
Decision Trees 决策树
创建: 2020 年4 月14 日5:28 PM
什么是决策树?
决策树以树结构的形式构建分类或回归模型。树决策是从根(开始)到叶节点进行的。决策树往往会过度拟合,因此可以使用剪枝来简化模型。
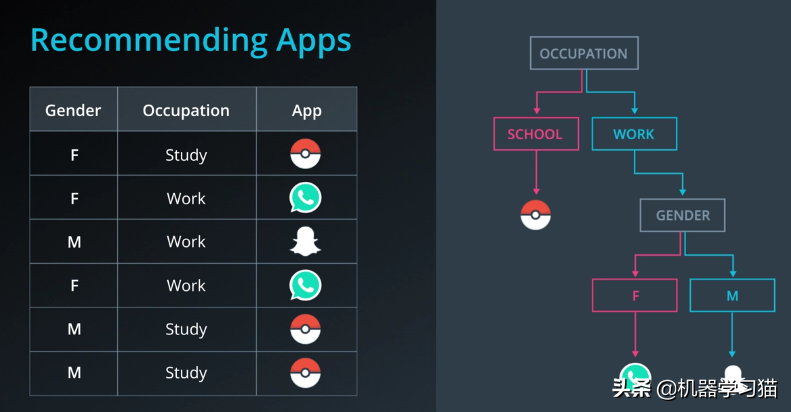
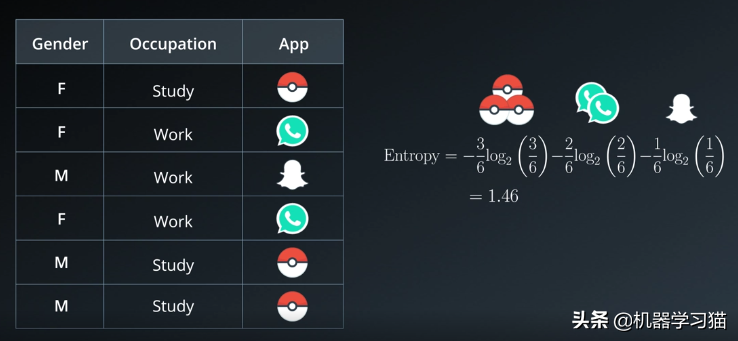
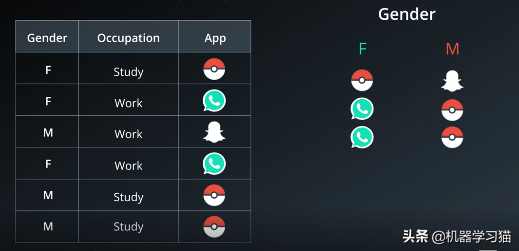
在创建APP推荐引擎时,我们的任务是根据现有数据推荐人们最有可能下载的APP。左表是6个用户的数据,分别是性别、职业、APP。已下载。
创建一棵树,如下图右侧所示。如果您是学生,我们推荐Pokemon Go。接下来,创建一个性别节点。男孩建议使用Snapchat。
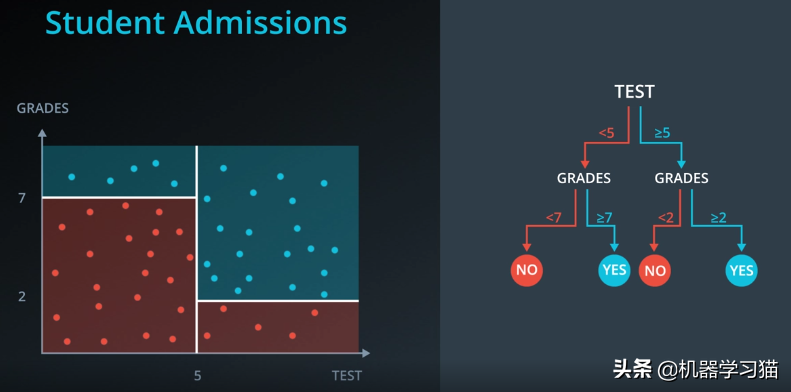
另一个例子是根据考试成绩和常规成绩决定学生是否被录取。您可以使用相同的方法来构建树。
树构建算法 Tree construction algorithms
ID3 用于分类C4.5。分类与C5.0类似,与C4.5相比,它使用更少的内存并构建更准确的规则集。 CART(分类和回归树)可用于分类和回归。这些有一些共同点。两者都是贪婪算法并且是自上而下的方法。
区别:属性选择的衡量方式不同:C4.5(增益比)、CART(基尼指数)、ID3(信息增益)
Entropy 熵
熵是物理学中的一个概念。如果系统中的粒子可以移动到多个位置,则系统的熵很高。如果系统是刚性的,粒子活性低,则系统的熵就会低。
例如,水在固态、液态和气态下具有不同的熵。冰的熵很低,因为冰中的分子必须保持在晶格内的刚性系统中。 液态水之所以有介质,是因为水中的分子可以移动到更多的地方。
熵。 水蒸气具有高熵,因为水蒸气中的分子几乎可以移动到它们想去的任何地方

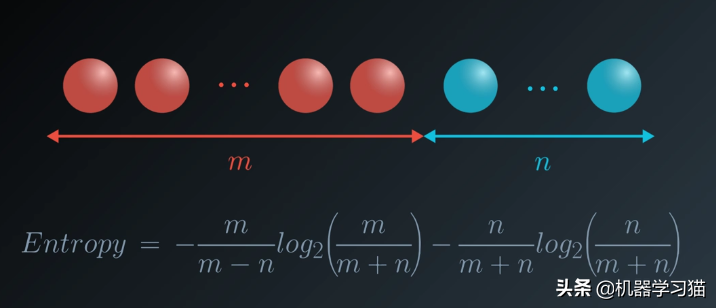
如果桶中有m个红球和n个蓝球,使用排列采样,上图中的熵将是:

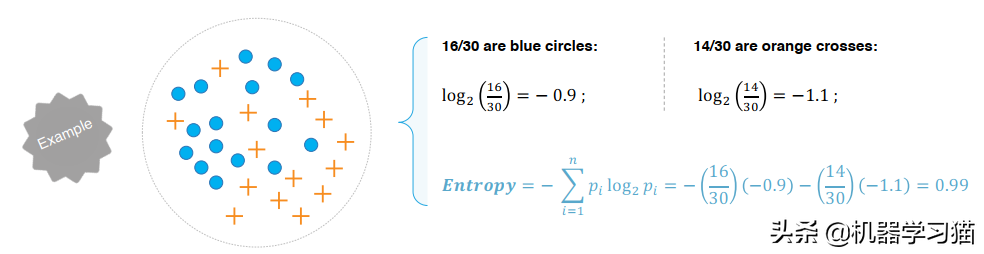
Information Gain 信息增益
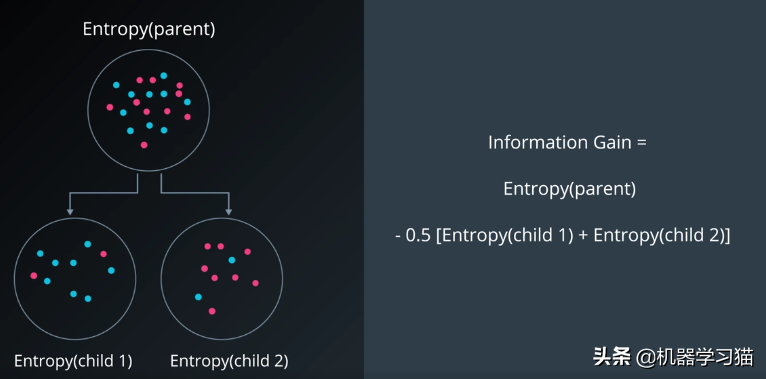
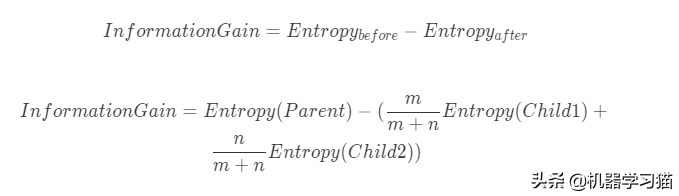
以推荐APP为例,构建决策树,计算信息增益,选择信息增益最大的。
1.计算类别信息增益为1.46。这显示了所有样本的各个类别中出现的不确定性的总和。
2. 按性别获取的信息量
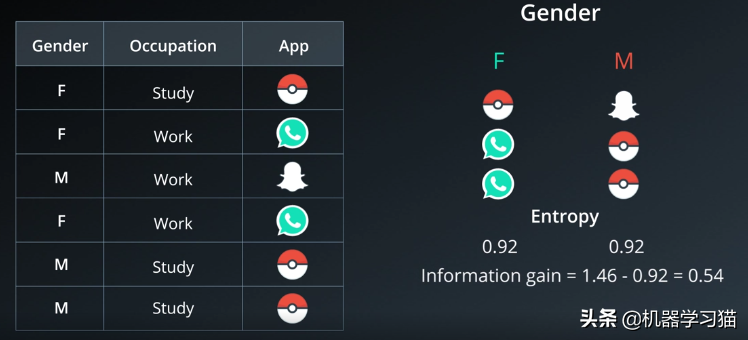
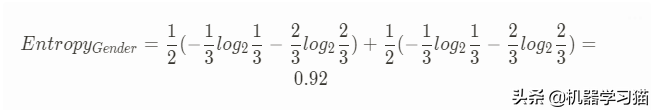
1/2是指总样本除以年龄。
信息增益=熵-熵性别=1.46-0.92=0.54
3. 按职业获取信息
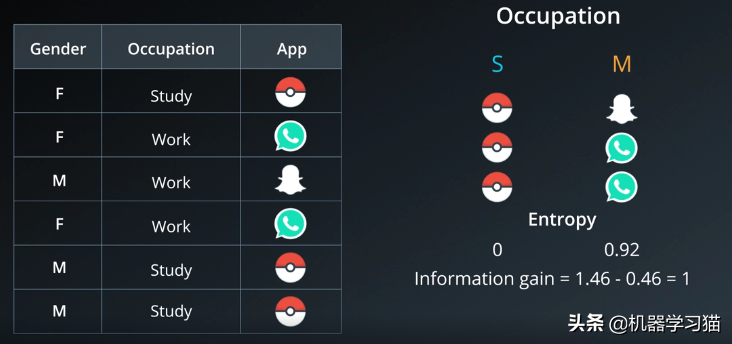
信息增益=熵-熵性别=1.46-0.46=1
选择职业作为第一个节点,因为职业的信息增益大于性别的信息增益
ID3算法
树从训练样本中的单个节点开始(步骤1)。如果样本都属于同一类,则该节点将成为叶子并用该类进行标记(步骤2 和3)。否则,该算法使用称为信息增益的基于熵的度量作为启发式信息来选择对样本进行最佳分类的特征(步骤6)。该函数成为节点的“决策”函数(步骤7)。在此版本的算法中,所有特征都是分类的或离散值的。连续属性必须离散化。为决策特征的每个已知值创建一个分支,并相应地分割样本(步骤8-10)。该算法使用相同的过程递归地为每个分区形成样本决策树。一旦某个特征出现在某个节点上,就无需考虑该节点的后代(步骤13)。仅当以下条件之一为真时,递归分割步骤才会停止: (a) 特定节点的所有样本属于同一类(步骤2 和3)。
(b) 没有剩余特征可用于进一步划分样本(步骤4)。在这种情况下,请使用多数投票(步骤5)。也就是说,将给定的节点转换为叶子,并用大多数样本所属的类来标记它们。
(c) 分支test_attribute=a i 没有样本(步骤11)。在本例中,创建一个包含样本中多数类的叶子(步骤12)。
超参数
最大深度每个分割的最小样本数最大特征数
sklearn实现决策树
# Import statements from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import precision_score import pandas as pd import numpy as np # 读取数据。 asarray(pd.read_csv(‘data.csv’, header=None)) # 将特征分配给变量X,将标签分配给变量y。 X=data[:0:2] y=data[:2 ] # 1. 构建决策树模型。 # TODO: 创建决策树模型并将其分配给变量model=DecisionTreeClassifier()。 # 2. 将模型与数据进行拟合。 # 适配TODO:模型。 ) # 3. 使用模型进行预测。 # TODO: 将预测保存到变量y_pred。 y_pred=model.predict(X) # 4. 计算模型的准确率。 # TODO: 计算精度并将其分配给变量acc。 acc=准确度得分(y, y_pred)
C4.5算法
由于信息获取比值较少的特征更青睐值较多的特征,因此这些“超级特征”很容易被选为根,导致它变得非常宽,性能受到影响。另一种特征选择方法,信息增益比,可以用来惩罚具有大量值的特征。
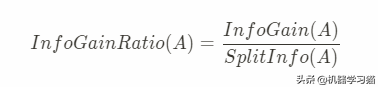
信息增益比本质上是信息增益乘以惩罚参数1/SplitInfo(A)。如果特征很小,SplitInfo(A)就会很小,所以它的倒数就会很大,信息增益就会很大。因此,存在对低值特征的偏见。
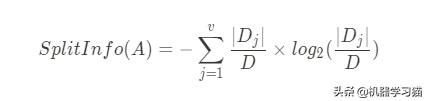
缺点:特征提供的信息少于偏差值
1. 计算SplitInfo(A)
通过计算上述两个特征(性别和职业)的信息增益率,选择信息增益率最高的特征(职业###)。
CART算法
CART算法基于基尼系数:样本被选择的概率* 样本被错误分类并选择特征的概率
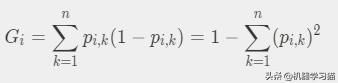
pk表示所选样本属于k个类别的概率。在这种情况下,该样本被错误分类的概率为(1-pk)。
1.计算性别基尼系数
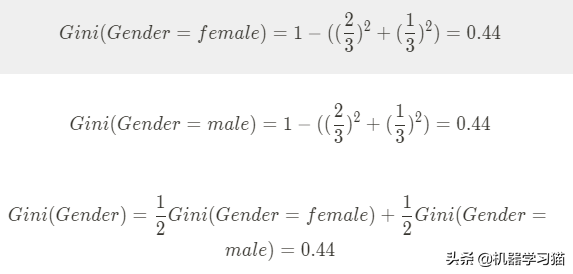
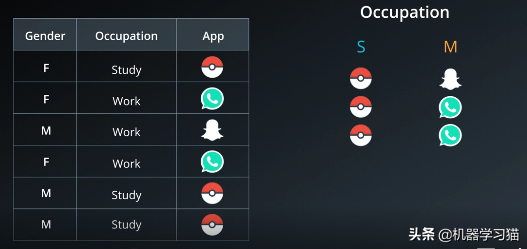
2.计算职业的基尼系数
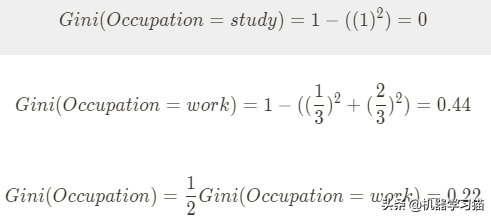
计算上述性别和职业两个特征的基尼系数,选择基尼系数最小的特征职业。
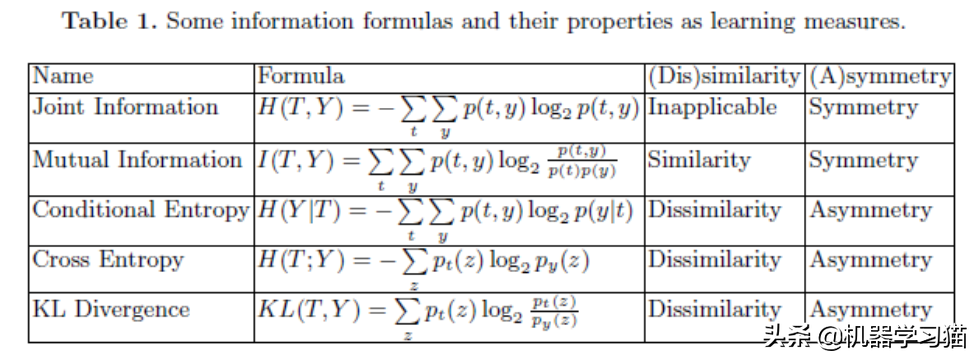
熵和互信息
平均互信息:了解有关特征Y 的信息减少有关标签X 的信息的不确定性的程度。
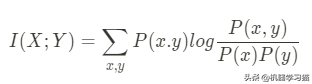
剪枝
一种策略是尽早停止树木生长,以防止树木变得过于复杂。我无法选择合适的阈值。另一种策略是首先构建一棵完整的树,然后将其修剪回更简单的形式,删除不重要的分支并用叶节点替换子树。
决策树的优势
易于理解和解释决策树是“白盒”模型。决策树可以产生“可理解的”规则。树木也可以被形象化。相比之下,对于黑盒模型(例如神经网络和随机森林),通常很难用简单的术语解释为什么做出预测。
构建决策树只需要很少的数据准备。决策树可以处理合理数量的缺失值。它也不受异常值的影响。 相比之下,其他算法通常需要数据标准化、创建虚拟变量以及删除空白值。
决策树可以处理连续变量和分类变量。其他技术通常专门分析仅具有一种变量类型的数据集。可以处理多个输出问题。
执行隐式特征选择例如,决策树(例如CART)具有用于执行特征选择的内置机制。决策树清楚地显示哪些字段对于预测或分类最重要
决策树的缺点
往往会过度拟合,并可能构建过于复杂的树,从而导致模型性能不佳。
要在不平衡的数据情况下创建有偏差的树,请在拟合不稳定数据之前平衡数据集,因为数据的微小变化可能会产生完全不同的树。通过在集成中使用决策树可以缓解这个问题。随机森林可以通过对许多树的预测进行平均来限制这种不稳定性。
决策树中使用的贪婪方法并不能保证最优解。由于贪心算法无法在每个节点做出局部最优决策,因此无法保证返回全局最优决策树。这可以通过训练多个树来缓解,其中特征和样本是通过排列随机抽取的。参考:【https://www.cnblogs.com/muzixi/p/6566803.html】
原创文章,作者:小条,如若转载,请注明出处:https://www.sudun.com/ask/86895.html