

作者: 泰伦斯·帕尔,格洛弗王子
翻译:王雨桐
校对:姜浩
本文长约9500字。我们建议阅读至少10 分钟
本文分析了决策树可视化中的重要元素,并对现有可视化工具进行了比较。还通过大量示例介绍了决策树可视化工具的设计和实现过程。
目录
决策树概述决策树可视化的关键要素与现有可视化的查看性能比较我们的决策树可视化视觉特征- 目标空间详细信息部分使用可视化树识别单个观测值解释水平决策树的简化结构过去的经验教训代码示例回归树可视化- – – 以波士顿房价为例。以红酒为例,创建Scikit Decision Tree Shadow Tree 工具箱的矢量图。对未来工作的概述。适用于结构化数据,随机森林被称为星级模型,决策树是两者的基础。可视化决策树对于理解这些模型的工作原理非常有帮助。然而,目前的可视化软件工具都非常基础,对于初学者来说并不容易使用。例如,您不能依赖现有库来告诉您每个节点如何分区变量。此外,当向决策树添加新样本进行预测时,只能生成并显示结果的图像,因此很难使用现有工具可视化整个过程。
因此,我们创建了一个通用包,用于在scikit-learn 中可视化决策树模型和解释模型。我计划在Jeremy Howard 即将出版的机器学习书籍《The Mechanics of Machine Learning》 中广泛使用这个包。这是一个简单决策树可视化的示例。
附书链接:
https://mlbook.explained.ai/
本文介绍了这项工作的成果,详细介绍了该工作,并概述了使用该工具的基本框架和技术细节。该可视化软件是新的Python 机器学习库dtreeviz 的一部分。本文不会过多详细介绍决策树的基本原理,但会提供快速概述,以帮助您熟悉相关术语。
决策树概述
决策树是基于二叉树(左右最多两个子树)的机器学习模型。决策树遍历训练数据并将信息压缩为二叉树的内部节点和叶节点。它学习训练集中的观察值之间的关系,表示为特征向量x 和目标值y。 (注:向量为粗体,标量为斜体。)
决策树的每个叶子代表一个特定的预测。回归树的预测输出是一个(连续)值,例如价格,而分类树的预测输出是一个(离散)目标类别(在scikit 中表示为整数),例如是否存在癌症。决策树将观察结果分为具有相似目标值的组,每个叶子代表其中一个组。对于回归,叶节点观测值的相似性意味着目标值之间几乎没有差异。对于分类来说,这意味着大多数或所有观察结果都属于同一类别。
从根到叶节点的每条路径都经过一组(内部)决策节点。在训练过程中选择特定的切点后,每个决策节点将x (xi) 中单个特征的值与切点的值进行比较。例如,在预测租金的模型中,决策节点会比较卧室和浴室数量等特征。 (请参阅第3 章“可视化新样本预测”。)scitkit 假设决策树模型中的所有特征都是数字,因此它不是具有离散目标值的分类模型,但是决策节点仍然比较数字特征值。因此分类变量需要经过one-hot编码、合并、标签编码等。
为了到达决策节点,模型迭代训练集的子集(或根节点处的完整训练集)。在训练过程中,决策树遵循相似度最大化的原则,根据所选节点的特征和该特征空间中的分裂点将观测值放入左右桶(子集)中。 (这个选择过程通常需要对特征和特征值进行详尽的比较。)左子集中样本的xi 特征值全部小于分割点,而右子集中样本的xi 特征值全部小于分割点大于分割点。通过为左分支和右分支创建决策节点来递归地构建树。当决策树达到某个停止标准(例如,一个节点包含的观测值少于5 个)时,它就会停止生长。
决策树可视化的关键要素
决策树可视化突出显示了以下关键元素:下面对此进行更详细的解释。
决策节点特征和目标值的分布(本文称为特征和目标空间)。我想知道是否可以根据特征和切点对观察结果进行分类。决策节点特征和特征分割点。我们需要知道每个决策节点选择的要检查的特征变量以及对观测值进行分类的标准。叶节点的纯度。这会影响预测的可靠性。纯度越高意味着回归问题的叶节点方差越小,分类问题的叶节点包含较大比例的目标,所有这些都意味着预测结果更可靠。 叶节点的预测值。根据训练集的目标值,我们得到叶子节点的具体预测结果。决策节点中的样本数。我需要知道大多数样本属于决策节点的位置。叶节点样本数。我们的目标是减少决策树中叶节点的数量并提高其纯度。如果样本节点下的样本数太少,可能会导致过拟合。如何将新样本分配到从根节点开始的特定叶节点。这有助于解释为什么要相应地预测新样本。例如,在预测公寓租金价格的回归树中,决策节点检查卧室数量,新样本的卧室数量大于3,因此预测价格较高。显示结果
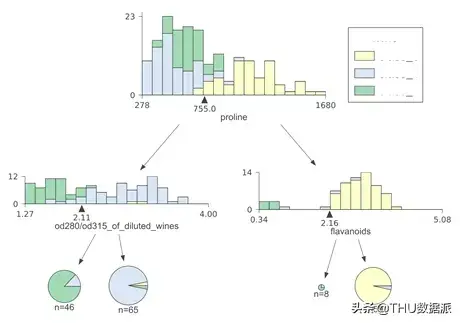
在详细讨论现有的可视化工具之前,我们想先介绍一下我们生成的渲染图。在本节中,我们将重点关注一些可视化案例。这是我使用多个数据集构建的scikit 回归和分类决策树。您还可以使用完整的库和代码重现所有案例。
附代码链接:
https://github.com/parrt/dtreeviz/blob/master/testing/gen_samples.py
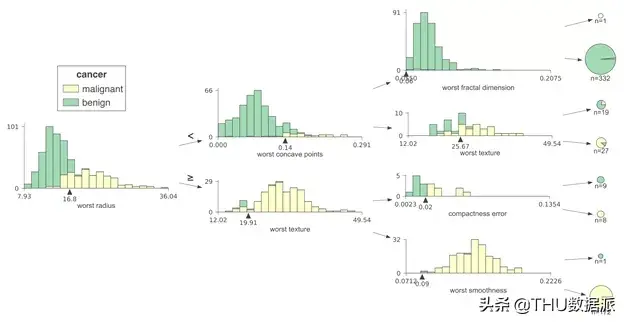
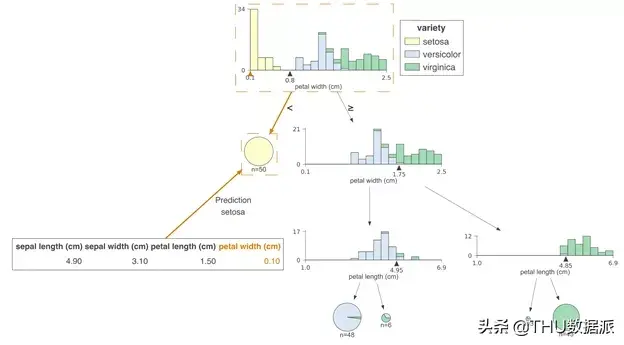
与现有可视化工具的比较
搜索“视觉决策树”,您将很快找到scikit 提供的基于Python 语言的解决方案(sklearn.tree.export_graphviz)。您还可以找到来自R、SAS 和IBM 的可视化工具。在本节中,我们收集各种现有的决策树可视化,并将它们与使用dtreeviz 库创建的决策树进行比较。在下一节中,我们将详细讨论可视化。
让我们使用scitkit 可视化工具及其默认设置在熟悉的Iris 数据集上绘制可视化决策树。
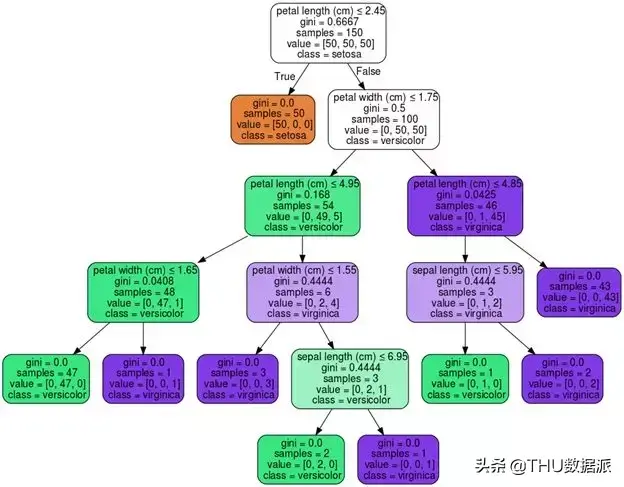

虽然scikit-tree 很好地表示了树结构,但我仍然发现了一些问题。首先,色彩的运用不够直观。例如,您可以看到为什么有些节点是彩色的而有些不是。如果颜色代表分类器的预测类别,您可以认为只有叶子才被着色。叶子是有预测性的。您可以看到没有颜色的节点的预测能力较差。
除此之外,基尼系数(确定性得分)占用了图中的空间并阻碍了解释。尽管在每个节点处获得每个目标类的样本数量很有用,但直方图提供了更多信息。此外,您可能需要使用彩色目标类别图例。最后,使用true 和false 作为边缘标签不够清晰,但3 看起来也更干净。最显着的区别是决策节点利用堆叠直方图来显示特征分布,并且每个目标类别以不同的颜色显示。类似地,叶子的大小与该叶子内的样本数量成正比。
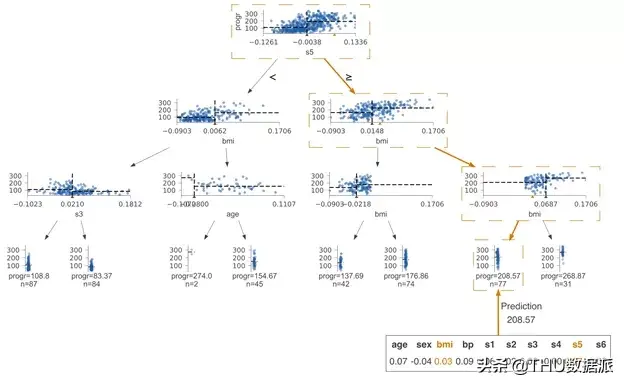
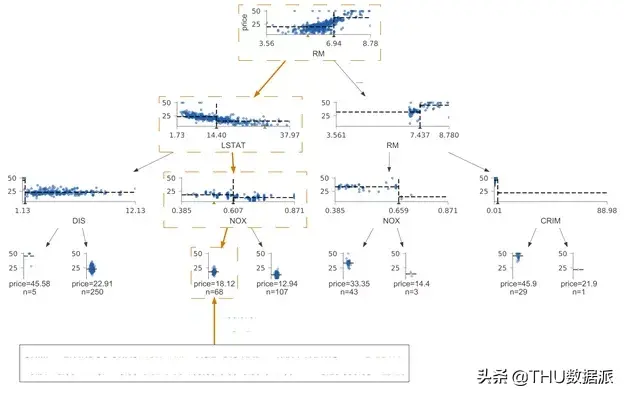
让我们再次检查回归案例。下图是使用scikit 在Boston 数据集上进行可视化,并与dtreeviz 版本进行比较。
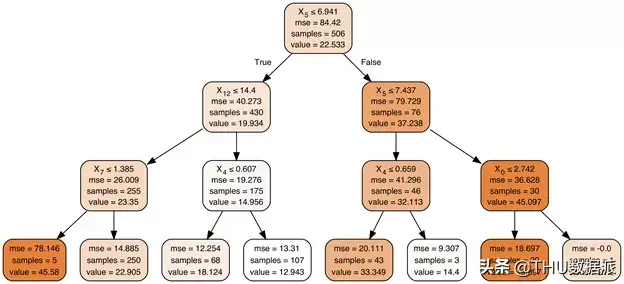
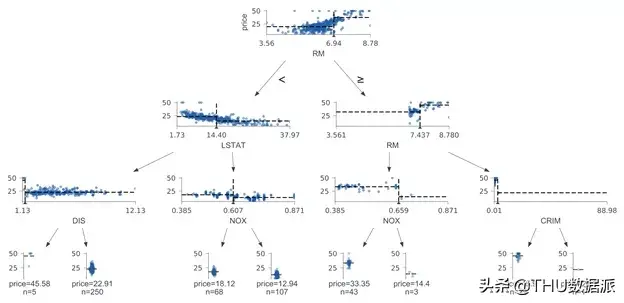
同样,在scikit 树中,我们并没有直观地理解颜色的用途,但经过进一步调查,我们发现较暗的图像代表较高的预测目标值。如前所述,我们的解决方案允许将特征空间分布显示在决策节点下方。例如,在本例中使用特征和目标值的散点图,而叶节点始终使用带状图。目标值及其中点的分布
同样,让我们探索以下用于用R 语言可视化决策树的软件包。这个包的结果和scikit类似,但是边缘标签更好。
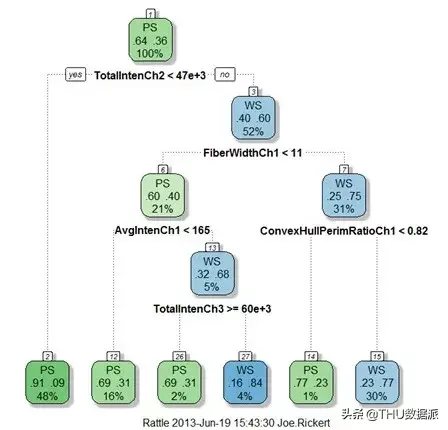
SAS 和IBM(都不支持Python 语言)也提供决策树可视化。我们发现SAS中的决策节点包含与节点的样本目标值和其他细节相关的条形图。
c-image/fe8e0aa18a004d548f0b89e177152cd4~noop.image?_iz=58558&from=article.pc_detail&lk3s=953192f4&x-expires=1717879892&x-signature=FVJ5hJsRiRp9csOgnmF9w485U5o%3D” alt=”fe8e0aa18a004d548f0b89e177152cd4~noop.image?_iz=58558&from=article.pc_detail&lk3s=953192f4&x-expires=1717879892&x-signature=FVJ5hJsRiRp9csOgnmF9w485U5o%3D” />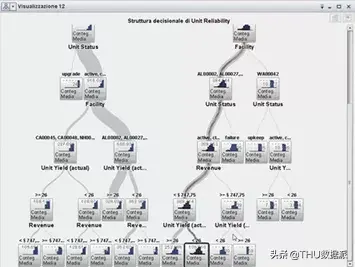
在这一案例中有一个很好的idea,就是通过边缘宽度来体现子树中的样本量。但是由于缺少水平轴,这些条形图的解释性并不如意。测试类别变量的决策节点(上图)每个类别仅具有一个条形,因此它们只能表示简单的类别计数,而不是特征分布。对于数字特征(下图),SAS决策节点显示目标值或特征值的直方图(我们无法从图像中分辨出)。SAS节点条形图/直方图似乎只是在说明目标值,这并没有告诉我们有关特征分割的信息。
下侧的SAS树似乎突出显示了新样本的预测过程,但我们无法从其他工具和库中找到任何其他示例,这样的功能似乎并不常见。
再来考察IBM软件的情况。它在泰坦尼克数据集中表现出了非常不错的可视化效果,甚至结合IBM的Watson分析以条形图的形式显示了决策节点类别的计数: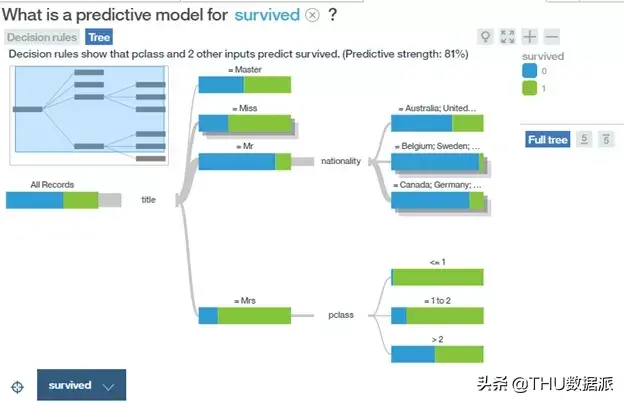
再来看看IBM较早的SPSS产品中对决策树可视化效果: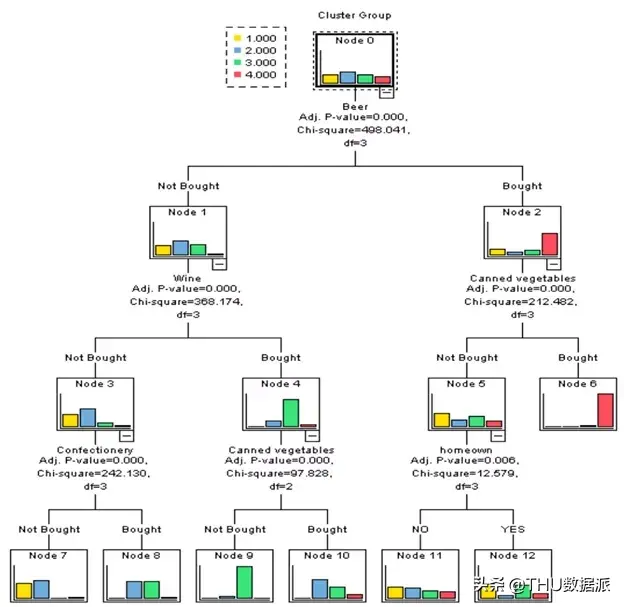
可见,在SPSS中,这些决策节点提供了与样本目标类别计数相同的SAS条形图。
以上所提及的所有可视化都提供了不错的结果,但是给予我们启发性最大的是来自《机器学习的可视化简介》中的案例。它给我们展示了一个以动画形式展示的决策树可视化案例,如下所示:
附链接:
r2d3.us/visual-intro-to-machine-learning-part-1/(译者注:很经典的可视化,建议看原网站动态图)
除了动画的要素之外,该可视化还具有此前提到的三个独特特征:
决策节点显示特征空间如何分割决策节点的分割点在分布中直观显示(就是那个三角形的指示符号)叶节点的大小与该叶中的样本数成正比尽管该案例是出于教学目的而开发的基于hardcoded技术的可视化动图,但它给我们指明了正确的方向。
我们的决策树可视化
除了《机器学习的可视化简介》中的动画外,我们找不到另一个能够更好说明如何在决策节点(特征目标空间)处分割特征值的案例了。而这一点恰恰是在决策树模型训练期间进行操作的关键点,也是新手应该关注的点,因此我们借鉴这一方案,从检查分类树和回归树的决策节点开始我们的可视化工作。
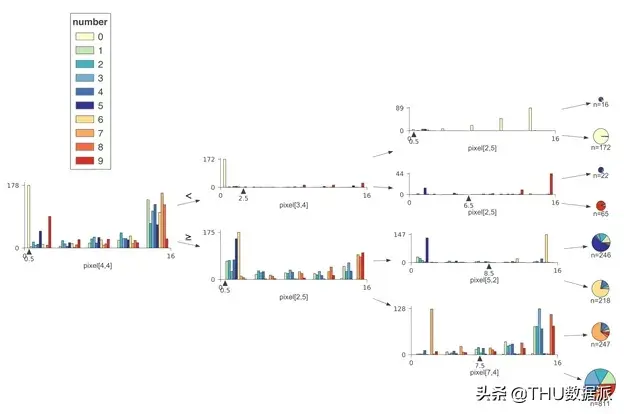
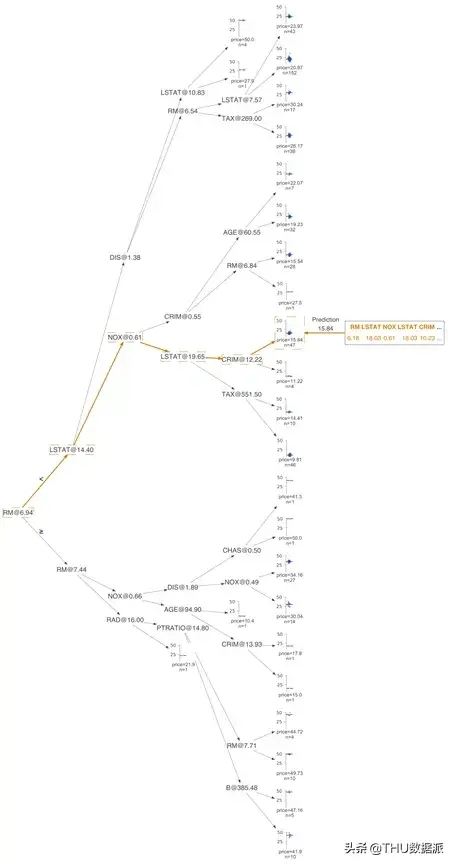
可视化特征-目标空间同行,我们通过训练数据学习到决策节点选择特征xi并在xi的值域(特征空间)进行分割,将具有相似目标值的样本分到两个子树中的一个中。准确地说,训练过程中需要检查特征和目标值之间的关系。因此,除非我们的可视化工作在决策节点上显示了特征-目标空间,否则读者很难根据可视化图像来直观理解得到预测结果的整个过程和原因。为了突出现实决策节点是如何分割特征空间的,我们以单特征(AGE)的回归树和分类树作为展示。这个案例使用波士顿房价数据中的单个特征(age)来训练回归决策树。为了便于讨论,在下图中加入了节点id:
附生成效果图的代码:
https://github.com/parrt/dtreeviz/blob/master/testing/paper_examples.py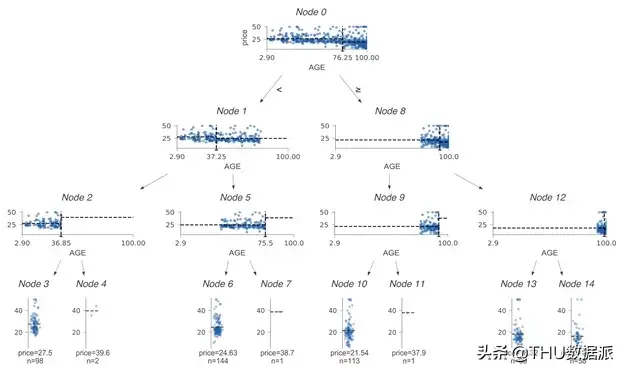
水平虚线表示决策节点中左子树和右子树的目标均值;垂直虚线表示特征空间中的分割点。下方的黑色三角形突出显示分割点并标出了确切的分割值。叶节点用虚线指示目标预测(这里使用的是平均值)。
如图所示,为了便于决策节点的比较,AGE特征轴都控制在了一个相同的值域上,而并没有将数值集中的区域进行方法。因此,决策节附近的样本的AGE值被限制在了一个狭窄的区域中。
例如,将节点0中的特征空间进一步被划分为了为节点1和8的特征空间;节点1的特征空间又进一步划分为节点2和5中所示的特征空间。当然,可以看到,这一决策树模型的预测效果并不是很好,这是因为出于展示的方便,我们仅仅单一的变量来训练模型,但是这个简单的案例给我们演示了如何可视化决策树划分特征空间的过程。
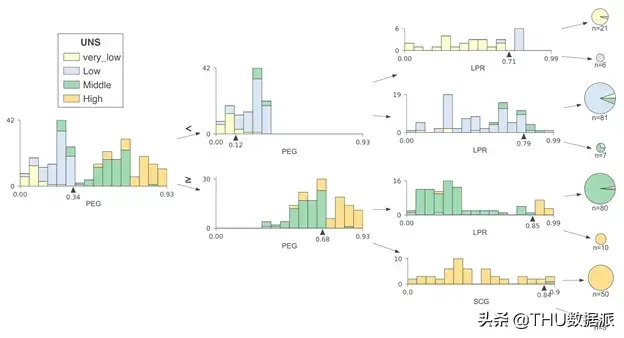
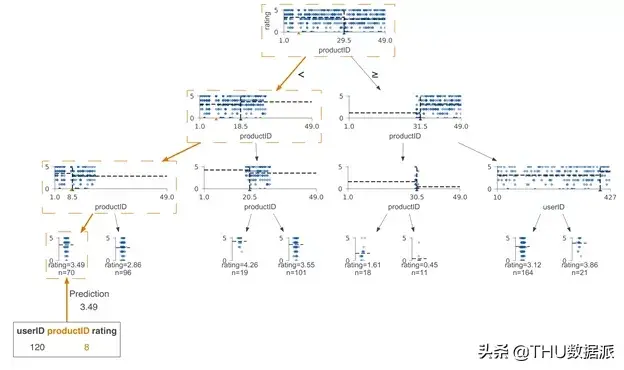
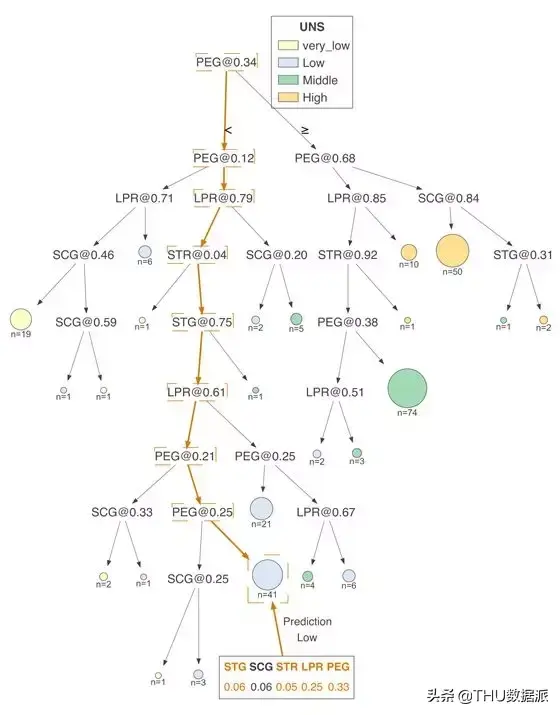
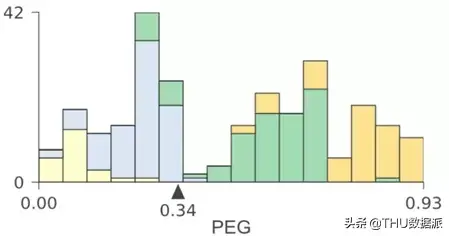
尽管分类决策树和回归决策树的在实现方式大致上相同,但对它们进行解释方式却大不相同,因此这两种情况的可视化效果是不同的。对于回归模型,最好使用特征与目标的散点图来显示特征-目标空间。但是,对于分类模型,目标是离散的类别而不是连续的数字,因此我们选择使用直方图来可视化特征目标空间。下图是在USER KNOWLEDGE数据上训练的分类树,同样我们只使用了单个特征(PEG)来进行训练,并且同样标记了节点id: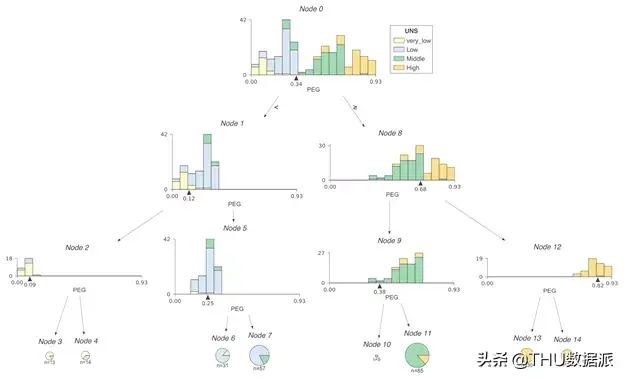
在这一案例中,直方图显示了PEG特征空间分布,而颜色则体现了特征与目标类别之间的关系。例如,在节点0中,我们可以看到具有very_low目标类别的样本聚集在PEG特征空间的左端,而具有high目标类别的样本聚集在右端。与回归树一样,左子树的特征空间和父节点上直方图分割点左侧的特征空间相同;右子树也同理。
例如,将节点9和12的直方图组合起来,可以得出节点8的直方图。我们将PEG决策节点的水平轴限制在相同范围,因此位于下方的直方图中的范围更窄,这也意味着分类更纯净。
为了更清楚地显示不同类别的特征空间,我们使用了堆叠直方图。值得注意的是,堆叠直方图在Y轴上的高度是所有类别的样本总数。多个类别的计数相互叠加。
当类别多于四或五个时,堆积直方图可读性很低,因此我们建议在这种情况下将直方图类型参数设置为不堆积的直方图。在基数较高的目标类别下,重叠的分布更难以可视化,并且出现问题,因此我们设置了10个目标类别的限制。使用10类Digits数据集(使用非堆叠直方图)所构成的一个比较浅的决策树的示例如下: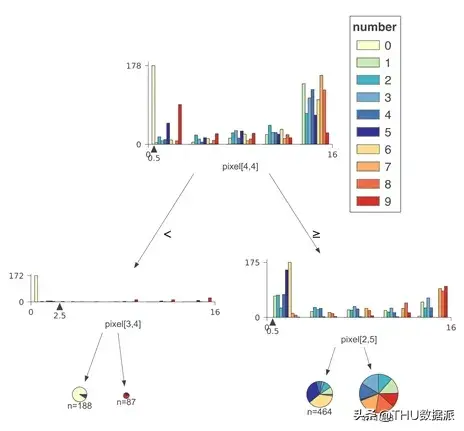
细节部分在前面的论述中,我们省略了一些最值得关注的可视化细节,在这里我们来对其中的一些关键要素展开分析。
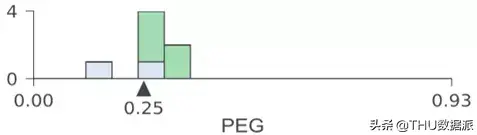
在对于分类树可视化中,我们使用了节点大小来指示每个节点包含的样本数量。随着节点中样本数量的减少和叶节点直径的变小,直方图将按比例变短。
对于给定的特征,特征空间(水平轴)始终具有相同的宽度和相同的范围,这更有利于比较不同节点的特征目标空间。所有直方图的条具有相同的宽度(以像素为单位)。为了避免混乱,我们仅在水平和垂直轴上标示了最小值和最大值。
尽管在决策树的可视化过程中一般不适用饼状图来进行呈现,但我们还是选择了使用它来体现叶节点的分类。我们通过观察图中是否有明显占主导的颜色,就可以评判分类结果的纯度。饼图最大的缺陷是无法体现元素间具体的关系。我们仅仅能从其中主导的颜色决定该节点的预测结果。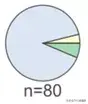
对于回归树而言,为了便于比较节点,我们将所有决策节点的目标(垂直)轴限制在相同的高度和相同的范围。对于给定的特征,回归要素空间(水平轴)始终是相同的宽度和范围。将所有散点图的透明度设置为较低水平,因此较高的目标值密度对应较深的颜色。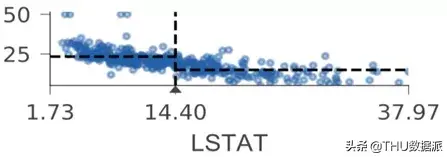
回归叶节点在垂直方向上显示相同范围的目标空间。相比于箱状图,我们选择了带状图,因为带状图能更好地表示分布,并隐含地以点数表示样本数。(我们还用文字标示了叶子节点的样本数。)关于叶节点的预测值,我们选择了带状图的质量(均值)分布中心,同时,我们使用了虚线来将其突出显示。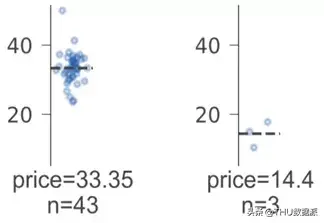
除此之外,还有许多其他细节可以提高可视化图表的效果:
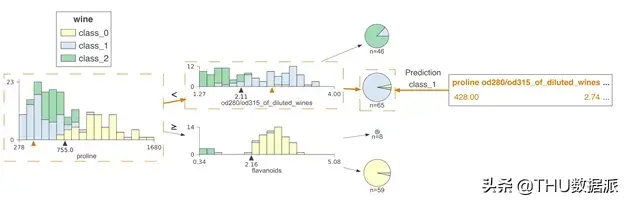
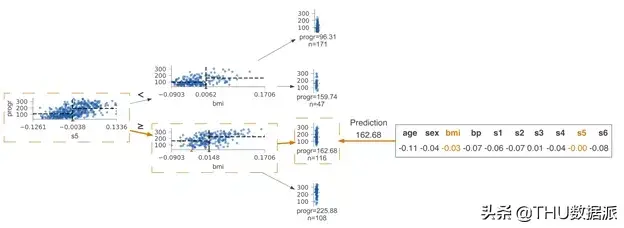
包含分类类别的图例。所有颜色均从一个对于色盲而言相对友好的调色板中进行挑选,每个2至10个目标类别绑定一个调色板。我们在文本上使用灰色而不是黑色,这更有利于人眼审视。图中的线采用细线。我们在带状图和饼状图中突出了其轮廓。新样本预测的可视化效果通过了解拆分决策节点的特征空间的过程,我们能直观地看到决策树是如何得到具体的预测结果的。现在让我们看一下如何将预测新样本的过程可视化。此处的关键是可视化从根到叶节点的路上所做出的决策。
节点内的决策很简单:如果测试向量x中的特征xi小于分割点,则归类到左子树,否则归为右子树。为了突出决策过程,我们必须重点强调比较操作。对于沿叶子预测变量节点路径的决策节点,我们在水平特征空间中的位置xi处显示了橙色三角形。
如果橙色三角形位于黑色三角形的左侧,则沿左路径,否则沿右路径。预测过程中涉及的决策节点被带有虚线框的框包围,边缘较粗且呈橙色。以下为两个测试向量的示例树: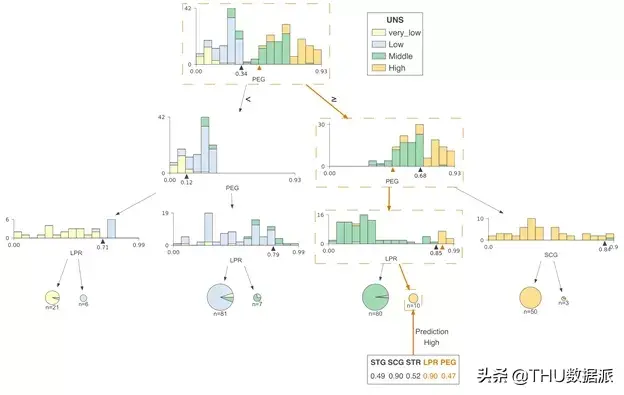
带有特征名称和值的测试向量x出现在叶子预测变量节点的下方(或横向决策树的右端)。测试向量突出显示了一个或多个决策节点中使用的特征。当特征数量达到阈值20(左右方向为10)时,测试向量不会显示未使用的特征,以避免不必要的测试向量。
横向决策树相比于纵向决策树,一些用户偏爱横向图像,有时树的性质从左到右体现得更好。在预测过程中,样本特征向量也可以从左向右延伸。以下是一些示例: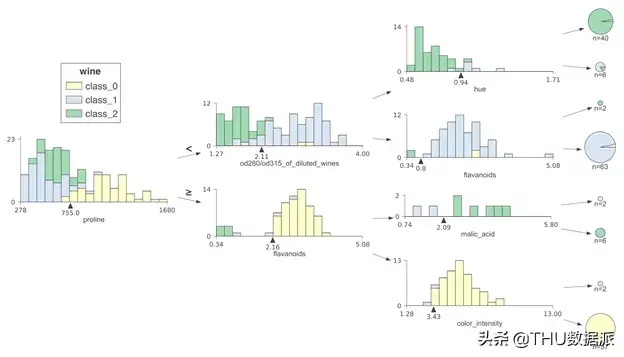

简化结构从更宏观的角度评估决策树,我们可以看到对分类过程的概述。这意味着比较树的形状和大小之类等,但更重要的是查看叶节点。我们想知道每个叶节点有多少个样本,分类的纯度如何,以及大多数样本落在哪里。
当可视化文件太大时,很难获得概述,因此我们提供了一个“non-fancy”选项。该选项可以生成较小的可视化文件,同时保留关键的叶子信息。以下案例是分别为non-fancy模式的回归树和分类树:
前车之鉴
从设计的角度对这些树可视化感兴趣的人可能会发现阅读我们尝试过并拒绝的内容很有意思。在设计分类树时,相比于块状的直方图,我们预计核密度估计会给出更准确的图像。我们完成了如下的案例: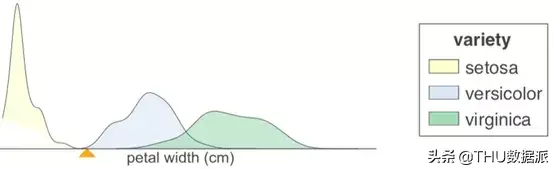
问题在于只有一个或两个样本的决策节点中,所得到的这种分布极具误导性: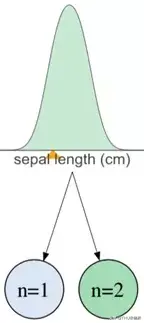
我们还尝试使用气泡图代替直方图作为分类器决策节点: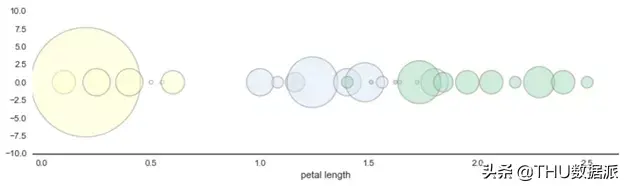
这些可视化图形看起来确实很酷,但比较下来,还是直方图更易于阅读。
关于回归树,我们考虑使用箱形图显示预测值的分布,还考虑使用简单的条形图显示样本数量: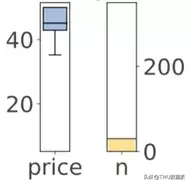
与现在使用的条形图相比,每片叶子的双图都不令人满意。箱形图无法像条形图那样显示目标值的分布。在带状图之前,我们只是使用样本索引值作为水平轴来体现目标值:
这是一种误导,因为水平轴通常是特征空间。我们将其压缩为带状图。
代码示例
本节提供了波士顿回归数据集和红酒分类数据集的可视化示例。您还可以查看示例可视化的完整库以及生成示例的代码。
回归树可视化—-以波士顿房价为例以下是一个代码示例,用于加载Boston数据并训练最大深度为3的回归树:
boston= load_boston()X_train= boston.datay_train= boston.targettestX= X_train[5,:]regr= tree.DecisionTreeRegressor(max_depth=3)regr= regr.fit(X_train, y_train)
可视化树的代码包括树模型,训练数据,特征和目标名以及新样本(如果必要的话):
viz = dtreeviz(regr, X_train, y_train,target_name=’price’, feature_names=boston.feature_names, X =testX)viz.save(“boston.svg”) # suffix determines thegenerated image formatviz.view() # pop up window to display image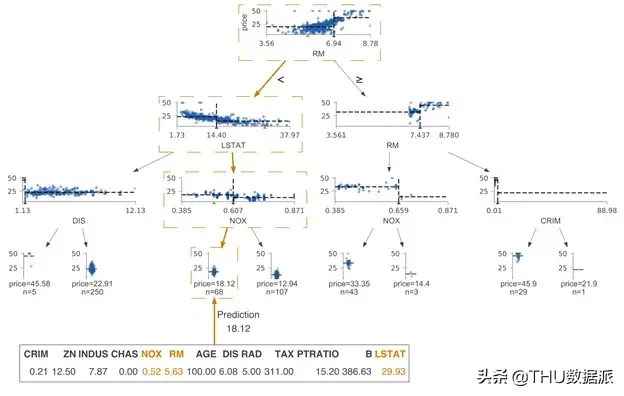
分类树可视化—以红酒为例这是一个代码案例,用于加载Wine数据并训练最大深度为3的分类树:
clf= tree.DecisionTreeClassifier(max_depth=3)wine= load_wine()clf.fit(wine.data,wine.target)
分类模型可视化与回归模型相同,但需要目标类名称:
viz= dtreeviz(clf, wine.data, wine.target, target_name=’wine’, feature_names=wine.feature_names, class_names=list(wine.target_names))viz.view()
在Jupyter notebooks中,从dtreeviz()返回的对象具有_repr_svg_()函数,Jupyter使用该函数自动显示该对象。请参阅示例笔记本。
附链接:
https://github.com/parrt/dtreeviz/blob/master/notebooks/examples.ipynb
JUPYTER NOTEBOOK中的小问题截至2018年9月,Jupyter notebooks无法正常显示此库生成的SVG,字体等会变得混乱: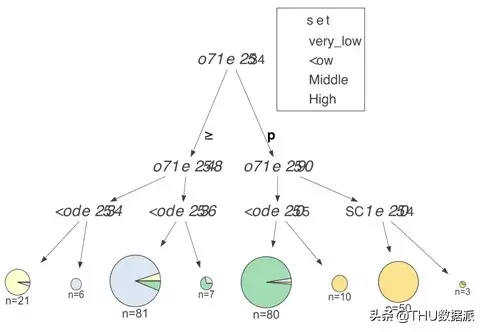
好消息是github和JupyterLab可以正确地显示图像。
在Juypter notebooks中使用Image(viz.topng())的视觉效果较差;如果直接调用viz.view(),会弹出一个窗口,其中会恰当地显示结果。
实践经验
我们在这个项目中遇到了很多问题,编程错误、参数设置、解决bug和各种库的错误/限制以及如何更好地融合现有工具。唯一有趣的部分是可视化设计的无数次尝试。期待这个可视化会对机器学习社区有很大的帮助,这也是我们坚持不懈完成项目的动力。结合stackoverflow,文档和繁琐的图形编程,我们大概花了两个月的时间完成了这个项目。
最终我们使用matplotlib生成决策和叶节点的图像,并使用传统的graphviz将它们组合成树。我们还在graphviz树的描述中广泛使用了HTML标签,以用于布局和字体规范。但我们遇到的最大麻烦是将所有组件组合成高质量的矢量图形。
我们先创建了一个影子树,它包括了scikit创建的决策树,让我们开始吧。
Scikit决策树的影子树scikit-learn的分类树和回归决策树是为提高效率而构建的,树的延伸或提取节点信息并不是重点。我们创建了dtreeviz.shadow.ShadowDecTree和dtreeviz.shadow.ShadowDecTreeNode类,以便于使用所有树信息(传统的二叉树)。以下是通过scikit分类树或回归树模型创建影子树的方法:
shadow_tree = ShadowDecTree(tree_model,X_train, y_train, feature_names, class_names)影子树/节点类具有许多方法,这些方法还可以用于需要遍历scikit决策树的其他库。例如,predict()不仅可以运用树来预测新样本,而且还返回被访问节点的路径。可以通过node_samples()获得与任意特定节点关联的样本。
工具箱
如果能掌握所有技巧,Graphviz和dot语言有助于设计合理的树型布局,例如当子树重叠时,如何隐藏图象重叠的边缘。如果要在同一水平上显示两个叶节点leaf4和leaf5,我们可以用到graphviz如下:
LSTAT3-> leaf4 [penwidth=0.3 color=”#444443″ label=<>]LSTAT3-> leaf5 [penwidth=0.3 color=”#444443″ label=<>]{rank=same;leaf4-> leaf5 [style=invis]}我们通常在graphviz节点上使用HTML标签,而不仅仅是文本标签,因为它们能更好地控制文本显示,并将表格数据显示为实际表格。例如,当显示沿着树的测试向量时,使用HTML表显示测试向量:
为了从graphviz文件生成图像,我们使用graphvizpython软件包,该软件包最终是用程序例程之一(run())执行dot二进制可执行文件。有时,我们在dot命令上使用了略有不同的参数,因此我们可以更像这样更灵活地直接调用run():
cmd= [“dot”, “-Tpng”, “-o”, filename, dotfilename]stdout,stderr = run(cmd, capture_output=True, check=True, quiet=False)我们还将使用run()函数来执行pdf2svg(PDF转SVG)工具,如下一节所述。
SVG生成的矢量图我们使用matplotlib生成决策和叶子节点,随后生成graphviz /dot图像和HTMLgraphviz标签,最终通过img标签引用生成的图像,如下所示:
<imgsrc=”/tmp/node3_94806.svg”/>94806数字是进程ID,它有利于独立运行同一台计算机的多个dtreeviz实例。否则,多个进程可能会覆盖相同的临时文件。
因为需要可缩放的矢量图形,我们先尝试着导入SVG图像,但无法通过graphviz插入这些文件(两者都不是pdf)。随后我们花了四个小时才发现生成和导入SVG是两件事,需要在OS X上使用–with-librsvg进行如下操作:
$brew install graphviz –with-librsvg –with-app –with-pango最初,当我们想从matplotlib生成PNG文件时,我们将每英寸的点数(dpi)设置为450,这样它们在iMac这样高分辨率屏幕上能有不错的效果。不幸的是,这意味着我们必须使用<td>标签的width和height参数和graphviz中的HTML表来设定整个树的大小。这会带来很多问题,因为我们必须了解matplotlib得到的宽高比。使用SVG文件后,我们不必再了解SVG 文件在HTML中的具体大小;在撰写此文档时,我们意识到没有必要了解SVG文件的具体尺寸。
然而graphviz的SVG结果仅引用了我们导入的节点文件,而没有将节点图像嵌入到整个树形图像中。这是一种很不方便的形式,因为当发送可视化树时,我们要发送文件的zip而不是单个文件。我们花了一些时间解析SVG XML,并将所有引用的图像嵌入到单个大型meta-SVG文件中。有最终,得到了很好的效果。
然后我们注意到在生成SVG时,graphviz不能正确处理HTML标签中的文本。例如,分类树图例的文本会被切除并重叠。
为了获得独立SVG文件的工作,我们首先从graphviz生成PDF文件,然后使用pdf2svg将PDF转换为SVG(pdf2cairo也似乎起作用)。
我们注意到Jupyter notebook存在一个问题,它无法正确显示这些SVG文件(请参见上文)。Jupyterlab确实可以像github一样正确处理SVG。我们添加了一个topng()方法,这样Jupyter Notebook的用户就能使用Image(viz.topng())来获取嵌入式图像。还有一个跟好的方法,调用viz.view()将弹出一个窗口,也可以正确显示图像。
经验总结
有时解决编程问题与算法无关,而与编程语言的限制和功能有关,例如构建一个工具和库。决策树可视化软件也是这种类似的情况。编程并不难,我们是通过搭配适当的图形工具和库来得到最终的结果。
设计实际的可视化效果还需要进行无数次的实验和调整。生成高质量的矢量图还需要不断试错,对结果进行完善。
我们算不上可视化的狂热者,但是对于这个特定的问题,我们一直坚持了下来,才收获了理想的效果。在爱德华·塔夫特(Edward Tufte)的研讨会上,我了解到,只要不是随意的瞎搭配,我们就可以在人眼可以处理的限度下使用丰富的图表呈现大量的信息。
在这个项目中,我们使用了设计面板中的许多元素:颜色,线条粗细,线条样式,各种图,大小(区域,长度,图形高度,…),颜色透明度(alpha),文本样式(颜色,字体,粗体,斜体,大小),图形注释和视觉流程。所有视觉元素都发挥了相应的作用。例如,我们不能仅因为某一个颜色漂亮就使用它,而是要考虑到如何使用这个颜色来突出显示重要的维度(目标类别),因为人类能轻松且快速地发现颜色差异。节点大小的差异也应该很容易被人眼捕捉到,所以我们用节点的大小来表示叶子节点数据量的大小。
未来工作
本文档中描述的可视化内容是dtreeviz机器学习库的一部分,该库还处于起步阶段。我很快会将rfpimp库移至dtreeviz。到目前为止,我们只在OS X上测试过该工具。我们期待其他平台上的程序员提供更多执导,以便包括更丰富的安装步骤。
我们还在考虑几个细节的调整,例如使直方图和分类树底部对齐,会更利于比较节点。另外,某些三角形标签与轴标签重叠。最后,如果边缘宽度和子树中的样本量成比例就更好了(如SAS)。
原文标题:
How to visualize decision trees
原文链接:
https://explained.ai/decision-tree-viz/index.html
编辑:黄继彦
校对:林亦霖
译者简介
王雨桐,UIUC统计学在读硕士,本科统计专业,目前专注于Coding技能的提升。理论到应用的转换中,敬畏数据,持续进化。
—完—
关注清华-青岛数据科学研究院官方微信公众平台“ THU数据派 ”及姊妹号“ 数据派THU ”获取更多讲座福利及优质内容。
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/86837.html