKKKKKEOTHX8F_2 UXOJJG8UTVJEC6EG0PTF8G0F5;jz3tuabp_8Lx4H3bQNaHc3Wlvctn3cShPCy-7m-p_z-J6bK6jULNchMhrL3l02VM Qae-t2ynLV5HAOW-RMW23U0l7mWPPWsxA45J7cM4IseboJLfT-0bc4K K XXSbnLWeIJEjjChDTcyeaLDqbQX2CO XsROS2ROOKRcgq4bohjPDynn9BtQmJJRtX4Jtb4oqE4FxQRoChlKJhJAO2JJqQg-q3R 5lLt02VlQueq3vBP0Fbfv80x-jLIOOVn0MW -KVo-Jz5tnJyUPib tnn 8pcNLTDK5f5L2Mc9Klov5DvtbJrC-CosjDbmjqO1j4_PX46EhnvibN 8fLKb Y-McFVp5jDh34b6ksD-Rt5JQytmry0hvcQb5cShn9eMjrDRLbXU6BK5vPbN cZ0l8K3l02V-bIe-t2b6 Qh-p52f6LjJbC83e;BDORZ=B490B5EBF6F3CD402E515D22BCDA1598;9571DCC96332320F57 3A4A81D5:FG=1;delPer=0;BD_CK_SAM=1;PSI NO=7;BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm;BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm;BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm;BDRCV 法国[dG2JNJb_ajR]=mk3SLVN 4HKm;BD_HOME=1;H_PS_645EC=0c49V2LWy0d6V4FbFpl BYiy6xyUu88szhVpw2raoJDgdtE3AL0TxHMUUFPM;BA_HECTOR=0l05812h21248584dc1g38qhn0 r;COOKIE_SESSION=1 _0_8_3_3_9_0_0_7_3_0_1_536 5_0_3_0_1614047800_0 _1614047797%7C9%23418111_17_1611988660%7C5 ;BDSVRTM=1′,’主机’:’www.baidu.com’,’用户代理’:’Mozilla /5.0(WindowsNT10.0; Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.182Safari /537.36′}response=requests.get(‘https://www.baidu.com/s’,params={‘wd ‘:’帅哥’} , headers=request_headers) #params 内部调用urlencodeprint(response.text)。上述内容输出了网页的基本信息,包括HTML、JSON、照片、视频等。如下图所示:
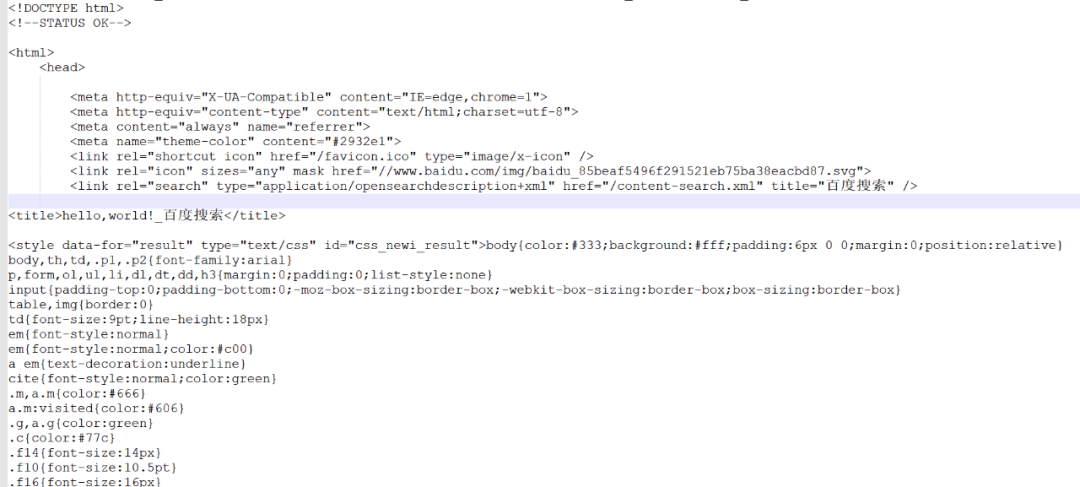
Response 响应后返回一些响应信息。例如:
1、合规状况
200:成功301:跳转404:文件不存在403:权限502:服务器错误2.响应头
set-cookie:用于指示浏览器保存cookie。 预览是网页的源代码。
最重要的部分包括所请求资源的内容,例如网页的HTML、图像和二进制数据。 4. 解析内容。
解析HTML数据:解析HTML数据的方法包括使用正则表达式,以及使用Beautifulsoup、pyquery等第三方解析库。
解析json数据:您可以使用json模块解析json数据。
解析二进制数据:并将其写入格式b的文件中。
5. 数据存储
爬取的数据以文件的形式存储在本地或直接存储在数据库中。 MySQL、Mongdb、Redis、Oracle 等
写在最后
爬虫的大致流程可以理解如下。蜘蛛想要捕捉特定的猎物——沿着蜘蛛的丝找到猎物——吃掉猎物,即爬行——分析——储存。
爬取数据过程中需要参考的工具有:
爬虫框架:Scrapy 请求库:Requests、selenium 解析库:Regular、Beautifulsoup、pyquery 存储库:Files、MySQL、Mongodb、Redis.
总结
我想今天的文章会详细讲解爬虫原理。它对每个人都有用,也将构成未来工作的基础。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/84809.html