
-
安装过程简单快捷 -
使用起来极为方便 -
为人工智能社区提供他们所需的RAG与LLM的精确API支持

PyMuPDF4LLM特征
-
支持多栏页面 -
支持图像和矢量图形的提取(并在MD文本中包含引用) -
支持页面分块输出 -
直接支持以 LlamaIndex 文档格式输出
import pymupdf4llmoutput = pymupdf4llm.to_markdown("input.pdf", write_images=True)
页面分块
如果请求页面分块(page_chunks),可以获取到带有丰富语义信息的输出。
import pymupdf4llmoutput = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
这会提供文档每一页的字典对象列表,遵循以下结构:
-
metadata — 包含文档元数据的字典。 -
toc_items — 指向页面的目录项列表。 -
tables — 该页面上的表格列表。 -
images — 该页面上的图像列表。 -
graphics — 该页面上的矢量图形矩形列表。 -
text — 页面内容,以Markdown文本形式。
LlamaIndex 文档格式输出
PyMuPDF4LLM实现了与LlamaIndex的无缝对接,具体细节如下:
import pymupdf4llmllama_reader = pymupdf4llm.LlamaMarkdownReader()llama_docs = llama_reader.load_data("input.pdf")
03。
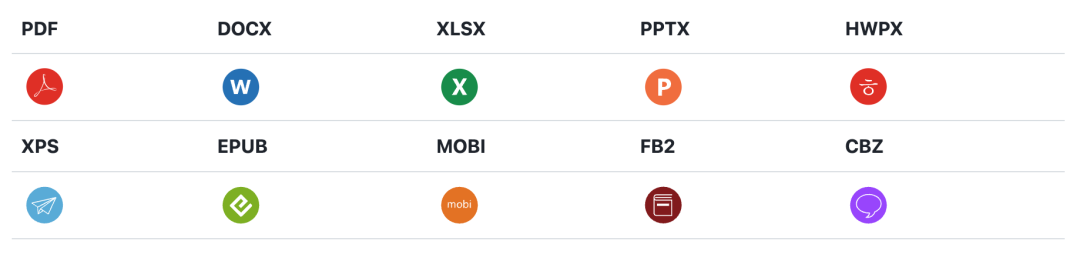
支持文档格式
PyMuPDF4LLM 支持以下文件类型进行文本提取:
-
此包利用PyMuPDF将文档页面转换为Markdown格式文本。 -
它能够识别标准文本和表格,确保它们按照正确的阅读顺序排列,然后统一转换为符合GitHub标准的Markdown文本。 -
标题行通过字体大小区分,并在前面加上一个或多个#号作为标题标记。 -
加粗、斜体、等宽文本以及代码块均能被准确识别,并按照相应的格式进行转换。有序列表和无序列表也遵循相同的处理逻辑。 -
默认情况下,会对文档的所有页面进行处理。如果需要,您也可以通过提供一个从0开始的页码列表来指定要处理的页面子集。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/88164.html