
《这几个神秘参数,教你TDengine集群的正确使用方式》 解释了如何在节点之间均匀分布数据。我们将继续从产品用户的角度与大家一起积极探索。
如果均匀分布数据的目标是最大限度地利用CPU资源,那么充分利用数据压缩功能就可以最大限度地利用存储资源。
我只能说TDengine在这方面做得非常好。
官方网站有这样的解释:
与典型数据库相比,TDengine的压缩比超过5倍,在某些情况下超过10倍。
以下是TDengine 过去三个月的业绩。
对于SF技术应用,TDengine可以轻松替代OpenTSDB+HBase。
物理服务器数量从21台减少到3台,每日所需存储容量为93G(2份),在节省成本方面相对更加通用。大数据平台具有巨大的优势。
对于得物APP应用,TDengine以10%的压缩率节省更多的存储资源。
Sentinel数据目前不使用副本,所有数据分布在三台机器上。根据计算,TDengine的Sentinel监控数据压缩率达到10%,非常不错。
首先,这个开源产品是免费的,其次,它会为你节省大量的服务器,第三,谁不喜欢——这个降低成本、提高效率的工具呢?
于是,一些用户开始安装该产品,并使用官方推荐的压力测试工具taosdemo来写入数据,看看它是否真的如宣传的那样。
但经过测试,很多用户都觉得TDengine的压缩比没有达到自己的预期。但另一方面,像顺丰速运和德物这样的大公司实际上正在实现显着的成本节约。所以有什么问题?
大家知道,物联网数据的特点之一是,如果监控量相同,即使是字符类型,彼此之间的差异也很小,并且大量数据有规律地重复。或类似的。正是这种数据模型赋予了TDengine的列式压缩最广泛的适用范围。
但如果仅使用taosdemo默认的随机数据集进行测试,生成的数据可能不具备这样的特征。例如,默认的nchar 字符类型的长度为16。压缩效率为2,因为每个nchar字符占用4个字节的存储空间,而4*16几乎占据了一半的行长,不易压缩。有点低了。
为了优化这种体验,taosdemo 2.1 版本中默认的写入数据被替换为4 列INT。但是,如果您想以自定义格式写入数据,请关注此博客。
TDengine taosdemo工具使用指南
那么回到实际生产中会发生什么呢?换句话说,TDengine 如何帮助顺丰、得物这样的独角兽降低存储成本呢?
现在我们来看看——意味着什么,才能赢在起跑线上。超级表创建语句和常规表创建语句之间的唯一区别是——Tag。拥有太多的超级表可以帮助您管理数百万个子表,这解释了为什么它们如此重要。

由于TDengine会提取每个设备的标签并将其放置在内存中,因此设备上的原始数据量自然要小得多。所以,如果你想测试相同业务场景下的性能,你会发现在生成数据的那一刻TDengine就胜出。这是因为在创建相同的场景时,您不需要创建那么多的数据。
假设设备上的标签数量与测量点数量相似或大于测量点数量,您可以节省至少一半的原始数据磁盘使用量。
接下来我们看一下TDengine的数据压缩流程。当数据写入内存时,TDengine首先将数据写入wal(预写日志)文件,以防止由于断电等特殊情况导致数据丢失。
一旦触发disk drop机制并开始将数据保存到存储中,COMP参数就开始生效。根据该参数的值(0 1 2),TDengine选择是否执行不压缩、一级压缩或二级压缩。一级压缩根据数据类型执行相应的列压缩。压缩算法包括delta-delta编码、简单8B法、zigzag编码、LZ4等算法。所以,总结一下:
1、针对特定列,采用特定算法进行定向压缩2、物联网场景下数据的普遍规律这两点共同作用,成就了TDengine的超级压缩能力。
其次,两级压缩在一级压缩的基础上使用通用的压缩算法,从而获得更好的压缩效果。有关TDengine 压缩算法的说明,请参阅下面的链接。
https://github.com/taosdata/TDengine/blob/master/src/util/src/tcompression.c
最后,我们来看看如何估计压缩比。
首先,我们需要计算裸数据的大小。官方网站上列出的公式是:
Raw DataSize=numOfTables * rowSizePerTable * rowsPerTable rowSizePerTable(每行的长度)可以根据每种数据类型的长度来计算。表描述显示表的结构和每个字段的大小。二进制和nchar 类的长度是最大长度。实际占用应以实际数据长度为准(下面的demo中,binary和nachar会占用全部空间),nchar字段占用的长度应乘以4。此外,每个二进制文件和nchar 占用额外的2 个字节。
例如下表:
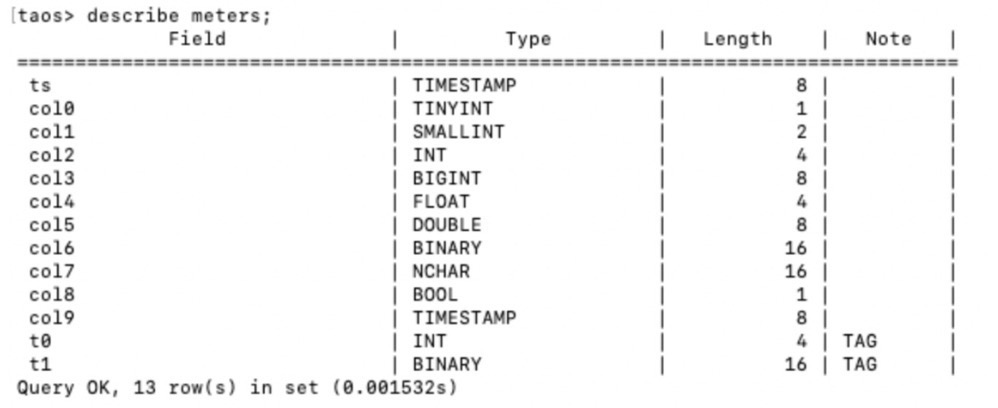
假设Binary和Nchar数据都填充16个字符,则一行的总长度为(8+1+2+4+8+4+8+16+16*4+1+8)+ 4=128。字节。您可以通过将128 字节乘以rowsPerTable * numOfTables(表数)来粗略估计数据总量。
事实上,测试更常见的是直接使用超级表作为测试目标,直接使用超级表的count(*)数据乘以每行的长度以获得Raw DataSize。
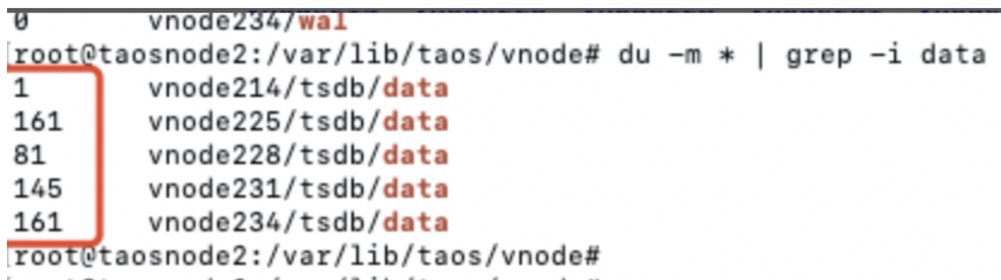
最后,将/var/lib/taos/vnode/中每个vnode 的数据文件大小除以原始数据大小。
完成——终于得到实际的压缩比。现在,大家要注意了:data files目录下的vnode目录下还有一个wal目录。如果这里存在数据,则意味着该数据没有放入存储中,这意味着该数据没有被压缩。为了让测试结果更加准确,可以使用最简单直接的方法——重启服务进程,直接触发部署机制。
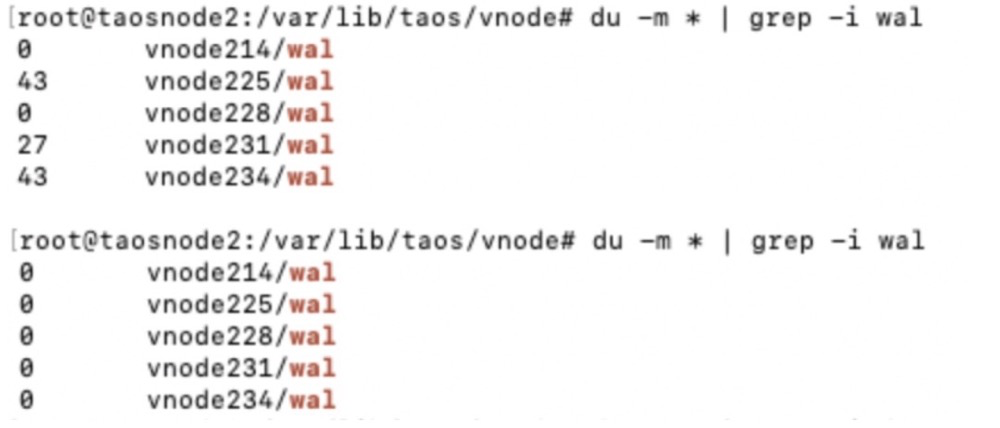
上图显示:重新启动后,所有wal 文件的大小均为0。这表明数据已成功压缩并写入存储。
这次TDengine之旅终于结束了。
事实上,测试压缩率的最佳方法是在进行适当的数据建模后在真实数据上进行尝试。
以上是TDengine 降低您存储成本的最大杀手级功能。
点击“了解更多”体验TDengine。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/85430.html