
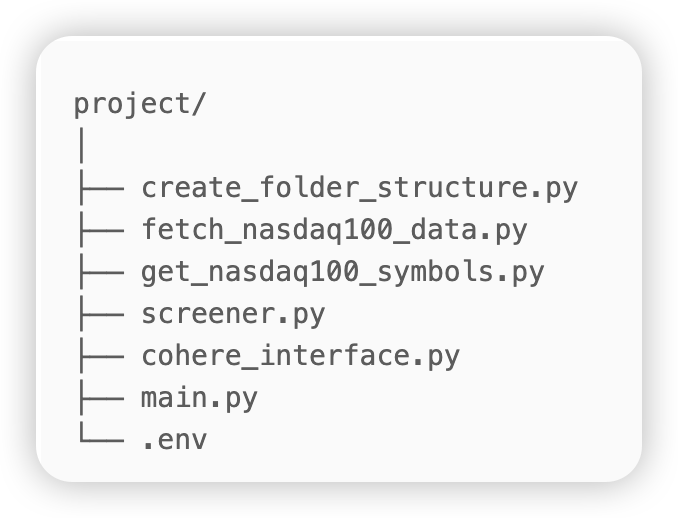

其中最关键的过程是数据处理和智能分析的部分,以下是关于这部分代码的详细技术分析,解释其实现原理和流程。
导入库和模块
import os
import pandas as pd
import yfinance as yf
from datetime import datetime, timedelta
from cohere_interface import Cohere # 确保导入Cohere类
from concurrent.futures import ThreadPoolExecutor
这些库和模块提供了基本的数据处理和并行处理功能:
-
os:用于操作文件和目录。 -
pandas:强大的数据处理库。 -
yfinance:用于从Yahoo Finance获取金融数据。 -
datetime和timedelta:用于日期和时间操作。 -
Cohere:自定义模块,用于与Cohere API交互。 -
ThreadPoolExecutor:用于并行处理,以提高数据处理速度。
Screener 类定义
class Screener:
def __init__(self, folder):
self.index = folder # 设置索引为文件夹名称
self.folder = f'/data/historical/analysis/{folder}/' # 设置数据文件夹路径
self.files = os.listdir(self.folder) # 获取文件夹中的所有文件
self.df_all = pd.DataFrame() # 初始化空的数据框,用于存储最终数据# 创建数据文件夹
if not os.path.exists(self.folder):
os.makedirs(self.folder)
-
初始化Screener类时,设置索引和数据文件夹路径。 -
获取文件夹中的所有文件名。 -
初始化一个空的DataFrame,用于存储最终的数据。 -
如果数据文件夹不存在,则创建该文件夹。
处理单个文件的方法
def process_file(self, filename):
if (filename.endswith('xlsx') or filename.endswith('csv')) and not filename.startswith('~$'):
file_path = os.path.join(self.folder, filename)
print(f"Processing file: {file_path}")try:
df = pd.read_csv(file_path) # 读取CSV文件
df[‘Date’] = pd.to_datetime(df[‘Date’], utc=True) # 转换日期列为日期时间格式
df[‘Date’] = df[‘Date’].dt.date # 提取日期部分
current_date = df.iloc[-1][‘Date’] # 获取最新日期
symbol = filename.split()[0] # 获取股票符号
info = yf.Ticker(symbol).info # 获取股票信息
# 提取关键财务数据
pe = info.get(‘trailingPE’, None)
pb = info.get(‘priceToBook’, None)
debtToEquity = round(info.get(‘debtToEquity’, 0) / 100.0, 2)
dividend_yield = info.get(‘dividendYield’, None)
eps_growth = info.get(‘earningsQuarterlyGrowth’, None)
close = df.iloc[-1][‘Close’]
# 生成数据字典
data = {
‘date’: [current_date],
‘symbol’: [symbol],
‘pe’: [pe],
‘pb’: [pb],
‘debtToEquity’: [debtToEquity],
‘dividend_yield’: [dividend_yield],
‘eps_growth’: [eps_growth],
‘close’: [close]
}
df_change = pd.DataFrame(data) # 将数据字典转换为数据框
self.df_all = pd.concat([self.df_all], axis=0) # 将新的数据框添加到总数据框中
except Exception as e:
print(f”Error processing file {file_path}: {e}“)
-
检查文件是否是Excel或CSV格式且不是临时文件。 -
读取CSV文件并转换日期格式。 -
获取最新的日期和股票符号。 -
使用 yfinance获取股票的财务信息。 -
提取关键财务数据:市盈率、价格与账面比、负债股本比、股息收益率、每股收益增长率和收盘价。 -
生成包含这些数据的字典,并将其转换为DataFrame。 -
将新的DataFrame添加到总的DataFrame中。 -
如果处理文件时出错,捕获异常并打印错误信息。
并行处理文件的方法
def run(self):
with ThreadPoolExecutor(max_workers=4) as executor: # 使用4个线程并行处理
executor.map(self.process_file, self.files)
-
使用 ThreadPoolExecutor并行处理文件。 -
max_workers=4指定使用4个线程并行处理文件。 -
executor.map(self.process_file, self.files)依次将文件传递给process_file方法进行处理。
将结果存储到CSV的方法
def store_in_csv(self):
# 将最终数据存储到CSV文件中
folder = f'./data/historical/screener/'
if not os.path.exists(folder):
os.makedirs(folder)
filename = f'{self.index}_{str(datetime.today()}.csv'
path = os.path.join(folder, filename)
self.df_all.to_csv(path, index=False)
-
将最终的数据存储到CSV文件中。 -
检查存储文件夹是否存在,如果不存在则创建。 -
生成包含当前日期的文件名。 -
将DataFrame保存到CSV文件中,不包含索引。
使用Cohere进行AI筛选的方法
def ai_screening(self):
# 使用Cohere进行AI筛选
co = Cohere()
message = f"""你将获得一些股票的数据。请分析这些数据并筛选出2只被低估且未来有可能产生更高回报的股票。以下是数据 {self.df_all}"""
preamble = """你是一名优秀的股市分析师,能够很好地理解提供的数据并做出谨慎的决策。输出应严格采用以下JSON格式:
[
{
"stock": "股票名称",
"justification": "筛选或选择该股票的理由"
},
{
"stock": "股票名称",
"justification": "筛选或选择该股票的理由"
}
]"""
result = co.chat_cohere(message=message, preamble=preamble)
print(result)
-
使用Cohere API进行AI筛选。 -
创建Cohere对象。 -
定义要发送给Cohere的消息,包含待分析的股票数据。 -
定义消息的前言,设置任务和输出格式的上下文。 -
调用 chat_cohere方法发送消息并接收结果。 -
打印筛选结果。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/87989.html