

编程是一门手艺,而不是一门科学
Python丰富的解析库和简洁的语法使其非常适合编写爬虫。这里的爬虫是指在网页周围爬行的bug。换句话说,爬虫是一种模拟浏览器访问网页并检索内容的程序。
爬虫工程师是一个非常重要的职位。爬虫每天抓取数亿个网页以供搜索引擎使用。当然,爬虫工程师不是通过右键保存来爬取网页,而是可以使用爬虫“冒充”真实用户,请求各种网站,从网页中检索信息。
本文摘自书籍《Python基础视频教程》,附有各章节的视频讲解和视频微讲座,帮助你快速入门Python。

(文本)
1、初识HTTP:4行代码创建爬虫
超文本传输协议(HTTP)是网络中最常见的网络传输协议。最常见的网站URL 以http 或https 开头。有一层基于http的加密协议。
通常,浏览器将http 或https 请求发送到服务器,一旦服务器接收到请求,相应的结果(响应)就会发送回浏览器,浏览器对其进行解析和细化并将其显示给用户。
创建一个爬虫并不那么困难。让我们用四行代码创建一个爬虫。在first_spider.py文件中写入以下代码。
1from urllib import request 2page=request.urlopen(‘http://www.yuqiaochuang.com/’) 3ret=page.read() 4print(ret)
运行python first_spider.py 页面的源代码将显示在屏幕上。这四根短线就是爬虫。
本质上,这与打开浏览器并输入URL 来访问它没有什么不同。然而,后者使用浏览器来检索页面内容,而爬虫则使用本机HTTP来检索内容。屏幕上显示的源代码与在Chrome浏览器中单击鼠标右键,然后在弹出的快捷菜单中单击“查看网页源代码”是一样的。
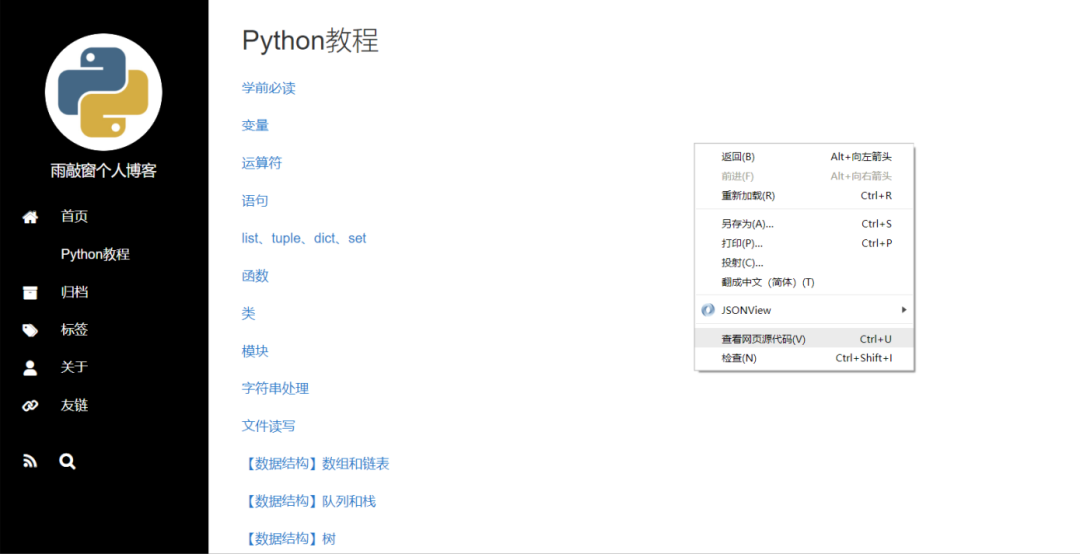
正如您所看到的,网页的源代码是由许多标签组成的。

标签括在尖括号中,例如head、body 和div。标签可以包含属性。例如,如果html lang=’zh-CN’,则有一个值为’zh-CN’的lang属性,表示语言是中文。标签通常成对出现,例如titlePython教程-雨敲窗子个人博客/标题。 《Python教程-雨打窗户个人博客》是通过title和/title包含的,包含的部分称为标签的内容。
2. 正则表达式
我们刚刚用4 行代码创建了一个爬虫。如果成功,您将看到抓取的内容。但是,由于这是一个很大的内容,如果你想提取一些字段怎么办?
一种常见的方法是使用正则表达式(regular expression)进行提取。
对于编程初学者来说,理解正则表达式的“原因”可能很困难。事实上,您可以将正则表达式视为提取工具,允许您通过制定一些规则从字符串中提取所需的内容。
首先,让我们看一下正则表达式的一些简单用法。在Regular_expression.py文件中写入以下代码。
1import re # 正则表达式包2 3m=re.findall(‘abc’, ‘aaaaabccabcc’) 4print(m) 5m=re.findall(‘\d’, ‘abc1ab2c’) 6print(m) 7m=findall( ‘\ d\d\d\d’, ‘123abc1234abc’) 8print(m) 9m=re.findall(r’div(.*)/div’, ‘divhello/div’)10print(m)11m=re.findall( r’div(.*)/div’, ‘divhello/divdivworld/div’)12print(m)13m=re.findall(r’div(.*?)/div’, ‘divhello/divdivworld/div’ )14打印(米)
运行python Regular_expression.py结果如下:
1[‘abc’, ‘abc’]2[‘1’, ‘2’]3[‘1234’]4[‘hello’]5[‘hello/divdivworld’]6[‘hello’, ‘world’]
首先,我们需要“import re”并引用正则表达式模块,以便我们可以使用正则表达式库的方法。
那么上面代码中的m=re.findall(‘abc’, ‘aaaaabcccabcc’) 将从’aaaaabccbcabcc’ 中提取’abc’,返回的m 将是一个包含两个’abc’ 的列表。
m=re.findall(‘\d’, ‘abc1ab2c’) 从’abc1ab2c’ 中提取单个数字。 ‘\d’ 表示提取的目标字符为数字,返回结果为[‘1’, ‘2 ‘] 。
m=re.findall(‘\d\d\d\d’, ‘123abc1234abc’) 提取四个连续数字并返回结果[‘1234’]。
m=re.findall(r’div(.*)/div’, ‘divhello/div’) 从’divhello/div’ 中提取div 和/div 之间的内容。如果用括号括起来,则表示提取括号内的内容。’.’表示匹配任意字符,’*’表示匹配任意个字符,返回结果为[‘hello’]。
m=re.findall(r’div(.*)/div’, ‘divhello/divdivworld/div’) 从’div hello/divdivworld/div’ 中提取div 的内容,并返回结果[‘hello /divdivworld” ]。提取规则和上一行一样,但是为什么不把hello 和world 分开提取呢?正则表达式默认使用贪婪匹配,所以所谓贪婪匹配就是只要匹配到就匹配。从头到尾匹配“divhello/divdivworld/div”并提取长字符串。
m=re.findall(r’div(.*?)/div’, ‘divhello/divdivworld/div’) 括号中添加“?”表示通过非贪婪匹配进行提取,即最短的匹配方式。它非常短,因此提取的结果将是[‘hello’, ‘world’] 。
结合前面的例子,我们可以总结一下findall方法的用法,该方法在正则表达式中最常用。第一个参数是定义的提取语法,第二个参数是原始字符串。返回的是满足提取规则的字符串列表。
有关正则表达式语法的更多信息,请使用搜索引擎搜索“菜鸟正则表达式教程”。
3. 爬取静态页面的网站
还记得我之前写的爬虫只用了4行代码就爬取了“http://www.yuqiaochuang.com”整个页面的内容吗?一旦你学会了正则表达式,你就可以提取你想要的内容。
以爬取该博客为例,我们提取该博客文章列表的标题。
在爬取一个网站之前,通常需要分析该网站是否是静态页面。静态页面是指网站的源代码包含了所有显示内容,意味着所见即所得。常见的方法是在浏览器中单击鼠标右键,然后从弹出的快捷菜单中选择“查看网页源代码”。我们建议使用Chrome 浏览器。
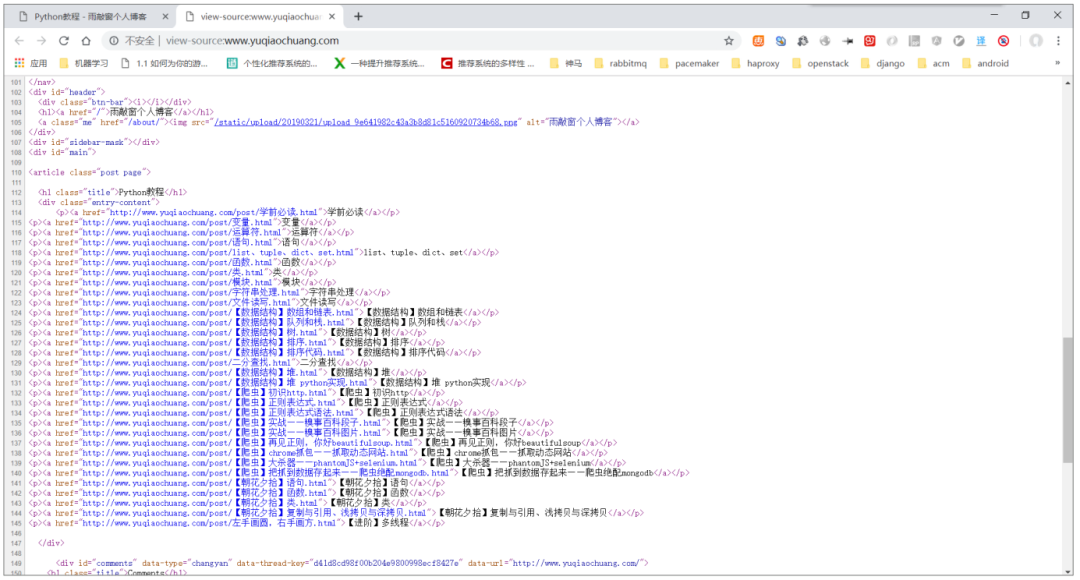
类似上图的代码就是网页的源代码。此处将显示您博客中文章的标题和URL。
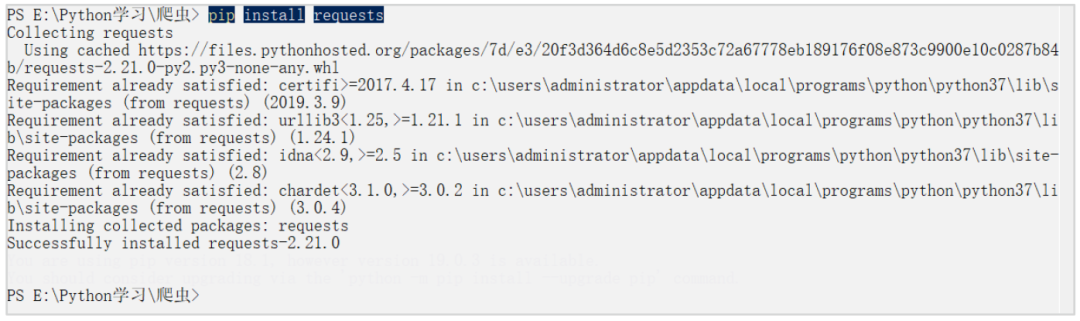
然后使用正则表达式提取每个标题。之前的爬虫只包含四行代码,使用标准库的urllib库。我们建议使用requests 库,它具有更强大且更易于使用的功能。要使用pip 安装,请在PowerShell 命令行窗口中输入以下命令:
1pip 安装请求
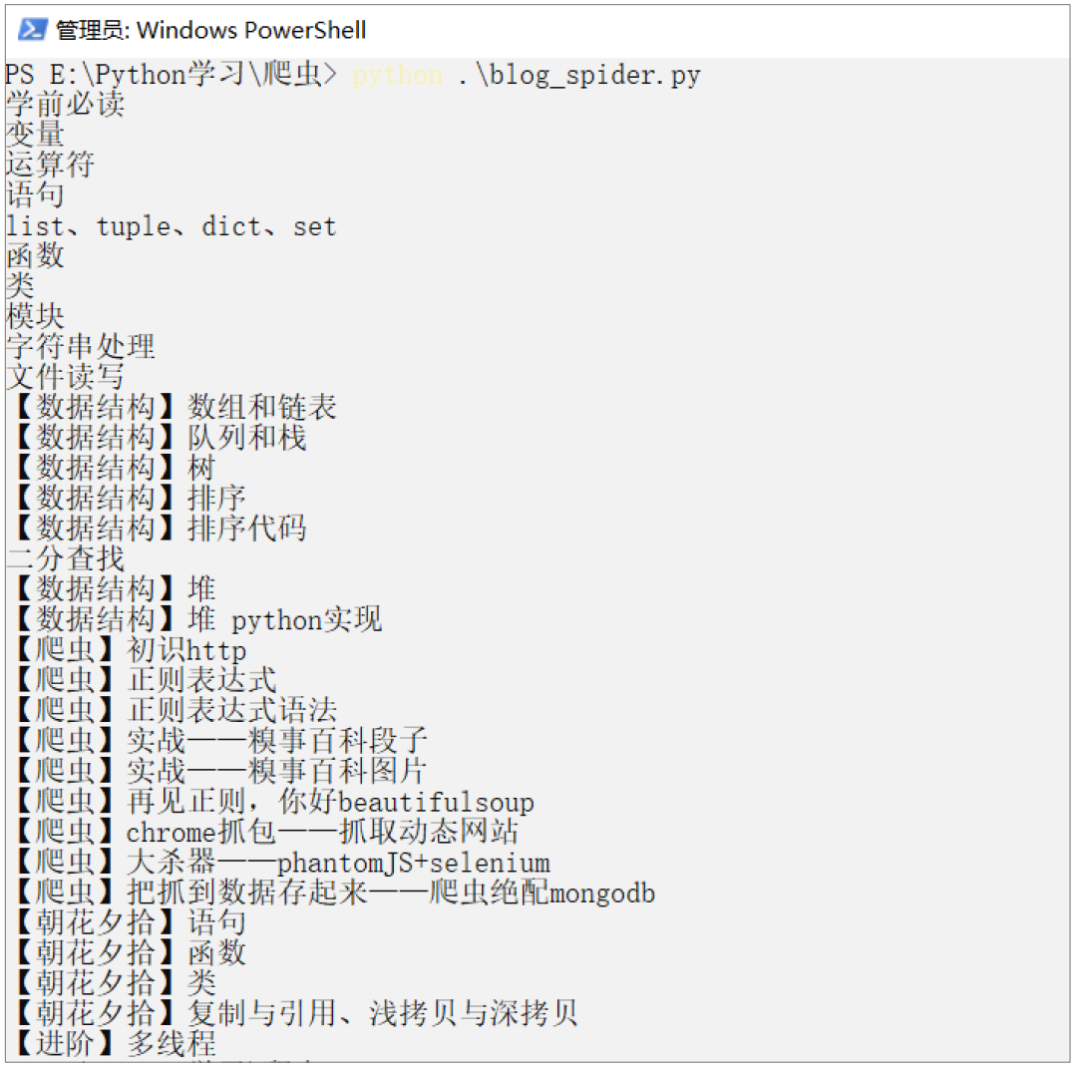
上面的前两行代码首先“导入”我们要使用的库,然后调用请求库的get 方法来检索页面。然后使用re.findall方法提取所有标题。 page.text是页面的源代码内容。从页面中提取以“pa.*”开头并以“/a/p”结尾的标题。
如果您想了解更多与requests库相关的信息,可以使用搜索引擎搜索“Python requests”查看具体的使用说明。
4. 美丽的汤4
beautifulsoup4也是Python的第三方库,提供解析网页的功能。它与正则表达式类似,但其语法更加复杂和有用。
通过在PowerShell 命令行窗口中键入以下命令来安装beautifulsoup4:
1pip安装beautifulsoup4

为了提取这些文章的标题和链接,我们以网页“http://www.yuqiaochuang.com”的源代码为例。在blog_spider_use_bs4.py文件中写入以下代码。
1from bs4 import BeautifulSoup2importrequests3page=requests.get(‘http://www.yuqiaochuang.com/’)4soup=BeautifulSoup(page.text, features=’html.parser’)5all_title=Soup.find(‘div’, ‘entry-content’ ) .find_all(‘a’)6for title in all_title: 7 print(title[‘href’], title.string)
“From bs4 import BeautifulSoup”会在程序中引入BeautifulSoup。
“soup=BeautifulSoup(page.text, features=’html.parser’)”声明一个解析的结构汤。这里分析的是抓取到的网页的源代码。 page.text 功能指定默认解析器“html.parser”。
正如您在这里所看到的,我们要抓取的所有标题都位于类为“entry-content”的div 块内。 “soup.find(‘div’, ‘entry-content’)”用于提取类为“entry-content”的div块。接下来,调用find_all爬取所有标题标签。 find_all 方法返回一个列表。此列表中的元素是满足您的搜索条件的标签。
接下来,创建一个输出标题标签的循环。您可以通过调用title[‘href’] 获取标记内属性的值(链接)。 title.string 用于获取标签的内容。

5. 抓取照片
一个只有枯燥文字的网站很难让用户继续访问,所以一个好的网站就是照片和文字。如果我也想爬取照片怎么办?当然,就像使用浏览器访问网站一样,爬虫也可以爬取图像。您可以通过右键单击图像并从弹出的快捷菜单中选择“另存为”选项来下载图像。
还可以使用请求库检索图像。举个例子,我们抓取“http://www.yuqiaochuang.com”。这次我们将抓取网站左上角的图像。右键单击左上角的图像,然后从弹出的快捷菜单中选择“检查”。
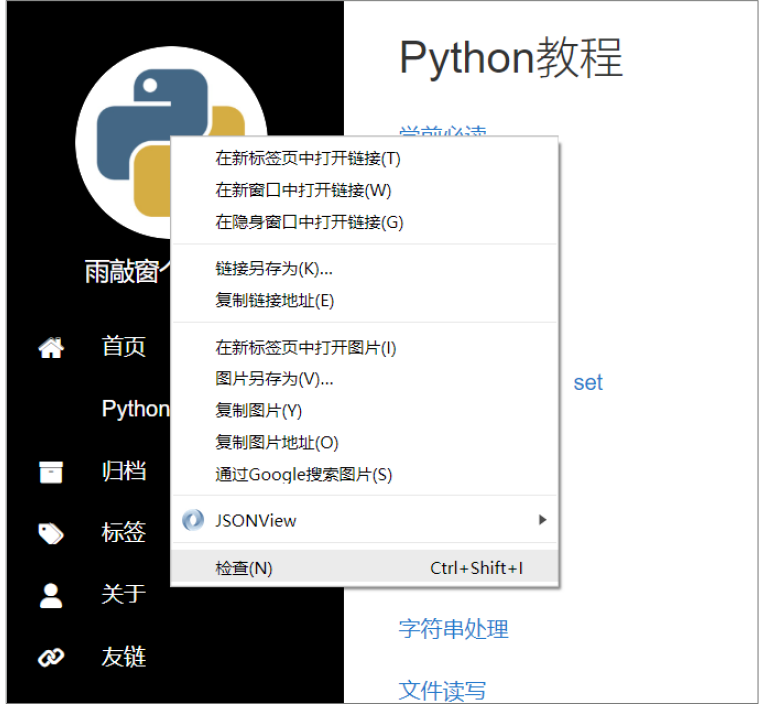
这里可以看到,浏览器底部区域出现了一个工具栏,高亮部分就是该图片地址的网页源代码。
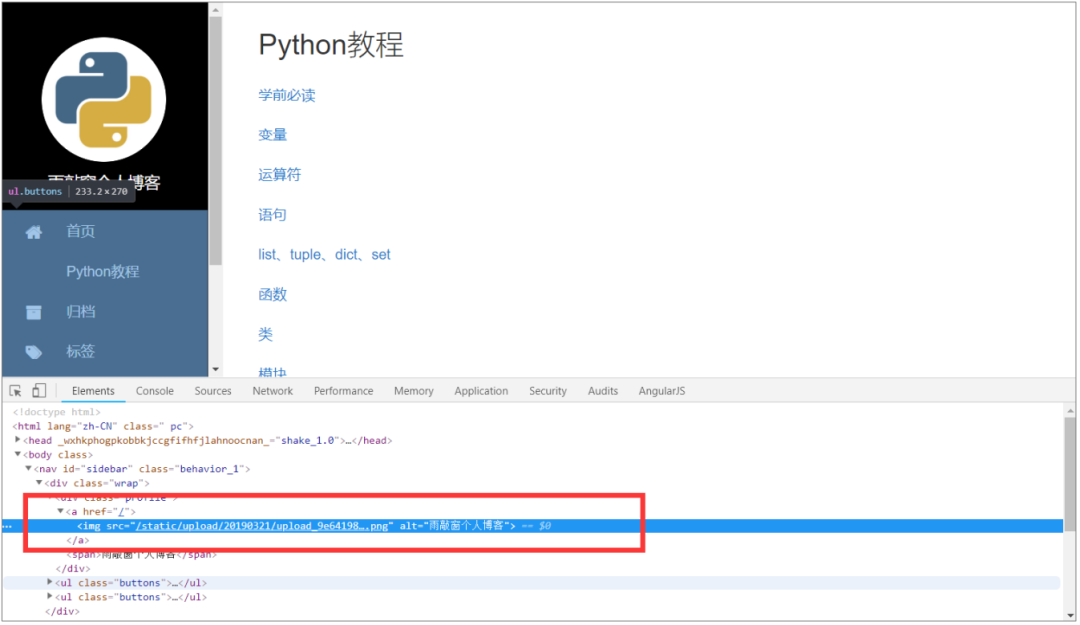
正如您在此处看到的,图像以“img”标签开头。这个“img”标签位于类“profile”的div内,因此您可以使用requests+Beautifulsoup4来提取图像的地址。
在image_spider.py 文件中写入以下代码。
1from bs4 import BeautifulSoup2importrequests34page=requests.get(‘http://www.yuqiaochuang.com/’)5soup=BeautifulSoup(page.text, features=’html.parser’)6img=Soup.find(‘div’, ‘profile’). find(‘img’)7print(img[‘src’])
python image_spider.py 的执行结果如下。

Soup.find(‘div’, ‘profile’).find(‘img’) 直接提取img标签并输出img标签内的src字段。这里可以看到图片地址被提取出来了。但是,您是否注意到这个链接地址似乎缺少一些前缀?
没错,少了“http://www.yuqiaochuang.com”。有些网站图片省略了前缀,只是在爬取时添加了前缀。接下来,正式抓取图片,并在image_spider.py文件中写入以下代码。
1from bs4 import BeautifulSoup 2import Request 3 4page=requests.get(‘http://www.yuqiaochuang.com/’) 5soup=BeautifulSoup(page.text, features=’html.parser’) 6img=Soup.find(‘div’, ‘profile ‘).find(‘img’) 7 8image_url=’http://www.yuqiaochuang.com’ + img[‘src’] 9img_data=request.get(image_url)10img_file=’image.png’ 1112f=open(img_file, ‘wb’ )13f.write(img_data.content)14f.close()
如果运行python image_spider.py,您会注意到当前文件夹中多了一个“image.png”图像文件。
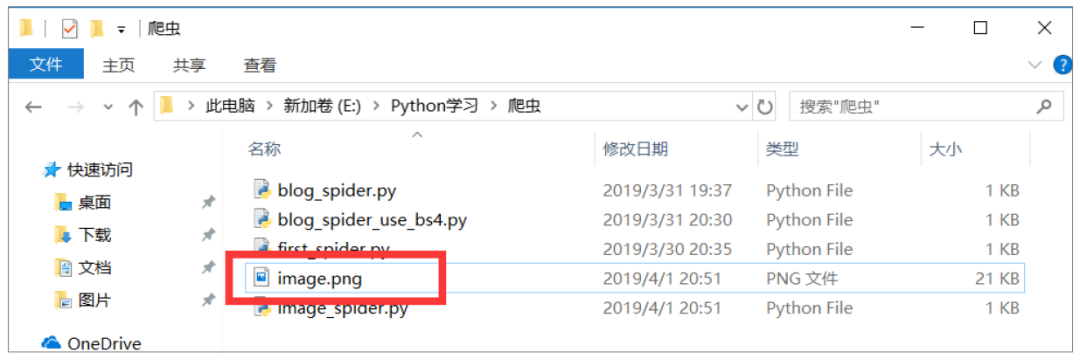
获取图片地址后,调用请求的get方法取出图片的请求数据,并调用write file方法将图片数据写入文件。
之前我们爬取文本时,它被称为文本字段,那么为什么现在它是内容字段呢?
这是因为内容是原始数据,是二进制数据流,而文本是编码后的数据。写入文件时的参数是“wb”而不是“w”。 “wb”表示正在写入的数据是二进制数据流而不是编码数据。图文爬取的本质是根据网页链接发送请求并检索内容,但图像必须以二进制格式存储在本地文件中。
—— 结束——
您是否对编程充满敬佩和好奇,却不知如何开始?
Bowen Viewpoint Academy 的精品课程【每天5 分钟:Python 基础视频教程(书本+课堂)】打开了编程世界的大门。

今天仅需39元即可获得:
300分钟的社区问答和46个视频片段,涵盖同伴交流、互助和成长。一本书价值59元。《Python基础视频教程》。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/84829.html