
在编程社区中,众所周知Python编程语言在速度方面并不占优势。
“但是就是慢…”
在这篇文章中,我将介绍Python的不同特性,我们将了解为什么这使其成为当今最完整的语言之一,但速度不够快。但首先,让我们掌握一些关于编程语言的基本知识。
抽象级别
正如我们可能知道的那样,编程语言通常根据其抽象级别进行描述。
- 低抽象级别表明该语言更接近硬件(难以解释)
- 高级别表示代码更接近用户(易于解释)。
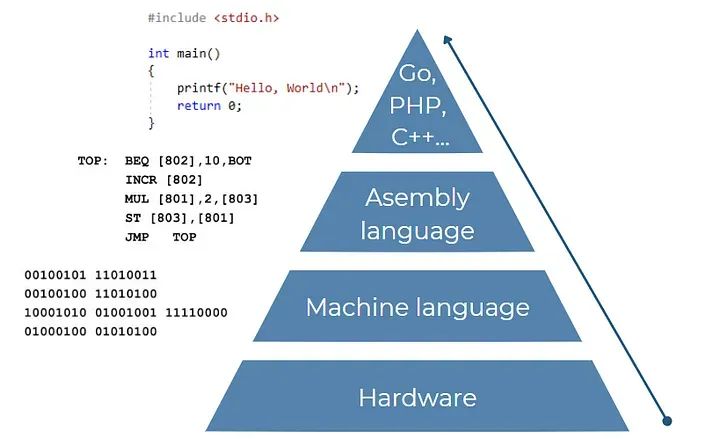

抽象级别(从硬件到现代编程语言)
C++、PHP、Java、Python等都被认为是现代(或高级)编程语言,因为它们可以在几乎任何类型的系统上运行。在汇编语言中,我们必须根据每个特定处理器的指令编写不同的程序(无法在不同的CPU上运行相同的代码)。例如,如果我们创建一个打印“Hello world”的程序并将代码发送给我们的朋友(他有不同的计算机型号),当他尝试执行它时,它可能会失败。
现代语言 金字塔的最后抽象层

现代语言抽象
尽管是离机器码最高的抽象,但在金字塔的最后一层也有层次结构。一方面,我们可以找到过程化语言,如C,我们需要逐步知道自己在做什么。这具有非常高效的优点,但缺点是复杂且不够灵活。另一方面,其他语言通过让我们使用更易读和灵活的代码来简化任务。这就是Python的情况。我们几乎可以用它做任何事情,而且易于实现,但在某些任务上效率不高。
但为什么Python确切地说是“慢”呢?
让我们回顾一些语言特性以回答这个问题。
解释性语言
首先,Python是一种解释性语言,这意味着代码由软件程序(称为解释器)逐行读取和执行,在运行时进行。这是将代码转换为机器代码的一种方式。
编译型语言
另一种使代码“为机器可理解”的方式是通过编译过程。在这种情况下,源代码在实际在计算机上运行之前通过编译器转换为机器代码。
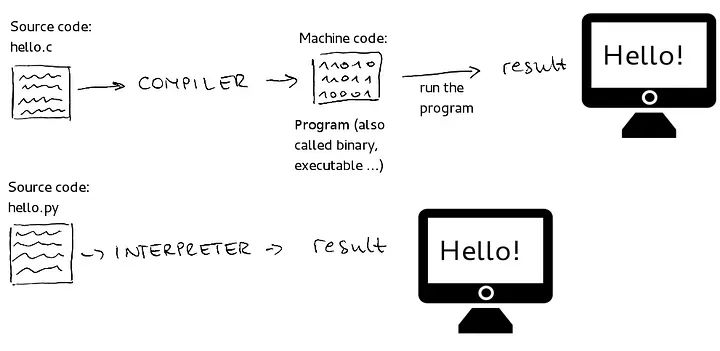 编译型与解释型语言
编译型与解释型语言
为什么解释性方式更慢?
在解释性语言中,源代码的每一行在执行过程中都会即时转换为机器代码。这意味着每次程序运行时,解释器必须解析、分析和执行代码,这增加了与直接运行预编译机器代码相比的开销。例如:如果某段代码运行多次(例如,在循环内),解释器必须每次遇到时读取和转换它。相反,编译程序将直接运行机器代码,无需在通过循环时重新翻译它。
CPython及其全局解释器锁(GIL)
标准的Python解释器是CPython。它由C和Python编写,将Python代码编译成字节码,然后进行解释。为了防止多个本机线程同时执行Python字节码,CPython使用全局解释器锁。这个锁是必要的,因为CPython的内存管理不是线程安全的。然而,在多线程程序中,它可能是一个显著的瓶颈,限制了在多核处理器上进行多线程的性能提升。
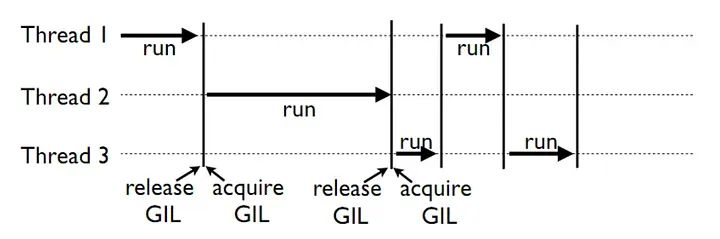 全局解释器锁的工作流程
全局解释器锁的工作流程
动态类型
此外,Python是动态类型的,这意味着在初始化变量时不需要声明变量的类型。这对效率有何影响呢?嗯,在动态类型语言中,类型是在运行时确定的。这意味着解释器需要在执行代码片段时进行类型检查。这需要额外的处理来确定每个变量的类型以及根据这些类型执行操作的方式。而动态类型语言的对立面是什么?
静态类型语言!
在这种情况下,变量的类型在编译时而不是在运行时确定。因此,类型在编译时已知,编译器可以更激进地优化代码执行。这导致更快但不够灵活的程序。一些采用这种方法的语言包括C++和Rust。
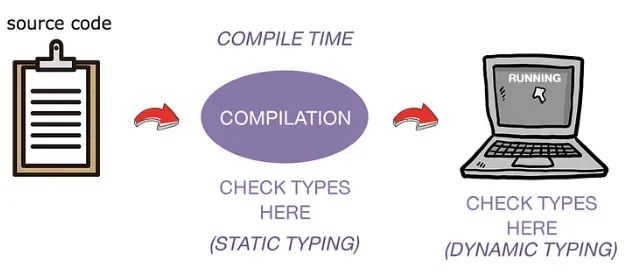 静态类型与动态类型语言
静态类型与动态类型语言
垃圾收集
垃圾收集是一种编程语言运行时系统用于回收程序不再使用的内存的自动内存管理形式。Python通过垃圾收集自动管理其对象的内存分配和释放。它使用的主要垃圾收集方法是引用计数。Python中的每个对象都有一个引用计数,即指向它的引用数量。当引用计数降至零,即不再有指向该对象的引用时,它会立即从内存中删除。
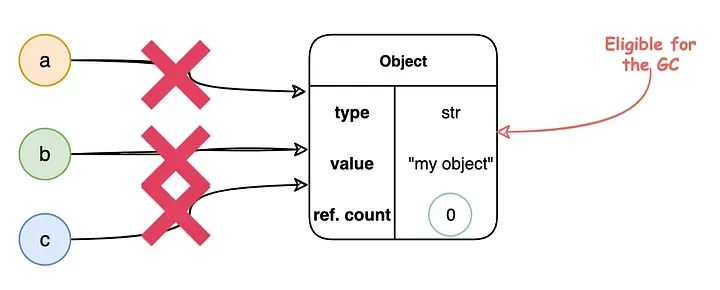
垃圾收集器的工作流程
然而,垃圾收集是一把双刃剑…
它通过自动清理未使用的对象极大简化了内存管理,有助于防止由于手动内存管理导致的内存泄漏和其他错误。但它引入了开销和不可预测性,可能影响应用程序的性能。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/88001.html