

决策树是一种逻辑简单的机器学习算法,因其具有树形结构而被称为决策树。
本文介绍了决策树的基本概念、学习决策树的三个步骤、三种流行的决策树算法以及决策树的十大优缺点。
什么是决策树?
决策树是一种解决分类问题的算法。决策树算法采用树结构并利用逐层推理来实现最终的分类。决策树由以下元素组成:
根节点:带有样本的完整内部节点集:对应的功能属性测试叶子节点:代表决策结果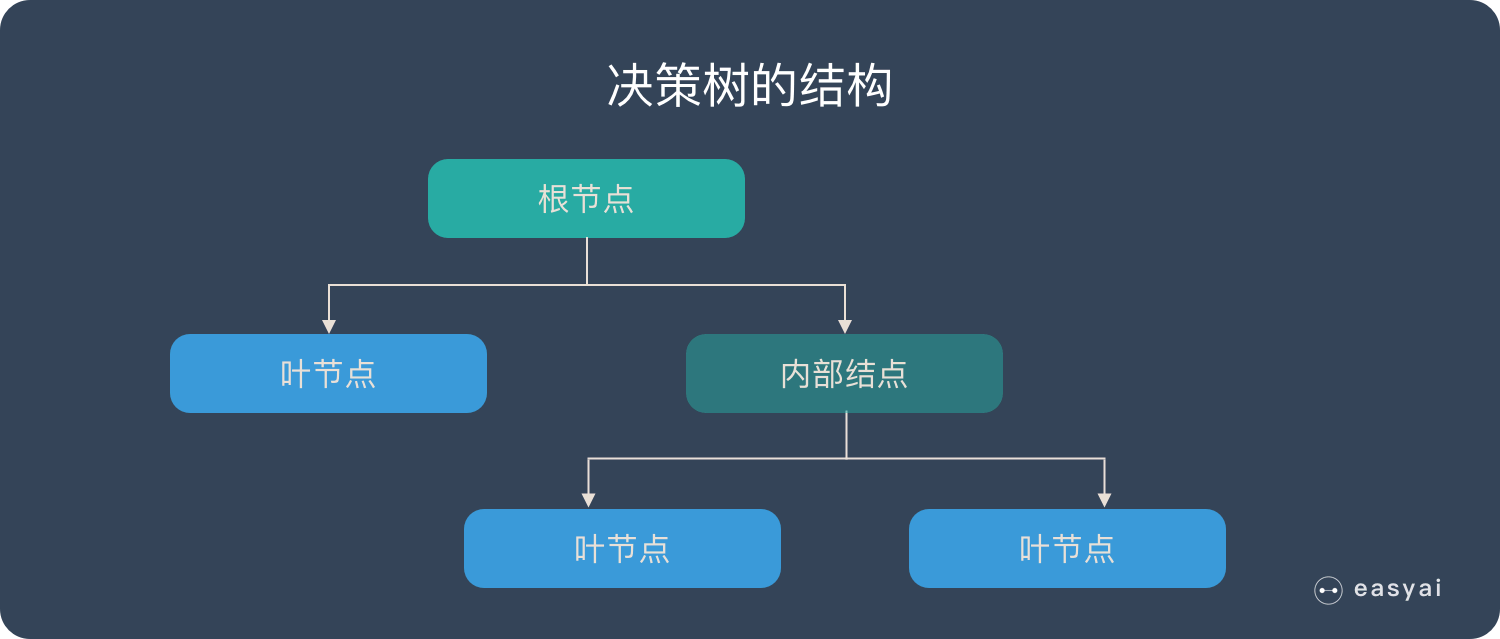
预测时,利用一定的属性值来确定树的内部节点,并根据确定结果确定树在到达叶子节点之前将进入哪个分支节点,并得到分类结果。
它是一种基于if-then-else规则的监督学习算法,其中决策树的规则是通过训练获得的,而不是手动制定的。
决策树是最简单的机器学习算法,易于实现,可解释性强,完全符合人类直观思维,应用范围广泛。
我给大家举个栗子:
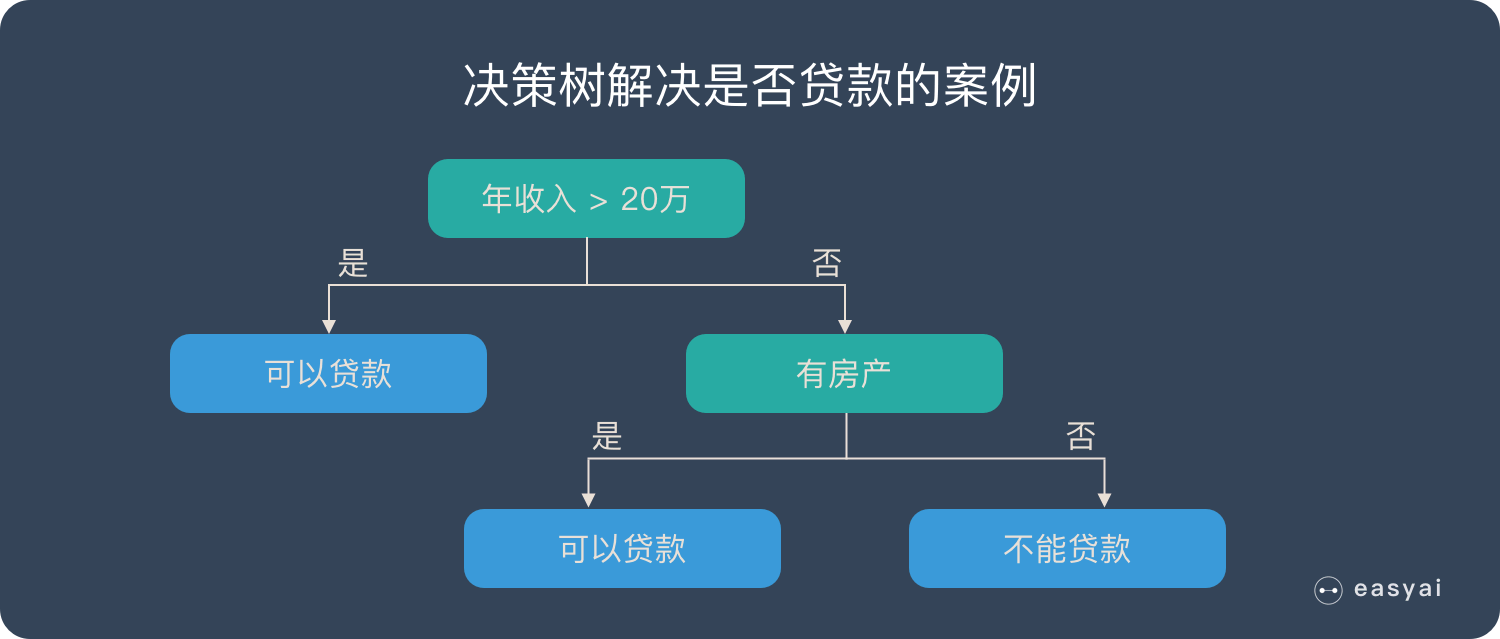
上面的解释太抽象了,我们来看一个真实的例子。银行必须使用机器学习算法来决定是否向客户提供贷款。为此,您需要查看两个指标:客户的年收入以及他们是否拥有房地产。领导安排你实现这个算法,你想出了最简单的线性模型,很快就完成了任务。
首先,确定客户的年收入指数。如果超过20万就可以贷款,否则我们会继续判断。接下来,确定客户是否拥有该财产。如果你有房产,你可以贷款,但如果你没有房产,你就不能贷款。
此示例的决策树如下所示。
决策树学习的 3 个步骤

特征选择
特征选择决定了决策中使用哪些特征。在训练数据集中,每个样本可以包含许多属性,不同的属性可以产生或大或小的影响。因此,特征选择的作用就是过滤掉与分类结果高度相关的特征,即分类能力强的特征。
特征选择的常用标准是信息增益。
决策树的生成
选择特征从根节点开始触发,计算该节点所有特征的信息增益,选择信息增益最大的特征作为节点特征,并根据不同的值建立子节点。使用相同的方法生成每个子节点,直到检索到很少的特征或无法选择任何特征。
修剪决策树
剪枝的主要目的是通过积极删除一些分支来处理“过拟合”,降低过拟合的风险。
3 种典型的决策树算法

ID3算法
ID3是最早提出的利用信息增益来选择特征的决策树算法。
C4.5算法
它是ID3的改进版本,它不是直接使用信息增益,而是引入了“信息增益比”度量作为特征选择的基础。
CART(分类和回归树)
该算法可用于分类和回归问题。 CART算法使用基尼系数代替信息熵模型。
决策树的优缺点
的优点
决策树易于理解和解释,可用于可视化分析,并且易于从中提取规则。适合处理缺失属性的样本。它在测试数据集时运行相对较快,并且可以在相对较短的时间内针对大型数据源生成可行且有效的结果。有缺点
更容易发生过拟合(随机森林可以显着减少过拟合)。在决策树中分割属性时,如果数据中每个类别的样本数量不一致,则属性相关性很可能会被忽略。不同的决策标准导致不同的属性选择趋势。信息增益标准偏向于具有更多期望属性的属性(通常由ID3算法表示),而增益率标准(CART)则偏向于具有较少期望属性的属性。然而,CART在分割属性时,它使用的是启发式规则,而不是简单地使用增益率来分割(只要使用信息增益,例如RF,这个缺点就存在)。 ID3算法计算信息增益时,结果偏向于数量较多的特征。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/86810.html