
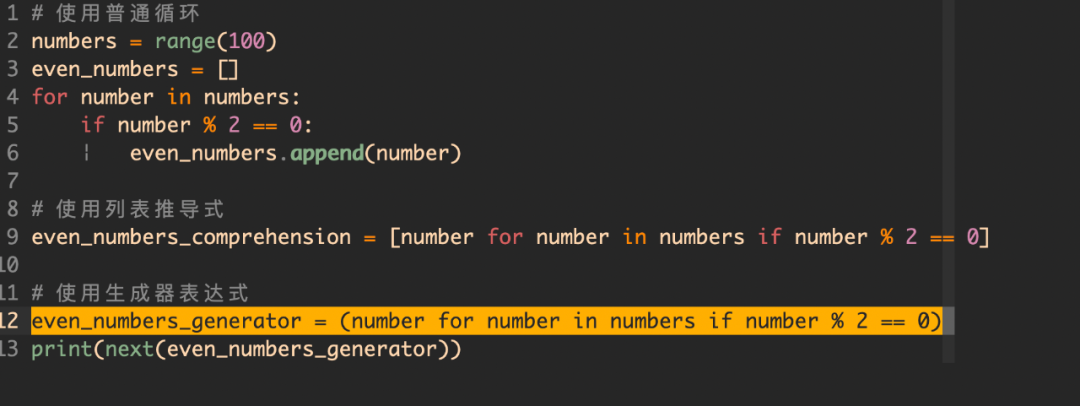
1, 善用表达式
比如我们需要从一组数字中筛选出所有的偶数,使用列表推导式和生成器表达式可以提高代码的效率和可读性。
2, 使用缓存
如果我们有一个计算成本较高的函数,比如计算斐波那契数列的第 n 项,那么使用 functools.lru_cache 缓存可以显著提高效率。
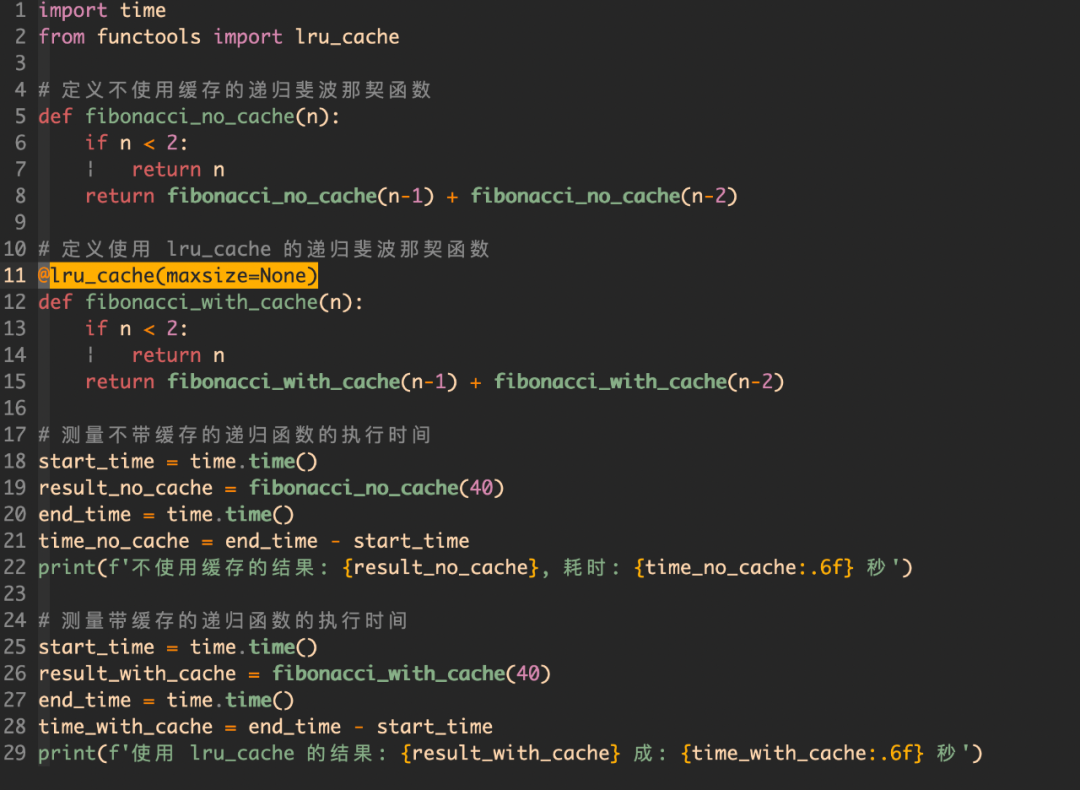
运行结果:
不使用缓存的结果: 102334155, 耗时: 31.831377 秒
使用 lru_cache 的结果: 102334155 成: 0.000032 秒
3, 可以用局部变量就不要用全局变量
这是因为 Python 访问局部变量比访问全局变量要快。
尽可能将变量定义在函数内部,这样可以利用 Python 的局部变量快速访问机制。
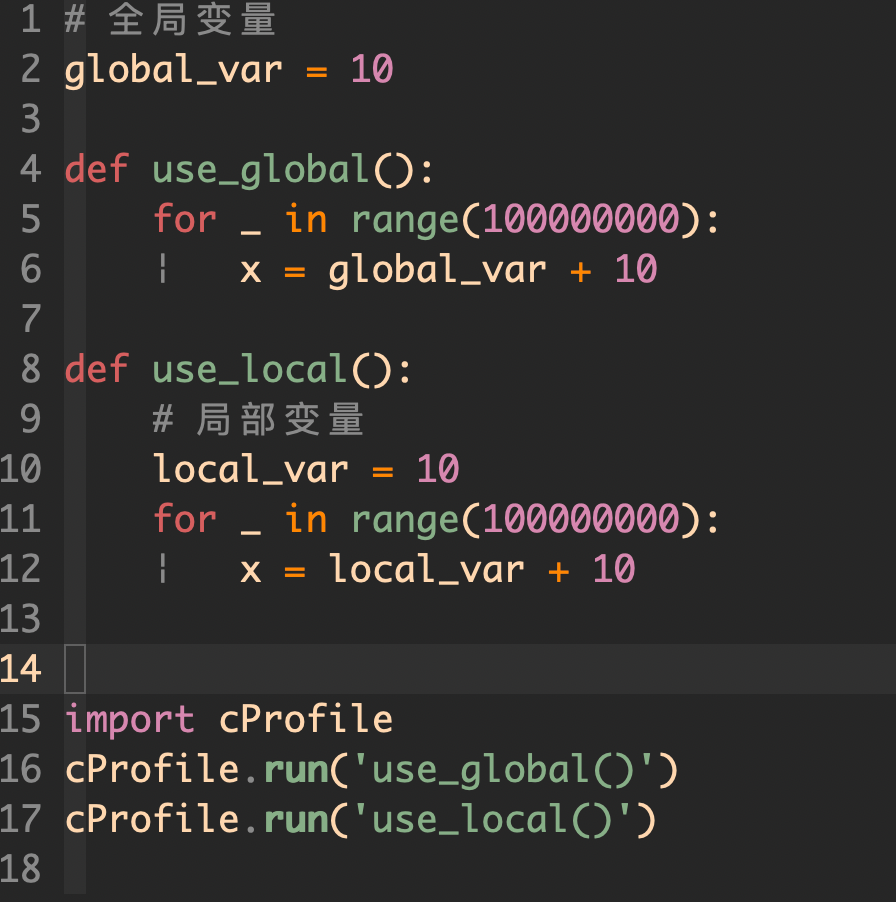
运行结果:
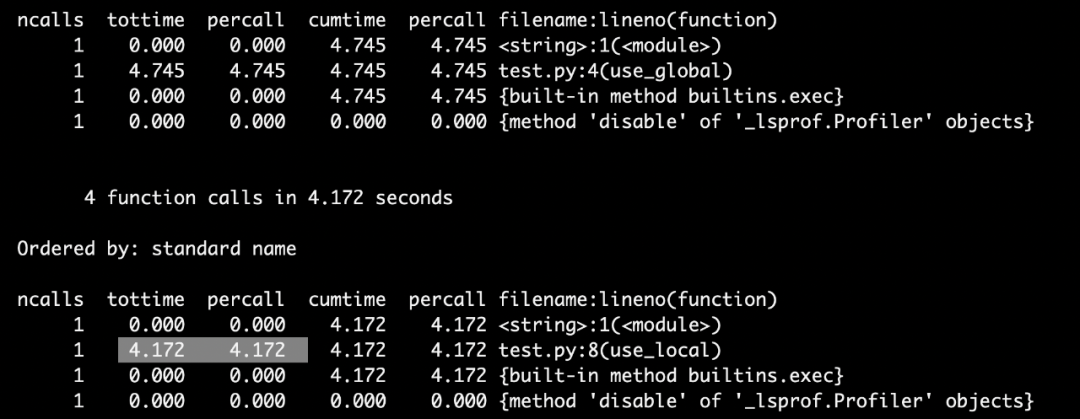
可以看到,使用局部变量耗时较短。
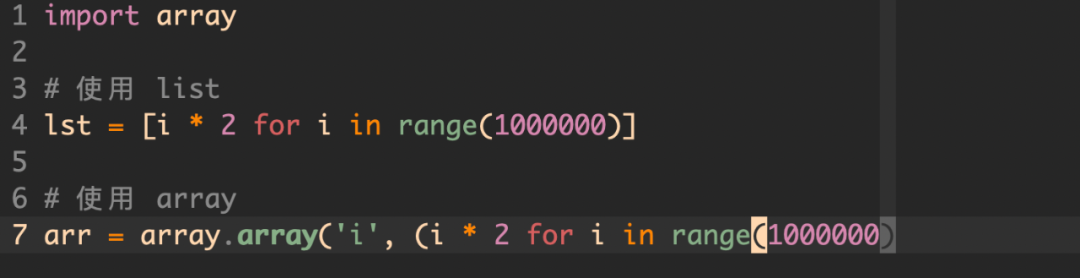
4, 使用 array 替代 list
如果你要存储的数据是同一类型的,那么可以使用 array 代替 list,这样就不用额外的去存储类型数据,减少内存。
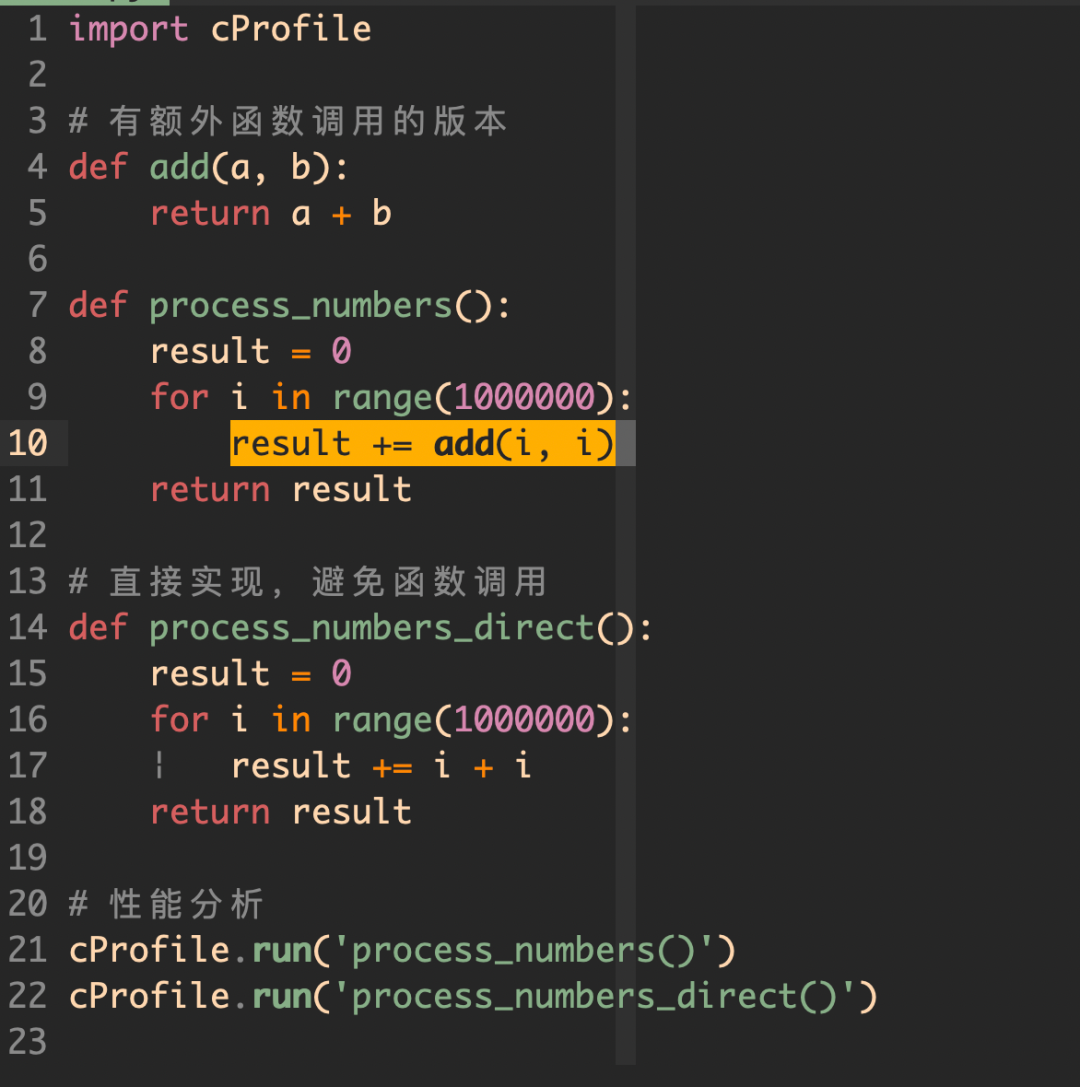
5, 减少不必要的函数
虽然说函数可以让我们提高复用,减少代码冗余,但凡事都有个物极必反,如果过度使用不必要的函数,就会影响性能,比如:
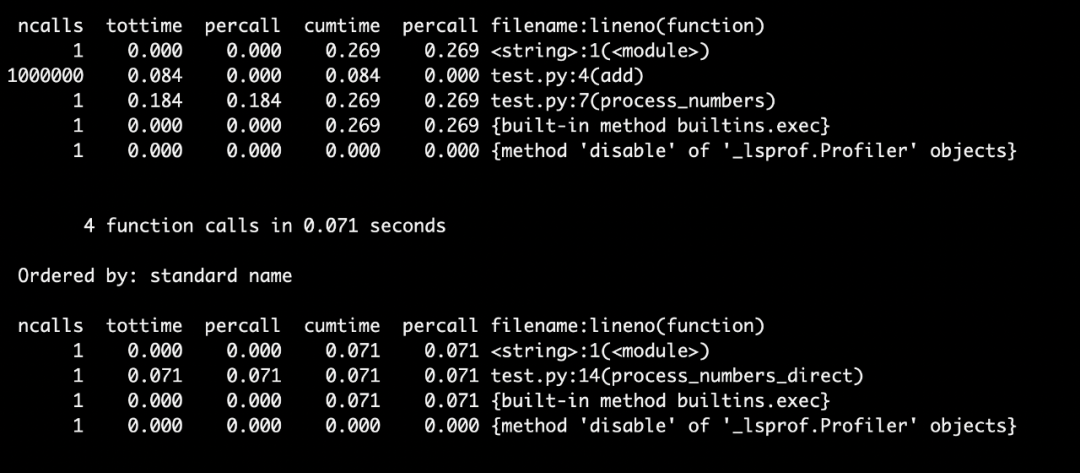
结果如下:
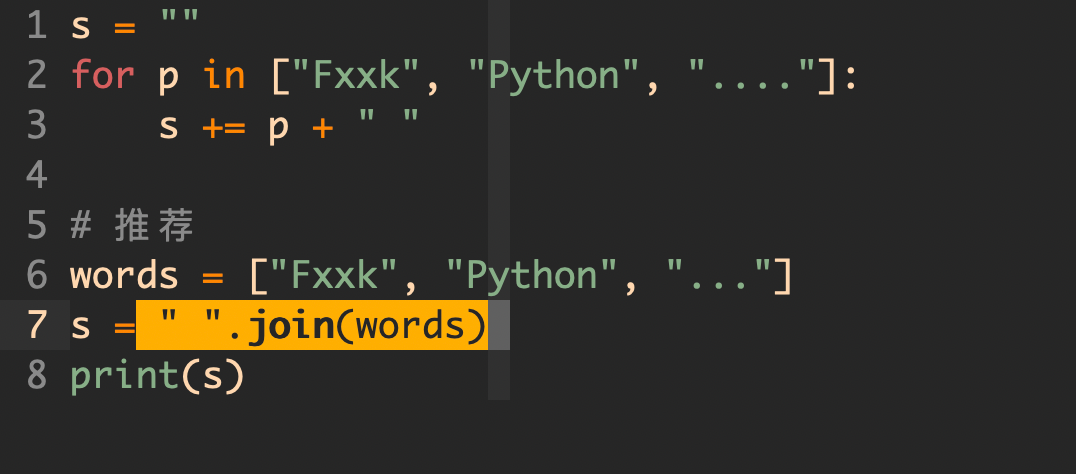
6, 使用 join 而不是用 +
我们常常会使用到字符串的拼接,很多时候我们会直接使用 「+」来连接字符串,每次使用 「+」 都会创建一个新的字符串,不过这在循环或大量字符串操作时就会显得很低效了。
可以使用 join 方法,因为它在内存中只创建一次新字符串。
7,避免贪婪匹配
我们在写正则表达式的时候,对于处理匹配大量数据的时候,应该减少贪婪匹配的使用,这样做的好处是可以减少不必要的性能消耗。
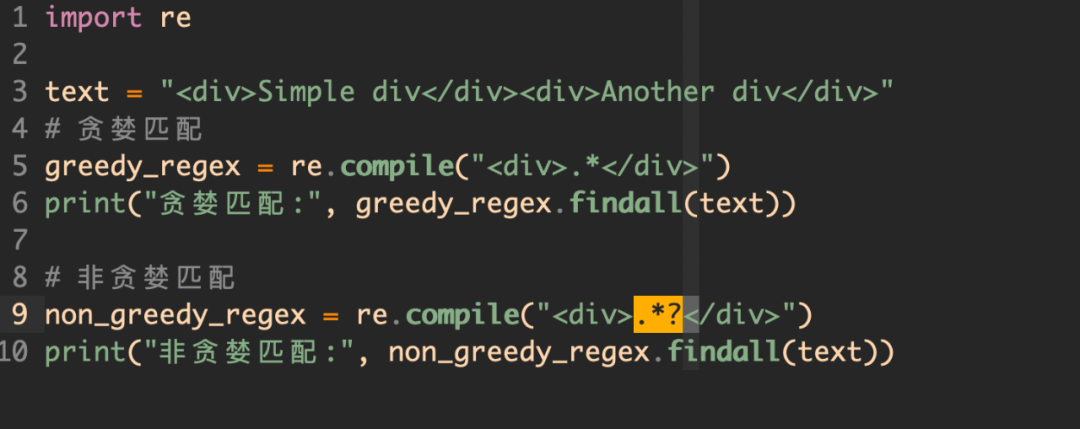

可以看到,我们使用加一个 「?」,正则表达式变为非贪婪的,就可以更少的匹配字符。
8,使用 intern 节省内存
如果你使用到大量字符串时,可以使用 intern 方法,这可以在一定程度上优化重复字符串的存储。
使用 intern 驻留,相同的字符串字面量只存储一次,多处引用指向同一个内存地址,这样可以节省内存,提升比较操作的效率。
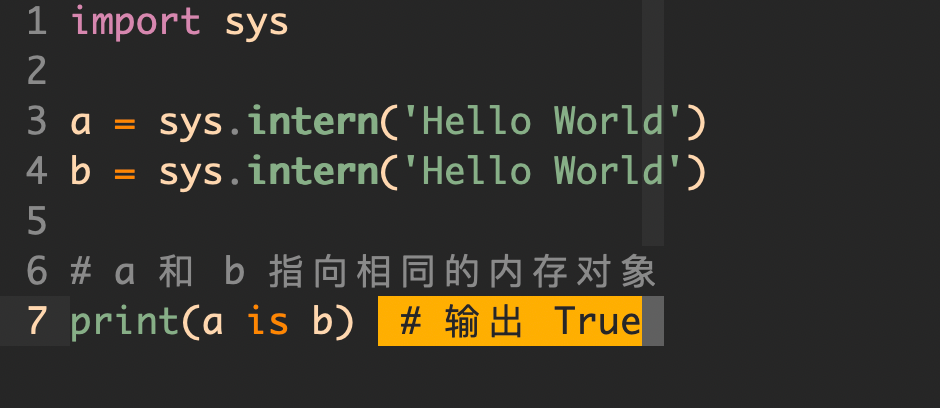
当然,有时候系统会自动帮你 intern。
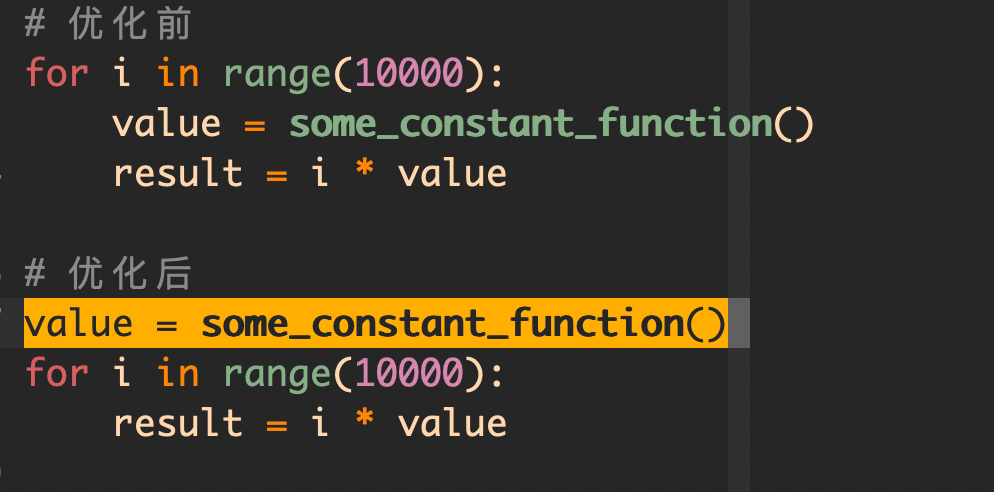
9,循环里的优化
我们经常会使用到循环语句,往往会把不必要重复执行的语句放到循环里面,这样就有点浪费了:
还有一些内置的函数如 map(), filter(), sum() 等,也可以使用它们来代替循环:
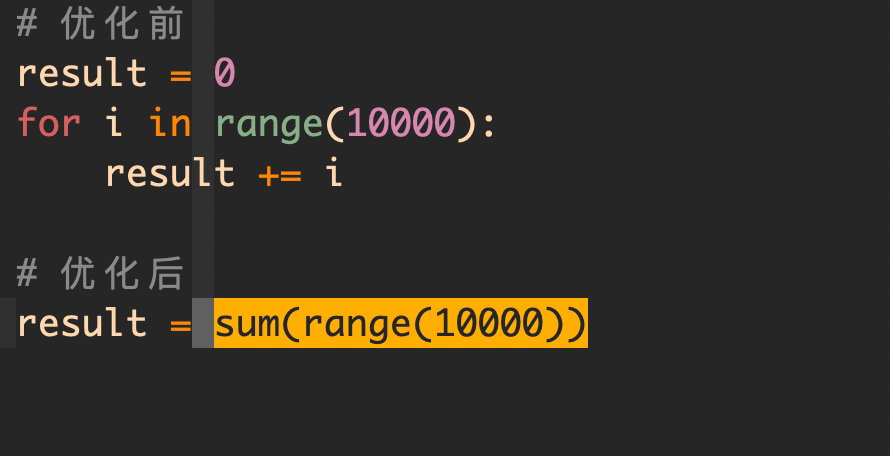
这比自己写的循环要来的舒服一些。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/88009.html
