
决策树是好树,是可以帮助你做出决策的树。

决策树图
在所有机器学习算法中,决策树可能是最用户友好的。这被归类为“白盒模型”,因为整个操作机制可以很容易地翻译成人类可以理解的语言。
与神经网络等算法更喜欢使用隐藏层进行黑盒操作不同,它的排名相对较高,并且最终学习到的树很容易让人理解。
01 直观理解
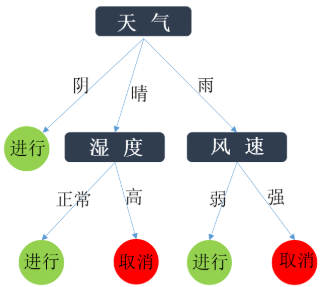
假设您开了一家小商店,想要了解该商店在特定日期的销售额如何关联。根据我们的经验,我们认为销售水平可能与天气、是否是周末以及是否有促销活动有关,如下图所示。
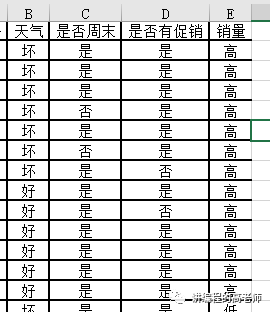
那么如果你想手动分析这个问题怎么办?
从是否周末开始,我们按照“周末与否”分为两类,如果是周末,我们就看天气好坏。如果天气好的话,相信销量也会更好。
此外,您还可以获得如下照片。
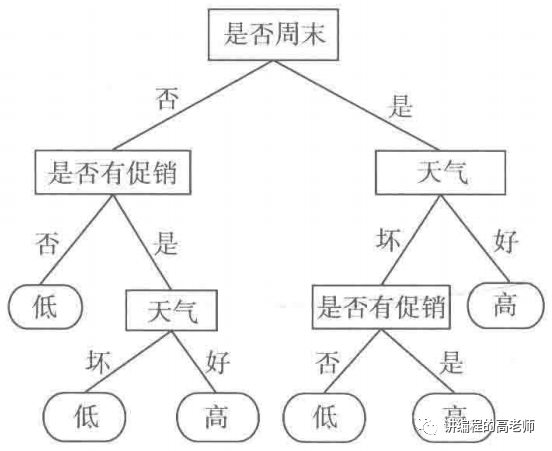
上图中,有一个圆角矩形、一个矩形和一条直线。
当你看到一个圆角矩形的时候,它就已经是最终的结果了,这种东西被称为决策树的叶子节点。
该矩形应始终向下分割。这称为中间节点(或内部节点)。
对于包含文本的线段(通常是带有箭头的方向线),线的一端连接到中间节点,另一端连接到另一个中间节点或叶节点。然后文本将出现在线段上。这就是所谓的边缘。
你现在可能已经明白了。所有内部节点都是自变量,叶节点是因变量的值,边是自变量的可能值。有了这棵树,你可以看到明天的天气情况,是否是周末,是否有促销活动,还可以预测明天的销售情况,提前备货。换句话说,如果你还有库存,你如何增加销量并尽快售出你的产品?
一个自变量可以包含多个值。例如,在判断一个学生是否是好学生时,学生的成绩是一个比较重要的自变量,该成绩的可能值为[0,100]。分数节点是否有100 条边? 不一定。正如上一篇文章中提到的,我们目前需要离散化成绩的数量。可分为“不及格”D、“及格”C、“良好”B、“优秀”A等。
Python实现KMeans算法mp.weixin.qq.com
了解数据离散化及其KMeans算法实现mp.weixin.qq.com

现在,当我们如上图组织决策树时,我们发现仍然存在一些问题。
选择哪一个作为根节点呢?选择了根节点之后,如何选择最后一个叶子节点呢?如何在计算机上详细说明和实现这一点?从
02 算法描述
01的描述中,我们可以看到决策树从根节点下降到叶节点,最终导致因变量为单个值。换句话说,节点越低,因变量取某个值的可能性就越大,到达叶子节点时概率最大。
这可以通过最直接和笨拙的步骤来实现。
选择自变量作为节点,从边导出值(属性值)。如果该值对应的变量值为空或单值,则在边的另一端生成叶节点。 否则,选择一个内部节点,即根据条件2 进行分割的新属性,直到得到条件1。参考以上步骤,就可以将01中介绍的例子绘制成决策树。
上面的简单算法很容易想到,但如果太容易获得,往往是不够的。给定大量的自变量,我们应该选择哪一个作为根节点?一旦选择了根节点,随着树的向下生长,接下来的内部节点应该如何选择?已经衍生出许多决策树算法来解决这个问题。这些问题。
我们通常使用ID3、C4.5、C5.0 和各种其他算法来绘制决策树,如下图所示。
常见决策树算法
由于篇幅限制,我们只讨论ID3算法,但是了解ID3的其他方面会更容易理解。
03 ID3算法
ID3算法基于02中介绍的简单决策树算法(CLS)解决属性选择问题。
内部节点的每个属性值都连接到一条边,但是哪一个更好呢?这就是引入“信息获取”概念的地方。
信息的获取可以用很多公式来解释,也可以从感性上初步理解。请记住,我们的目标是在删除某些属性时使节点比叶节点增长得更快。换句话说,节点的某些属性使我们能够更可靠地预测因变量的值。在示例01中,如果“是否周末”的节点为“是”,则很容易判断销量高,获取的信息量也会高。
深入挖掘,我们需要了解熵的概念才能理解信息获取。
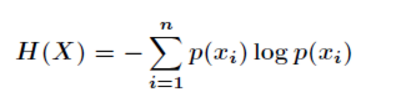
信息熵的定义
这个公式虽然看起来很繁琐,但实际上是为了定量地描述一个事实。换句话说,事件的随机性越大,预测它就越困难。具体来说,概率p越小,最终的熵就越大(即信息量越大)。如果一个事件的概率为1,那么在极端情况下它的熵为0。
熵越高,如果其值能够被准确预测则越有意义,反之则意义越小。例如,如果你能预测彩票的中奖号码,你就很富有,但如果你能预测明天太阳何时从东方升起,你就一文不值。因此,信息价值的度量可以用熵来表示。
那么,如果我们在绘制决策树时能够快速降低熵,是不是就意味着我们能够快速找到概率接近1的叶子节点呢,所谓信息量最大的就是一条路线。
那么这个利润的差异是谁造成的呢?自变量取一定值之前的熵和取一定值之后的熵之间的差。例如,如果你不知道明天天气是否好,则熵为H1,如果你知道明天天气好还是坏,则熵为H2。那么H1-H2就成为信息增益。条件熵的计算公式为:
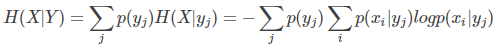
根据经验熵计算的条件熵
其中,H(X|yi) 是后验熵。具体算法请参见下面的示例。
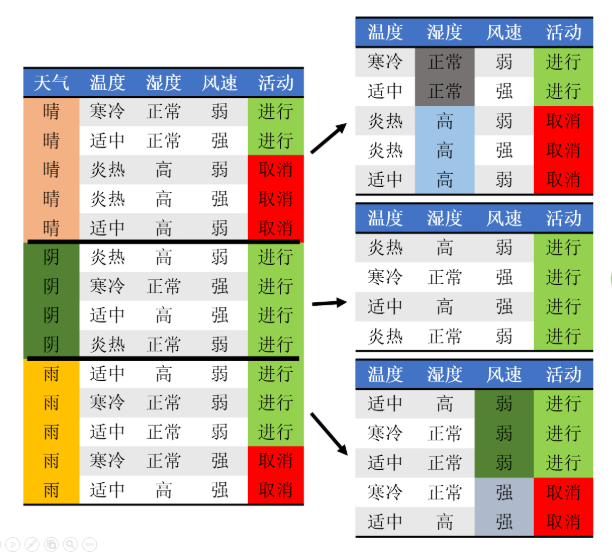
让我们看一个更清楚的例子。假设您要记录第14 个学校运动会是安排还是取消。持有或取消的概率分别为9/14 和5/14。那么,信息熵为:
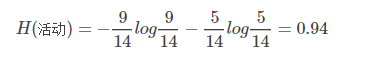
我们还记录了活动当天的天气状况,发现天气与运动会举行还是取消有关。 14天内,晴天5次(举办2次,取消3次),下雨5次(举办3次,取消2次),阴天4次(举办4次)。晴天、阴天、雨天对应的后验熵
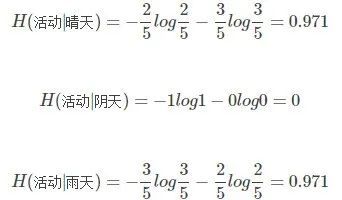
接下来,知道天气情况,学校运动会的条件熵为:
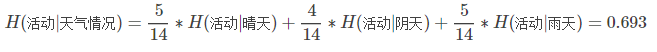
本例中,天气情况前后获取的信息如下:

对应的ID3算法很容易找到。
找到所有自变量中信息增益最大的节点。节点的每个值都取决于其熵。例如,在下面的过程中,该节点对应于叶子节点。 (参考文献1)。
04 总结
有一些有趣的概念,例如熵(先验熵)、后验熵、条件熵和信息增益。对应的ID3算法。
参考:
https://blog.csdn.net/robin_Xu_shuai/article/details/74011205https://zhuanlan.zhihu.com/p/26486223
关注我们的公众号:
添加作者为好友并加入学习群。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/86816.html