
决策树是机器学习中的一种常见算法,其思想与我们通常用来做决策的过程完全相同。决策树是一种基本的分类和回归技术,用于分类时称为分类树,用于回归时称为回归树。

1、决策树结构:
顾名思义,决策树在逻辑上表示为包含节点和边的树。
一般来说,决策树包括根节点、一些内部节点和一些叶节点。
根节点:包含完整的样本集。从根节点到每个叶节点的路径对应于一个决策测试序列。
内部节点:表示特征或属性。每个内部节点都是一个条件,包含数据集中满足从根节点到该节点的所有条件的数据的集合。根据内部节点的属性测试结果,将内部节点对应的数据集划分为两个或多个子节点。
叶子节点:代表判断结果对应的类。叶节点是最后一类。如果数据包含在叶节点中,则它属于该类别。
圆圈和方框分别代表内部节点和叶节点,如下图所示。
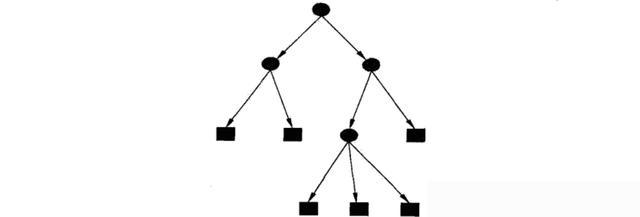
换句话说,决策树是一种预测模型,它使用树模型进行决策,并以简单、清晰、非常容易理解的方式展示对象的属性和对象的值之间的映射关系。
我们决策树学习的目标是生成具有强泛化能力的决策树,即能够高效、有效地处理未见过的例子的决策树。
2.决策树的优缺点:
1、决策树最大的优点是不需要高深的背景知识,计算复杂度也不是很高,可以自行学习。
2.属于监督学习
3.不受中间缺失值的影响
4. 比线性回归具有更强的可解释性
5. 与传统的回归和分类方法相比,决策树是更加人性化的决策模型。
6. 即使非专家也可以创建易于理解的图形表达
7. 可以直接处理定性预测变量,无需创建虚拟变量。
8、虽然决策树的预测精度普遍不如回归和分类方法,但通过将多个决策树与集成学习方法相结合,可以大大提高树的预测效果。
3. 决策树的生成
决策树的生成是一个自上而下的递归过程,基本思想是用信息熵作为衡量标准,构建熵值下降最快的树,并且叶子节点的熵值为零。
决策树算法中存在三种情况会出现递归返回。
1)当前节点包含的样本属于同一类别,不需要分裂。
2) 当前属性集为空,不能拆分。在这种情况下,您应该将当前节点标记为叶节点,并将其类别设置为样本最多的类别(即将属性除以样本)。
3)当前节点包含的样本集为空,无法拆分项目。此时,当前节点被标记为叶子节点,并且其类别被设置为父节点中样本最多的类别。使用父节点的先验分布(即样本没有属性)。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/86829.html